






机器学习、深度学习基础知识记录
1.3 损失函数
评价模型的预测值和真实值不一样的程度,损失函数越小,通常模型的性能越好。
损失函数 和 目标函数 区别


分类:
-
经验风险损失函数 :指预测结果和实际结果的差别
-
结构风险损失函数 :经验风险损失函数 加上正则项
1.3.1 0-1 损失函数

1.3.2 对数损失函数


1.3.3 MAE / L1 loss
(Mean Absolute Error:平均绝对误差、绝对值损失)
又称 曼哈顿距离,表示残差的绝对值之和。
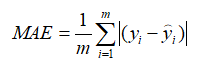

1.3.4 MSE / L2 loss
(Mean Square Error:均方误差、平方值损失)
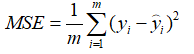
又被称为 欧氏距离,是一种常用的距离度量方法,通常用于度量数据点之间的相似度。

1.3.5 RMSE
(Root Mean Square Error:均方根误差)
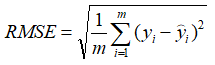
1.3.6 Smooth L1

1.3.7 Hinge loss
用于 SVM
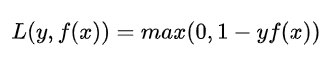
y 为目标值,f(x) 为预测值。
在样本被正确分类同时函数间隔大于1时,合页损失才会是0.否则损失就是1-y(wx+b)。
不仅需要分类正确,并且确信度足够高时,损失才为 0。
更专注于整体的误差,健壮性相对较高,对异常点、噪声不敏感,但它没太好的概率解释。
1.3.8 最小二乘法


数学特性导致不适合作分类的损失函数
(求导可知,距离越远,下降越慢。)
1.3.9 MLE & LL & NLL
MLE
极大似然估计(Maximum likelihood estimation,MLE)
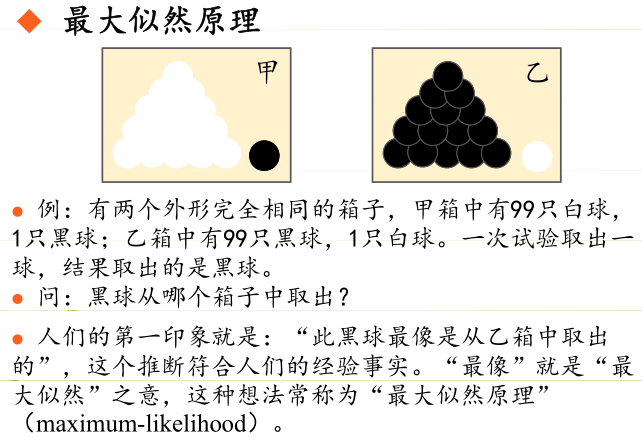
极大似然估计提供了一种给定观察数据来评估模型参数 的方法,即:“模型已定,参数未知 ”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
方程的 解只是一个估计值,只有在样本数趋于无限多的时候,它才会接近于真实值。
公式:
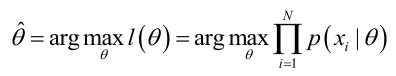
LL
对数似然(LL,log likelihood)
似然函数是多数相乘 的形式,计算容易造成下溢,不方便求导。通常对其求对数,不改变单调性,方便求极值点。使用 对数似然(log-likelihood),连乘就可以写成连加的形式:

NLL
负对数似然(NLL,negative log likelihood)
概率分布 P 取值为 [0, 1],取对数后,取值为 [-\infty, 0];再取负变为 [0,\infty],如下图所示:

我们希望似然(MLE)越大越好,取完负数后(NLL)越小越好。
1.3.10 交叉熵 (cross-entropy)
交叉熵是信息论中的一个重要概念,主要用于度量两个概率分布间的差异性。
信息量
信息是用来 消除不确定性 的东西”,也就是说衡量信息量的大小就是看这个信息消除不确定性的程度。
信息量的大小与信息发生的概率成反比。

信息熵
也被称为熵,表示所有信息量的期望。
可表示为:(这里的 X 是一个离散型随机变量)

相对熵 ( KL 散度 )
用来 衡量两个 概率分布的相似性 的一个 (非对称性)度量指标。

常用 P(x) 来表示样本的真实分布,Q(x) 来表示模型所预测的分布。
KL散度越小,表示 P(x) 与 Q(x) 的分布更加接近,即模型效果越好。
KL 具有
-
非对称性
-
非负性
-
不确定性
-
不准确性

交叉熵


D_{KL} (P || Q) 表示以 P 为基准的相对熵,展开后,后一项为 P 系统的熵(不变)。
总结
-
交叉熵 能 衡量同一个随机变量中的两个不同概率分布的差异程度。交叉熵的值越小,模型预测效果就越好。
-
交叉熵 常与 softmax 标配,softmax 使其多个分类的预测值和为1,再通过交叉熵来计算损失。
-
具有“ 误差大的时候,权重更新快;误差小的时候,权重更新慢 ”的良好性质。
负对数似然和交叉熵有高度的(形式)相似性,但其本质(似然,熵)不同。其实,在分类问题中,所使用的的交叉熵损失,本质就是负对数似然。
交叉熵函数的最小化 的本质就是 对数似然函数的最大化。
1.3.11 Focal Loss
解决难易样本不均衡的问题,注意有区别于正负样本不均衡的问题。难易样本分为四个类型:

易分样本虽然损失很低,但是数量太多,对模型的效果提升贡献很小,模型应该重点关注那些难分样本,因此需要把置信度高的损失再降低一些

1.3.12 损失函数的具体应用
















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









