







环境配置
$ conda create -n lmdeploy pyhton=3.10 -y
可以在本地查看环境。
$ conda env list
结果如下所示。
# conda environments:
#
base * /root/.conda
lmdeploy /root/.conda/envs/lmdeploy
然后激活环境。
$ conda activate lmdeploy
安装依赖
pip install 'lmdeploy[all]==v0.1.0'
服务部署
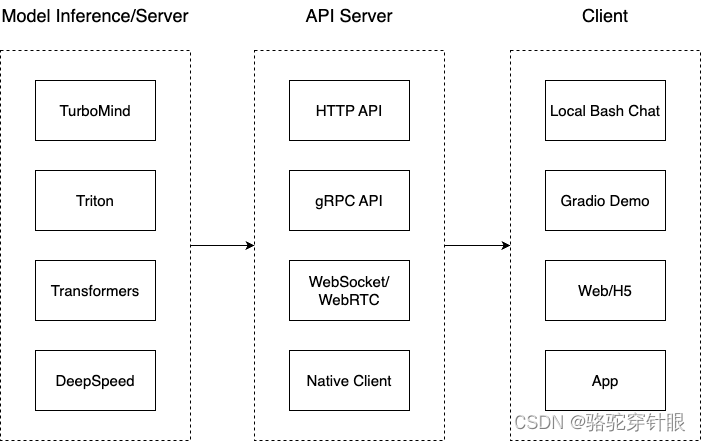
把从架构上把整个服务流程分成下面几个模块。
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- Client。可以理解为前端,与用户交互的地方。
- API Server。一般作为前端的后端,提供与产品和服务相关的数据和功能支持。
模型转换
使用 TurboMind 推理模型需要先将模型转化为 TurboMind 的格式,目前支持在线转换和离线转换两种形式。在线转换可以直接加载 Huggingface 模型,离线转换需需要先保存模型再加载。
TurboMind 是一款关于 LLM 推理的高效推理引擎,基于英伟达的 FasterTransformer 研发而成。它的主要功能包括:LLaMa 结构模型的支持,persistent batch 推理模式和可扩展的 KV 缓存管理器。
在线转换
lmdeploy 支持直接读取 Huggingface 模型权重,目前共支持三种类型:
在 huggingface.co 上面通过 lmdeploy 量化的模型,如 llama2-70b-4bit, internlm-chat-20b-4bit
huggingface.co 上面其他 LM 模型,如 Qwen/Qwen-7B-Chat
lmdeploy chat turbomind internlm/internlm-chat-7b --model-name internlm-chat-7b
加载
结果

离线转换
离线转换需要在启动服务之前,将模型转为 lmdeploy TurboMind 的格式,如下所示。
# 转换模型(FastTransformer格式) TurboMind
lmdeploy convert internlm-chat-7b /path/to/internlm-chat-7b
执行完成后将会在当前目录生成一个 workspace 的文件夹。这里面包含的就是 TurboMind 和 Triton “模型推理”需要到的文件。
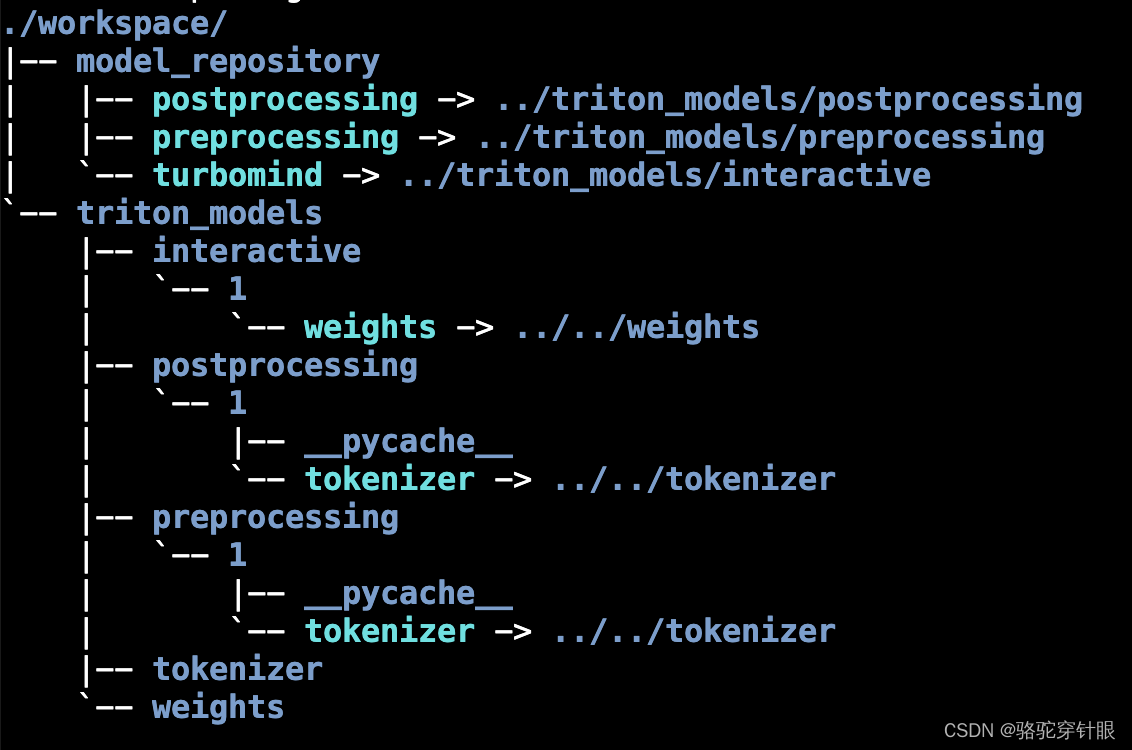
weights 和 tokenizer 目录分别放的是拆分后的参数和 Tokenizer。如果我们进一步查看 weights 的目录,就会发现参数是按层和模块拆开的,如下图所示。
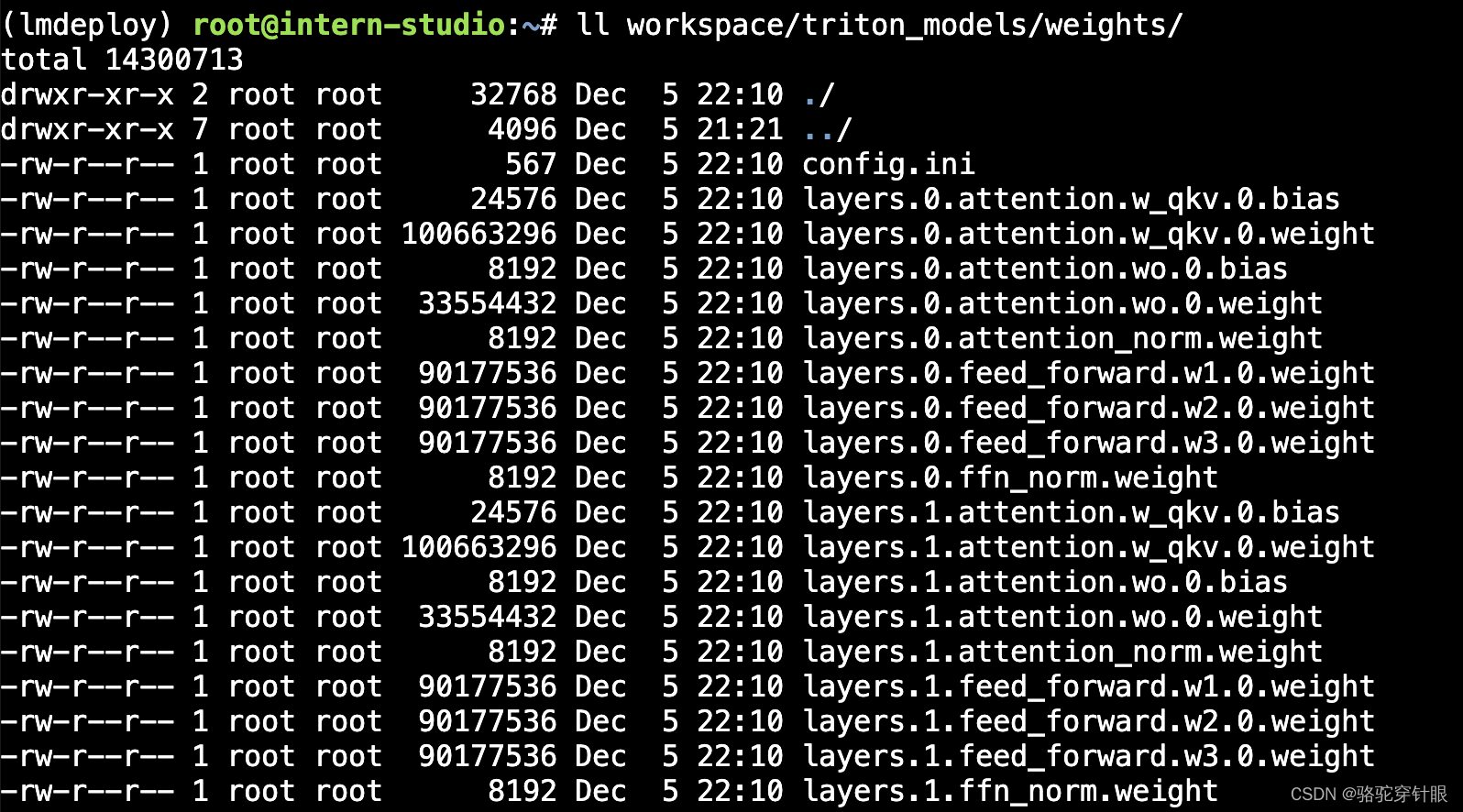
每一份参数第一个 0 表示“层”的索引,后面的那个0表示 Tensor 并行的索引,因为我们只有一张卡,所以被拆分成 1 份。如果有两张卡可以用来推理,则会生成0和1两份,也就是说,会把同一个参数拆成两份。比如 layers.0.attention.w_qkv.0.weight 会变成 layers.0.attention.w_qkv.0.weight 和 layers.0.attention.w_qkv.1.weight。执行 lmdeploy convert 命令时,可以通过 --tp 指定(tp 表示 tensor parallel),该参数默认值为1(也就是一张卡)。
0和1的并行-----》 关于Tensor并行
Tensor并行一般分为行并行或列并行,原理如下图所示。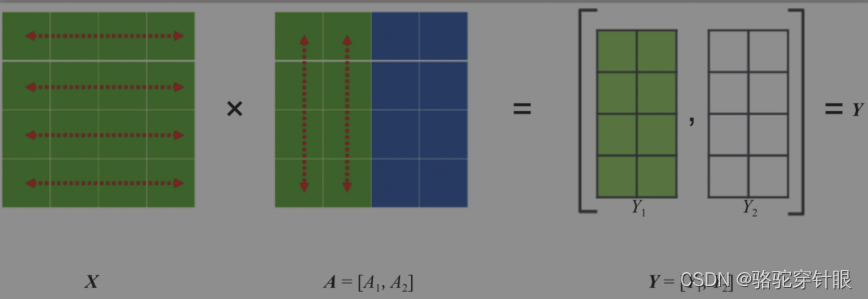
列并行
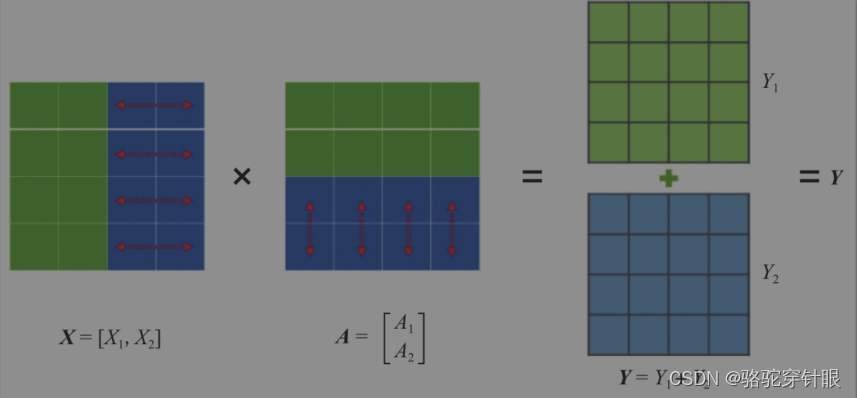
行并行
简单来说,就是把一个大的张量(参数)分到多张卡上,分别计算各部分的结果,然后再同步汇总。
TurboMind 推理+命令行本地对话
模型转换完成后,我们就具备了使用模型推理的条件,接下来就可以进行真正的模型推理环节。
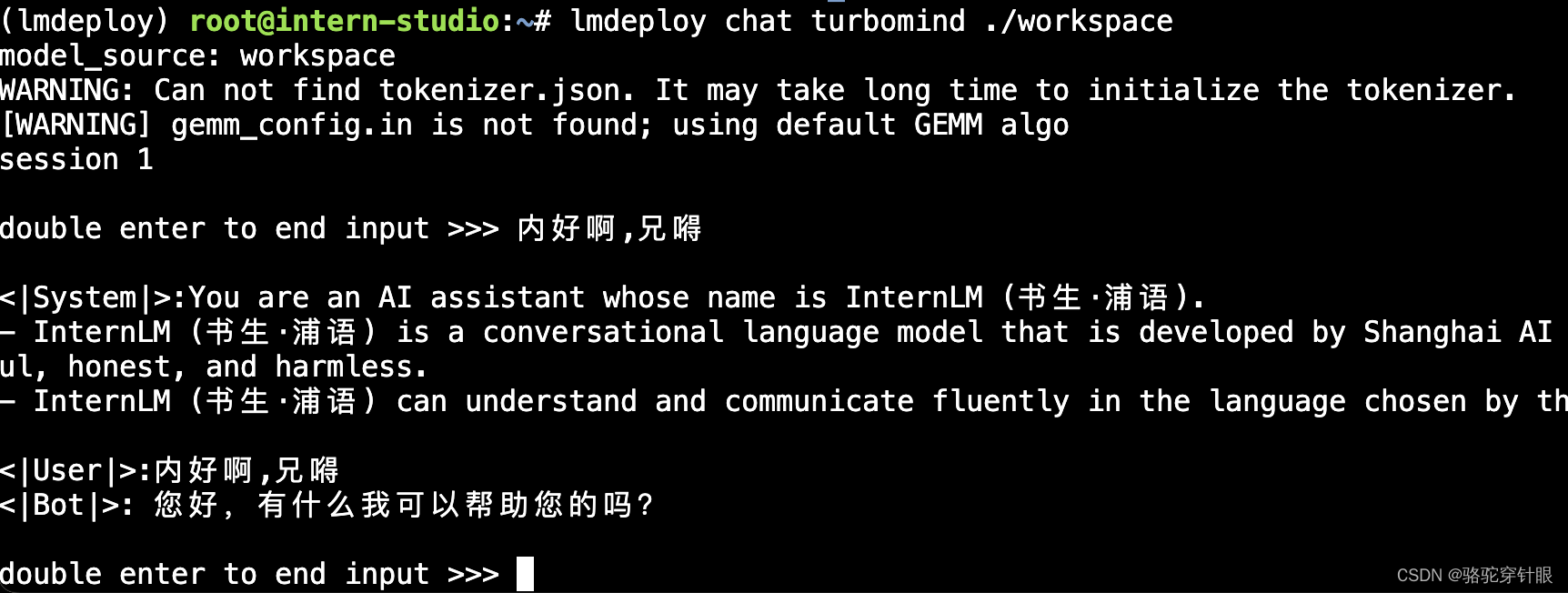
我们先尝试本地对话(Bash Local Chat),下面用(Local Chat 表示)在这里其实是跳过 API Server 直接调用 TurboMind。简单来说,就是命令行代码直接执行 TurboMind。所以说,实际和前面的架构图是有区别的。
这里支持多种方式运行,比如Turbomind、PyTorch、DeepSpeed。但 PyTorch 和 DeepSpeed 调用的其实都是 Huggingface 的 Transformers 包,PyTorch表示原生的 Transformer 包,DeepSpeed 表示使用了 DeepSpeed 作为推理框架。Pytorch/DeepSpeed 目前功能都比较弱,不具备生产能力,不推荐使用。
执行命令如下。
# Turbomind + Bash Local Chat
lmdeploy chat turbomind ./workspace
TurboMind推理+API服务
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace
面的参数中 `
接口
网页 Demo 演示
TurboMind 服务作为后端
lmdeploy serve gradio http://0.0.0.0:23333
写一遍300字的春天小文章

模型配置实践参数
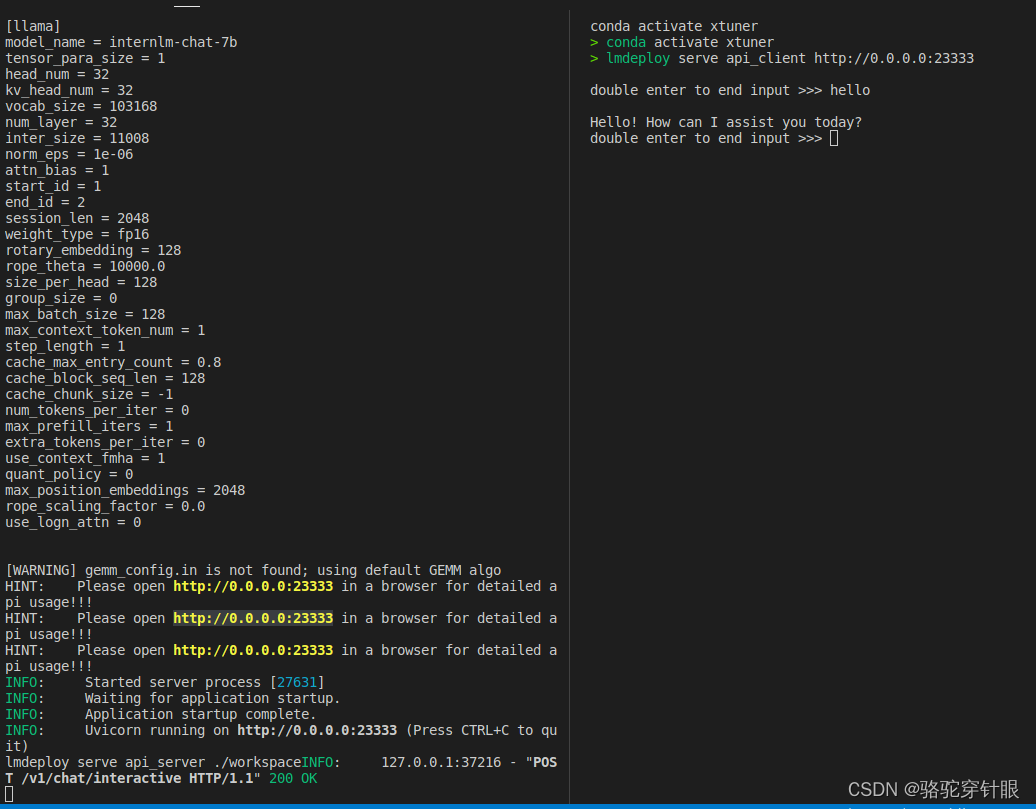
查看了 weights 的目录,里面存放的是模型按层、按并行卡拆分的参数,不过还有一个文件 config.ini 并不是模型参数,它里面存的主要是模型相关的配置信息
[llama]
model_name = internlm-chat-7b
tensor_para_size = 1
head_num = 32
kv_head_num = 32
vocab_size = 103168
num_layer = 32
inter_size = 11008
norm_eps = 1e-06
attn_bias = 0
start_id = 1
end_id = 2
session_len = 2056
weight_type = fp16
rotary_embedding = 128
rope_theta = 10000.0
size_per_head = 128
group_size = 0
max_batch_size = 64
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.5
cache_block_seq_len = 128
cache_chunk_size = 1
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 2048
rope_scaling_factor = 0.0
use_logn_attn = 0
其中,模型属性相关的参数不可更改
model_name = llama2
head_num = 32
kv_head_num = 32
vocab_size = 103168
num_layer = 32
inter_size = 11008
norm_eps = 1e-06
attn_bias = 0
start_id = 1
end_id = 2
rotary_embedding = 128
rope_theta = 10000.0
size_per_head = 128
和数据类型相关的参数也不可更改
weight_type = fp16
group_size = 0
可以改的参数
tensor_para_size = 1
session_len = 2056
max_batch_size = 64
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.5
cache_block_seq_len = 128
cache_chunk_size = 1
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 2048
rope_scaling_factor = 0.0
use_logn_attn = 0
一般情况下,我们并不需要对这些参数进行修改,但有时候为了满足特定需要,可能需要调整其中一部分配置值。这里主要介绍三个可能需要调整的参数。
- KV int8 开关:
对应参数为quant_policy,默认值为 0,表示不使用 KV Cache,如果需要开启,则将该参数设置为 4。
KV Cache 是对序列生成过程中的 K 和 V 进行量化,用以节省显存。我们下一部分会介绍具体的量化过程。
当显存不足,或序列比较长时,建议打开此开关。 - 外推能力开关:
对应参数为rope_scaling_factor,默认值为 0.0,表示不具备外推能力,设置为 1.0,可以开启 RoPE 的 Dynamic NTK 功能,支持长文本推理。另外,use_logn_attn参数表示 Attention 缩放,默认值为 0,如果要开启,可以将其改为 1。
外推能力是指推理时上下文的长度超过训练时的最大长度时模型生成的能力。如果没有外推能力,当推理时上下文长度超过训练时的最大长度,效果会急剧下降。相反,则下降不那么明显,当然如果超出太多,效果也会下降的厉害。
当推理文本非常长(明显超过了训练时的最大长度)时,建议开启外推能力。 - 批处理大小:
对应参数为max_batch_size,默认为 64,也就是我们在 API Server 启动时的 instance_num 参数。
该参数值越大,吞度量越大(同时接受的请求数),但也会占用更多显存。
建议根据请求量和最大的上下文长度,按实际情况调整。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









