







整体框架
作者团队:Stanford University || NVIDIA
论文链接:paper
代码链接:code
论文摘要
- 利用单张图片,通过无监督的方式生成多角度协同的视图和对应的3D图仍存在很大的挑战
- 当前的3D GANs模型存在两点不足:1.所需计算资源巨大–限制了其实际应用和可输出分辨率;2.采用估计的方法而非3D协同(没有采用一个点一个点的方法去生成整张3D视图)–无法做到真正的多角度协同。
- 作者提出了一种高效的,显示-隐式混合的模型,可以实时生成高分辨率的多角度协同视图以及对应的3D视图。
- 通过将特征获取和渲染出图这两步解耦开来的方式,作者的模型能够利用当前的SOTA的2D图像生成器,继承了其所具有的高效和高表现力
- 在FFHQ、AFHQ上面进行多角度协同实验,均达到了SOTA。
论文引言
- 3D GANS开始向多角度协同图片生成的领域出发,但其效果却远不如2D图像的生成,主要原因是1:计算强度大 2.不合适的渲染框架
- 与2D GANs对比,3D GANs主要依赖生成器的 3D结构感知归纳偏置和输出多角度协同的渲染器。这种归纳偏置可以被建模为显示的体素网格(理解为2D图像中的像素点,在3D空间中的表示)或者神经隐式(神经隐式表示使用神经网络来学习从输入向量到隐式函数的映射)。
- 所提到了两种表示形式,即体素网格和神经隐式表示,它们在单个场景的“过拟合”情况下取得了成功。然而,这两种表示形式都不适用于训练高分辨率的3D GAN,因为它们在内存效率或速度上都存在问题。 首先,体素网格在高分辨率情况下很容易导致内存不足的问题。随着分辨率的增加,体素的数量呈指数级增长,需要大量的内存来存储和处理体素网格。这导致难以训练高分辨率的3D GAN,因为它们需要处理大规模的体素数据,对计算资源要求很高。 其次,神经隐式表示虽然能够灵活地表示复杂的三维结构,但由于需要对整个三维空间进行隐式函数的评估,速度较慢。在高分辨率情况下,神经隐式表示需要对大量的三维点进行评估,这对于训练3D GAN来说是一个显著的计算负担。
- 在训练3D GAN时,为了生成高质量的图像,需要对大量的三维场景进行渲染。然而,使用体素网格或神经隐式表示进行高分辨率的神经体积渲染是非常复杂和计算密集的。因此,研究人员提出了基于CNN的图像上采样网络,以提高图像的质量和分辨率。这种方法通过使用卷积神经网络,将低分辨率输入图像转换为高分辨率输出图像,使得训练过程更加高效和可行。 然而,这种基于图像上采样网络的方法会牺牲视角一致性,即生成的图像在不同视角下有不一致的外观。这是由于上采样网络的处理过程中,没有考虑到三维场景的空间结构和视角信息。因此,虽然生成的图像在分辨率上得到了提升,但对于视角一致性以及学习到的三维几何结构的质量可能会有所损失。 因此,在3D GAN的训练中,权衡图像质量和视角一致性是一个具有挑战性的问题。研究人员需要寻找更好的方法,在保持视角一致性的同时提高图像生成的质量,并学习到更准确的三维几何结构。这是当前3D GAN研究中的一个重要课题。
- 作者团队提出了一用于无监督学习3D表示的新型生成器架构,通过对一组单视角2D照片进行处理,旨在提高渲染的计算效率,同时保持对3D的基于神经网络的渲染的准确性。为了实现这一目标,采用了一个双管齐下的方法。
- 提到了一种混合显式-隐式的3D表示方法,对于3D基准渲染的计算效率进行了改进,并在不降低表达能力的情况下提供了显著的速度和内存优势。这种混合表示方法同时融合了显式和隐式的3D表示方式,以克服完全隐式或显式方法所面临的速度和内存的挑战。
- 作者使用了一些在图像空间中的近似方法, 因此在使用基于图像的上采样方法时,通常会出现生成图像在不同视角下外观不一致的问题。这是
由于上采样过程中缺乏对三维结构和视角信息的准确建模。 为了解决这个问题,该方法引入了一种双重鉴别策略。- 作者还为生成器引入了姿势估计条件,生成器通过解耦姿势相关的属性(例如面部表情),在推断过程中实现多视角一致的输出,并且在准确
地建模训练数据中姿势相关属性的联合分布。
- 贡献总结:
- 提出了一种计算高效、表达能力强的3D GAN模型,能够生成高分辨率的多角度协同视图。
- 提出了一种训练策略,可以促进多角度协同和高效地建模姿势的联合发布
- 做了大量实验,均为SOTA
论文方法
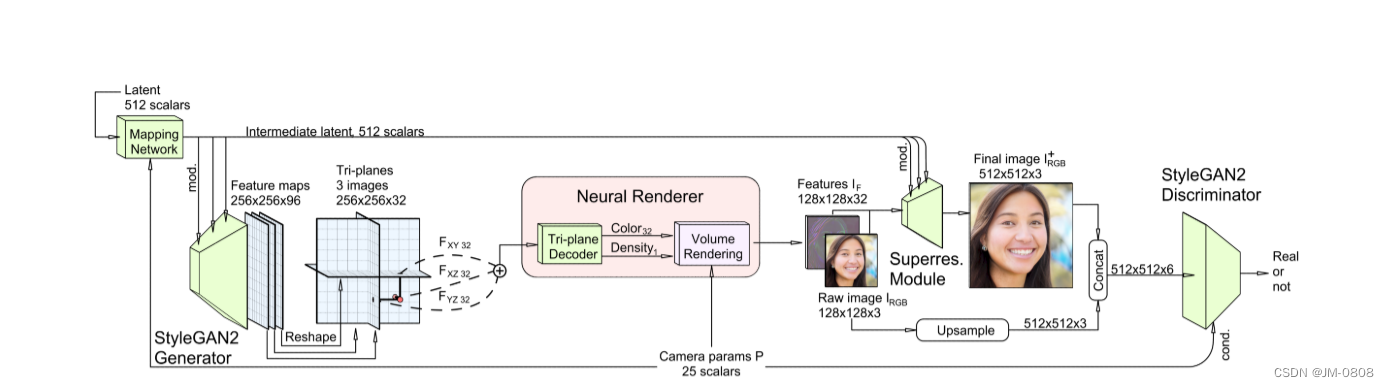
体素网格的表征:通过StyleGAN2生成器输出一张[256,256,96]的特征图,将其平分为3份[3, 32, 256, 256],分别代表xy,xz,yz三个平面。将3D像素隐射到体素网格中,通过坐标分别索引对应平面的特征,用过双线性插值得到xy,xz,yz的特征,通过总和进行聚合,并使用轻量级解码器处理聚合特征,上图中,解码器是一个多层感知器,有一个64个单元的单个隐藏层和软加激活函数。MLP不使用位置编码、坐标输入或视图方向输入。该混合表示可以查询连续坐标,输出标量密度σ和32通道特征,然后通过神经体渲染器处理,将3D特征体投影到2D特征图像。体渲染器采用双通道重要采样实现,产生特征图像,而不是RGB图像,因为特征图像包含更多的信息,可以有效地用于下面描述的图像空间细化。最后产生128 x 128 x 32的特征图IF,并且每条射线有96个总深度样本。
对渲染结构进行超分辨率重构:虽然三平面表示比之前的方法在计算效率上有了显著提高,但在保持交互帧率的同时,它在本地训练或呈现高分辨率时仍然太慢。因此,在中等分辨率(如128x128)下进行体积渲染,并依靠图像空间卷积对神经渲染进行上采样,使其最终图像大小为256x256或512x512。
dual discrimination:判别器使用Dual discrimination避免多视图不一致问题,将Volume Rendering处理后的特征图的前三个特征通道理解为低分辨率的RGB图像——IRGB,dual discrimination通过双线性上采样IRGB到与I+ RGB相同的分辨率,并将结果拼接形成一个六通道图像来实现,IRGB和超分辨率图像I+ RGB之间的一致性。输入鉴别器的真实图像也通过将它们与自身适当模糊的副本进行拼接作同样处理。
条件策略:循StyleGAN2-ADA的条件策略,将呈现摄像机intrinsic和extrinsics矩阵(集合P)作为条件标签传递给鉴别器,使鉴别器意识到相机的姿态,由此生成的图像被渲染。这种条件反射引入了额外的信息,指导生成器学习正确的3D先验。引入生成器位姿条件反射作为一种方法来建模和解耦在训练图像中观察到的位姿和其他属性之间的相关性。为此,遵循条件生成策略,为骨干映射网络提供一个潜在的代码向量z,并将摄像机参数P作为输入。通过给出渲染相机位置的主干知识,我们允许目标视图影响场景合成。















 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









