







前言
一年多前,OpenAI重塑了聊天机器人,彻底推动大模型技术的突飞猛进
一个月前,OpenAI又重塑了视频生成
当sora的热度还在持续时,没想到OpenAI在机器人领域也出手了,和Figure联合打造的人形机器人,边与人类自然流畅对话、边干活(给人类苹果、整理桌面)
如此,现在大模型机器人的发展有三个攻克点
- 一个是模仿学习,以斯坦福的mobile aloha、UMI为代表
- 一个是预训练 + RL,以CMU 18万机器人为代表
- 一个则是基于VLM的工作——也是后来25年3.12日在解读ViLLA的过程中,发现可以把基于VLM的工作分成两个方面
一方面,微调VLM使之成为robotic VLM或VLA
二方面,不微调直接提示VLM做顶层任务规划,当然 机器人执行动作的过程中加约束,比如从SayCan、VoxPoser到ViLA、CoPa、ReKep为代表
至于Google机器人相关的工作很重要,故后续把本部分独立成文了
详见:Google视觉机器人超级汇总:从RT、RT-2到AutoRT/SARA-RT/RT-Trajectory、RT-H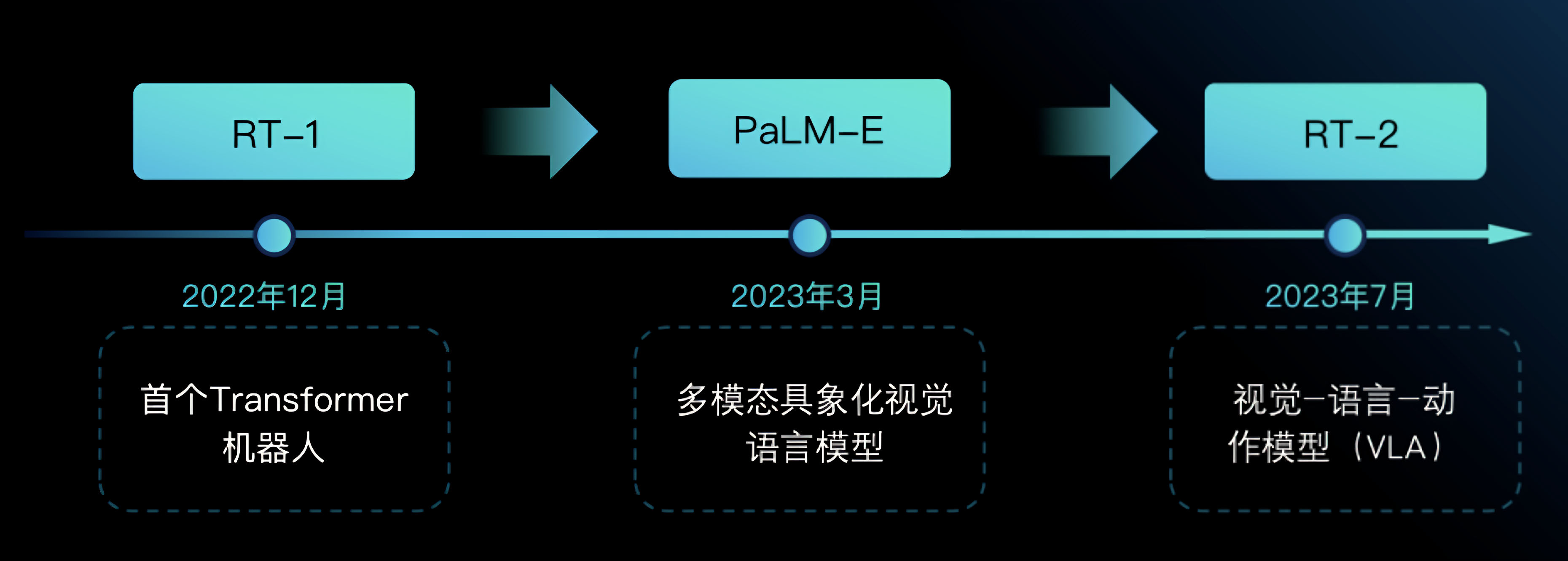
本文则重点介绍第三个攻克点中的「不微调直接提示VLM做顶层任务规划」
后为聚焦起见,也为让各篇文章的主题和定位更加清晰明确,故对本文做了如下调整
- 把原属于本文第三部分的RoboFlamingo
移动到代表另一条路线的此文:机器人大小脑的融合——从微调VLM到VLM+动作专家的VLA:详解RoboFlamingo、Octo、TinyVLA、DexVLA- 把原属于本文第五部分的OK-Robot
移动到此文:以Mobile ALOHA为代表的模仿学习的爆发:从Dobb·E、Gello到ALOHA、OK-Robot、UMI、DexCap、伯克利FMB- 把原属于本文第六部分的Figure 01
移动到此文:Helix——Figure 02发布的通用人形机器人控制VLA:不用微调即可做多个任务的快与慢双系统,让两个机器人协作干活(含清华HiRT详解)
再后来,25年3月底,补充了对本文一部分SayCan的解读,原因在于落地越深,对模型中的一切细节便会抠的越细,比如π0有用到saycan做策略辅助,于是在下文第一部分解读了下 这个saycan
第一部分 SayCan:基于LLM 先规划,然后通过RL约束做执行
1.1 整体理解:SayCan的提出与相关工作
1.1.1 SayCan的提出背景
虽然这两年,chatgpt带动的大模型异常火热、技术更新日新月异,但其实早在2020年,GPT3为代表的便已经证明了语言模型的巨大潜力「比如Transformers [2]、BERT [3]、T5 [4]、GPT-3 [5]、Gopher [6]、LAMDA [7]、FLAN [8] 和PaLM [9],它们展现了越来越大的容量(数十亿参数和数万亿字节的文本)以及随之而来的跨任务泛化能力」,能写邮件、新闻、简单代码
然在20-22年那几年期间,语言模型的一个显著弱点是它们缺乏实际的现实经验,这使得在特定的实体中利用它们进行决策变得困难。例如下图,当要求语言模型给一杯饮料时,它可能只是产生一个合理的叙述,但它可能不适用于需要在特定环境中执行此任务的特定代理
22年4月份,来自Robotics at Google、Everyday Robots的研究者们推出SayCan
- 其对应的论文为《Do As I Can, Not As I Say: Grounding Language in Robotic Affordances》
- 其对应的项目地址为:say-can.github.io
他们建议通过预训练技能提供现实世界的基础,这些技能用于约束模型提出既可行又符合上下文的自然语言动作。机器人可以作为语言模型的“手和眼”,而语言模型提供关于任务的高级语义知识
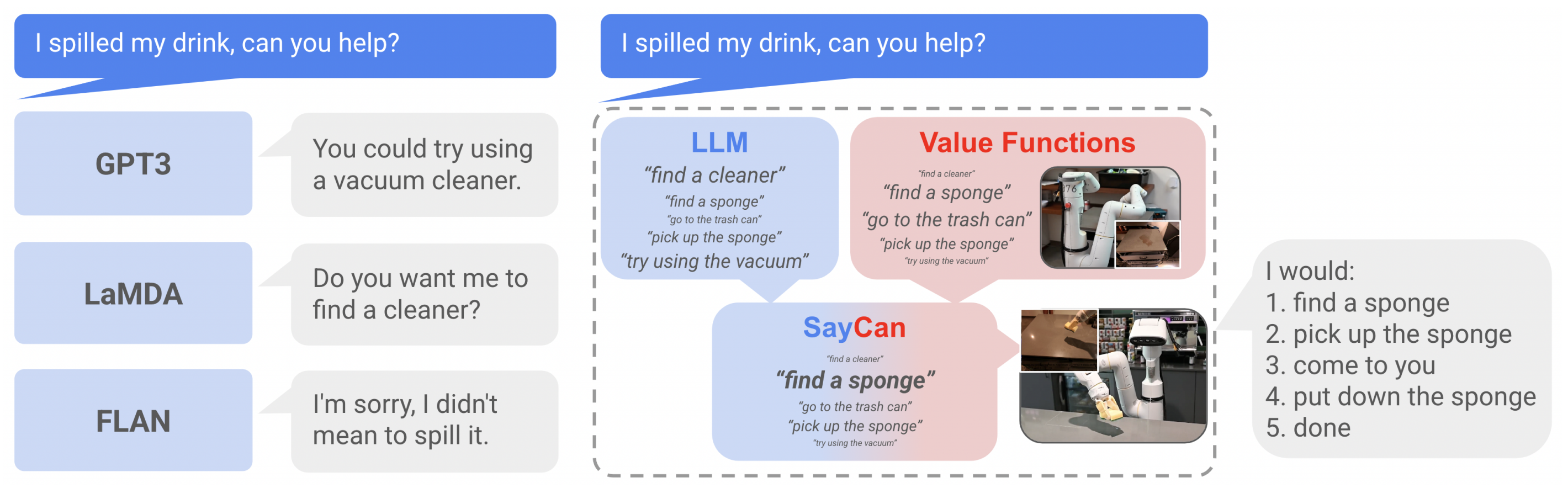
再比如,我把饮料洒了,你能帮忙吗?
- 语言模型可能会给出一个合理但对机器人不可行或无用的叙述。“你可以试试用吸尘器”在没有吸尘器或机器人无法使用吸尘器的情况下是不可能实现的
- 通过prompt工程,LLM可能能够将高层次的指令分解为子任务,但在不了解机器人能力及其当前状态和环境的上下文的情况下,它无法做到这一点
受到这个例子的启发,他们研究了如何提取大语言模型(LLM)的知识以使一个具身智能体(例如机器人)能够遵循高级文本指令的问题
- 机器人配备了一套“原子”行为的学习技能,这些技能能够进行低级的视觉运动控制。其利用了这样一个事实:除了让LLM简单地解释指令之外,他们还可以使用它来评估某个单独技能在完成高级指令方面取得进展的可能性
- 然后,如果每个技能都有一个可量化其从当前状态成功的可能性的可供性函数affordance function(例如一个学习到的价值函数),则其值可以用来加权技能的可能性
通过这种方式,LLM描述了每项技能对完成指令的贡献概率(相当于技能组合),而能力函数则描述了每项技能成功的概率——将两者结合起来,就能得出每项技能成功执行指令的概率
In this way, the LLM describes the probability that each skill contributes to completing the instruction, and the affordance function describes the probability that each skill will succeed – combining the two provides the probability that each skill will perform theinstruction successfully.
相当于当主帅要攻取某座城池时,会先筛选目前有哪几个方法可用,以及每个方法对攻取该座城池有用的概率分别是多少——比如55% 75% 95%
最后再看每个可选的方法能成功施展出来的概率又是多少——比如90% 60% 30%
这个也好理解,比如大炮威力大、对攻城很有用 高达95%,但有时可能不一定能成功发射,比如连连哑炮,成功发射的概率只有30%..
可供性函数使LLM能够感知当前场景,而将补全内容限制在技能描述中则使大语言模型了解机器人的能力。此外,这种组合产生了一个完全可解释的步骤序列,机器人将通过这些步骤来完成指令——一个通过语言表达的可解释计划
SayCan,在物理任务中提取和利用了LLM(大语言模型)中的知识
- LLM(Say)提供了任务基础,用于确定高层目标的有用操作
- 而学习的可行性函数(Can)提供了世界基础,用于确定计划中可以执行的内容
具体则可以使用RL作为一种方法来学习语言条件的价值函数,这些函数提供了世界中可能的可行性
对于后者,目标是预测由语言指令给出的某项技能在当前状态下是否可行。他们使用基于时间差分(TD)的强化学习来实现这一目标
- 具体来说,定义一个马尔可夫决策过程MDP
其中S 和A 分别是状态空间和动作空间
是状态转移概率函数
是奖励函数
γ 是折扣因子- TD 方法的目标是学习状态或状态-动作值函数Q 函数:
,它表示从状态s 和动作a 开始后,在策略π 生成的动作下,奖励的折现和,即
Q 函数
其中D 是状态和动作的数据集,θ 是Q 函数的参数- 值得注意的是,在无折扣的稀疏奖励场景中,agent在成功完成任务时在剧集结束时获得1.0的奖励,否则为0.0,通过强化学习训练的价值函数对应于一种可行性函数[10],该函数指定在给定状态下某技能是否可能
如果某部分读者对RL还不够了解,可以阅读本博客里的:RL极简入门
最终对于这个例子而言,即“我洒了一些东西,你能帮忙吗?”
- 一个没有实质基础的语言模型可能会回答诸如“我可以叫清洁工”或“我可以为你吸尘”之类的内容,但考虑到机器人,这些回答是不合理的
- 而PaLM-SayCan的响应是“我会:1. 找到海绵,2. 拿起海绵,3. 带给你,4. 完成”,并且能够在真实厨房中的机器人上执行这个序列。这需要对所需顺序的长远推理,对指令的抽象理解,以及对环境和机器人的能力的知识
1.1.2 相关工作
类似的工作包括以下三大方面
第一方面,使语言模型具备基础能力
- 大量研究集中于使语言具有基础能力[28,29]。最近的研究探讨了如何通过训练语言模型接受额外的环境输入[30,31,32,33,34]或直接输出动作[35,36,37]来使现代语言模型具备基础能力。其他研究通过提示工程在环境中实现语言基础能力[24]
- 与SayCan同时,Huang等人[23]使用提示工程提取时间扩展计划,但没有任何额外机制来确保基础能力,大致相当于我们实验中的“生成”基线。上述方法都未与物理环境交互进行训练,因此限制了它们对具身交互进行推理的能力
- 一种通过交互使语言模型具备基础能力的方法是通过预训练的LLM表示学习下游网络[38,22,21,39,40,41,42,43]。另一种方法是使用交互数据(如奖励或交互排名反馈)微调语言模型[11,44,45]
而SayCan能够通过先前训练的价值函数使语言模型在给定环境中具备基础能力,从而以零样本的方式实现通用的长时间行为,即无需额外训练
第二方面,学习语言条件行为
- 研究如何将语言与行为相结合的历史悠久[46,47,48,49,50]。许多之前的工作已经通过模仿学习[51,22,20,13,26,37]或强化学习[52,53,49,54,55,56,21,41]学习了语言条件行为
这些先前的工作大多集中在遵循低级指令,如抓取和放置任务以及其他机器人操作原语[20,22,56,21,13,26],尽管一些方法解决了模拟环境中的长远、复杂任务[57,58,54]。与这些后者的工作类似,SayCan专注于完成时间上扩展的任务 - 且,SayCan工作的一个核心方面是通过提取和利用大型语言模型中的知识来解决此类任务。虽然之前的工作研究了预训练语言嵌入如何改进对新指令[38,22,21]和新低级任务[13]的泛化,但他们通过将其与机器人的可供性相结合,从LLM中提取了更多实质性的知识。这使得机器人能够利用语言模型进行规划
第三方面,任务规划与运动规划
- 任务和运动规划[59, 60]是一个将任务排序以解决高层次问题的问题,同时要确保在给定的实体条件下具有可行性(任务规划[61, 62, 63];运动规划[64])
- 传统上,这个问题通过符号规划[61,63]或优化[65,66]来解决,但这些方法需要显式的原语和约束
最近,机器学习被应用于实现抽象任务规范,允许通用原语,或放松约束[67,68,69,70,71,72,73,74,75,76,77,78]
其他研究致力于学习分层地解决此类长时间范围的问题[79,80,12,81,54] - SayCan利用了LLM对世界的语义知识来解释指令和理解如何执行它们。使用LLM和学习的低级策略的通用性使得能够实现有效扩展到现实世界的长时间范围、抽象任务
1.2 深入细节:SayCan——做我能做的,而不是我说的
1.2.1 问题陈述
首先,SayCan接收用户提供的自然语言指令 ,该指令描述了机器人应执行的任务,指令可能是冗长的、抽象的或模糊的
- 假设给定了一组技能
,其中每个技能
执行一个简短的任务,例如拾取特定的物体,并附带一个简短的语言描述
(例如,“ 找到一个海绵”)——相当于对任务的进一步简短描述
,即技能的文本标签是用户指令的有效下一步的概率
换言之,一个成功的技能以概率上取得进展,而一个失败的技能取得进展的概率为零
简言之,给定指令下的对应技能的概率
This corresponds to multiplying the probability of the language description of the skill given the instruction p(ℓπ|i),which we refer to as task-grounding - 和一个可供性函数affordance function
,该函数表示从状态
开始,成功完成带有描述
相当于是一个伯努利随机变量
直观地说,
在强化学习术语中,
简言之,该技能在当前世界状态下可行的概率
and the probability of the skill being possible in the current state of the world p(cπ|s, ℓπ), which we refer to as world-grounding - 最终,咱们感兴趣的便是某一给定技能在实际完成指令方面成功取得进展的概率,将其表示为
相当于把以上第二点的
流程上来说
- 他们使用强化学习作为一种方法,学习个别技能的价值函数,这些价值函数提供了世界中可能的操作能力
- 然后使用这些技能的文本标签作为潜在的响应,由语言模型进行评分
这种结合产生了一种协同关系,其中技能及其价值函数可以作为语言模型的“手和眼”,而语言模型则提供关于如何完成任务的高级语义知识
1.2.2 将LLM连接到机器人:LLM 提供的某项技能对高级指令有用的概率
尽管大型语言模型可以从大量文本中学习到丰富的知识,但它们不一定会将高级命令分解为适合机器人执行的低级指令
- 如果问一个语言模型“机器人如何给我拿一个苹果”,它可能会回答“机器人可以去附近的商店为你购买一个苹果”
- 尽管这个回答对于提示是一个合理的完成,但对于一个具体现身的代理来说,它可能并不具备可操作性,因为agent的能力可能是有限且固定的
因此,为了使语言模型适应我们的问题陈述,必须以某种方式告知它们,比如将高级指令分解为一系列可用的低级技能
- 一种方法是精心设计提示(prompt engineering)[5,11],这是一种引导语言模型产生特定响应结构的技术。prompt工程在上下文文本(“提示”)中提供示例,指定任务和响应结构,模型将模仿这些结构;本文使用的提示在附录D.3中展示,并附有消融实验
- 然而,这还不足以完全将输出约束为适合具体代理的可接受的原始技能,实际上有时它可能会产生不可接受的动作或难以解析为单个步骤的语言
为语言模型评分通过输出语言模型分配给固定输出的概率,为受限response开辟了一条途径。语言模型表示了潜在完成的分布,其中
是出现在文本中第
个位置的一个单词
虽然典型的生成应用(例如,会话代理)会从该分布中采样或解码最大似然完成,但也可以使用模型对从一组选项中选择的候选完成进行评分
- 在SayCan 中,形式化地,给定一组低级技能
和一个指令
对执行指令
- 之后,根据语言模型的最优技能通过公式
计算出来
一旦选择了技能,过程会继续通过迭代选择技能并将其添加到指令中
- 在实际应用中,他们将规划结构化为用户与机器人之间的对话,其中用户提供高级指令(例如,“你会如何给我拿一个可乐罐?”),而语言模型则以明确的序列响应(例如,“我会:1. ℓπ”,例如,“我会:1. 找到一个可乐罐,2. 拿起可乐罐,3. 把它带给你”)
- 这具有可解释性的额外好处,因为模型不仅输出生成式响应,还提供了对许多可能响应的可能性的概念
下图图3(以及附录图12更详细地展示)显示了将LLM强制到语言模式中的过程,其中任务合Combined是低级策略所能执行的技能,而提示工程prompt examples展示了计划示例以及用户和机器人的对话
Figure 3 (and Appendix Figure 12 in more detail) shows this process of forcing the LLM into a language pattern, where the set of tasksare the skills the low-level policy is capable of and prompt engineering shows plan examples anddialog between the user and the robot
- 通过这种方法,能够有效地从语言模型中提取知识,但这留下了一个主要问题:虽然以这种方式获得的指令解码总是由机器人可用的技能组成,这些技能可能不一定适合在机器人当前的特定情境中执行所需的高级任务
例如,如果我让机器人“给我拿一个苹果”,如果视野中没有苹果,或者它手上已经有一个苹果,那么最佳的技能集合会发生变化
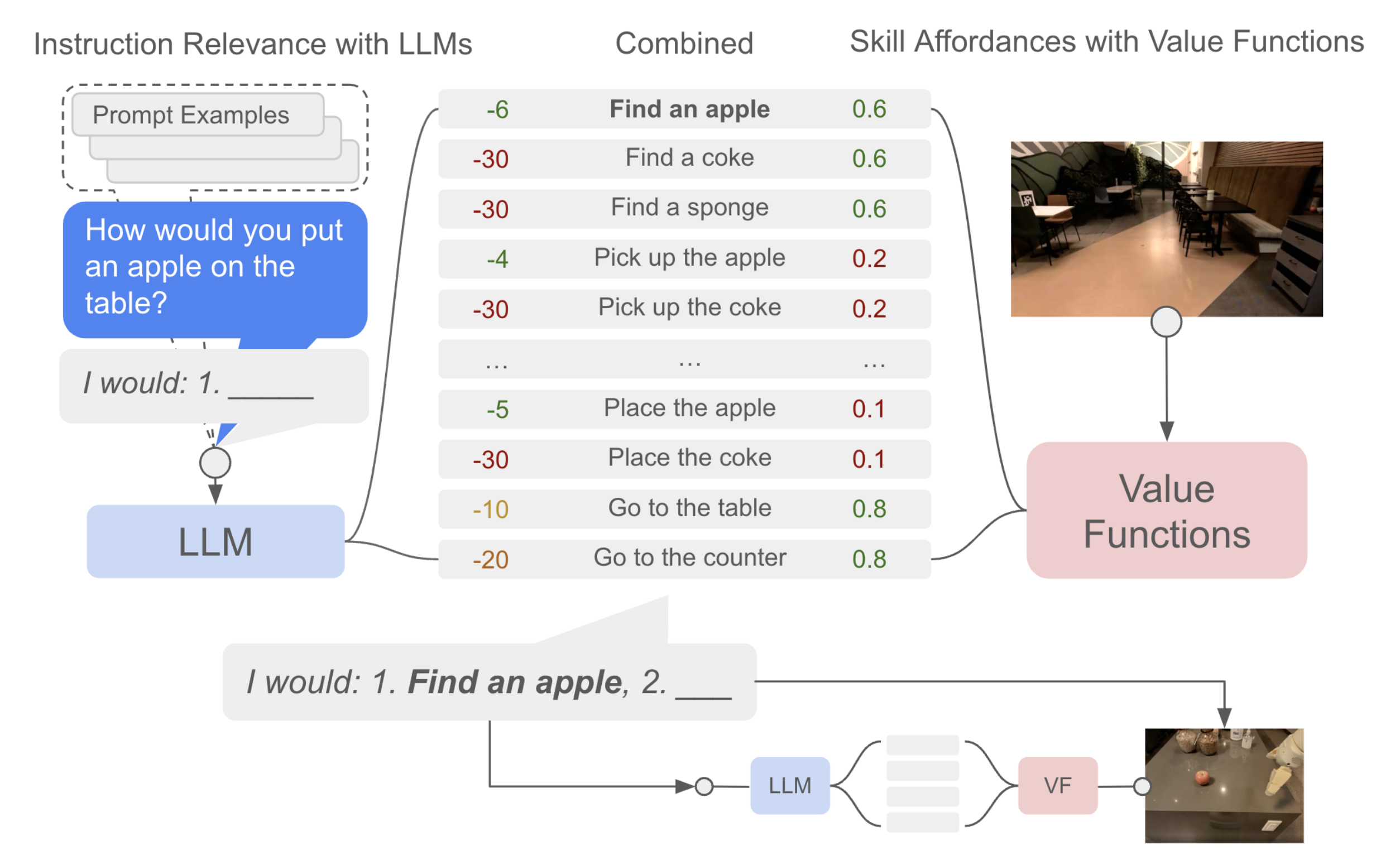
1.2.3 SayCan的本质:LLM给定技能组合后,可供性提供成功执行每个技能的概率
SayCan 的核心思想是通过价值函数——一种捕获特定技能在当前状态下成功可能性的对数似然的可操作性函数——来为大型语言模型提供基础
- 而大模型给定一个技能
,从而构建了一个可供性空间
该价值函数空间捕获了所有技能的可供性[12],见下图图2
- 对于每个技能,可供性函数和LLM 概率随后相乘,最终选择最可能的技能,即
「Ror each skill, the affordance function andthe LLM probability are then multiplied together and ultimately the most probable skill is selected,i.e. π = arg maxπ∈Π p(cπ|s, ℓπ)p(ℓπ|i).」一旦技能被选择,agent执行相应的策略,并修改LLM 查询以包含
总结一下,该过程如图3 所示,并在算法1 中描述
- 即当给定一个高级指令,SayCan 会将来自LLM的概率(某项技能对指令有用的概率)与来自价值函数的概率(成功执行该技能的概率)相结合,以选择要执行的技能。这会输出一个既可行又有用的技能
- 通过将技能附加到响应中并再次查询模型,此过程会重复进行,直到输出步骤为终止
相当于一旦完成了某个操作,则随时更新待执行列表
总之,这两个镜像过程共同导致了SayCan 的概率解释
- 其中LLM 提供了某个技能对高级指令有用的概率
- 而可供性提供了成功执行每个技能的概率
将这两个概率结合在一起,提供了一个该技能促进用户命令的高级指令执行的概率
1.3 实例化SayCan:在机器人系统中实现SayCan
1.3.1 语言条件的机器人控制策略
为了实例化SayCan,必须为其提供一组技能,每个技能都有一个策略、一个价值函数和一个简短的语言描述(例如,“拿起罐子”)。这些技能、价值函数和描述可以通过多种不同的方式获得
- 在他们的实现中,他们通过基于图像的行为克隆(遵循BC-Z方法[13])或强化学习(遵循MT-Opt[14])来训练个体技能
无论技能的策略是如何获得的,他们都利用通过TD备份训练的价值函数作为该技能的可行性模型 - 尽管他们发现BC策略在他们当前的数据收集阶段实现了更高的成功率,但RL策略提供的价值函数作为将控制能力翻译为场景语义理解的抽象是至关重要的
为了降低训练许多技能的成本,他们分别利用了多任务BC和多任务RL,在这种情况下,他们不是为每项技能训练单独的策略和价值函数,而是训练基于语言描述条件的多任务策略和模型 - 需要注意的是为了使策略依赖于语言,他们使用了一个预训练的大型句子编码器语言模型[15]
然后在训练期间冻结语言模型参数,并通过传入每种技能的文本描述生成嵌入。这些文本嵌入被用作策略和价值函数的输入,以指定应执行哪种技能(有关所用架构的详细信息,请参见附录C.1)
由于用于生成文本嵌入的语言模型不一定与用于规划的语言模型相同,SayCan能够很好地利用适合于不同抽象级别的语言模型——从理解涉及许多技能的规划到更细致地表达具体技能
1.3.2 训练低级技能
他们使用行为克隆(BC)和强化学习(RL)策略训练程序分别获取语言条件策略和价值函数。为了完整描述我们考虑的底层马尔可夫决策过程(MDP),他们提供了奖励函数以及策略和价值函数使用的技能规范
如前所述,对于技能规范,使用一组短的自然语言描述,这些描述以语言模型嵌入的形式表示。且使用稀疏奖励函数,在一个回合结束时,如果语言指令被成功执行,则奖励值为1.0,否则为0.0
语言指令执行的成功由人类评估,评估人员会观看机器人执行技能的视频以及给定的指令。如果三位评估人员中有两位同意技能完成成功,则该回合被标记为正向奖励
- 为了在实际环境中大规模学习语言条件的行为克隆(BC)策略,他们基于 BC-Z [13] 并使用类似的策略网络架构,如下图图 10 所示
BC模型使用了类似于BC-Z [13]的架构(参见图10中的网络图)。语言指令通过通用句子编码器[15]嵌入,然后用于FiLM条件化基于Resnet-18的架构。与RL模型不同,他们没有提供先前的动作或抓手高度,因为这对于学习策略来说并不是必要的。多个全连接层应用于最终的视觉特征,以输出每个动作组件(手臂位置、手臂方向、抓手和终止动作)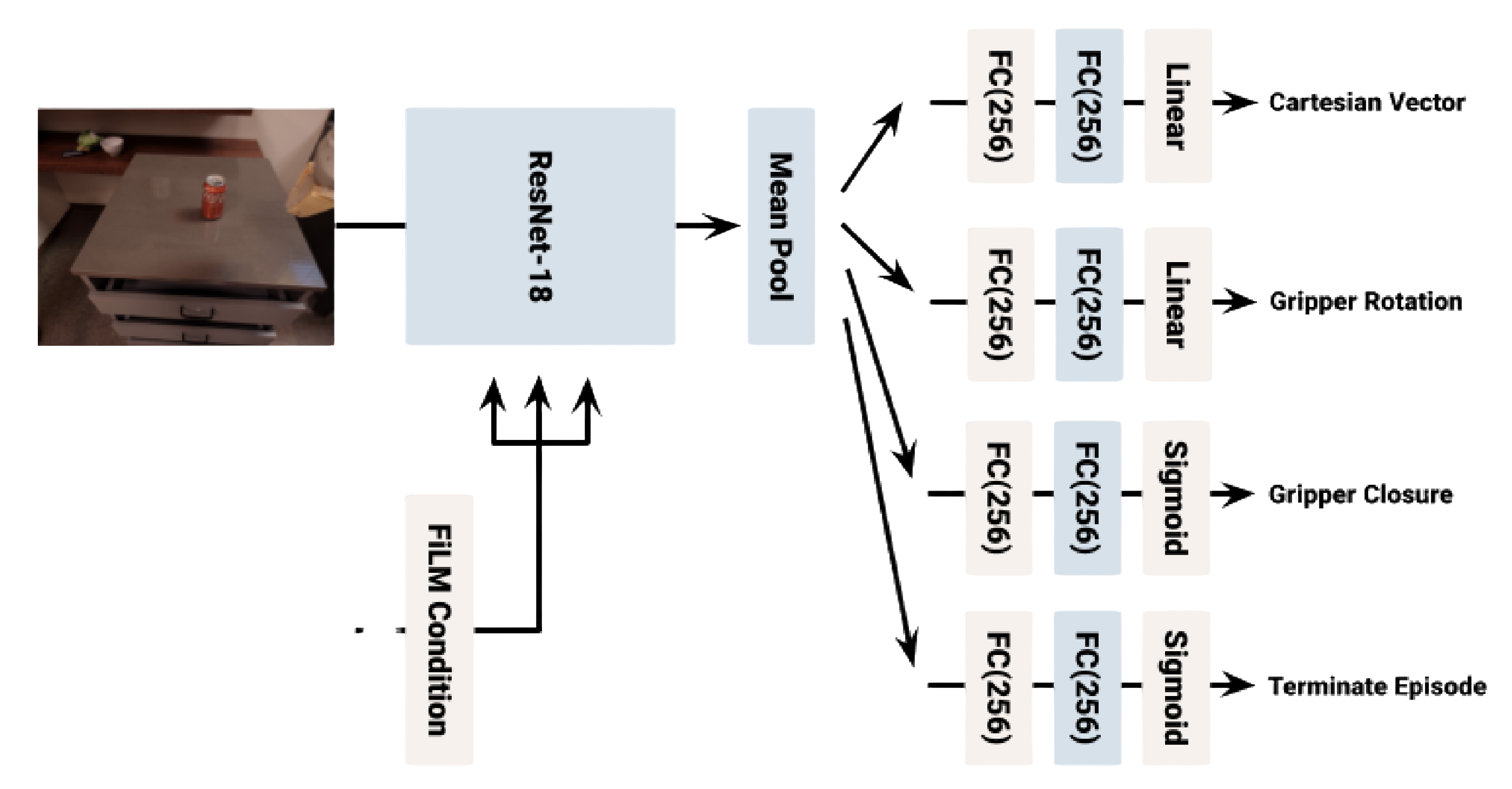
在BC 训练上,他们使用了 68000 个通过远程操作收集的演示,这些演示是在 11个月 的过程中收集的
- 使用一个由10个机器人组成的车队进行数月的操作。操作员使用VR头戴式控制器跟踪他们手部的运动,然后将其映射到机器人末端执行器的姿态上。操作员还可以使用操纵杆移动机器人的底座
- 通过276000个自主学习策略的演示数据集扩展了数据集,这些数据后来经过成功筛选并包含在行为克隆(BC)训练中,增加了12000个成功的片段
- 为了进一步处理数据,他们还要求评估员将片段标记为不安全(例如,机器人与环境发生碰撞)、不理想(例如,机器人干扰了与技能无关的物体)或不可行(例如,该技能无法完成或已经完成)
如果满足任何这些条件,则从训练中排除该片段
- 为了学习语言条件的强化学习(RL)策略,他们在Everyday Robots 模拟器中使用 MT-Opt [14] 和 RetinaGAN 模拟到实际的迁移 [16]
且通过利用模拟演示来提供初始成功来引导模拟策略的性能,然后通过在线不断改进强化学习性能
且在数据收集上
他们使用了类似于MT-Opt的网络架构,如下图图9所示
他们策略的动作空间包括末端执行器姿态的六个自由度,以及夹持器的打开和关闭命令、机器人移动基座的x-y位置和偏航方向变化量,以及终止动作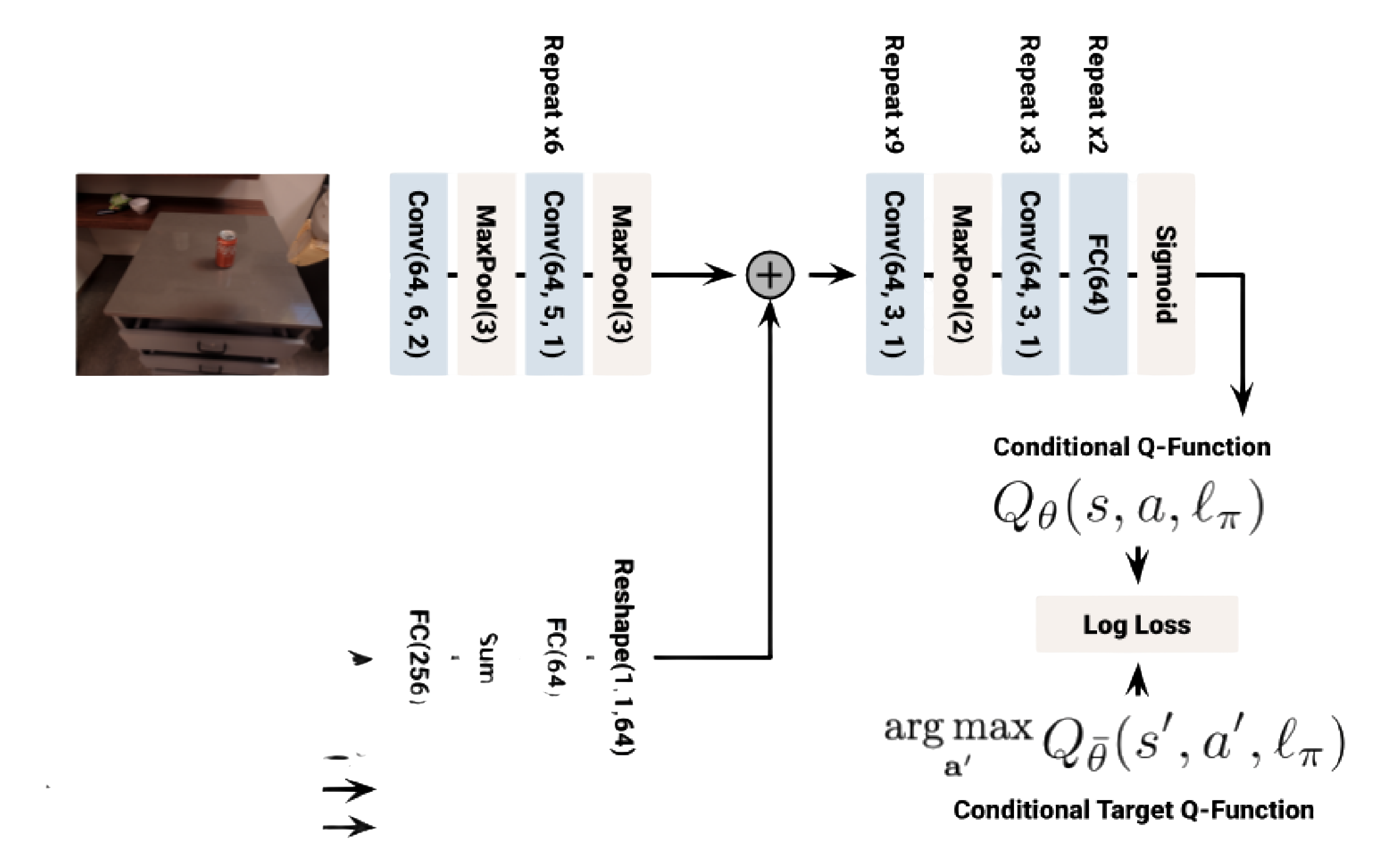
其中,语言指令由LLM嵌入,然后与机器人动作和状态的非图像部分(例如夹持器高度)连接起来。为了支持异步控制,在机器人仍在执行上一个动作时进行推理。模型被告知上一个动作还有多少未完成的部分[87]。条件输入通过全连接层,然后在空间上平铺并添加到卷积体积中,再通过另外11个卷积层。输出通过sigmoid门控,因此Q值始终在[0,1]范围内
RL模型使用16个TPUv3芯片训练约100小时,并使用一个由3000个CPU工作节点组成的池子来收集训练情节数据,另一个3000个CPU工作节点池计算目标Q值
- 在TPU之外计算目标Q值使得TPU可以专注于计算梯度更新。情节奖励是稀疏的,总是0或1,因此Q函数使用对数损失进行更新
- 模型使用优先经验回放[88]进行训练,其中调整了情节优先级以使每项技能的回放缓冲区训练数据接近50%的成功率
情节被按照其优先级按比例采样,优先级定义为 1 + 10· |p−0.5|,其中 p 是重放缓冲区中剧集的平均成功率
1.3.3 机器人系统与技能
对于控制策略,他们研究了使用移动操作机器人进行操控和导航技能的多样化集合。受厨房环境中常见技能的启发,他们提出了涵盖七个技能类别和17种对象的551种技能,这些技能包括拾取、放置和重新排列物体,打开和关闭抽屉,导航到不同位置,以及将物体放置在特定配置中
在本研究中,他们利用了那些通过组合和规划更适合复杂行为的技能,以及那些在当前数据收集阶段表现优异的技能;更多详细信息,请参见附录D
1.4 一系列实验
1.4.1 实验设置:使用的LLM是540B PaLM
他们在一个移动操作机器人和一组对象操作与导航技能中评估SayCan,实验环境包括两个办公室厨房。下图图4展示了环境设置和机器人

- 他们使用了办公室厨房中常见的15个物体和5个具有语义意义的已知位置(两个柜台、一张桌子、一个垃圾桶和用户位置)
- 且在两个环境中测试了他们的方法:一个真实的办公室厨房和一个模拟厨房环境(也是机器人技能训练的环境)
- 使用的机器人是来自Everyday Robots的移动操作机器人,配备一个7自由度的机械臂和一个双指抓手
- 使用的LLM是540B PaLM[9],除非另有说明用于LLM对比实验。我们将使用PaLM的SayCan称为PaLM-SayCan
下图图6展示了PaLM-SayCan的决策过程及其可解释性。通过可视化算法两部分的输出,用户可以理解其解决指令的决策过程

1.4.2 消融价值函数
表2说明了可供性基础的重要性,可以看出来
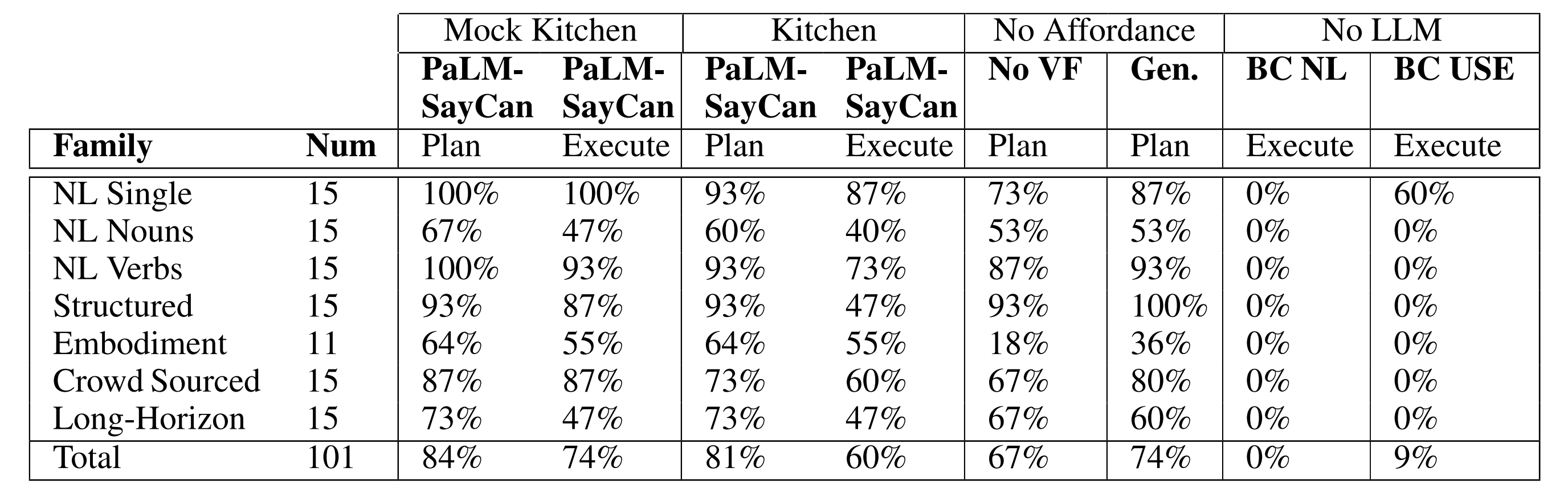
- 在训练环境中,PaLM-SayCan的整体规划成功率为84%,整体执行成功率为74%
而在实际厨房环境中,其整体的规划成功率为81%,整体的执行成功率为60% - No V使用来自LLM的最高得分技能
Generative (Gen.)使用生成式LLM,然后通过USE嵌入投影到最近的技能 - BC NL使用基于自然语言指令的策略
BC USE使用基于自然语言指令并通过USE嵌入投影到最近技能的策略
总之,他们将PaLM-SayCan与以下两种方法进行比较:
- No VF,即去除价值函数基础(即选择最大语言分数的技能)
- Generative,即使用LLM的生成输出,并通过USE嵌入将每个计划技能投影到其最大余弦相似度技能
后者实际上与[23-Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents]进行比较,它失去了明确的选项概率,因此可解释性较差,且无法与可供性概率结合
对于Generative,他们还尝试了BERT嵌入[3],但发现性能较差
No VF和Generative方法的表现相似,分别实现了67%和74%的规划成功率,而低于PaLM-SayCan的84%
1.4.3 语言模型的选择与消融
SayCan 能够通过改进的语言模型得到改进。本研究中使用的语言模型是 PaLM [9],一个具有 540B 参数的模型。在本节中,我们对具有 8B、62B 和 540B参数的模型以及一个经过“指令回答”数据集微调的 137B 参数 FLAN 模型 [8] 进行了消融实验
最终,SayCan 在使用 PaLM 时实现了 84% 的计划成功率和 74% 的执行成功率,而 FLAN 实现了 70% 的计划成功率和 61% 的执行成功率,如下图所示
1.4.4 PaLM-SayCan的思维链能力
原始 SayCan 的一个局限是它无法处理涉及否定的任务。这是从底层语言模型继承的,并在自然语言处理社区中被研究过 [19]。然而,他们发现通过使用思维链提示 [24],可以在这方面改进 SayCan
下图所示,他们使用PaLM-SayCan进行链式思维规划展开。高亮部分是由PaLM-SayCan生成的链式思维

值得一提的是,他们在Google Colab 笔记本中开源了 SayCan 的一个实现,地址为:https://say-can.github.io/#open-source
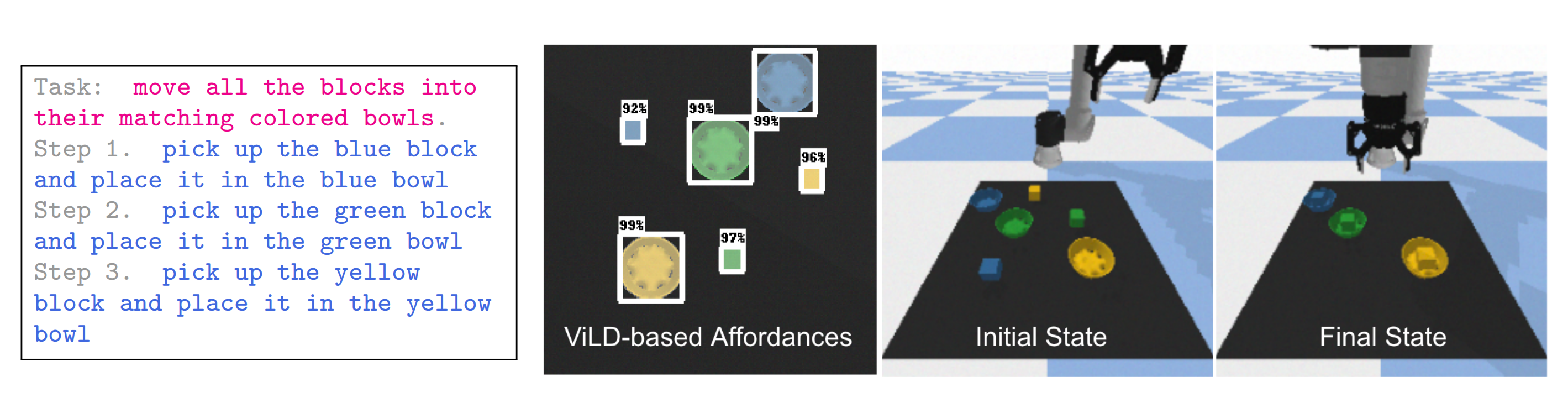
- 该环境如下图图 8 所示,是一个带有 UR5 机器人和随机生成的彩色方块和碗的桌面
- 低级策略使用 CLIPort [26] 实现,经过训练后可以输出抓取和放置的位置。由于该策略缺乏价值函数,操作能力是通过 ViLD 对象检测器[27] 实现的
GPT-3 被用作开源语言模型 [5]。步骤以“拾取对象并将其放置在位置”的形式输出,利用了大语言模型生成代码结构的能力
第二部分 李飞飞团队:具身智能VoxPoser——与RT-2同于23年7月发布
2.1 机器人对从没见过的任务也能一次执行且不需要示范
大模型接入机器人,把复杂指令转化成具体行动规划,无需额外数据和训练,说白了,人类可以很随意地用自然语言给机器人下达指令,如:打开上面的抽屉,小心花瓶!

大语言模型+视觉语言模型就能从3D空间中分析出目标和需要绕过的障碍,帮助机器人做行动规划

然后重点来了, 真实世界中的机器人在未经“培训”的情况下,就能直接执行这个任务。

新方法实现了零样本的日常操作任务轨迹合成,也就是机器人从没见过的任务也能一次执行,连给他做个示范都不需要
可操作的物体也是开放的,不用事先划定范围,开瓶子、按开关、拔充电线都能完成

2.2 VoxPoser:大模型指导机器人如何与环境进行交互
2.2.1 3D Value Map:既标记了“在哪里行动”,也标记了“如何行动”
机器人如何直接听懂人话?李飞飞团队将该系统命名为VoxPoser,如下图所示,它的原理非常简单(项目地址、论文地址、代码地址,发布于23年7月12)

简单而言就通过利用VLM和LLM的常识知识,借助模型生成代码,将常识知识映射到三维空间,具体而言
- 首先,给定环境信息(用相机采集RGB-D图像)和我们要执行的自然语言指令
例如,给定一条指令“打开顶层抽屉并注意花瓶”,LLMs可以被提示推断做任务拆解「而这个拆解很重要啊,拆解的好 机器人可以更快get」:
1)应该抓住顶层抽屉的把手,2)把手需要向外移动,3)机器人应该远离花瓶
- 接着,LLM(大语言模型)根据这些内容编写代码,所生成代码与VLM(视觉语言模型)进行交互,指导系统生成相应的操作指示地图,即3D Value Map
所谓3D Value Map,它是Affordance Map和Constraint Map的总称,既标记了“在哪里行动”,也标记了“如何行动”
比如,继续接着上面的例子——“打开顶层抽屉并注意花瓶”而言,通过生成调用感知API的Python代码(generating Python code to invoke perception APIs),LLMs可以获得相关对象或部件的空间几何信息,然后操纵3D体素(3D voxels)以在观察空间的相关位置上指定奖励或成本(例如,把手区域被分配高值,而花瓶周围被分配低值,即the handle region is assigned high values while the surrounding of the vase is assigned low values)
- 如此一来,再搬出动作规划器,将生成的3D地图作为其目标函数,便能够合成最终要执行的操作轨迹了
而从这个过程我们可以看到,相比传统方法需要进行额外的预训练,这个方法用大模型指导机器人如何与环境进行交互,所以直接解决了机器人训练数据稀缺的问题
更进一步,正是由于这个特点,它也实现了零样本能力,只要掌握了以上基本流程,就能hold任何给定任务
相当于对于上面的任务——“打开顶层抽屉并注意花瓶”,在其最后,组合的价值地图可以作为运动规划器的目标函数,直接合成实现给定指令的机器人轨迹 1,而无需为“每个任务或LLM”额外提供训练数据
2.2.2 将指令拆解成很多子任务 + 规划路径
在具体实现中,作者将VoxPoser的思路转化为一个优化问题,即下面这样一个复杂的公式:
其中
表示机器人,
表示机器人对应的运动轨迹,其中每个路径点包括期望的6自由度末端执行器姿态、末端执行器速度和夹爪动作,
表示第
评分了
完成指令
指定了控制成本,例如鼓励
表示动力学和运动学约束,这些约束由机器人的已知模型和基于物理或基于学习的环境模型来实施
最终,通过为每个子任务所指定的整体任务
它考虑到了人类下达的指令可能范围很大,并且需要上下文理解,于是将指令拆解成很多子任务,比如开头第一个示例就由“抓住抽屉把手”和“拉开抽屉”组成
VoxPoser要实现的就是优化每一个子任务,获得一系列机器人轨迹,最终最小化总的工作量和工作时间
而在用LLM和VLM将语言指令映射为3D地图的过程中,系统考虑到语言可以传达丰富的语义空间,便利用“感兴趣的实体(entity of interest)”来引导机器人进行操作,也就是通过3D Value Map中标记的值来反应哪个物体是对它具有“吸引力”的,那些物体是具有“排斥性”。

还是以开头的例子举例,抽屉就是“吸引”的,花瓶是“排斥”的。
当然,这些值如何生成,就靠大语言模型的理解能力了。
而在最后的轨迹合成过程中,由于语言模型的输出在整个任务中保持不变,所以我们可以通过缓存其输出,并使用闭环视觉反馈重新评估生成的代码,从而在遇到干扰时快速进行重新规划
因此,VoxPoser有着很强的抗干扰能力,比如下图将废纸放进蓝色托盘

最后,作者还惊喜地发现,VoxPoser产生了4个“涌现能力”:

- 评估物理特性,比如给定两个质量未知的方块,让机器人使用工具进行物理实验,确定哪个块更重;
- 行为常识推理,比如在摆餐具的任务中,告诉机器人“我是左撇子”,它就能通过上下文理解其含义;
- 细粒度校正,比如执行“给茶壶盖上盖子”这种精度要求较高的任务时,我们可以向机器人发出“你偏离了1厘米”等精确指令来校正它的操作;
- 基于视觉的多步操作,比如叫机器人将抽屉精准地打开成一半,由于没有对象模型导致的信息不足可能让机器人无法执行这样的任务,但VoxPoser可以根据视觉反馈提出多步操作策略,即首先完全打开抽屉同时记录手柄位移,然后将其推回至中点就可以满足要求了
第三部分 清华ViLA框架:Robotic Vision-Language Planning
3.1 ViLA
3.1.1 ViLA:直接提示VLMs基于环境的视觉观察和高级语言指令生成可执行步骤
23年11月,来自清华交叉信息研究院的高阳团队提出机器人视觉语言规划框架:Robotic Vision-Language Planning(简称ViLA)——其直接提示VLMs基于环境的视觉观察和高级语言指令生成一系列可执行步骤
- 其对应的论文为《Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning》
作者包括:Yingdong Hu, Fanqi Lin, Tong Zhang, Li Yi, Yang Gao - 其对应的项目地址为:robot-vila.github.io
3.1.2 相关工作:预训练基础模型与任务/运动规划
首先,在此之前,对于在机器人学中应用大型预训练基础模型,其进展可分为三类:
- 预训练视觉模型:大量先前的方法使用在大规模图像数据集上预训练的视觉模型[28-Ego4d, 15-Imagenet]来生成用于视觉运动控制任务的视觉表示[64- The unsurprising effectiveness of pre-trained vision models for control, 85-Masked visual pre-training for motor control, 67-Real-world robot learning with masked visual pre-training, 59- R3m,55, 95]
然而,机器人系统不仅仅包含感知模块;它还包括控制策略。仅依赖捕捉高层语义的视觉表示可能无法确保控制策略的普遍性或系统的整体有效性[35, 91, 30] - 预训练语言模型:另一研究方向探讨了将大规模语言模型(LLM)用于机器人任务,特别是在推理和规划方面 [37- Language models as zero-shot planners:Extracting actionable knowledge for embodied agents, 2-即上文第一部分介绍的Do as i can, not as i say, 73-Progprompt, 84-Tidybot, 74-Llm-planner:Few-shot grounded planning for embodied agents with large language models, 51, 80-Chatgpt for robotics: Design principles and model abilities,50- Text2motion, 16- Task and motion planning with large language models for object rearrangement, 68-Robots that ask for help: Uncertainty alignment for large language model planners]
然而,为了将这些语言模型与物理环境相结合,诸如可供性模型 [40]、感知 API[49] 和文本场景描述 [38, 94] 等辅助模块是必不可少的
相比之下,ViLA的工作强调生成计划而不依赖于这些辅助模型进行结合。这种方法允许将感知信息无缝集成到推理和规划过程中 - 预训练视觉-语言模型:许多研究探讨了视觉-语言模型(VLMs)在机器人领域的应用[39-即上文介绍过的Voxposer,19-Vision-language models as success detectors, 70, 96-Grounding
classical task planners via vision-language models, 24-Physically grounded vision-language models for robotic manipulation]
值得注意的是,RT-2[8]展示了VLMs在低层次机器人控制中的整合
相反,ViLA的研究主要集中在高层次的机器人规划上。尽管PaLM-E[18-Palme: An embodied multimodal language model,详见此文《Google视觉机器人超级汇总:从RT、PaLM-E、RT-2到RT-X、RT-H(含Open X-Embodiment数据集详解)》的第二部分]与ViLA的方法有相似之处,但它需要在大量的机器人和通用视觉-语言数据[11, 54]上进行训练
这种方法意味着将机器人引入新环境需要收集额外的数据并对模型进行重新训练
与此形成鲜明对比的是,VILA作为一个开放世界的零样本模型脱颖而出。它能够在没有额外训练数据和提示中的上下文示例的情况下执行广泛的日常操作任务
其次,再来看下之前任务与运动规划的工作
- 任务与运动规划(TAMP)[43-Hierarchical task and motion planning in the now, 26- Integrated task and motion planning] 是解决长时间规划任务的关键框架,将低层次的连续运动规划[46-Planning algorithms]与高层次的离散任务规划[22, 69, 60]相结合
- 虽然该领域的传统研究主要集中在符号规划[22, 60]或基于优化的方法[77, 78]上,但机器学习[87, 20, 25, 41]和LLMs[16-Task and motion planning with large language models for object rearrangement, 12-Autotamp: Autoregressive task and motion planning with llms as translators and checkers, 72, 86- Translating natural language to planning goals with large-language models]的出现正在革新这一领域
在ViLA的工作中,其利用VLMs来理解机器人环境并解释高层次的指令。通过结合视觉世界中固有的常识知识,ViLA在处理超出以往基于LLM的规划方法范围的复杂任务方面表现出色
3.2 VILA如何利用视觉-语言模型作为机器人规划器
首先,事先明确,在机器人系统
- 获取环境的视觉观测
——假设视觉观测xt 作为世界状态的准确表示
- 一个高级语言指令
其次,VILA研究的核心问题是生成一系列文本动作,表示为。每个文本动作
是一个短期语言指令(例如” 捡起蓝色容器”),它指定了一个子任务/基本技能
请注意,他们的贡献并不集中于这些技能Π的获取;相反,我们假设所有必要的技能已经可用。这些技能可以采取预定义脚本策略的形式,或者通过各种学习方法获得,包括强化学习(RL)[76] 和行为克隆(BC)[66]
3.2.1 VILA:让VLM将高层次指令分解为一系列低层次技能
作者主张通过使用VLMs,将视觉与语言能力结合起来,将高层次指令分解为一系列低层次技能,从而将该方法称为机器人视觉语言规划(VILA)
- 具体来说,给定环境的当前视觉观测
且通过选择第一个步骤作为文本动作来实现闭环执行。一旦文本动作
被选定,相应的策略
由机器人执行
并且VLM 查询被修改以包含 - 整个过程如下图图2 所示「给定语言指令和当前视觉观察,利用VLM通过CoT推理来理解环境场景,随后生成逐步计划。该计划的第一步由原始策略执行。最后,已执行的步骤被添加到完成的计划中,从而在动态环境中实现闭环规划方法」,并在算法1 中描述
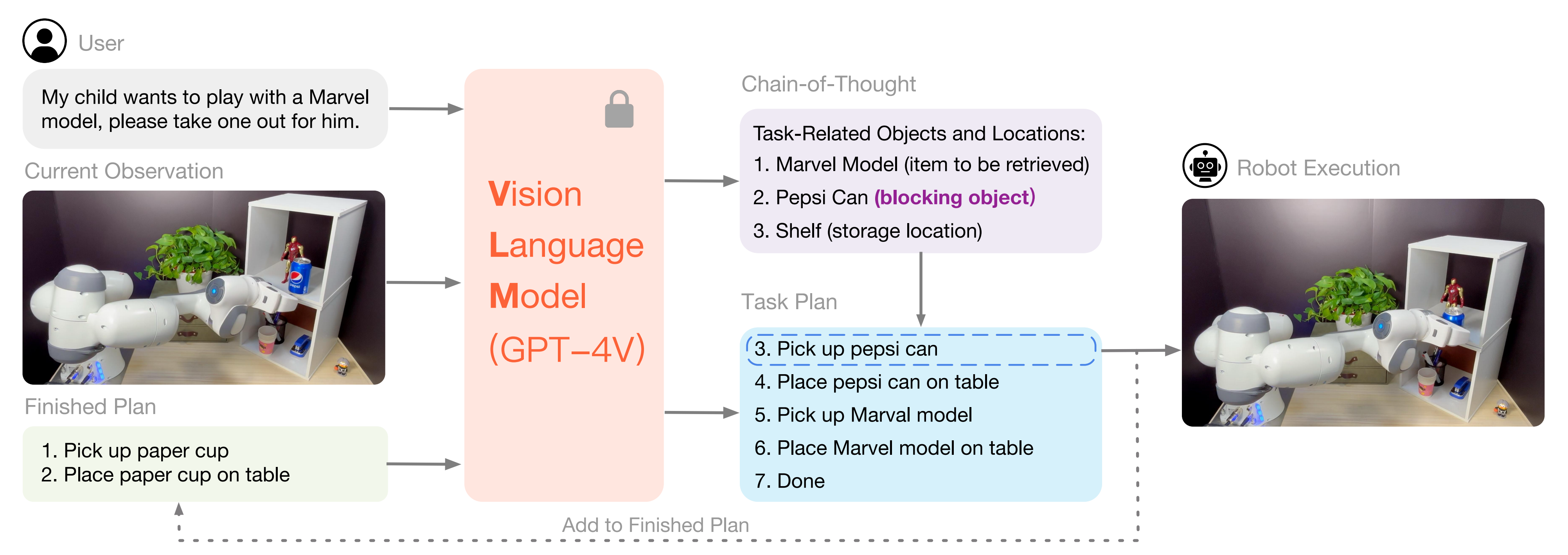
过程中的VLM则直接用的OpenAI的GPT-4V
3.2.2 VILA可以自然地利用视觉反馈
最后,值得一提的是
- VILA 不仅可以接受当前视觉观察
和语言指令
。这一特性使其区别于许多现有的目标条件RL/IL 算法[58, 21- Contrastive learning as goalconditioned reinforcement learning, 17],因为它不要求目标图像和视觉观察图像来自同一领域「as it does not require the goal and visualobservation images to originate from the same domain」
- 而且VILA能提供视觉反馈
毕竟具身环境本质上是动态的,这使得闭环反馈对于机器人至关重要。为了将环境反馈纳入仅依赖LLM的规划方法中,Huang等人[38]研究了将所有反馈转换为自然语言的方法。然而,这种方法被证明是笨重且无效的,因为大多数反馈最初是通过视觉观察到的。将视觉反馈转换为语言不仅增加了系统的复杂性,还可能导致宝贵信息的丢失
故直接提供视觉反馈是一种更直观和自然的方法——在VILA中,VLM既作为场景描述器识别对象状态,又作为成功检测器判断环境是否满足指令定义的成功条件。通过对视觉反馈进行推理,VILA使机器人能够在环境变化或技能失败时进行修正或重新规划
比如如下图所示,展示了VILA在寻找订书机任务中的执行过程。通过在每一步都结合视觉反馈和重新规划,当在上抽屉找不到订书机时,VILA能够继续探索下抽屉,从而成功找到订书机
第四部分 清华具身智能CoPa:超过之前李飞飞团队的VoxPoser
4.1 清华推出机器人操控框架CoPa
24年3月下旬,清华交叉信息研究院的一团队通过这篇论文《CoPa: General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models》提出了名为CoPa的机器人操控框架(其对应的GitHub地址为:github.com/HaoxuHuang/copa),其利用嵌入在基础模型中的常识知识(比如视觉语言模型的代表GPT-4V)为开放世界机器人操控生成一系列6自由度末端执行器姿势
具体而言,将操控过程分解为两个阶段:
- 任务导向抓取,类似抓到锤柄
使用视觉语言模型(VLMs) 比如GPT4-V,通过一种新颖的粗到细的定位机制选择对象的抓取部件(这句话的意思类似,好比人拿一个锤子去钉钉子时,是知道用手去拿锤子的锤柄,而非锤头) - 任务感知运动规划,类似拿打击面对准钉子
再次利用VLMs来识别与任务相关的对象部件的空间几何状态(或约束),然后用于推导抓取后的姿势
4.1.1 机器人基础模型(相当于大脑):用于整体任务规划
近年来,基础模型已经极大地改变了机器人领域的格局[Toward general-purpose robots via foundation models: A survey and meta-analysis]
- 许多研究采用在大规模图像数据集上进行预训练的视觉模型,用于生成视觉表征以进行视觉运动控制任务[比如A universal semanticgeometric representation for robotic manipulation、The unsurprising effectiveness of pre-trained vision models for control、Real-world robot learning with masked visual pre-training,” in Conference on Robot Learning等等]
- 其他一些研究利用基础模型来规定强化学习中的奖励[Vip: Towards universal visual reward and representation via value-implicit pre-training、Eureka: Humanlevel reward design via coding large language models、Learning reward functions for robotic manipulation by observing humans、Zero-shot reward specification via grounded natural language、Can foundation models perform zero-shot task specification for robot manipulation?、Liv: Language-image representations and rewards for robotic contro]
此外,许多研究利用基础模型进行机器人高层规划,取得了显著的成功,比如
- Do as i can, not as i say: Grounding language in robotic affordances
- Grounded decoding: Guiding text generation with grounded models for robot control
- Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning
- Progprompt: Generating situated robot task plans using large language models
- Physically grounded vision-language models for robotic manipulation
- Task and motion planning with large language models for object rearrangement
- Language models as zero-shot planners: Extracting actionable knowledge for embodiedagents
- Text2motion: From natural language instructions to feasible plans
- Llm+ p: Empowering large language models with optimal planning proficiency
- Robots that ask for help: Uncertainty alignment for large language model planners
- Llm-planner: Few-shot grounded planning for embodied agents with large language models
- Tidybot: Personalized robot assistance with large language models
当然了,也还有一些研究利用基础模型进行低层控制[比如Google的RT-1、RT-2、Open x-embodiment: Robotic learning datasets and rt-x model、Octo: An open-source generalist robot policy
此外,一些研究对视觉语言模型VLMs进行微调,直接输出机器人动作(比如RT-2)。 然而,这种微调方法需要大量的专家数据,为了解决这个问题
- Code as Policies [Code as policies: Language model programs for embodied control]使用大型语言模型LLMs编写控制机器人的代码
- 而VoxPoser[16]通过基础模型生成机器人轨迹,产生基于基础模型的值图
然而,这些方法依赖于复杂的提示工程,并且对场景只有粗略的理解。 与之形成鲜明对比的是,CoPa通过合理利用视觉语言模型中的常识知识,对场景有着细致入微的理解,并且能够推广到开放世界的场景,无需额外的训练,只需要最少的提示工程
4.1.2 机器人操控模型(相当于小脑):用于精确控制
机器人操控是机器人领域中一个关键且具有挑战性的方面
- 大量的研究利用专家演示的模仿学习IL来获得操控技能(比如Google的RT-1、RT-2等等)
尽管模仿学习在概念上很简单,并且在广泛的真实世界任务中取得了显著的成功,但它在处理分布不匹配的样本时存在困难,并且需要大量的专家数据收集工作 - 强化学习(RL)是另一种主要方法[比如Do as i can, not as i say、Imitation learning from observation with automatic discount scheduling、End-to-end training of deep visuomotor policies]使机器人能够通过与环境的试错交互来发展操控技能
然而,RL的样本效率限制了它在真实世界环境中的适用性,导致大多数机器人系统依赖于从仿真到真实的转移[比如Sim-to-real reinforcement learning for deformable object manipulation、Self-supervised sim-to-real adaptation for visual robotic manipulation]
而从仿真到真实的方法需要构建特定的仿真器,并面临仿真到真实之间的差距
此外,通过这些端到端学习方法学习的策略通常缺乏对新任务的泛化能力。 相比之下,通过利用基础模型的常识知识,CoPa可以在开放世界场景中实现泛化,而无需额外的训练
4.2 物体抓取与运动规划
打开抽屉需要抓住把手并沿直线拉动,而拿起水杯则需要先抓住杯子然后抬起来。受到这一观察的启发,将方法分为两个模块:
- 面向任务的抓取
给定语言指令和初始场景观察
(RGB-D图像),在面向任务的抓取模块中的目标是为指定的感兴趣对象生成适当的抓取姿态,该过程表示为
,并将机器人到达
后的观察表示为
- 任务感知的运动规划
对于任务感知的运动规划模块,我们的目标是得出一系列抓取后的姿态,表示为,其中
是完成任务所需的姿态总数。 在获取目标姿态之后,机器人的末端执行器可以利用运动规划算法(如RRT* [50]和PRM* [51])到达这些姿态
4.2.1 任务导向的抓取:SoM + GPT-4V + 准确定位物体被抓部位
物体的初始抓取的整个过程如下所示
- 首先使用SoM对场景中的物体进行分割和标记
- 然后,结合指令,我们使用GPT-4V选择抓取/任务相关的物体
- 最后,类似的细粒度部件定位被应用于定位特定的抓取/任务相关部位
首先,采用一种称为Set-of-Mark (SoM) [55]的最新视觉提示机制,其利用分割模型将图像分割成不同的区域,并为每个区域分配一个数字标记(即在粗粒度对象定位阶段,使用SoM在对象级别上检测和标记场景中的所有对象)
其次,类似人类根据预期使用方式抓取物体的特定部件(例如,当用刀切割时,我们握住刀柄而不是刀刃;同样,拿起眼镜时,我们抓住镜框而不是镜片。这个过程实质上代表了人类运用常识的能力),CoPa利用视觉语言模型(VLMs),如GPT-4V [https://cdn.openai.com/papers/GPTV_System_Card.pdf],它们融合了大量的常识知识[Look before you leap:Unveiling the power of gpt-4v in robotic vision-language planning],[Sage: Bridging semantic and actionable parts for generalizable articulated-object manipulation under language instructions],以确定抓取物体的适当部位

最后,为了生成任务导向的抓取姿势,我们的方法首先使用抓取模型生成抓取姿势提案,并通过我们的新颖抓取部件基准模块筛选出最可行的一个

那如何生成抓取姿势的提案呢?简言之,利用预训练的抓取模型生成抓取姿势提案,具体而言
- 首先通过将RGB-D图像反投影到3D空间中将其转换为点云
- 然后将这些点云输入到GraspNet [Graspnet-1billion: A largescale benchmark for general object grasping]中,这是一个在包含超过十亿个抓取姿势的大型数据集上训练的模型。 GraspNet输出6自由度的抓取候选项,包括抓取点的信息、宽度、高度、深度和“抓取得分”,该得分表示成功抓取的可能性
- 然而,鉴于GraspNet在场景中产生了所有潜在的抓取,我们有必要使用一个选择性的过滤机制来选择根据语言指令所述的具体任务选择最佳的抓取方式
总之,回顾上述整个过程,可知分为以下三步
- VLMs的任务是根据用户的指令来确定目标对象进行抓取(例如,一个锤子)
- 然后,从图像中裁剪出所选对象,并应用细粒度部件定位来确定要抓取的具体部位(例如,锤子的把手)。 这种由粗到细的设计赋予了CoPa对复杂场景的细粒度物理理解能力,实现了泛化
- 最后,我们过滤抓取姿势候选,将所有抓取点投影到图像上,并仅保留在抓取部件掩码内的点。 从中选择GraspNet评分最高的姿势作为最终的执行抓取姿势
4.2.2 任务感知的运动规划
在成功执行面向任务的抓取后,现在的目标是获得一系列抓取后的姿态。 可将这一步骤分为三个模块:

- 与任务相关的部件定位
与之前的抓取部件定位模块类似,我们使用粗粒度的物体定位和细粒度的部件定位来定位与任务相关的部件
在这里,需要识别多个与任务相关的部件(例如锤子的打击面、手柄和钉子的表面)。 此外,观察到机器人手臂上的数字标记可能会影响VLM的选择,因此过滤掉了机器人手臂上的标记 - 操控约束生成
在执行任务的过程中,与任务相关的物体往往受到各种空间几何约束的限制。 例如,充电手机时,充电器的连接器必须与充电口对齐;同样,盖子必须直接放在瓶口上方才能盖上瓶子。 这些约束本质上需要常识知识,包括对物体物理属性的深入理解。 我们旨在利用VLM生成被操控对象的空间几何约束 - 目标姿态规划
4.3 与23年李飞飞团队VoxPoser的对比

4.4 目前CoPa的局限与不足
- 首先,CoPa处理复杂对象的能力受到其依赖的simplistic geometric elements(如surfaces and vector)的限制
CoPa’s capability to process complex objects is con-strained by its reliance on simplistic geometric elements such as surfaces and vector
通过将更多的几何元素纳入我们的建模过程,可以改善这一点 - 其次,目前使用的VLMs是在大规模2D图像上进行预训练的,缺乏对3D物理世界的真实基础。这个限制影响了它们进行准确的空间推理的能力
若将3D输入(如点云)整合到VLMs的训练阶段中,可以缓解这个挑战 - 最后,现有的VLMs只产生离散的文本输出,而我们的框架实际上需要连续的输出值,如物体部件的坐标
the existing VLMs produce only discrete textual outputs, where as our framework essentially necessitates continuous output values, like the coordinates of object parts
开发具备这些能力的基础模型仍然是一个备受期待的进展
对于目前这个方向,后来还有了:ReKep——李飞飞团队提出的让机器人具备空间智能:基于VLM模型GPT-4o和关系关键点约束(含源码解析)
参考文献与推荐阅读
- 李飞飞「具身智能」新成果!机器人接入大模型直接听懂人话,0预训练就能完成复杂指令
VoxPoser论文一作在Twitter上发的关于VoxPoser的视频:https://twitter.com/wenlong_huang/status/1677375515811016704 - 谷歌AGI机器人大招!54人天团憋7个月,强泛化强推理,DeepMind和谷歌大脑合并后新成果,RT-2
- 买个机器人端茶倒水有希望了?Meta、纽约大学造了一个OK-Robot
- 机器人领域首个开源视觉-语言操作大模型,RoboFlamingo框架激发开源VLMs更大潜能
如果某些点与本文冲突,请以本文为准,本文更严谨、准确 - 只用 13 天,OpenAI 做出了能听、能说、能自主决策的机器人大模型
- 国内创业者和投资人如何看待 Figure 01 机器人:距离具身智能还有多远?
- OpenAI 和 Figure 机器人背后的技术原理是什么?
- OpenAI没有放弃的机器人梦想 | 甲子光年
- 斯坦福家务机器人Mobile ALOHA的关键技术:动作分块算法ACT的原理解析
- 一句指令就能冲咖啡、倒红酒、锤钉子,清华具身智能CoPa「动」手了
- 叠衣服、擦案板、冲果汁,能做家务的国产机器人终于要来了,来自X Square
- 2个月不见,人形机器人Walker S会叠衣服了,来自优必选 + 百度文心一言


















 2978
2978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











