






在这一周,我主要是通过观看了吴恩达教授的机器学习,以下是我在这一周的学习笔记,继续努力,继续学习,继续进步!
目录
机器学习
在上一周了解了强化学习的一些基本概念,在这一周继续学习深入强化学习。
强化学习的回报
上周了解了强化学习的概念,了解了奖励和惩罚,我们应该如何知道一组特定的奖励比另外一组奖励更好还是更差,举一个简单的例子,一种是脚边就有5块钱,一种是我们花半个小时去另外一个地方去拿10块钱,如果只能选择一个的话,我们应该是选择哪一个呢?
对于强化学习的回报,我们认为抓住了可以更快获得的奖励比需要很长时间才能获得的奖励更好,对于上面的例子,我们认为脚边的5块钱要比需要更长时间的10块钱更好。
我们在这里需要引入折扣因子的概念,它是一个小于1的数字,一般记为 Gamma,一般为0.9,0.99,0.999接近于1的数字,去往下一个状态时,需要在前面乘以Gamma的几次方,去往的第一个状态乘以Gamma的一次方,去往第二个状态乘以Gamma的二次方,以此类推,一直到自己想去的状态,如下图所示:

假设我们处于4号状态,我们要前往1号状态,根据前面的回报值计算,最终去往1号状态的回报值为72.9,我们可以看出,越早获得奖励总回报值会越高,如果折扣因子为0.5时,会严重降低未来的奖励回报值,如图我们只能得到12的回报值,意思也就是花的时间越长,收益也就会越低,如果存在多个奖励就是越容易拿到的奖励更有吸引力。
我们要根据所处的状态去选择我们要采取的行动的不同方式,如下图例子:

如果所有的状态都要去往1号状态的话,那么对于离1号状态更近的状态,回报值更高;如果所有的状态都要去往6号状态的话,那么对于离6号状态更近的状态,回报值更高。
所以我们可以去进行比较这两种方式的回报值,对于3号状态,往1号状态走的回报值为25,往6号状态走的回报值为5,所以在2号状态时要选择往1号状态走;对于5号状态,往1号状态走的回报值为6.25,往6号状态走的回报值为20,所以在5号状态时要选择往6号状态走。
往左或者右基于最后回报分摊到每个状态上,比较选择最佳的方向。
强化学习的回报是系统获得的奖励总和,由折扣因子加权,若回报是负的,那么折扣因子实际上会激励系统将负奖励尽可能推迟到未来。
强化学习中的策略
在强化学习中,我们的目标是提出一个称为策略Pi的函数,工作是将任何状态s作为输入并将映射到它希望我们采取的某个动作a。
Pi应用于状态s,告诉我们在该状态下采取什么行动。
根据我们上一节所提到的回报,计算出某个状态下应该执行的动作,如下图所示:
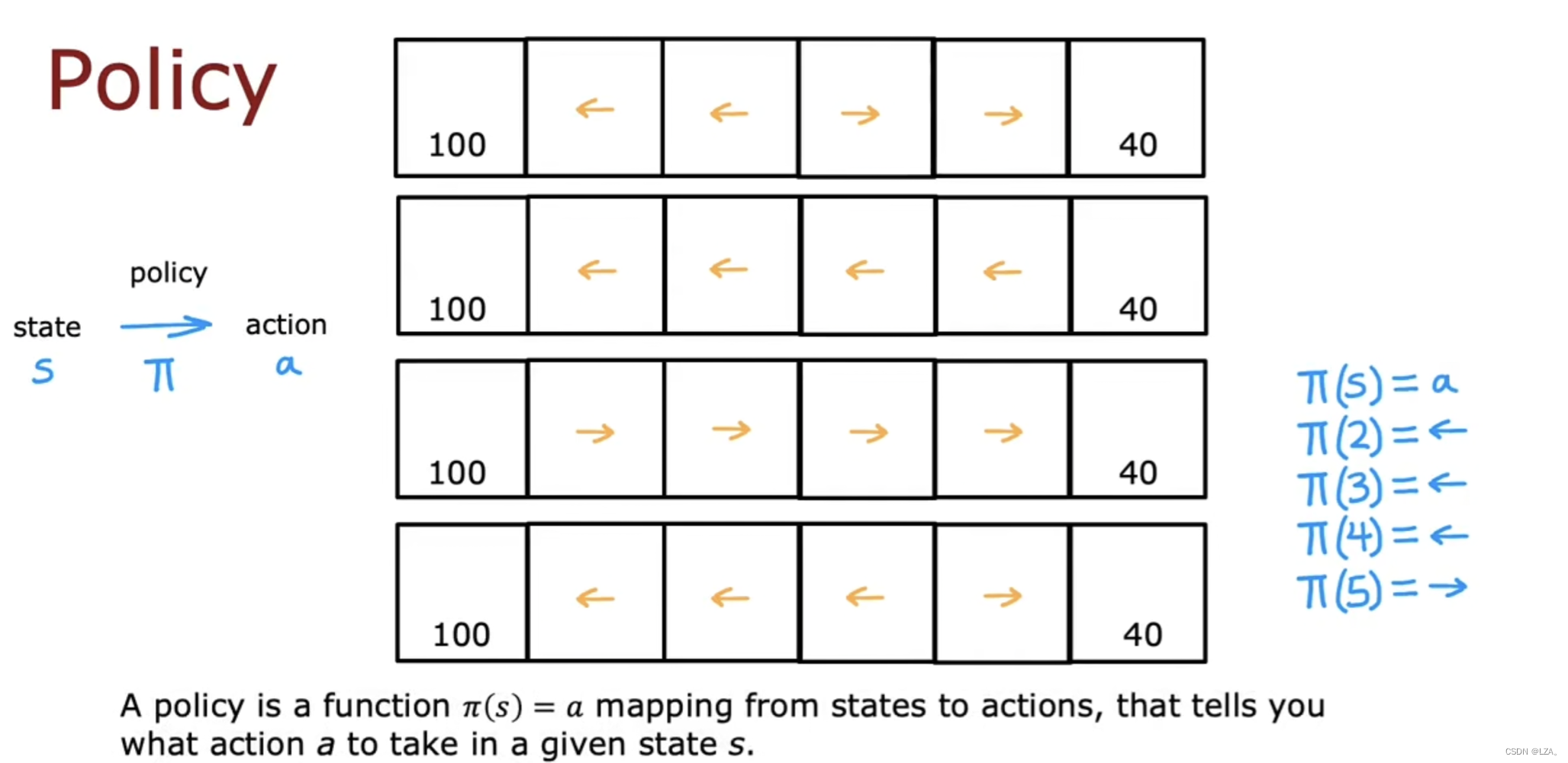
比如我们在2状态下应该往左走,我们就记为pi(2)=⬅️;我们在5状态下应该往右走,我们就记为pi(5)=➡️
强化学习的目标是找到一个策略pi,告诉每个状态下采取什么行动以最大化回报。
审查关键概念
我们需要了解到对于我们之前提到的例子,火星探测器,我们举的例子有6个状态,所需要的动作只有两种,向左走,或者向右走,我们的奖励只有100,0,40,折扣因子我们记为0.5,当然也有自己每个状态下的回报公式;如果对于一个直升机来说,它的状态可能有更多种,就是为直升机的位置,它所需要的动作并非只有一两种,而是如何移动控制的动作,我们的奖励只有1,-1000,当它做的正确的时我们奖励+1,当它做的错误的时候我们奖励-1000,也就是惩罚,折扣因子我们记为0.99;如果对于下棋的强化学习来说,它的状态为棋子在棋盘的位置,它的动作为移动的可能性,我们的奖励有+1,0,-1,当它赢得比赛时我们奖励+1,当它与对手打成平局时,我们奖励+0,当它输掉比赛时,我们奖励-1,折扣因子我们记为0.995,以此来进行强化学习。
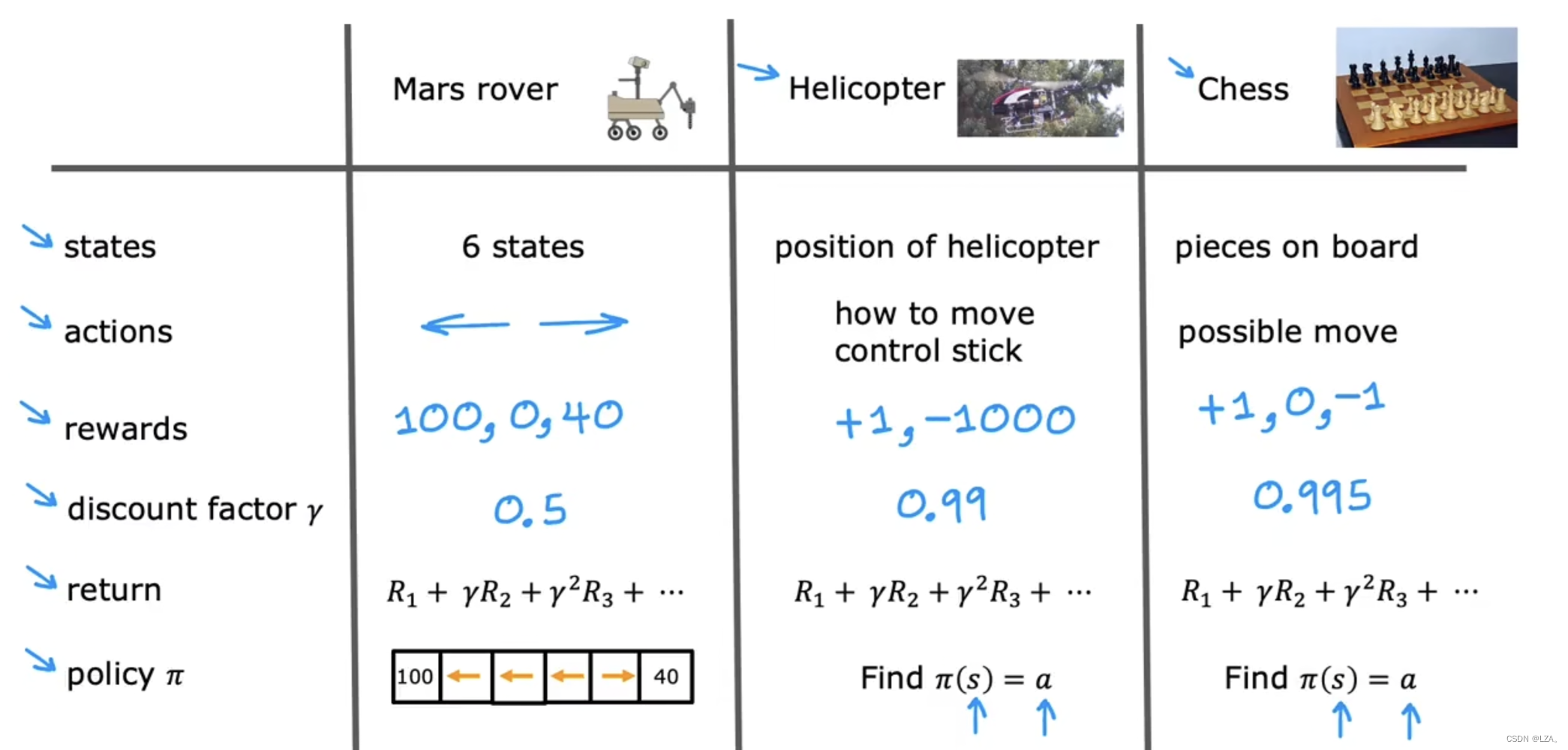
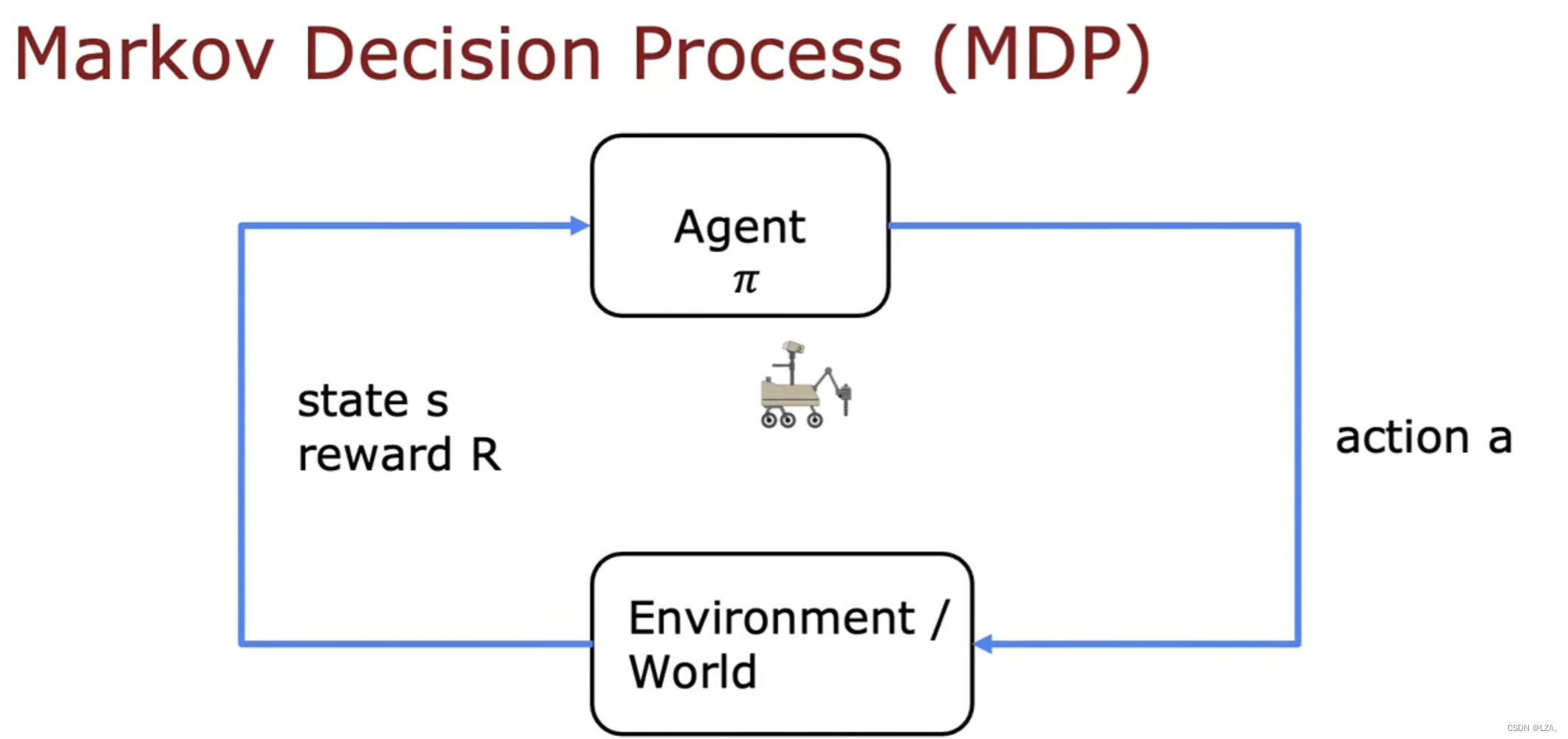
这种强化学习应用程序的形式实际上有一个名字,中文名字叫做马尔可夫决策过程,英文名字叫做Markov Decision Process,简称MDP,未来仅取决于当前的状态,不取决于达到当前状态前发生的事情,也就是我们不看之前的状态。
它的决策过程如下:
状态-动作价值函数
强化学习箭头尝试计算一个关键量,称为状态动作价值函数,通常用Q表示,处于在该状态下采取的工作
Q(s,a)给出一个等于回报的数字,s表示状态,a表示下一步的动作。
每一次迭代选择最优的动作,通过计算知道最佳路径,并非是知道路径再计算,先找到一个状态s,在做出行动a1,a2等等,先后去比较这些行动。

比如我们的2号状态,若动作往左,则回报价值为50,若动作向右,去往3状态又返回前往1号状态,则回报价值为12.5,以此类推迭代计算每个状态的回报价值。
Q函数可以告诉我们回报价值是什么,计算了不同动作的回报,可以通过比较得到回报最高的动作,也就是从任何状态s获得的最佳可能回报是Q(s,a)的最大值,查看不同动作,使Q(s,a)最大。
比如在2号状态,往左的回报价值为50,往右的回报价值为12.5,因此如果我们在2号状态,我们应该选择往左走;若在5号状态,往左的回报价值为6.25,往右的回报价值为20,因此如果我们在5号状态,我么应该选择往右走。
贝尔曼方程
贝尔曼方程也叫做动态规划方程,它可以帮助我们计算状态动作价值函数。
所谓状态动作价值函数是Q(s,a),从状态s开始,执行一次操作a后表现最佳,则返回,是一个递归的过程。
我们将s记为当前状态,a记为当前操作,s‘记为下一个状态,a’记为下一个动作,那么状态动作价值函数的计算方程如下:

这就是贝尔曼方程,也是一个递归方程,为当前状态的回报加上折扣因子乘以下一个状态的最大回报值,以此类推。
原理是把终点的期望按照对应的权重分配给了每个状态,利用贝尔曼方程去计算状态价值函数。
如下是通过贝尔曼方程计算的状态价值函数

我们发现,通过贝尔曼方程去计算状态价值函数,与我们之前通过简单的回报公式算出来的值是一样的,这个也验证了贝尔曼方程的准确性。
通过我们的贝尔曼方程,可以将它分解为两部分,第一部分是立即奖励,即当前状态下的奖励,第二部分是折扣因子gamma乘以从下一个状态开始获得的回报,这两部分的总和就是当前状态s的总回报,这是贝尔曼方程的本质,是一个递归过程,我们通过贝尔曼方程也可以去转化为我们原有的计算回报的公式。

这当然也是为动态规划,核心是状态的转移,下一个状态的最优解是计算下一个状态的所有解中的最大值。

模拟随机环境
在我们采取行动的时候,结果并非是完全可靠的,比如当我们向左行驶的时候,可能会出现滑坡等一些我们不可预知的风险,可能会因此去往我们的反方向,让机器人向左走,它有90%的可能向左走,10%的可能向右走。
所以在随机强化学习过程中,感兴趣的不是最大化回报,那是一个随机的数字,我们感兴趣的而是最大化折扣奖励的平均值,也是预期收益。
根据折扣奖励总和最大化我们期望获得的平均收益,选择策略Pi来最大化折扣奖励的平均值。

所以期望回报的贝尔曼方程需要在第二部分是折扣因子gamma乘以从下一个状态开始获得的回报的期望,也是平均值,来得到随机强化学习的预期收益。

连续状态空间应用
在我们之前的示例,是一组离散的状态,例如我们之前只有6个状态,意味着处于6个可能的位置,而我们大多数可以处于非常大量的连续值位置中的任何一个,机器人所处的位置可能不止是离散状态,它可以位于大量连续位置中的任何一个。位置可以用一个数字来表示,比如2.7公里或者4.8公里,或者0到6之间的其他任何数字。
比如说自动驾驶,我们可以利用强化学习来实现自动驾驶技术,但是它的状态包括X位置,Y位置,方向,在X方向的速度,在Y方向的速度,角度变化的速度这6个向量,如下图所示:

又比如直升机,它的每个状态包括位置XYZ,横滚、俯仰,偏航,以及控制直升机的各个位置方向的速度。

这些状态不是离散值,而是一个数字向量。
学习状态值函数
学习状态值函数的关键思想是训练一个神经网络来计算或者近似状态s和动作a的状态价值函数Q,然后让我们去选择好的动作。
神经网络的输入是当前的状态和当前的动作,最后计算当前状态和当前动作下的Q(s,a)
其中s和a用12个数字的向量,8个数字用于状态,4个数字利用one-hot编码为我们的动作,因为我们的动作为四种之一,什么都不做,左喷射,中间喷射,右边喷射,这四种,这个是我们神经网络的输入,称为X,神经网络的工作就是输出Q(s,a)
强化学习与监督学习不同,但我们要做的不是输入状态并让他输出动作,我们是需要输入一个状态和动作,输出Q(s,a),并在强化学习算法中使用神经网络,一共4个动作,分别计算这个状态和动作的状态价值函数,对于这4个动作,选择Q(s,a)的最大值相应的动作a。如下图:
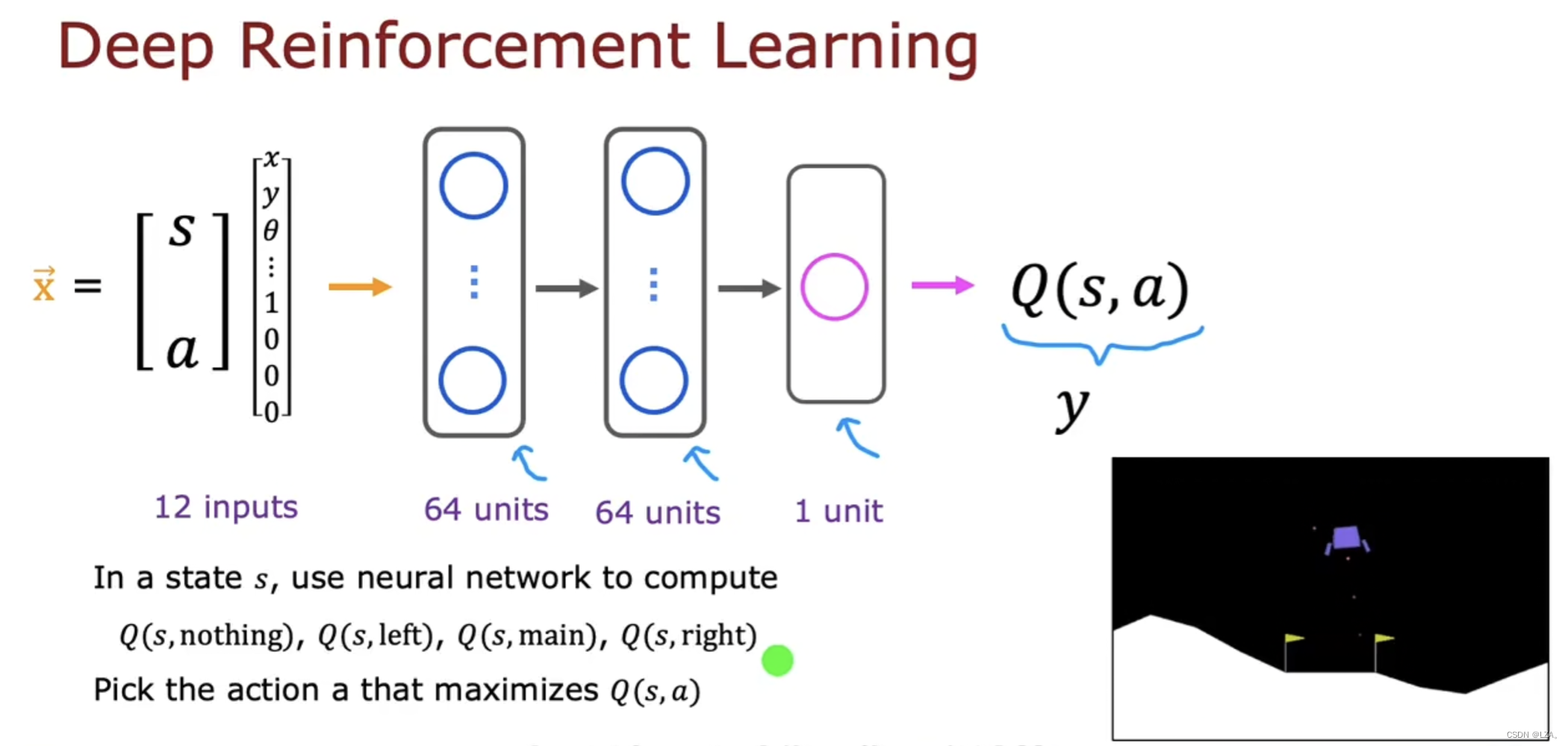
那么我们应该如何训练神经网络来输出Q(s,a)呢?
神经网络的工作是输入X,也就是状态s和动作a,并尝试预测Q(s,a),也可以利用贝尔曼方程计算。
这同时也是动态规划,每一步都选择最优的,整体也就是最优的。
我们是从随机猜测开始的,通过Q(s,a)来计算出我们需要的y,最终得到我们的数据集,X=(s,a),y=Q(s,a),Q函数是我们假设的,最终会迭代一个好的。
一边行动,一边构造数据集,然后在学习。
X是具有12个特征的输入,y只是个数字,使用均方误差损失来训练一个新网络,尝试将y预测为输入x的函数。具体如下图:

x向量为每次的状态和动作,y向量为每次的状态价值函数
我们把仅存储最近示例的技术称为重放缓冲区(Replay Buffer),把Q函数当成参数w和b,用神经网络来去拟合。

我们把这个称为DQN算法,(Deep Q-NetWork),使用深度学习和神经网络训练模型来学习Q函数。
算法改进:改进的神经网络架构
在上一节学习的DQN算法在之前是输入12个数字,其中8个数字为状态,4个数字利用one-hot编码代表动作,之后在神经网络中进行四次推理技术四个值,再选择最大的那个Q值动作a,这样的话很低效,必须要从每个状态要进行四次推理,很麻烦。
所有我们要改进神经网络架构,训练单个神经网络输出所有的四个Q值更有效
之前的神经网络架构是这样的,一次只能输出一个Q值,效率低
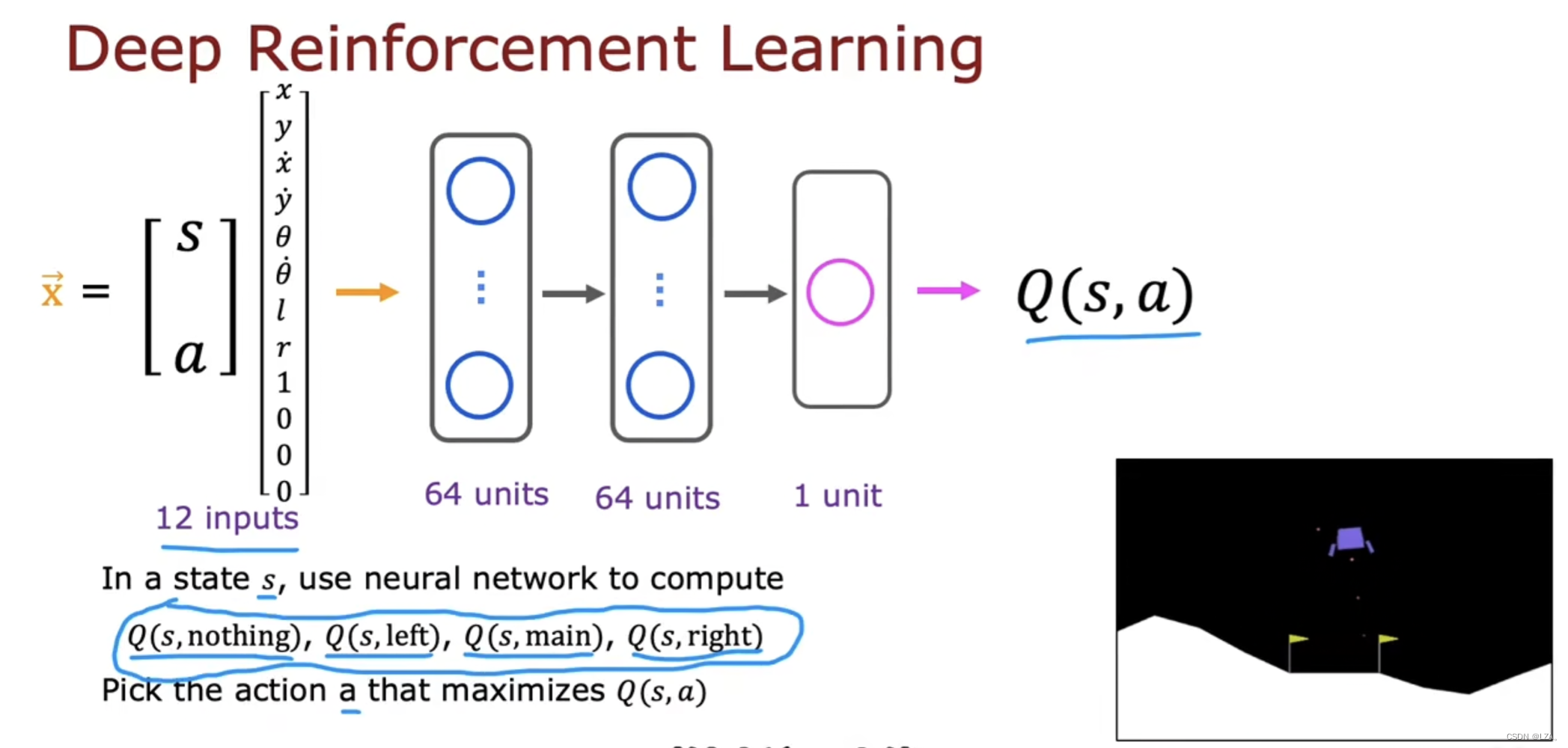
改进后的神经网络如下,输入对应状态的8个数字,通过神经网络输出单元有4个,输出每一个动作的Q值
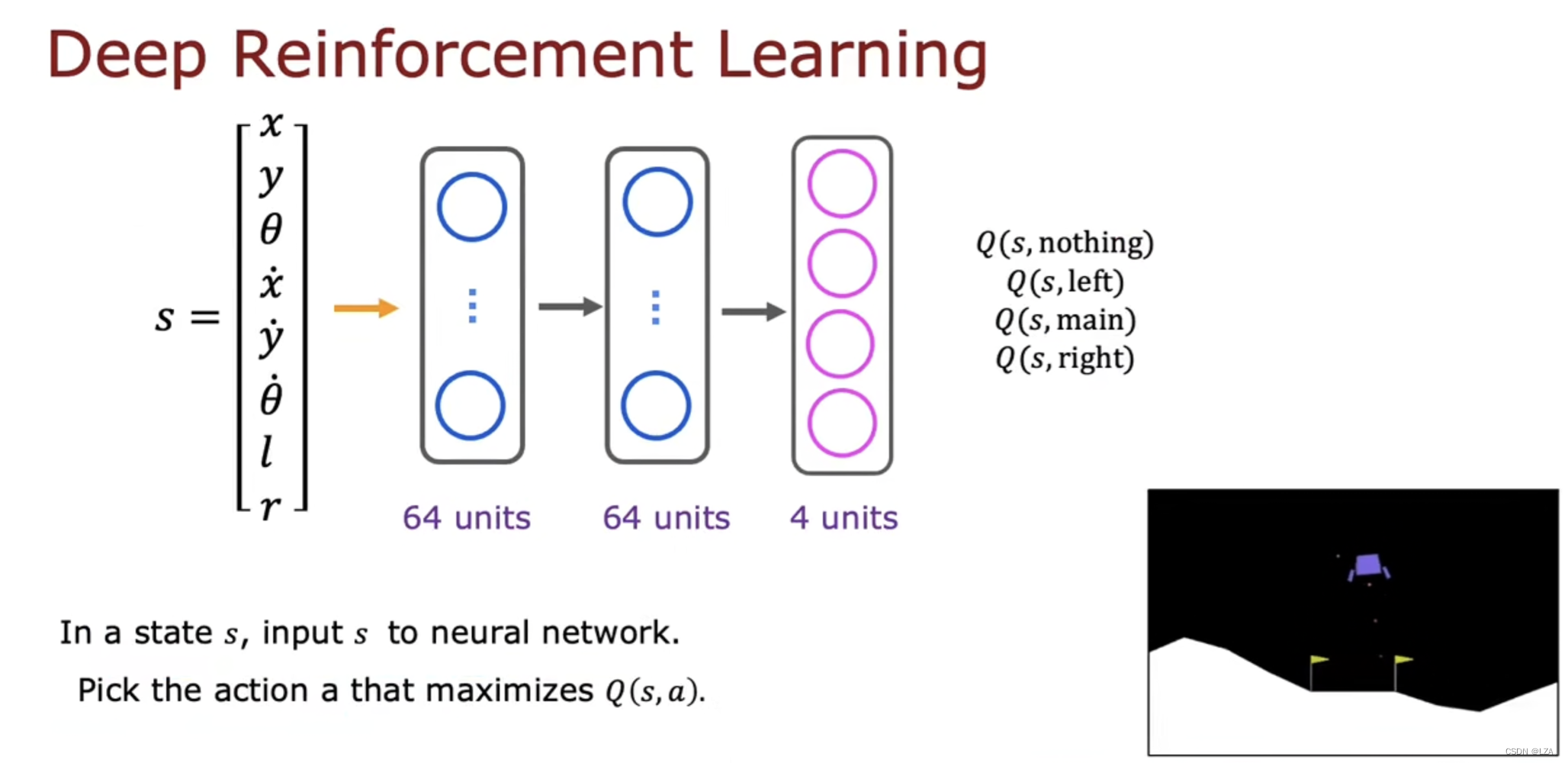
同时计算处于状态s所有四种可能动作的Q值,非常快速选择最大化的动作a,就可以只选择最大值来计算贝尔曼方程右侧的值。
个人总结
本周学习了强化学习,对强化学习有了基本认识,下一周将深入深度学习,学习深度学习的一些算法,到现在为止,机器学习的一些基本概念,以及一些基本算法已经了解,但是仍然需要回顾复习,要做到不仅要会用,还要知道是怎么来的,一定要了解其数学原理,还要多敲代码,要做到熟稔于心,继续努力,继续学习,继续进步!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









