






标题 CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks
Abstract
文章发表于2022年,由于当时已经有很多人注意到nlp与robot结合,只不过没有一个好的评判标准。所以作者提出了一个benchmark,说是第一个公开的结合了自然语言控制、高维多模态输入、7自由度的机械臂控制以及长视野的机器人操纵。
他们用了之前的多情景模仿学习(MCIL)模型作为baseline,认为其对有目标导向的任务有较好的效果,但是在他们的长视野任务中表现并不理想,或许引入强化学习也会有一个不错的结果。
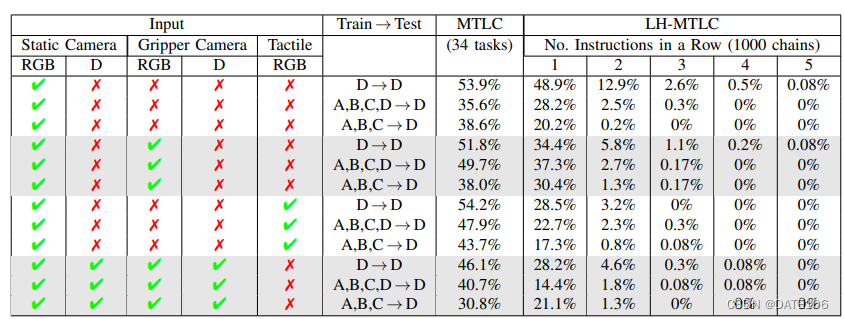
下面是他们对MCIL的评测结果:
Discussion
这个工作是2022年的,在当时或许不错,但放在今天而言满大街的benchmark来说也只是普通的工作了。

















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









