






背景: 在银行业务中,客户投诉是一个重要的指标,它直接关系到客户满意度和银行服务质量。为了提前识别可能引起投诉的因素并采取措施,本文构建了一个机器学习模型来预测客户是否会提出投诉。在这个场景中,本文关注两个关键特征:‘refund’(退款金额)和’compensation’(赔偿金额)。
模型构建: 本文使用逻辑回归模型来预测投诉的可能性。由于银行客户可能更关注某一个指标,比如:退款金额,本文假设退款金额对于预测投诉的权重应该高于赔偿金额。为了找到最佳的特征权重,本文编写了一个Python脚本来遍历可能的权重组合,并评估它们在测试集上的准确率。
权重调整: 本文对于更注重的指标为a:通过遍历权重 a 的范围从0.5到1来寻找最佳的权重组合。这里的 a 代表退款金额的权重,而 compensation 的权重 b 则被计算为 1 - a,以确保两个特征权重的总和为1(a+b=1)。在每次迭代中,本文使用当前的权重组合来训练模型,并计算在测试集上的准确率。
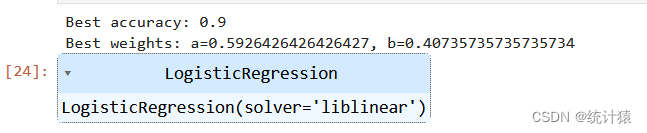
结果分析: 通过权重搜索,本文找到了在测试集上准确率最高的权重组合。这个组合告诉本文,在预测客户投诉时,退款金额和赔偿金额应该如何加权。这种方法不仅帮助本文优化了模型的性能,还提供了对客户行为背后原因的洞察。
代码实现: 以下是实现这一模型优化的Python代码。代码首先生成一个模拟数据集,然后定义了一个函数来调整权重并训练模型。接着,它通过遍历权重 a 的可能值来搜索最佳的权重组合,并输出最佳准确率及对应的权重。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import numpy as np
# 生成模拟数据集,确保特征值大于0
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, random_state=42, n_clusters_per_class=1)
X = np.exp(X) # 使用指数函数确保所有值为正
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义一个函数来调整权重并训练模型
def train_model(a, b):
weight_matrix = np.array([[a, b]])
model = LogisticRegression(penalty='l2', solver='liblinear')
model.fit(X_train * weight_matrix, y_train)
y_pred = model.predict(X_test * weight_matrix)
return accuracy_score(y_test, y_pred)
# 权重搜索
best_accuracy = 0
best_a = 0
best_b = 0
for a in np.linspace(0.51, 0.99, 1000):
b = 1 - a
accuracy = train_model(a, b)
if accuracy > best_accuracy:
best_accuracy = accuracy
best_a = a
best_b = b
print(f"Best accuracy: {best_accuracy}")
print(f"Best weights: a={best_a}, b={best_b}")
# 使用最佳权重训练最终模型
final_model = LogisticRegression(penalty='l2', solver='liblinear')
final_model.fit(X_train * np.array([[best_a, best_b]]), y_train)
实际应用: 在实际操作中,银行可以使用这个优化后的模型来识别那些可能引起客户不满的因素,并采取预防措施。例如,如果模型表明退款金额是一个很强的预测因子,银行可能会审查其退款政策,以确保它对客户是公平和透明的。通过这种方式,银行可以提升客户满意度,减少投诉,从而提高服务质量。

















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









