






进入账户 : root
查看ip地址: ip addr
关闭NetworkManager让它不再工作: systemctl stop NetworkManager & systemctl disable NetworkManager(不能小写)
命令重启网卡的操作:service network restart
编辑命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33
改静态方式:BOOTPROTO=dhcp 改为BOOTPROTO=static
设置IP地址:IPADDR=192.168.128.130(这里更具自己ip地址编辑,下面有步骤怎么查看虚拟机的ip地址)
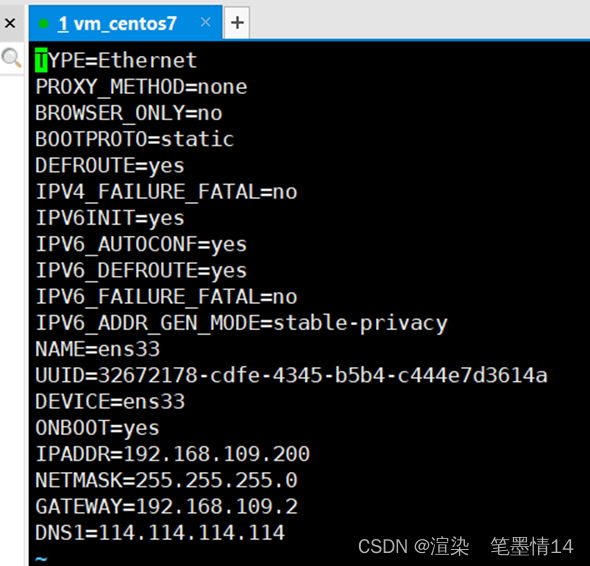
按ESC键,然后输入wq,保存退出
重启网络服务:service network restart
然查看新改的IP:ip addr
打开Xshell
点用户身份验证:输入root和密码
查看ip地址:ip addr
第二次实验
在Xshells输入 :ssh root@192.168.137.200 ,然后输入密码
安装jdk(后面要下载Xftp传输文件)
传输jdk:
输入ls查询jdk
输入 rpm -ivh jdk全名
输入 vi /etc/profile 配置文件
进去后在最下面输入 export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64
按住Escj键,输入::wq 退出
• 然后输入source /etc/profile命令对该文件进行刷新(一定要刷新)
Cd回到根目录、
创建java: vi Hello.java
第三次实验
右键 虚拟机—管理 –克隆—完整克隆
用同样的方式创建3个克隆、然后登录虚拟机和3个克隆机
更改3台克隆机的ip: vi /etc/sysconfig/network-scripts/ifcfg-ens33
改成201、202、203
重启网络服务:service network restart
第四次课:
打开Xshell
修改主机名: vi /etc/sysconfig/network
输入: HOSTNAME=master/node1/node2/node3 :wq退出(分别进入每个连接,共四个)
hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node2
hostnamectl set-hostname node3
(分别再每台主机上执行修改主机名,输入reboot重启)
设置域名和映射:vi /etc/hosts
输入:192.168.137.200 master master.centos.com
192.168.137.201 node1 node1.centos.com
192.168.137.202 node2 node2.centos.com
192.168.137.203 node3 node3.centos.com
剩下的3个都做这样的操作(完成映射关系的设置)
免密登录:所有的机器执行
ssh-keygen -t rsa 敲3次回车键
ssh-copy-id master (四台机器都要执行) 要输入yes
cd /root/.ssh (四台机器) ls
在masterz执行: 要输入yes
scp /root/.ssh/authorized_keys node1:/root/.ssh
scp /root/.ssh/authorized_keys node2:/root/.ssh
scp /root/.ssh/authorized_keys node3:/root/.ssh
验证: ssh node1 ip addr ssh node2 ip addr ssh node3 ip addr exit exit exit
配置Hadoop集群
tar -zxf hadoop-3.1.4.tar.gz -C /opt
删除文件:
编辑hadoop vi hadoop-env.sh
按住Escj键,输入::wq 退出
• 然后输入source /etc/profile命令对该文件进行刷新(一定要刷新)
后面五个个文件的配置(学习通4.8)
vi core-site.xml
配置命令复制到标签中
- 修改配置文件
/opt/hadoop-3.1.4/etc/hadoop
######hadoop-env.sh
添加JAVA_HOME环境变量:
export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64
(可以通过 echo $JAVA_HOME 获取路径)
######core-site.xml
fs.defaultFS
hdfs://master:8020
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
######hdfs-site.xml
dfs.namenode.name.dir
/data/hadoop/namenode
dfs.datanode.data.dir
/data/hadoop/datanode
dfs.blocksize
134217728
dfs.replication
3
dfs.permissions.enabled
false
dfs.namenode.http-address
master:50070
######mapred-site.xml
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=/opt/hadoop-3.1.4
mapreduce.application.classpath
/opt/Hadoop-3.1.4/share/Hadoop/mapreduce/:/opt/Hadoop-3.1.4/share/Hadoop/mapreduce/lib/
######yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.app.mapreduce.am.resource.mb
1024
进去后输入node1 node2 node3
拷贝hadoop包:cd /opt
分发到每个节点(这个时候比较慢,可以打开三台机器)
scp -r /opt/hadoop-3.1.4/ node1:/opt/
scp -r /opt/hadoop-3.1.4/ node2:/opt/
scp -r /opt/hadoop-3.1.4/ node3:/opt/
- 创建数据和临时文件夹
Master node:
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/namenode
Other nodes:
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/datanode
或者在master节点shell :
ssh node1 “mkdir -p /data/hadoop/tmp & mkdir -p /data/hadoop/datanode”
ssh node2 “mkdir -p /data/hadoop/tmp & mkdir -p /data/hadoop/datanode”
ssh node3 “mkdir -p /data/hadoop/tmp & mkdir -p /data/hadoop/datanode”
(英文符号)
-
格式化 HDFS
在master上面:
cd /opt/hadoop-3.1.4
cd bin
./hdfs namenode -format demo -
启动集群
在master上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意启动顺序:
[root@master sbin]# ./start-dfs.sh(会报错)
解决:
再输入:vi hadoop-env.sh
- 报错:设置hadoop-env.sh
/opt/hadoop-3.1.4/etc/hadoop/hadoop-env.sh
在master上设置,添加授权:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
拷贝文件到其他节点:
scp hadoop-env.sh node1:/opt/hadoop-3.1.4/etc/hadoop/
scp hadoop-env.sh node2:/opt/hadoop-3.1.4/etc/hadoop/
scp hadoop-env.sh node3:/opt/hadoop-3.1.4/etc/hadoop/
[root@master sbin]# ./start-yarn.sh
每一个虚拟机都要输入exit
[root@master sbin]# ./mr-jobhistory-daemon.sh start historyserver或者 mapred --daemon start historyserver
每一步都输入:ssh node1 “jps” ssh node2 “jps” ssh node3 “jps”
-
关闭防火墙
(对所有节点,可以考虑在克隆之前完成)
systemctl status firewalld.service
systemctl stop firewalld.service & systemctl disable firewalld.service -
宿主机上做节点映射
宿主机上修改,host文件
/C:/Windows/System32/drivers/etc/hosts
编辑文件(参看视频)
在最下面添加:
192.168.137.200 master master.centos.com
192.168.137.201 node1 node1.centos.com
192.168.137.202 node2 node2.centos.com
192.168.137.203 node3 node3.centos.com
(PS:这里修改涉及权限,可上网查,CSDN收藏linux文件夹)
- Hadoop环境变量配置
(在主机上)
vi /etc/profile
export HADOOP_HOME=/opt/hadoop-3.1.4
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/bin
source /etc/profile
echo $HADOOP_HOME
echo $PATH
- 关闭
在master上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意关闭顺序:
[root@master sbin]# ./stop-dfs.sh
[root@master sbin]# ./stop-yarn.sh
[root@master sbin]#./mr-jobhistory-daemon.sh stop historyserver 或者 mapred --daemon stop historyserver
poweroff
HDFS的操作:
先到cd /opt/hadoop-3.1.4/sbin目录
[root@master sbin]# ./start-dfs.sh
[root@master sbin]# ./start-yarn.sh
[root@master sbin]# ./mr-jobhistory-daemon.sh start historyserver
访问HDFS系统的指令:
常用的shell命令:
-
查看指令 ls
调用格式: hdfs dfs -ls /目录
hdfs dfs -ls -R / -
创建目录 mkdir
hdfs dfs -mkdir [-p]
path 为待创建的目录
-p选项的行为与linux mkdir -p非常相似,它会沿着路径创建父目录
调用格式: hdfs dfs -mkdir (-p) /目录 -
上传指令 put(拷贝)
调用格式:hdfs dfs -put /本地文件 /目的目录
(注意:所有节点的防火墙都要关闭,不然可能会上传失败。)
-
上传指令 moveFromLocal(剪切)
-
下载文件 get
hdfs dfs -get [-f] [-p] -
移动数据 mv
hdfs dfs -mv /dir1/c.txt /dir2 -
删除文件 rm
hdfs dfs -rm [-r] [-skipTrash]
注意:如果删除文件夹需要加-r
e.g. hdfs dfs -rm /dir2/a.txt -
拷贝文件 cp
e.g. hdfs dfs -cp /dir1/a.txt /dir2
9. 查看文件内容 cat
hdfs dfs -cat
e.g. hdfs dfs -cat /dir1/a.txt
10. 追加数据到HDFS文件中 appendToFile
hdfs dfs -appendToFile
hdfs dfs -appendToFile
- 更改权限 chmod
hdfs dfs -chmod 777 /a.txt
hdfs dfs -chmod [-R] 改变文件权限 -R 对整个目录有效,递归执行。
- 更改用户用户组 chown
hdfs dfs -chown [-R]
改变文件的用户和用户组
e.g.
(先新建一个账户:hadoop 密码:wyh2001)
MapReduce
Step 1. 数据准备
创建一个新的文件:WordCount.txt,输入下面内容后改后缀为 .java
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, “word count”);
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
新建文件夹wc00,上传WordCount.java到虚拟机,再移动到wc00这个文件夹
环境变量的配置:将 Hadoop 的 classhpath 信息添加到 CLASSPATH 变量中
export CLASSPATH=
(
(
(HADOOP_HOME/bin/hadoop classpath):$CLASSPAH
vi /etc/profile
source /etc/profile
(最底下)
编译、打包 Hadoop MapReduce程序:
javac WordCount.java
jar -cvf WordCount.jar ./WordCount*.class
(随便新建一个txt文件,随便写入一些单词)
配置yarn-site.xml:
hadoop classpath
.
vi /opt/hadoop-3.1.4/etc/hadoop/yarn-site.xml
启动集群&上传文件到集群:
在master上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意启动顺序:
[root@master sbin]# ./start-dfs.sh
[root@master sbin]# ./start-yarn.sh
[root@master sbin]# ./mr-jobhistory-daemon.sh start historyserver
hdfs dfs -mkdir /output
hdfs dfs -put wordcount.txt /output (wordcount.txt是有单词的文本文件,output是创建的文件夹)
运行jar 包 (output是输入路径, results是输出路径)
[root@master wc00]# hadoop jar WordCount.jar WordCount /output /results
6.6扩展阅读:yarn的资源调度
目标:配置Capacity Scdeduler (配置见6.6)
[root@master hadoop]# vi capacity-scheduler.xml
原来是0.1,改成0.3
(第一个(defult)改为(dev,prod) ,其余的全部改为dev,第一个100改为40,第二个100改为60)
(在最后)保存退出
[root@master hadoop]# vi capacity-scheduler.xml
再次编辑,复制这段代码(已经改好了)
(这是位置和标识处)
拷贝到节点上:
[root@master hadoop]# scp capacity-scheduler.xml node1:/opt/hadoop-3.1.4/etc/hadoop/
[root@master hadoop]# scp capacity-scheduler.xml node2:/opt/hadoop-3.1.4/etc/hadoop/
[root@master hadoop]# scp capacity-scheduler.xml node3:/opt/hadoop-3.1.4/etc/hadoop/
启动
在master上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意启动顺序:
[root@master sbin]# ./start-dfs.sh
[root@master sbin]# ./start-yarn.sh
[root@master sbin]# ./mr-jobhistory-daemon.sh start historyserver
6.8:MapReduce案例2_Countbydate(没有配置)
6.9:MapReduce案例2_Countbydate(第一个视频没有配置)
MapReduce案例2_Countbydate
(1)安装NTP服务。在各节点:
yum -y install ntp
(2)设置假设master节点为NTP服务主节点,那么其配置如下。
使用命令“vi /etc/ntp.conf”打开/etc/ntp.conf文件,注释掉以server开头的行,并添加:
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)在slave中配置NTP,注释掉server开头的行,同样修改/etc/ntp.conf文件,并继续添加一行:
server master
(4)执行命令“systemctl stop firewalld.service & systemctl disable firewalld.service”永久性关闭防火墙,主节点和从节点都要关闭,之前永久关闭防火墙,可以忽略,查看命令:systemctl status firewalld.service。
(5)启动NTP服务。
① 在master节点执行命令“service ntpd start & chkconfig ntpd on”
② 在slave上执行命令“ntpdate master”即可同步时间
③ 在slave上分别执行“service ntpd start & chkconfig ntpd on”即可启动并永久启动NTP服务。
6.11 SortByCount案例(没有配置)
7.1:Hive简介与MySQL的安装
安装wget : ( “ yum install -y wget ”)
在master节点上:
下载mysql8.x的yum源
wget http://repo.mysql.com//mysql80-community-release-el7-3.noarch.rpm
加载下载的mysqlyum源
yum localinstall mysql80-community-release-el7-3.noarch.rpm
搜索mysql源是否加载
yum search mysql
yum install mysql-community-server.x86_64
启动mysql服务
service mysqld start & chkconfig mysqld on
查询初始密码
cat /var/log/mysqld.log
重新登录
mysql -u root -p
(将复制的密码粘贴进去)
第一次强行修改密码规则:
ALTER USER ‘root’@‘localhost’ IDENTIFIED BY ‘adD23+#M’;
set global validate_password.policy=0;
set global validate_password.length=1;
设置自定义密码:
alter user ‘root’@‘localhost’ identified by ‘123456’;
修改root账户权限:
use mysql;
show tables;
select host,user from user;
update user set host=‘%’ where user=’root’;
flush privileges;
(上面几句都是sql语言)
注:可能出现的问题
The GPG keys listed for the “MySQL 8.0 Community Server” repository are already installed but they are not correct for this package.
Check that the correct key URLs are configured for this repository.
解决办法:
1, 导入Key:
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
2, 再重新安装
7.2:Hive的安装与部署
上传与解压Hive:
- 把安装包上传到 /opt 目录下
- 解压安装包到 /usr/local/ 目录下
tar -zxf /opt/apache-hive-2.3.8-bin.tar.gz -C /usr/local/ - 文件夹重命名
mv apache-hive-2.3.8-bin hive
配置hive-env.sh:
在/usr/local/hive/conf 目录下 ,修改文件hive-env.sh ( vi hive-env.sh )
末尾添加:
export HADOOP_HOME=/opt/hadoop-3.1.4
安装Hive:
-
把hive-site.xml文件上传到Hive安装目录的conf目录下
/usr/local/hive/conf -
上传MySQL驱动到Hive安装目录的lib目录下
-
替换Hive的guava-27.0-jre.jar
rm -rf /usr/local/hive/lib/guava-14.0.1.jar
cp /opt/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib -
在 /etc/profile 文件中添加Hive的环境变量 (vi /etc/profile)
exoprt HIVE_HOME=/usr/local/hive :$HIVE_HOME/bin (输入source /etc/profile)
5. 使用Apache的工具schematool初始化metastore
schematool -dbType mysql -initSchema(会出现问题,执行下面代码)
打开 hive-site.xml,改写此段代码
javax.jdo.option.ConnectionURL
jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF8&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Europe/Berlin
(找到这一段,加入红色字体部分)
再输入:schematool -dbType mysql -initSchema
-
启动元数据服务:hive --service metastore &
-
启动hadoop,启动hive
启动集群:在master上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意启动顺序:
[root@master sbin]# ./start-dfs.sh
[root@master sbin]# ./start-yarn.sh
[root@master sbin]# ./mr-jobhistory-daemon.sh start historyserver
(每一台虚拟机都要开机)
到这样一个目录
[root@master sbin]# cd /usr/local/hive/lib
内部表:
查看位置,是否建立好
上传person.txt文件到 /opt目录下
查看数据库信息:通过dfs命令上传
dfs -put /opt/person.txt /user/hive/warehouse/train.db/person;
查看:
设置在每一个字段上看到表头
hive> set hive.cli.print.header=true;
hive> select * from person;
显示表 的信息
hive> set hive.cli.print.current.db=true;
hive (train)> select * from person;
外部表:
创建方式:
hive (train)> create external table external_table(
> id int,
> name string,
> age int)
> row format delimited fields terminated by ‘,’
> location ‘/user/root/external/external_person’;
把数据加载上面:
hive (train)> dfs -put /opt/person.txt /user/root/external/external_person;
删除表:
hive (train)> drop table person;
hive (train)> drop table external_table;
(drop删除的是内部表,外部表还在)
(前面内部表,后面外部表; 内部表在hive/warehouse里,外部表在root里)
7.5:Hive的基本操作:分区表
- 创建tidanic 表格
create table tidanic(
passengerid int,
survived int,
pclass int,
name string,
sex string,
age int,
sibsp int,
parch int,
ticket string,
fare double,
cabin string,
embarked string)
row format delimited fields terminated by ‘,’;
上传文件:(删掉第一行()或者上传后在/opt目录下用vi 命令删除)
上传(在opt目录下):
[root@master opt]# hdfs dfs -put /opt/train.csv /user/hive/warehouse/taitan.db/tidanic
查看:hive> select * from tidanic;
查看前十行:hive> select * from tidanic limit 10;
- 静态分区表
hive> create table tidanic_part(
> passengerid int,
> survived int,
> pclass int,
> name string,
> sex string)
> partitioned by(gender string)
row format delimited fields terminated by ‘,’;
hive> insert overwrite table tidanic_part partition(gender=‘female’) select passengerid,survived,pclass,name,sex from tidanic where sex=‘female’;
结果查询:
hive> insert overwrite table tidanic_part partition(gender=‘male’) select passengerid,survived,pclass,name,sex from tidanic where sex=‘male’;
(把female 改成 male)
- 动态分区表
建表
hive> create table tidanic_dynamic_part(passengerid int,
survived int,
name string)
partitioned by(passenderclass string) #指定分段为gender
row format delimited fields terminated by ‘,’;
设置
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode-nostrict;
设置字段
set hive.exec.dynamic.partition.mode=nostrict;
insert overwrite table tidanic_dynamic_part partition(passenderclass) select passengerid,survived,name,pclass from tidanic;
7.8(1)通过HDFS导入文件: dfs -put /opt/train.csv /user/root;
7.8(2)多表查询导入数据:
create table tidanic_save like tidanic;
create table tidanic_died like tidanic;
from tidanic
insert overwrite table tidanic_save select * where survived=1
insert overwrite table tidanic_died select * where survived=0;
7.8(3):导出到linux:
insert overwrite local directory ‘/opt/tidanic_save’ row format delimited fields terminated by ‘,’ select * from tidanic_save;
前十行
select sex,count(*) as s_count from tidanic where survived=1 group by sex;
1、统计性别与生存率的关系
hive (taitan)> set hive.strict.checks.cartesian.product=false;
hive (taitan)> set hive.mapred.mode=nonstrict;
hive (taitan)> select sex,s_count/all_count as s_percent from(select sex,count() as s_count from tidanic where survived=1 group by sex) a join (select count() as all_count from tidanic where survived=1) b on 1=1;
结果展示:
2、统计客舱等级与生存率的关系
hive (taitan)> select pclass,s_count/all_count as s_percent from(select pclass,count() as s_count from tidanic where survived=1 group by pclass) a join (select count() as all_count from tidanic where survived=1) b on 1=1;
(将sex改为pclass)
结果展示:
3、统计登船港口与生存率的关系
hive (taitan)> select embarked,s_count/all_count as s_percent from(select embarked,count() as s_count from tidanic where survived=1 group by embarked) a join (select count() as all_count from tidanic where survived=1) b on 1=1;
(改为embarkeds)
结果展示
8.2 :ZooKeeper的安装部署
配置ZooKeeper集群主要步骤:
解压安装包
修改zoo.cfg配置文件
发送安装包到其他节点
启动ZooKeeper
主要配置过程及文件:
在要设置为zookeeper的node1节点
-
上传zookeeper-3.4.6.tar.gz安装包到slave1节点的/opt目录下
-
解压
tar -zxf /opt/zookeeper-3.4.6.tar.gz -C /usr/local/ -
进入/usr/local/zookeeper-3.4.6/conf
cd /usr/local/zookeeper-3.4.6/conf
4.复制zoo_sample.cfg重命名为zoo.cfg
cp zoo_sample.cfg zoo.cfg
配置内容如下:(vi zoo.cfg)(配置放在最后)
dataDir=/usr/lib/zookeeper
dataLogDir=/var/log/zookeeper
clientPort=2181
tickTime=2000
initLimit=5
syncLimit=2
server.4=master:2888:3888
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
5.在各个子节点新建以下文件夹:
mkdir /usr/lib/zookeeper
mkdir /var/log/zookeeper
编辑:
vi /usr/lib/zookeeper/myid
在 master的/usr/lib/zookeeper目录下新建文件myid,内容为4
在 node1的/usr/lib/zookeeper目录下新建文件myid,内容为1
在 node2的/usr/lib/zookeeper目录下新建文件myid,内容为2
在 node3的/usr/lib/zookeeper目录下新建文件myid,内容为3
6.在master节点 /或者在所配置zookeeper的节点,将zookeeper复制给其他节点
scp -r /usr/local/zookeeper-3.4.6 node2:/usr/local/
scp -r /usr/local/zookeeper-3.4.6 node3:/usr/local/
7.在各子节点的/etc/profile中配置环境变量
export ZK_HOME=/usr/local/zookeeper:-3.4.6
export PATH=
P
A
T
H
:
PATH:
PATH:ZK_HOME/bin
运行source /etc/profile使配置生效
8. 启动各节点Zookeeper
/usr/local/zookeeper/bin/zkServer.sh start
9.查看各个子节点的zookeeper是否启动
/usr/local/zookeeper/bin/zkServer.sh status
到master主机上,和上面步骤一样
(修改zoo.cfg时可直接从node1拷贝)
[root@node1 ~]# cd /usr/local/zookeeper-3.4.6/conf/
[root@node1 conf]# scp -r zoo.cfg master:/usr/local/zookeeper-3.4.6/conf/
第6步每个节点都要复制
8.3:HBase的安装部署
主要配置过程及文件:
-
通过xmanager的Xftp上传hbase-2.2.6-bin.tar.gz压缩包到/opt目录
-
解压缩hbase-2.2.6.tar.gz 文件
tar -zxf /opt/hbase-2.2.6-bin.tar.gz -C /usr/local
解压后即可,看到/usr/local/hbase-2.2.6文件夹
修改文件名称
[root@master local]# mv hbase-2.2.6/ hbase -
配置hbase
进入目录:
cd /usr/local/hbase/conf
3.1 修改hbase-site.xml文件,内容如:
hbase.rootdir
hdfs://master:8020/hbase
hbase.master
master
hbase.cluster.distributed
true
hbase.zookeeper.property.clientPort
2181
hbase.zookeeper.quorum
master,node1,node3
zookeeper.session.timeout
60000000
dfs.support.append
true
hbase.unsafe.stream.capability.enforce
false
从这里插入,删掉后面部分
3.2 配置hbase-env.sh
注释下面两句:
export HBASE_MASTER_OPTS=“
H
B
A
S
E
M
A
S
T
E
R
O
P
T
S
−
X
X
:
P
e
r
m
S
i
z
e
=
128
m
−
X
X
:
M
a
x
P
e
r
m
S
i
z
e
=
128
m
"
e
x
p
o
r
t
H
B
A
S
E
R
E
G
I
O
N
S
E
R
V
E
R
O
P
T
S
=
"
HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" export HBASE_REGIONSERVER_OPTS="
HBASEMASTEROPTS−XX:PermSize=128m−XX:MaxPermSize=128m"exportHBASEREGIONSERVEROPTS="HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m”
如果没有可以不管
添加如下内容(均根据实际情况修改):
export HBASE_CLASSPATH=/opt/hadoop-3.1.4/etc/hadoop
export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64
export HBASE_MANAGES_ZK=false
3.3 配置regionservers,内容如下
master
node1
node3
3.4 拷贝到各子节点
scp -r /usr/local/hbase/ node1:/usr/local/
scp -r /usr/local/hbase/ node3:/usr/local/
3.5 配置环境变量
export HBASE_HOME=/usr/local/hbase-2.2.6
export PATH=
P
A
T
H
:
PATH:
PATH:HBASE_HOME/bin
[root@master conf]# scp -r /etc/profile node1:/etc/profile
[root@master conf]# scp -r /etc/profile node3:/etc/profile
[root@master conf]# ssh node1 source /etc/profile
[root@master conf]# ssh node3 source /etc/profile
- 运行 hbase
首先确保启动了zookeeper和Hadoop集群
[root@node3 sbin]# cd /opt/hadoop-3.1.4/sbin
[root@node3 sbin]# ./start-all.sh
[root@node3 sbin]# zkServer.sh start
[root@node3 sbin]# zkServer.sh status
进入目录
cd /usr/local/hbase/bin/
运行
./start-hbase.sh
5.在浏览器查看
http://192.168.137.200:16010 (根据自己的集群设置输入地址)















 6032
6032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









