







目录
首先了解可疑行为检测,它的目标是学习未知欺诈模式,这些模式符合“已知的已知”模型。
创建工程
接着前面的项目,导入jar包和数据。
数据集
我们将使用一个描述保险交易的数据集,可以在Oracle Database Online Documentation (2015)中找到它.
这个数据集描述了一个未公开的保险公司的车辆事故保险理赔情况。其中包含15 430个理赔 案例,每个理赔用33个属性进行描述:
客户详细信息(年龄、性别、婚姻状况等)
购买保单(保单种类、车辆类型、增补数、代理类型等)
理赔情况(日/月/周理赔,保单报告归档、证人、事故报告间隔日期、事故理赔等)
其他客户数据(车辆数、上一次理赔、司机评级等)
有无欺诈(有或无)
我们的任务是创建一个模型,将来用于识别可疑的理赔。这项任务面临的挑战是,这些索 赔中只有6%是可疑的。如果我们创建了一个虚拟分类器,说所有索赔都不可疑,那在94%的索 赔案例中它的判断都是对的。因此,这项任务中,我们将使用不同的精确度测量方法:准确率 与召回率。
表格中有4种可能的结果,分别是真正、假正、假负、真负,由此可推出

准确率与召回率定义如下。
准确率等于在被分类器判定为正的所有样本实例(TP+FP)中,正确判断为正(TP)的 正例样本所占比重,如下:

召回率等于在总正例样本(TP+FN)中,被正确判定为正(TP)的正例所占比重,如下: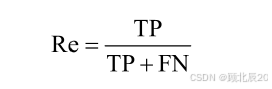
若使用这些指标,我们的虚拟分类器得分是:Pr=0、Re=0,因为它从不会将任何实例标 记为欺诈(TP=0)。实际上,我们希望使用这两个指标评价分类器,即F值(F-measure), 它是一种在准确率与召回率之间计算调和平均数的方法,如下:
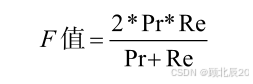
接下来,继续设计一个真实的分类器。
为可疑模式建模
为了设计一个分类器,我们将遵循第1章讲解的有关监督学习的标准步骤。此处还要加入其 他一些步骤,以处理非平衡数据集,并对基于准确率与召回率的分类模型做评估。详细步骤如下。
加载.csv格式的数据;
指派分类属性;
将所有属性从数值型(numeric)转换为名义型(nominal),确保没有错误加载的数值;
Experiment 1:使用k折交叉验证评价模型;
Experiment 2:重新调整数据集,使之拥有更均衡的类分布,并且手动交叉验证;
使用召回率、精确率与F值评价分类器。
首先,使用CSVLoader类加载数据.
// 获取CSV文件的路径
String filePath = ClassUtils.getDefaultClassLoader().getResource("data/test07/claims.csv").getPath();
// 创建CSVLoader对象,用于加载CSV文件
CSVLoader loader = new CSVLoader();
// 设置CSV文件的分隔符为逗号
loader.setFieldSeparator(",");
// 将文件路径设置为CSVLoader的输入源
loader.setSource(new File(filePath));
// 使用CSVLoader加载数据并将其转换为Weka的Instances对象
Instances data = loader.getDataSet();然后,确保所有属性的类型都是名义型。在数据导入期间,Weka会使用一些启发式方法猜 测属性最有可能的类型,即数值型、名义型、字符串型、日期型。由于启发式方法并非总能正确 猜中属性类型,所以要手动设置属性类型
/*
* 配置数据集
*/
// 定义属性索引
int CLASS_INDEX = 15; // 类标签的索引(欺诈类别)
int POLICY_INDEX = 17; // 政策属性的索引(不相关)
int NO_FRAUD = 0, FRAUD = 1; // 欺诈类别的标签值
int FOLDS = 3; // K折交叉验证的折数
// 将所有数值属性转换为标称属性(分类属性)
NumericToNominal toNominal = new NumericToNominal();
toNominal.setInputFormat(data);
data = Filter.useFilter(data, toNominal);继续下一步之前,还要指定待预测的属性。
// 设置类标签索引
data.setClassIndex(CLASS_INDEX);接着,剔除一个描述保单编号的属性,因为它不具有预测价值。只要简单使用Remove过滤 器即可移除。
// 移除不相关的属性(政策属性)
Remove remove = new Remove();
remove.setInputFormat(data);
remove.setOptions(new String[]{"-R", "" + POLICY_INDEX});
data = Filter.useFilter(data, remove);以上就是建模的准备工作。
纯方法
纯方法(Vanilla approach)是指直接应用第3章介绍的方法,既不需要做预处理,也不需要 考虑数据集具体细节。为了说明Vanilla方法的缺点,我们将创建一个带有默认参数的简单模型, 并且应用k折交叉验证。
首先,添加要测试的分类器:
/*
* 朴素方法(不进行数据重平衡)
*/
// 定义分类器列表
List<Classifier> models = new ArrayList<Classifier>();
models.add(new J48()); // C4.5决策树
models.add(new RandomForest()); // 随机森林
models.add(new NaiveBayes()); // 朴素贝叶斯
models.add(new AdaBoostM1()); // AdaBoost
models.add(new Logistic()); // 逻辑回归然后,创建一个Evaluation对象,通过调用crossValidate(Classifier, Instances, int, Random, String[])方法进行k折交叉验证,最后输出准确率、召回率与F值
// 创建评估对象
Evaluation eval = new Evaluation(data);
// 打印朴素方法的标题
System.out.println("Vanilla approach\n----------------");
// 对每个模型进行K折交叉验证
for (Classifier model : models) {
eval.crossValidateModel(model, data, FOLDS, new Random(1), new String[]{});
// 打印召回率、精确率和F1分数
System.out.println(model.getClass().getName() + "\n" + "\tRecall: " + eval.recall(FRAUD) + "\n" + "\tPrecision: " + eval.precision(FRAUD) + "\n" + "\tF-measure: " + eval.fMeasure(FRAUD));
}最终输出的评估分数如下
Vanilla approach
----------------
weka.classifiers.trees.J48
Recall: 0.03358613217768147
Precision: 0.9117647058823529
F-measure: 0.06478578892371996
weka.classifiers.trees.RandomForest
Recall: 0.017876489707475622
Precision: 0.9166666666666666
F-measure: 0.03506907545164719
weka.classifiers.bayes.NaiveBayes
Recall: 0.05597688696280245
Precision: 0.25162337662337664
F-measure: 0.0915805022156573
weka.classifiers.meta.AdaBoostM1
Recall: 0.04198266522210184
Precision: 0.25162337662337664
F-measure: 0.07195914577530177
weka.classifiers.functions.Logistic
Recall: 0.037486457204767065
Precision: 0.2521865889212828
F-measure: 0.06527070364082249从上面这些输出可以看到,结果并不理想。从召回率(Recall)看,所有欺诈行为中,被发 现的欺诈只占1%~3%。也就是说,只有1~3/100个欺诈能被检测到。而从准确率(Precision)来 说,报警准确率有91%。这意味着申请理赔的9/10个案例中,模型都是正确的。
数据集重整
由于相比于正例,反例(即欺诈)数目非常少,所以学习算法要与归纳推理做“斗争”。为 帮助算法解决这个问题,我们可以给它们一个数据集。该数据集中,正例与反例的比重是可比的。 也就是说,这个问题可以通过数据集重整(Dataset rebalancing)得到解决。
Weka有一个内置的过滤器Resample,用于从一个数据集随机抽选子样本,它使用重置抽样 或不重置抽样。这个过滤器也可以将一个分布调整为类均匀分布。 我们将手工实现k折交叉验证。
首先,把数据集均等地分成k折,其中第k折用作测试,其他 折用来学习。使用StratifiedRemoveFolds过滤器划分数据集,划分后的各折中仍然保持着相 同的类分布
/*
* 手工进行K折交叉验证并进行数据重平衡
*/
// 创建StratifiedRemoveFolds对象,用于分层K折交叉验证
StratifiedRemoveFolds kFold = new StratifiedRemoveFolds();
kFold.setInputFormat(data);
// 用于存储每个模型的召回率、精确率和F1分数
double measures[][] = new double[models.size()][3];
// 打印数据重平衡的标题
System.out.println("\nData rebalancing\n----------------");
// 进行K折交叉验证
for (int k = 1; k <= FOLDS; k++) {
// 将数据集分为测试集和训练集
kFold.setOptions(new String[]{"-N", "" + FOLDS, "-F", "" + k, "-S", "1"});
Instances test = Filter.useFilter(data, kFold);
kFold.setOptions(new String[]{"-N", "" + FOLDS, "-F", "" + k, "-S", "1", "-V"}); // 反向选择
Instances train = Filter.useFilter(data, kFold);
// 打印当前折的训练集和测试集大小
System.out.println("Fold " + k + "\n\ttrain: " + train.size() + "\n\ttest: " + test.size());然后,重整训练数据集,-Z参数指定要重抽样数据集的比例,-B把类分布调整成均匀分布
// 对训练集进行重采样以平衡数据
Resample resample = new Resample();
resample.setInputFormat(data);
resample.setOptions(new String[]{"-Z", "100", "-B", "1"}); // 有放回采样
Instances balancedTrain = Filter.useFilter(train, resample);接着,创建分类器并做评估。
// 遍历每个分类器
for (ListIterator<Classifier> it = models.listIterator(); it.hasNext(); ) {
Classifier model = it.next();
// 构建分类器模型
model.buildClassifier(balancedTrain);
// 创建评估对象
eval = new Evaluation(balancedTrain);
// 评估模型在测试集上的表现
eval.evaluateModel(model, test);
// 打印召回率、精确率和F1分数
System.out.println("\n\t" + model.getClass().getName() + "\n" + "\tRecall: " + eval.recall(FRAUD) + "\n" + "\tPrecision: " + eval.precision(FRAUD) + "\n" + "\tF-measure: " + eval.fMeasure(FRAUD));
// 保存结果以计算平均值
measures[it.previousIndex()][0] += eval.recall(FRAUD);
measures[it.previousIndex()][1] += eval.precision(FRAUD);
measures[it.previousIndex()][2] += eval.fMeasure(FRAUD);
}
}最后,计算平均数,输出最佳模型
// 计算每个模型的平均召回率、精确率和F1分数
for (int i = 0; i < models.size(); i++) {
measures[i][0] /= 1.0 * FOLDS;
measures[i][1] /= 1.0 * FOLDS;
measures[i][2] /= 1.0 * FOLDS;
}
// 输出结果并选择最佳模型
Classifier bestModel = null;
double bestScore = -1;
for (ListIterator<Classifier> it = models.listIterator(); it.hasNext(); ) {
Classifier model = it.next();
double fMeasure = measures[it.previousIndex()][2];
System.out.println(model.getClass().getName() + "\n" + "\tRecall: " + measures[it.previousIndex()][0] + "\n" + "\tPrecision: " + measures[it.previousIndex()][1] + "\n" + "\tF-measure: " + fMeasure);
if (fMeasure > bestScore) {
bestScore = fMeasure;
bestModel = model;
}
}
// 打印最佳模型
System.out.println("Best model: " + bestModel.getClass().getName());现在,模型性能得到显著提升,如下:
Data rebalancing
----------------
Fold 1
train: 10280
test: 5140
weka.classifiers.trees.J48
Recall: 0.4527687296416938
Precision: 0.15191256830601094
F-measure: 0.22749590834697217
weka.classifiers.trees.RandomForest
Recall: 0.14332247557003258
Precision: 0.24444444444444444
F-measure: 0.1806981519507187
weka.classifiers.bayes.NaiveBayes
Recall: 0.8110749185667753
Precision: 0.12345066931085771
F-measure: 0.2142857142857143
weka.classifiers.meta.AdaBoostM1
Recall: 0.9022801302931596
Precision: 0.11888412017167382
F-measure: 0.21008722032612817
weka.classifiers.functions.Logistic
Recall: 0.7687296416938111
Precision: 0.13280810354530106
F-measure: 0.22648752399232247
Fold 2
train: 10280
test: 5140
weka.classifiers.trees.J48
Recall: 0.4675324675324675
Precision: 0.1470888661899898
F-measure: 0.22377622377622378
weka.classifiers.trees.RandomForest
Recall: 0.13636363636363635
Precision: 0.25149700598802394
F-measure: 0.17684210526315788
weka.classifiers.bayes.NaiveBayes
Recall: 0.8441558441558441
Precision: 0.12566457225712904
F-measure: 0.21876314682372738
weka.classifiers.meta.AdaBoostM1
Recall: 0.9318181818181818
Precision: 0.12328178694158076
F-measure: 0.21775417298937788
weka.classifiers.functions.Logistic
Recall: 0.7824675324675324
Precision: 0.13693181818181818
F-measure: 0.23307543520309476
Fold 3
train: 10280
test: 5140
weka.classifiers.trees.J48
Recall: 0.40584415584415584
Precision: 0.13812154696132597
F-measure: 0.2061005770816158
weka.classifiers.trees.RandomForest
Recall: 0.1038961038961039
Precision: 0.19753086419753085
F-measure: 0.13617021276595745
weka.classifiers.bayes.NaiveBayes
Recall: 0.8376623376623377
Precision: 0.1315655277919429
F-measure: 0.22741295724988983
weka.classifiers.meta.AdaBoostM1
Recall: 0.9318181818181818
Precision: 0.12532751091703057
F-measure: 0.22093918398768284
weka.classifiers.functions.Logistic
Recall: 0.75
Precision: 0.13548387096774195
F-measure: 0.22950819672131148
weka.classifiers.trees.J48
Recall: 0.44204845100610574
Precision: 0.14570766048577555
F-measure: 0.21912423640160392
weka.classifiers.trees.RandomForest
Recall: 0.12786073860992428
Precision: 0.23115743820999976
F-measure: 0.16457015665994468
weka.classifiers.bayes.NaiveBayes
Recall: 0.8309643667949856
Precision: 0.12689358978664322
F-measure: 0.2201539394531105
weka.classifiers.meta.AdaBoostM1
Recall: 0.9219721646431743
Precision: 0.12249780601009504
F-measure: 0.21626019243439631
weka.classifiers.functions.Logistic
Recall: 0.7670657247204478
Precision: 0.13507459756495374
F-measure: 0.22969038530557626
Best model: weka.classifiers.functions.Logistic
Class transformation time: 0.0243242s for 692 classes or 3.5150578034682084E-5s per class
从上述结果可以看到,所有模型的得分都有了显著提高,比如最佳模型——逻辑回归,它发 现欺诈的准确率达到了76%;而误报率相对合理,被标记为“欺诈”的索赔中,只有13%是真正 的欺诈。如果“漏掉一个坏人”(未检测到欺诈行为)所付出的代价要比“误杀一个好人”(欺诈 误报)的代价大得多,那么“宁可误杀也不错放”就是理所应当的了。
模型的整体性能可能还有一些提升空间,比如我们可以做属性选择与特征生成,并且应用更 复杂的模型学习,相关内容已经在第3章讲解过。
完整代码
public class Fraud {
public static void main(String[] args) throws Exception {
// 获取CSV文件的路径
String filePath = ClassUtils.getDefaultClassLoader().getResource("data/test07/claims.csv").getPath();
// 创建CSVLoader对象,用于加载CSV文件
CSVLoader loader = new CSVLoader();
// 设置CSV文件的分隔符为逗号
loader.setFieldSeparator(",");
// 将文件路径设置为CSVLoader的输入源
loader.setSource(new File(filePath));
// 使用CSVLoader加载数据并将其转换为Weka的Instances对象
Instances data = loader.getDataSet();
/*
* 配置数据集
*/
// 定义属性索引
int CLASS_INDEX = 15; // 类标签的索引(欺诈类别)
int POLICY_INDEX = 17; // 政策属性的索引(不相关)
int NO_FRAUD = 0, FRAUD = 1; // 欺诈类别的标签值
int FOLDS = 3; // K折交叉验证的折数
// 将所有数值属性转换为标称属性(分类属性)
NumericToNominal toNominal = new NumericToNominal();
toNominal.setInputFormat(data);
data = Filter.useFilter(data, toNominal);
// 设置类标签索引
data.setClassIndex(CLASS_INDEX);
// 移除不相关的属性(政策属性)
Remove remove = new Remove();
remove.setInputFormat(data);
remove.setOptions(new String[]{"-R", "" + POLICY_INDEX});
data = Filter.useFilter(data, remove);
// 打印数据集的摘要信息
System.out.println(data.toSummaryString());
// 打印类标签的统计信息
System.out.println("Class attribute:\n" + data.attributeStats(data.classIndex()));
/*
* 朴素方法(不进行数据重平衡)
*/
// 定义分类器列表
List<Classifier> models = new ArrayList<Classifier>();
models.add(new J48()); // C4.5决策树
models.add(new RandomForest()); // 随机森林
models.add(new NaiveBayes()); // 朴素贝叶斯
models.add(new AdaBoostM1()); // AdaBoost
models.add(new Logistic()); // 逻辑回归
// 创建评估对象
Evaluation eval = new Evaluation(data);
// 打印朴素方法的标题
System.out.println("Vanilla approach\n----------------");
// 对每个模型进行K折交叉验证
for (Classifier model : models) {
eval.crossValidateModel(model, data, FOLDS, new Random(1), new String[]{});
// 打印召回率、精确率和F1分数
System.out.println(model.getClass().getName() + "\n" + "\tRecall: " + eval.recall(FRAUD) + "\n" + "\tPrecision: " + eval.precision(FRAUD) + "\n" + "\tF-measure: " + eval.fMeasure(FRAUD));
}
/*
* 手工进行K折交叉验证并进行数据重平衡
*/
// 创建StratifiedRemoveFolds对象,用于分层K折交叉验证
StratifiedRemoveFolds kFold = new StratifiedRemoveFolds();
kFold.setInputFormat(data);
// 用于存储每个模型的召回率、精确率和F1分数
double measures[][] = new double[models.size()][3];
// 打印数据重平衡的标题
System.out.println("\nData rebalancing\n----------------");
// 进行K折交叉验证
for (int k = 1; k <= FOLDS; k++) {
// 将数据集分为测试集和训练集
kFold.setOptions(new String[]{"-N", "" + FOLDS, "-F", "" + k, "-S", "1"});
Instances test = Filter.useFilter(data, kFold);
kFold.setOptions(new String[]{"-N", "" + FOLDS, "-F", "" + k, "-S", "1", "-V"}); // 反向选择
Instances train = Filter.useFilter(data, kFold);
// 打印当前折的训练集和测试集大小
System.out.println("Fold " + k + "\n\ttrain: " + train.size() + "\n\ttest: " + test.size());
// 对训练集进行重采样以平衡数据
Resample resample = new Resample();
resample.setInputFormat(data);
resample.setOptions(new String[]{"-Z", "100", "-B", "1"}); // 有放回采样
Instances balancedTrain = Filter.useFilter(train, resample);
// 遍历每个分类器
for (ListIterator<Classifier> it = models.listIterator(); it.hasNext(); ) {
Classifier model = it.next();
// 构建分类器模型
model.buildClassifier(balancedTrain);
// 创建评估对象
eval = new Evaluation(balancedTrain);
// 评估模型在测试集上的表现
eval.evaluateModel(model, test);
// 打印召回率、精确率和F1分数
System.out.println("\n\t" + model.getClass().getName() + "\n" + "\tRecall: " + eval.recall(FRAUD) + "\n" + "\tPrecision: " + eval.precision(FRAUD) + "\n" + "\tF-measure: " + eval.fMeasure(FRAUD));
// 保存结果以计算平均值
measures[it.previousIndex()][0] += eval.recall(FRAUD);
measures[it.previousIndex()][1] += eval.precision(FRAUD);
measures[it.previousIndex()][2] += eval.fMeasure(FRAUD);
}
}
// 计算每个模型的平均召回率、精确率和F1分数
for (int i = 0; i < models.size(); i++) {
measures[i][0] /= 1.0 * FOLDS;
measures[i][1] /= 1.0 * FOLDS;
measures[i][2] /= 1.0 * FOLDS;
}
// 输出结果并选择最佳模型
Classifier bestModel = null;
double bestScore = -1;
for (ListIterator<Classifier> it = models.listIterator(); it.hasNext(); ) {
Classifier model = it.next();
double fMeasure = measures[it.previousIndex()][2];
System.out.println(model.getClass().getName() + "\n" + "\tRecall: " + measures[it.previousIndex()][0] + "\n" + "\tPrecision: " + measures[it.previousIndex()][1] + "\n" + "\tF-measure: " + fMeasure);
if (fMeasure > bestScore) {
bestScore = fMeasure;
bestModel = model;
}
}
// 打印最佳模型
System.out.println("Best model: " + bestModel.getClass().getName());
// ... 使用所有可用的(重采样)数据构建最佳模型
}
}

















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











