






class1 配置环境
jupyter notebook 用来运行代码
conda用来解决
pytorch
paddle百度研发的深度学习框架
class2 baseline:特征提取 + 机器学习
1 文本二分类问题
机器需要根据对论文摘要等信息的理解,将论文划分为医学领域的文献和非医学领域的文献两个类别之一。
针对文本分类任务,可以提供两种实践思路,一种是使用传统的特征提取方法(如TF-IDF/BOW)结合机器学习模型,另一种是使用预训练的BERT模型进行建模。下面是方法一:特征提取+机器学习
- 数据预处理:首先,对文本数据进行预处理,包括文本清洗(如去除特殊字符、标点符号)、分词等操作。可以使用常见的NLP工具包(如NLTK或spaCy)来辅助进行预处理。
- 特征提取:使用TF-IDF(词频-逆文档频率)或BOW(词袋模型)方法将文本转换为向量表示。TF-IDF可以计算文本中词语的重要性,而BOW则简单地统计每个词语在文本中的出现次数。可以使用scikit-learn库的TfidfVectorizer或CountVectorizer来实现特征提取。
- 构建训练集和测试集:将预处理后的文本数据分割为训练集和测试集,确保数据集的样本分布均匀。
- 选择机器学习模型:根据实际情况选择适合的机器学习模型,如朴素贝叶斯、支持向量机(SVM)、随机森林等。这些模型在文本分类任务中表现良好。可以使用scikit-learn库中相应的分类器进行模型训练和评估。
- 模型训练和评估:使用训练集对选定的机器学习模型进行训练,然后使用测试集进行评估。评估指标可以选择准确率、精确率、召回率、F1值等。
- 调参优化:如果模型效果不理想,可以尝试调整特征提取的参数(如词频阈值、词袋大小等)或机器学习模型的参数,以获得更好的性能。
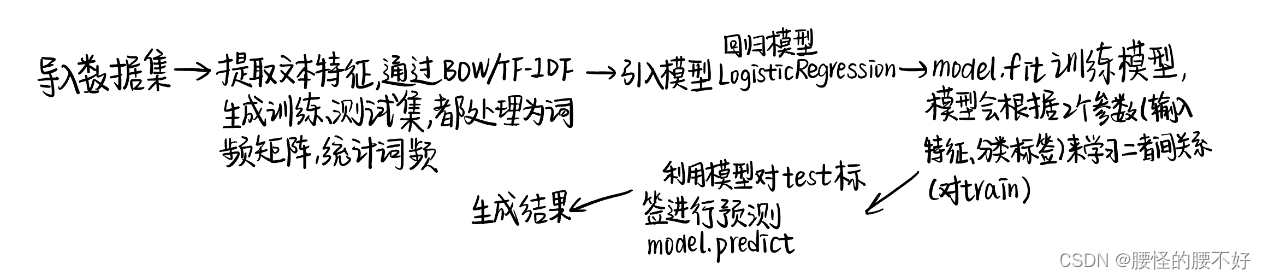
Baseline中我们选择使用BOW将文本转换为向量表示,选择逻辑回归模型来完成训练和评估。
# 1 导入pandas用于读取表格数据
import pandas as pd
#2 导入BOW(词袋模型),可以选择将CountVectorizer替换为TfidfVectorizer(TF-IDF(词频-逆文档频率)),注意上下文要同时修改,亲测后者效果更佳
from sklearn.feature_extraction.text import CountVectorizer
#3 导入LogisticRegression回归模型
from sklearn.linear_model import LogisticRegression
#4 过滤警告消息
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)
#5 读取数据集
#数据集是个表格,用pandas来读取其中数据
train = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/train.csv')
train['title'] = train['title'].fillna('')
train['abstract'] = train['abstract'].fillna('')
test = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/test.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')
#6 提取文本特征,生成训练集与测试集
#将title、abstract、text、author、keywords进行整合,放到一块方便后续处理
train['text'] = train['title'].fillna('') + ' ' + train['author'].fillna('') + ' ' + train['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
test['text'] = test['title'].fillna('') + ' ' + test['author'].fillna('') + ' ' + test['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
vector = CountVectorizer().fit(train['text'])
#首先使用CountVectorizer类创建了一个向量化器对象vector。CountVectorizer是一个用于将文本转换为词频矩阵的工具,它将文本中的每个单词视为一个特征,并统计每个单词在文本中出现的次数。其次,通过调用fit方法,将训练集的文本数据train['text']传入向量化器对象vector进行拟合,从而建立词汇表。词汇表是由训练集文本中出现的所有单词组成的,每个单词都被赋予一个唯一的索引。
train_vector = vector.transform(train['text'])
#然后,使用transform方法将训练集的文本数据train['text']转换为词频矩阵train_vector。词频矩阵是一个二维矩阵,每行表示一个文本样本,每列表示一个单词特征,矩阵中的每个元素表示对应文本样本中对应单词的出现次数。
test_vector = vector.transform(test['text'])
#和上一步一样,这里处理的是测试集。到此为止,训练集和测试集的文本数据都被转换为了词频矩阵,可以用于后续的机器学习模型训练和预测。
#7 引入模型
model = LogisticRegression()
#8 开始训练,这里可以考虑修改默认的batch_size与epoch来取得更好的效果
model.fit(train_vector, train['label'])#利用句子向量和分类标签来对他们进行训练
#使用train_vector作为输入特征,train['label']作为对应的分类标签,调用model的fit方法来对模型进行训练。模型会根据输入的特征和对应的分类标签来学习特征与标签之间的关系。
#9 利用模型对测试集label标签进行预测
test['label'] = model.predict(test_vector)
#10 生成任务一推测结果
test[['uuid', 'Keywords', 'label']].to_csv('submit_task1.csv', index=None)#
在任务1中还可以尝试BERT模型,但直接TF-IDF(词频-逆文档频率)或BOW(词袋模型)方法的效果已经足够好,已经可以在测试集达到0.99+的分数。
(1)文本提取方法:
NLP三种词袋模型CountVectorizer/TFIDF/HashVectorizer (zhihu.com)
TfidfVectorizer和CountVectorizer的区别在于特征向量的表示方式和计算方式,他们都是常见的文本特征提取方法。
sklearn——CountVectorizer:Bow词袋模型
CountVectorizer属于词袋模型。词袋模型是一种文本表示方法,将每个文本看作是一个"袋子",忽略单词的顺序,只关注每个单词的出现次数,忽略其次序、语法,仅仅看做是一些词汇的集合。CountVectorizer将文本转换为特征向量表示时,统计每个单词在文本中的出现频率,构建特征向量。
CountVectorizer是属于常见的特征数值计算类,是一个文本特征提取方法。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数。
CountVectorizer类会将文本中的词语转换为词频矩阵。 例如矩阵中包含一个元素! [a[ i ] [ j ]],它表示[ j ]词在[ i ]类文本下的词频。它通过fit_transform函数计算各个词语出现的次数,通过get_feature_names()可获取词袋中所有文本的关键字,通过toarray()可看到词频矩阵的结果。
from sklearn.feature_extraction.text import CountVectorizer
texts=["dog cat fish","dog cat cat","fish bird", 'bird'] # “dog cat fish” 为输入列表元素,即代表一个文章的字符串
cv = CountVectorizer()#创建词袋数据结构
cv_fit=cv.fit_transform(texts)
#上述代码等价于下面两行
#cv.fit(texts)
#cv_fit=cv.transform(texts)
print(cv.get_feature_names()) #['bird', 'cat', 'dog', 'fish'] 列表形式呈现文章生成的词典
print(cv.vocabulary_ ) #{‘dog’:2,'cat':1,'fish':3,'bird':0} 字典形式呈现,key:词,value:索引号
print(cv_fit)
# (0,3) 1 第0句的、词典中索引为3的元素(fish) 词频为1
print(cv_fit.toarray()) #.toarray() 是将结果转化为稀疏矩阵矩阵的表示方式;
print(cv_fit.toarray().sum(axis=0)) #每个词在所有文档中的词频
#[2 3 2 2]
结果:
['bird', 'cat', 'dog', 'fish']
{'dog': 2, 'cat': 1, 'fish': 3, 'bird': 0}
(0, 2) 1
(0, 1) 1
(0, 3) 1
(1, 2) 1
(1, 1) 2
(2, 3) 1
(2, 0) 1
(3, 0) 1
[[0 1 1 1]
[0 2 1 0]
[1 0 0 1]
[1 0 0 0]]
[2 3 2 2]
skarn——TfidfVectorizer:TF-IDF(词频-逆文档频率)
与bow不同的是,TF-IDF还可以计算文本中词语的重要性。
TF-IDF(term frequency-inverse document frequency 词频-逆文档频率)是文本加权方法,采用统计思想,即通过文本出现的次数和整个语料中的文档频率来计算字词的重要度。
相比之下,TfidfVectorizer使用了TF-IDF(Term Frequency-Inverse Document Frequency)方法来计算特征向量。TF-IDF考虑了单词在文本中的频率(TF)以及在整个语料库中的重要性(IDF)。通过将TF和IDF相乘,TfidfVectorizer计算出每个单词的TF-IDF值,用于表示文本的特征向量。
词频(TF)=某个词在文档中出现的次数、文档的总次数
逆文档频率(IDF)=log(语料库的文档总数/(包含该词语的文档数+1))
TF-IDF=词频(TF)×逆文档频率(IDF)
即:**TF-IDF(w,d)=TF(w,d)×IDF(w)**其中,w表示词语,d表示文档
一个词语的重要程度跟它在文档中出现的次数成正比,跟它在语料库中出现的次数成反比。这样可以有效避免常用词(如的、呢、吧等虽然出现很多次,但并不重要,TF数值很大但IDF数值小)对于关键词的影响。
语料库:用于语言学研究和自然语言处理任务的大规模文本数据集合。它是对自然语言的实际使用进行收集和整理的结果,包括书籍、新闻文章、网页内容、对话记录等等。
优点:可以过滤一些常见但是无关紧要的字词。
from sklearn.feature_extraction.text import TfidfVectorizer
# 定义文本数据
corpus = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?"
]
# 创建TfidfVectorizer对象
vectorizer = TfidfVectorizer()
# 对文本数据进行拟合和转换
X = vectorizer.fit_transform(corpus)
# 打印特征向量表示
print(X.toarray())
# 打印特征词汇
print(vectorizer.get_feature_names())
结果:
[[0. 0. 0.57615236 0.40993715 0.57615236 0. 0.40993715 0. ]
[0. 0. 0.34884223 0.49248834 0.34884223 0.70044055 0.49248834 0. ]
[0.70044055 0.70044055 0.25082703 0.1778275 0.25082703 0. 0.1778275 0.70044055]
[0. 0. 0.57615236 0.40993715 0.57615236 0. 0.40993715 0. ]]
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
上述代码首先定义了一个包含四个文本数据的列表。然后创建了一个TfidfVectorizer对象,并使用fit_transform方法对文本数据进行拟合和转换,得到特征向量表示。最后打印了特征向量表示和特征词汇。
特征向量表示是一个矩阵,每行表示一个文本数据的特征向量。特征词汇是一个列表,表示所有出现在文本数据中的单词。每个特征向量的每个维度对应一个特征词汇,值表示该单词在文本中的TF-IDF值。
(2)选择机器学习模型
在文本分类任务中,针对不同的数据集和问题,适合的机器学习模型可能会有所不同。
常用的分类算法:
- 朴素贝叶斯(Naive Bayes):朴素贝叶斯是一种基于概率的分类算法,通过计算每个特征在每个类别下的条件概率来进行分类。在文本分类中,朴素贝叶斯模型(如Multinomial Naive Bayes)常用于处理文本特征,特别适用于高维稀疏数据。
- 支持向量机(SVM):支持向量机是一种二分类模型,它通过将数据映射到高维特征空间,并在该空间中找到一个最优的超平面来进行分类。在文本分类中,通过将文本转化为特征向量表示,SVM可以有效地处理线性和非线性分类问题。
- 随机森林(Random Forest):随机森林是一种集成学习算法,它由多个决策树组成,通过投票或平均的方式来进行分类。在文本分类中,随机森林可以利用树的特性处理高维离散特征,并具有一定的抗过拟合能力。
朴素贝叶斯、支持向量机和随机森林这三种模型则可以用于二分类问题和多分类问题。朴素贝叶斯模型基于贝叶斯定理计算条件概率,支持向量机通过构造超平面对数据进行分类,随机森林则通过多个决策树的集成进行分类。
需要注意的是,虽然Logistic Regression通常用于二分类问题,但也可以通过一些技巧进行多分类问题的处理,例如使用一对多(One-vs-Rest)或一对一(One-vs-One)的策略来将多分类问题转化为多个二分类问题。
逻辑回归 Logistic Regression
LogisticRegression模型的简化实现示例代码:
import numpy as np
class LogisticRegression:
def __init__(self, learning_rate=0.01, num_iterations=1000):
self.learning_rate = learning_rate
self.num_iterations = num_iterations
self.weights = None
self.bias = None
def sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def fit(self, X, y):
num_samples, num_features = X.shape
# 初始化权重和偏置
self.weights = np.zeros(num_features)
self.bias = 0
# 梯度下降训练模型
for _ in range(self.num_iterations):
# 计算预测值
linear_model = np.dot(X, self.weights) + self.bias
y_pred = self.sigmoid(linear_model)
# 计算梯度
dw = (1 / num_samples) * np.dot(X.T, (y_pred - y))
db = (1 / num_samples) * np.sum(y_pred - y)
# 更新权重和偏置
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
def predict(self, X):
linear_model = np.dot(X, self.weights) + self.bias
y_pred = self.sigmoid(linear_model)
y_pred_class = np.where(y_pred > 0.5, 1, 0)
return y_pred_class
包含了fit和predict方法。fit方法用于训练模型,接受特征矩阵X和标签向量y作为输入,使用梯度下降法更新权重和偏置。predict方法用于预测新样本的分类,接受特征矩阵X作为输入,根据模型的权重和偏置计算预测值,并根据阈值0.5将预测值转换为分类标签。
以题目为例,回归模型如何将论文主题二分类:
首先,需要准备训练数据集,其中包含一些已知是否为医学论文的样本。每个样本都有一些特征,比如论文的标题、摘要、关键词等。此外,每个样本还有一个标签,表示该论文是否为医学论文,通常用0表示非医学论文,用1表示医学论文。
接下来,使用Logistic回归模型进行训练。训练过程中,模型会根据输入的特征和对应的标签来学习特征与标签之间的关系。具体来说,模型会根据特征的权重和偏置,通过一个sigmoid函数将线性模型的输出值转换为一个0到1之间的概率值。概率值大于0.5的样本被预测为医学论文,概率值小于等于0.5的样本被预测为非医学论文。
训练完成后,可以使用训练好的模型对新的论文进行分类预测。首先,提取新论文的特征,比如标题、摘要、关键词等。然后,将这些特征输入到训练好的模型中,模型会根据学习到的参数对新论文进行分类预测,输出一个概率值。根据概率值是否大于0.5,可以判断新论文是医学论文还是非医学论文。
总结起来,Logistic回归模型通过学习特征与标签之间的关系,将线性模型的输出值转换为一个概率值,从而进行二分类任务。对于医学论文的分类,可以使用该模型对论文的特征进行预测,并根据概率值判断论文是否为医学论文。
2 关键词提取问题
从论文标题、摘要作者等信息,提取出该论文关键词。看作是一个文本关键词识别任务,机器需要从给定的论文中识别和提取出与论文内容相关的关键词。
论文关键词划分为两类:
- 在标题和摘要中出现的关键词
- 没有在标题和摘要中出的关键词
在标题和摘要中出现的关键词:这些关键词是文本的核心内容,通常在文章的标题和摘要中出现,用于概括和提炼文本的主题或要点。对于提取这类关键词,可以采用以下方法:
- 词频统计:统计标题和摘要中的词频,选择出现频率较高的词语作为关键词。同时设置停用词去掉价值不大、有负作用的词语。
- 词性过滤:根据文本的词性信息,筛选出名词、动词、形容词等词性的词语作为关键词。
- TF-IDF算法:计算词语在文本中的词频和逆文档频率,选择TF-IDF值较高的词语作为关键词。
没有在标题和摘要中出现的关键词:这类关键词可能在文本的正文部分出现,但并没有在标题和摘要中提及。要提取这些关键词,可以考虑以下方法:
- 文本聚类:将文本划分为不同的主题或类别,提取每个主题下的关键词。
- 上下文分析:通过分析关键词周围的上下文信息,判断其重要性和相关性。
- 基于机器学习/深度学习的方法:使用监督学习或无监督学习的方法训练模型,从文本中提取出未出现在标题和摘要中的关键词。
#普通的词频统计方法:
# 引入分词器
from nltk import word_tokenize, ngrams
# 定义停用词,去掉出现较多,但对文章不关键的词语
stops = [
'will', 'can', "couldn't", 'same', 'own', "needn't", 'between', "shan't", 'very',
'so', 'over', 'in', 'have', 'the', 's', 'didn', 'few', 'should', 'of', 'that',
'don', 'weren', 'into', "mustn't", 'other', 'from', "she's", 'hasn', "you're",
'ain', 'ours', 'them', 'he', 'hers', 'up', 'below', 'won', 'out', 'through',
'than', 'this', 'who', "you've", 'on', 'how', 'more', 'being', 'any', 'no',
'mightn', 'for', 'again', 'nor', 'there', 'him', 'was', 'y', 'too', 'now',
'whom', 'an', 've', 'or', 'itself', 'is', 'all', "hasn't", 'been', 'themselves',
'wouldn', 'its', 'had', "should've", 'it', "you'll", 'are', 'be', 'when', "hadn't",
"that'll", 'what', 'while', 'above', 'such', 'we', 't', 'my', 'd', 'i', 'me',
'at', 'after', 'am', 'against', 'further', 'just', 'isn', 'haven', 'down',
"isn't", "wouldn't", 'some', "didn't", 'ourselves', 'their', 'theirs', 'both',
're', 'her', 'ma', 'before', "don't", 'having', 'where', 'shouldn', 'under',
'if', 'as', 'myself', 'needn', 'these', 'you', 'with', 'yourself', 'those',
'each', 'herself', 'off', 'to', 'not', 'm', "it's", 'does', "weren't", "aren't",
'were', 'aren', 'by', 'doesn', 'himself', 'wasn', "you'd", 'once', 'because', 'yours',
'has', "mightn't", 'they', 'll', "haven't", 'but', 'couldn', 'a', 'do', 'hadn',
"doesn't", 'your', 'she', 'yourselves', 'o', 'our', 'here', 'and', 'his', 'most',
'about', 'shan', "wasn't", 'then', 'only', 'mustn', 'doing', 'during', 'why',
"won't", 'until', 'did', "shouldn't", 'which'
]
# 定义方法按照词频筛选关键词
def extract_keywords_by_freq(title, abstract):#传入参数title、abstract
ngrams_count = list(ngrams(word_tokenize(title.lower()), 2)) + list(ngrams(word_tokenize(abstract.lower()), 2))
#↑分别对title和abstract进行向量化(分词处理),2表示两个两个词语放一起,再将结果合并
ngrams_count = pd.DataFrame(ngrams_count)#利用pandas奖结果变成表格
ngrams_count = ngrams_count[~ngrams_count[0].isin(stops)]#将停用词删除 并保留非停用词
ngrams_count = ngrams_count[~ngrams_count[1].isin(stops)]
ngrams_count = ngrams_count[ngrams_count[0].apply(len) > 3]#只保留长度大于3的词 一个词太短意义不大(医学领域)
ngrams_count = ngrams_count[ngrams_count[1].apply(len) > 3]
ngrams_count['phrase'] = ngrams_count[0] + ' ' + ngrams_count[1]#前面筛选出的是两行 0和1,再把他们拼到一行中
ngrams_count = ngrams_count['phrase'].value_counts()#合并后统计词频
ngrams_count = ngrams_count[ngrams_count > 1]#筛选出词频大于一的
return list(ngrams_count.index)[:5]#返回前五个最重要的作为结果
## 对测试集提取关键词
test_words = []#定义一个空列表
for row in test.iterrows():#一行一行提取信息
# 读取第每一行数据的标题与摘要并提取关键词
prediction_keywords = extract_keywords_by_freq(row[1].title, row[1].abstract)
# 利用文章标题进一步提取关键词
prediction_keywords = [x.title() for x in prediction_keywords]#可以删掉试下 好像评分变高
# 如果未能提取到关键词
if len(prediction_keywords) == 0:
prediction_keywords = ['A', 'B']#就随便用A、B来代替掉
test_words.append('; '.join(prediction_keywords))
test['Keywords'] = test_words
test[['uuid', 'Keywords', 'label']].to_csv('submit_task2.csv', index=None)
提分入手:
使用其他向量化模型;
train的过程中可修改fit方法默认的batch_size、epoch;
对测试集处理过程中,除了标题和摘要,还可以添加正文中的关键词,来扩大关键词适配的面积
class3 进阶:使用预训练的BERT模型进行建模
Bert原理与技巧视频讲解:https://www.bilibili.com/video/BV1nX4y1E7Sn/
视频配套PPT与代码::https://datawhaler.feishu.cn/drive/folder/M25PfywzhlsImXdrmFqcxenRn9c
1 文本二分类问题
导入前置依赖
#导入前置依赖
import os
import pandas as pd
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
# 用于加载bert模型的分词器
from transformers import AutoTokenizer
# 用于加载bert模型
from transformers import BertModel
from pathlib import Path
设置全局配置
batch_size = 16#决定一次训练选取的文本长度
# 文本的最大长度
text_max_length = 128#可以适当增大
# 总训练的epochs数,我只是随便定义了个数
epochs = 100#可以改小
# 学习率
lr = 3e-5
# 取多少训练集的数据作为验证集:在将数据集划分为训练集和验证集时,验证集所占的比例 表示90%用来训练 10%用来验证
validation_ratio = 0.1
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 每多少步,打印一次loss
log_per_step = 50
# 数据集所在位置
dataset_dir = Path("./基于论文摘要的文本分类与关键词抽取挑战赛公开数据")
os.makedirs(dataset_dir) if not os.path.exists(dataset_dir) else ''
# 模型存储路径
model_dir = Path("./model/bert_checkpoints")
# 如果模型目录不存在,则创建一个
os.makedirs(model_dir) if not os.path.exists(model_dir) else ''
print("Device:", device)
进行数据读取与数据预处理
和baseline内容一样
# 读取数据集,进行数据处理
pd_train_data = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/train.csv')
pd_train_data['title'] = pd_train_data['title'].fillna('')
pd_train_data['abstract'] = pd_train_data['abstract'].fillna('')
test_data = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/test.csv')
test_data['title'] = test_data['title'].fillna('')
test_data['abstract'] = test_data['abstract'].fillna('')
pd_train_data['text'] = pd_train_data['title'].fillna('') + ' ' + pd_train_data['author'].fillna('') + ' ' + pd_train_data['abstract'].fillna('')+ ' ' + pd_train_data['Keywords'].fillna('')
test_data['text'] = test_data['title'].fillna('') + ' ' + test_data['author'].fillna('') + ' ' + test_data['abstract'].fillna('')+ ' ' + pd_train_data['Keywords'].fillna('')
# 从训练集中随机采样测试集
validation_data = pd_train_data.sample(frac=validation_ratio)
train_data = pd_train_data[~pd_train_data.index.isin(validation_data.index)]
构建训练所需的dataloader与dataset
# 构建Dataset
class MyDataset(Dataset):
def __init__(self, mode='train'):#init负责数据初始化
super(MyDataset, self).__init__()
self.mode = mode
# 拿到对应的数据
if mode == 'train':
self.dataset = train_data
elif mode == 'validation':
self.dataset = validation_data
elif mode == 'test':
# 如果是测试模式,则返回内容和uuid。拿uuid做target主要是方便后面写入结果。
self.dataset = test_data
else:
raise Exception("Unknown mode {}".format(mode))
def __getitem__(self, index):
# 取第index条
data = self.dataset.iloc[index]
# 取其内容
text = data['text']
# 根据状态返回内容
if self.mode == 'test':
# 如果是test,将uuid做为target
label = data['uuid']
else:
label = data['label']
# 返回内容和label
return text, label
def __len__(self):
return len(self.dataset)
train_dataset = MyDataset('train')
validation_dataset = MyDataset('validation')
train_dataset.__getitem__(0)#查看第一行数据
#获取Bert预训练模型
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")#获取分词器
构造Dataloader
bert模型是如何具体实现文本向量化的:下节课讲
#我们需要定义一下collate_fn,在其中完成对句子进行编码、填充、组装batch等动作:
def collate_fn(batch):
"""
将一个batch的文本句子转成tensor,并组成batch。
:param batch: 一个batch的句子,例如: [('推文', target), ('推文', target), ...]
:return: 处理后的结果,例如:
src: {'input_ids': tensor([[ 101, ..., 102, 0, 0, ...], ...]), 'attention_mask': tensor([[1, ..., 1, 0, ...], ...])}
target:[1, 1, 0, ...]
"""
text, label = zip(*batch)#把一个batch中包含的text、label取出来
text, label = list(text), list(label)#转换成列表
# src是要送给bert的,所以不需要特殊处理,直接用tokenizer的结果即可
# padding='max_length' 不够长度的进行填充
# truncation=True 长度过长的进行裁剪
src = tokenizer(text, padding='max_length', max_length=text_max_length, return_tensors='pt', truncation=True)
return src, torch.LongTensor(label)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
validation_loader = DataLoader(validation_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
inputs, targets = next(iter(train_loader))
print("inputs:", inputs)
print("targets:", targets)
定义预测模型
#定义预测模型,该模型由bert模型加上最后的预测层组成
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 加载bert模型
self.bert = BertModel.from_pretrained('bert-base-uncased', mirror='tuna')#引入bert模型
# 最后的预测层
self.predictor = nn.Sequential(
nn.Linear(768, 256),#利用转换槽将768维度最终都转换成0/1
nn.ReLU(),
nn.Linear(256, 1),#最终都转换成0/1
nn.Sigmoid()#reLU和sigmoid用于防止过拟合
)
def forward(self, src):
"""
:param src: 分词后的推文数据
"""
# 将src直接序列解包传入bert,因为bert和tokenizer是一套的,所以可以这么做。
# 得到encoder的输出,用最前面[CLS]的输出作为最终线性层的输入
outputs = self.bert(**src).last_hidden_state[:, 0, :]
# 使用线性层来做最终的预测
return self.predictor(outputs)
bert模型会在文本前插入一个CLS符号,并将该符号对应的输出向量作为整篇文本的予以表示,用于文本分类。
可以理解为:与文本中已经有的其他字、词相比较,这个无明显语义信息的符号回更公平的融合文本中各个字词的语义信息。
model = MyModel()#加载模型 送到gpu 利用服务来做向量化推理
model = model.to(device)
定义出损失函数和优化器
#定义出损失函数和优化器。这里使用Binary Cross Entropy:
criteria = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 由于inputs是字典类型的,所以需要定义一个辅助函数帮助to(device)
def to_device(dict_tensors):
result_tensors = {}
for key, value in dict_tensors.items():
result_tensors[key] = value.to(device)#把 key, value取出来,把value值放入gpu里面
return result_tensors
定义验证方法
#定义一个验证方法,获取到验证集的精准率和loss
def validate():
model.eval()#先启动模型的验证方式
total_loss = 0.#定义两个变量 统计正确率、损失
total_correct = 0
for inputs, targets in validation_loader:
inputs, targets = to_device(inputs), targets.to(device)#把他俩放入cpu中进行输出
outputs = model(inputs)
loss = criteria(outputs.view(-1), targets.float())
total_loss += float(loss)#统计全局loss
correct_num = (((outputs >= 0.5).float() * 1).flatten() == targets).sum()
total_correct += correct_num#统计正确率 再进行总结
return total_correct / len(validation_dataset), total_loss / len(validation_dataset)
模型训练
# 首先将模型调成训练模式
model.train()
# 清空一下cuda缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()
# 定义几个变量,帮助打印loss
total_loss = 0.
# 记录步数
step = 0
# 记录在验证集上最好的准确率
best_accuracy = 0
# 开始训练
for epoch in range(epochs):
model.train()
for i, (inputs, targets) in enumerate(train_loader):
# 从batch中拿到训练数据
inputs, targets = to_device(inputs), targets.to(device)
# 传入模型进行前向传递
outputs = model(inputs)
# 计算损失
loss = criteria(outputs.view(-1), targets.float())
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += float(loss)
step += 1
if step % log_per_step == 0:#对于损失进行梯度反馈、优化
print("Epoch {}/{}, Step: {}/{}, total loss:{:.4f}".format(epoch+1, epochs, i, len(train_loader), total_loss))
total_loss = 0
del inputs, targets
# 一个epoch后,使用过验证集进行验证
accuracy, validation_loss = validate()
print("Epoch {}, accuracy: {:.4f}, validation loss: {:.4f}".format(epoch+1, accuracy, validation_loss))
torch.save(model, model_dir / f"model_{epoch}.pt")
# 保存最好的模型
if accuracy > best_accuracy:
torch.save(model, model_dir / f"model_best.pt")
best_accuracy = accuracy
#加载最好的模型,然后进行测试集的预测
model = torch.load(model_dir / f"model_best.pt")
model = model.eval()#启用评估模式
#加载test数据集 加载他的DataLoader
test_dataset = MyDataset('test')
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
输出结果
把测试数据送入模型,得到结果,最后输出为要求的格式
results = []
for inputs, ids in test_loader:
outputs = model(inputs.to(device))
outputs = (outputs >= 0.5).int().flatten().tolist()
ids = ids.tolist()
results = results + [(id, result) for result, id in zip(outputs, ids)]
#输出部分
test_label = [pair[1] for pair in results]
test_data['label'] = test_label
test_data[['uuid', 'Keywords', 'label']].to_csv('submit_task1.csv', index=None)
2 关键词提取问题
当我们想从特定文档中了解关键信息时,通常会转向关键词提取(keyword extraction)。关键词提取(keyword extraction)是提取与输入文本最相关的词汇、短语的自动化过程。
目前已经有很多的集成工具库类似KeyBERT,是专门用于关键词提取的,已经能够达到非常好的效果,但是在这里我们选择使用原生的BERT创建自己的关键词提取模型,来帮助大家更好的完成文本关键词提取的整个流程。(这里的方法比较笨)
导入前置依赖
# 导入pandas用于读取表格数据
import pandas as pd
# 导入BOW(词袋模型),可以选择将CountVectorizer替换为TfidfVectorizer(TF-IDF(词频-逆文档频率)),注意上下文要同时修改,亲测后者效果更佳
from sklearn.feature_extraction.text import TfidfVectorizer
# 导入Bert模型
from sentence_transformers import SentenceTransformer
# 导入计算相似度前置库,为了计算候选者和文档之间的相似度,我们将使用向量之间的余弦相似度,因为它在高维度下表现得相当好。
from sklearn.metrics.pairwise import cosine_similarity#用余弦相似度来求解
# 过滤警告消息
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)
读取数据集并预处理
# 读取数据集
test = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/test.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')
test['text'] = test['title'].fillna('') + ' ' +test['abstract'].fillna('')
stop.txt停用词文件链接:链接: https://pan.baidu.com/s/1mQ50_gsKZHWERHzfiDnheg?pwd=qzuc 提取码: qzuc
# 定义停用词,去掉出现较多,但对文章不关键的词语
stops =[i.strip() for i in open(r'stop.txt',encoding='utf-8').readlines()]
Bert预训练模型方面,这里我们使用distiluse-base-multilingual-cased,因为它在相似性任务中表现出了很好的性能,这也是我们对关键词/关键短语提取的目标!
由于transformer模型有token长度限制,所以在输入大型文档时,你可能会遇到一些错误。在这种情况下,您可以考虑将您的文档分割成几个小的段落,并对其产生的向量进行平均池化(mean pooling ,要取平均值)。
model = SentenceTransformer(r'xlm-r-distilroberta-base-paraphrase-v1')#选择的这个bert模型
提取关键词
这里我的思路是获取文本内容的embedding,同时与文本标题的embedding进行比较,文章的关键词往往与标题内容有很强的相似性,为了计算候选者和文档之间的相似度,我们将使用向量之间的余弦相似度,因为它在高维度下表现得相当好。
test_words = []
for row in test.iterrows():
# 读取第每一行数据的标题与摘要并提取关键词
# 修改n_gram_range来改变结果候选词的词长大小。例如,如果我们将它设置为(3,3),那么产生的候选词将是包含3个关键词的短语。
n_gram_range = (2,2)#这样筛选出的是两个连在一块的短语
# 这里我们使用TF-IDF算法来获取候选关键词
count = TfidfVectorizer(ngram_range=n_gram_range, stop_words=stops).fit([row[1].text])
candidates = count.get_feature_names_out()
# 将文本标题以及候选关键词/关键短语转换为数值型数据(numerical data)。我们使用BERT来实现这一目的
title_embedding = model.encode([row[1].title])
candidate_embeddings = model.encode(candidates)
# 通过修改这个参数来更改关键词数量
top_n = 15
# 利用文章标题进一步提取关键词
distances = cosine_similarity(title_embedding, candidate_embeddings)
keywords = [candidates[index] for index in distances.argsort()[0][-top_n:]]
if len( keywords) == 0:
keywords = ['A', 'B']
test_words.append('; '.join( keywords))
得到结果,最后输出为要求格式
test['Keywords'] = test_words
test[['uuid', 'Keywords']].to_csv('submit_task2.csv', index=None)















 1717
1717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









