







 GD&T(几何尺寸与公差)是一种国际通用的技术,用于清晰定义零件的形状和位置。本文详细介绍了第一、第二和第三基准的拟合方法,包括基准模拟体的概念,以及如何通过模拟体与实际零件特征的贴合来确定基准。内容涵盖了GD&T系统的优势、测量基准的影响以及不同标准(ASME、ISO、GB)的异同。通过对基准模拟体的讨论,阐述了如何在实际测量和设计中合理设定基准,确保测量坐标系与图纸基准坐标系的一致性,实现功能坐标、基准坐标和测量坐标的统一。
GD&T(几何尺寸与公差)是一种国际通用的技术,用于清晰定义零件的形状和位置。本文详细介绍了第一、第二和第三基准的拟合方法,包括基准模拟体的概念,以及如何通过模拟体与实际零件特征的贴合来确定基准。内容涵盖了GD&T系统的优势、测量基准的影响以及不同标准(ASME、ISO、GB)的异同。通过对基准模拟体的讨论,阐述了如何在实际测量和设计中合理设定基准,确保测量坐标系与图纸基准坐标系的一致性,实现功能坐标、基准坐标和测量坐标的统一。
GD&T
GD&T是Geometric Dimensioning and Tolerancing的缩写,即"形状与位置公差”
◆尺寸标注方法(同我国的技术制图标准)
◆几何公差(同我国的形状和位置公差标准)
美国ASME Y14.5M-2009 ( GD&T) :美国机械工程师协会( American Society of Mechanical Engineers )标准,在美国和全球广泛使用,主要在北美和美国/加拿大在全球的公司使用。南美、澳洲、日本、韩国等亚洲公司也使用该标准。
欧洲ISO ( 1101系列)标准主要在欧洲公司及其在全球的公司使用。也有一些欧洲公司使用美国ASMEY14.5 GD&T标准。
中国GB/T1182-2008/IS01101:2004标准在中国使用;中国在2008-08-1实施这一新标准:产品几何技术规范( GPS )几何公差形状、方向、位置和跳动公差标注。该标准翻译了部分欧洲ISO标准内容,还沿用了GB/T1182-1996老标准的一些内容。
ISO标准和ASME Y14.5M标准目前有80-90%相同;美国是GD&T标准,欧洲ISO标准,中国是GB标准。这是3个不同的标准。
GD&T系统具有以下特点和优势:
1.测量基准、原点鲜明2.累计公差最小化3.所有特征有公差限度4.公差带一致5.采用圆形或者圆柱形公差带扩大公差6.提高信息交流7.改善产品设计8.放宽生产公差
使用性能:
1.影响零件的功能要求。
2.影响零件的配合性质。
3.影响零件的互换性。
4.影响零件本身及配合件寿命。
相关国家标准:
GB/T 1182—2008《产品几何技术规范(GPS)几何公差 形状、方向、位置和跳动公差标注》
GB/T 1184—1996《形状和位置公差 未注公差值》
GB/T 4249—2009《产品几何技术规范(GPS)公差原则》
GB/T 16671—2009《形状和位置公差 最大实体要求、最小实体要求和可逆要求》
GB/T 13319—2003《形状和位置公差 位置度公差》
正文
1. 第一基准是单一要素
例题: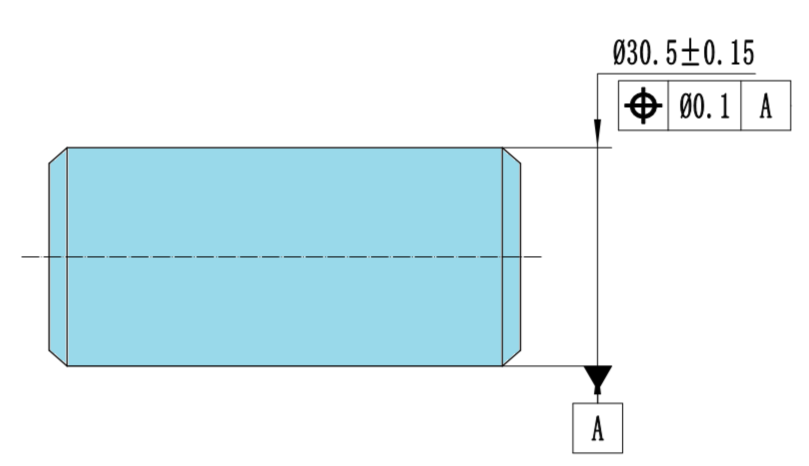
图1 图纸标注
对图1得出判断,就必须确认下面3个问题:
1. 什么是基准?
2. 什么是被测要素?
3. 如何评价?
在图1中,直径为30.5的圆柱,并不是基准,是基准要素(Datum Feature)。所谓基准要素,就是实际零件上用手可以摸的着的零件特征。
引入ASME-Y14.5-2009标准的另外一个概念,叫基准模拟体(Datum-Feature-simulator), 它是一个形状理想,大小可变的圆柱体。当我们用一个理想的圆柱体,慢慢缩小去贴合30.5的圆柱,直到停止为止。这时不再变化的圆柱体叫基准模拟体,而基准模拟体的轴线,就是基准。见图2。
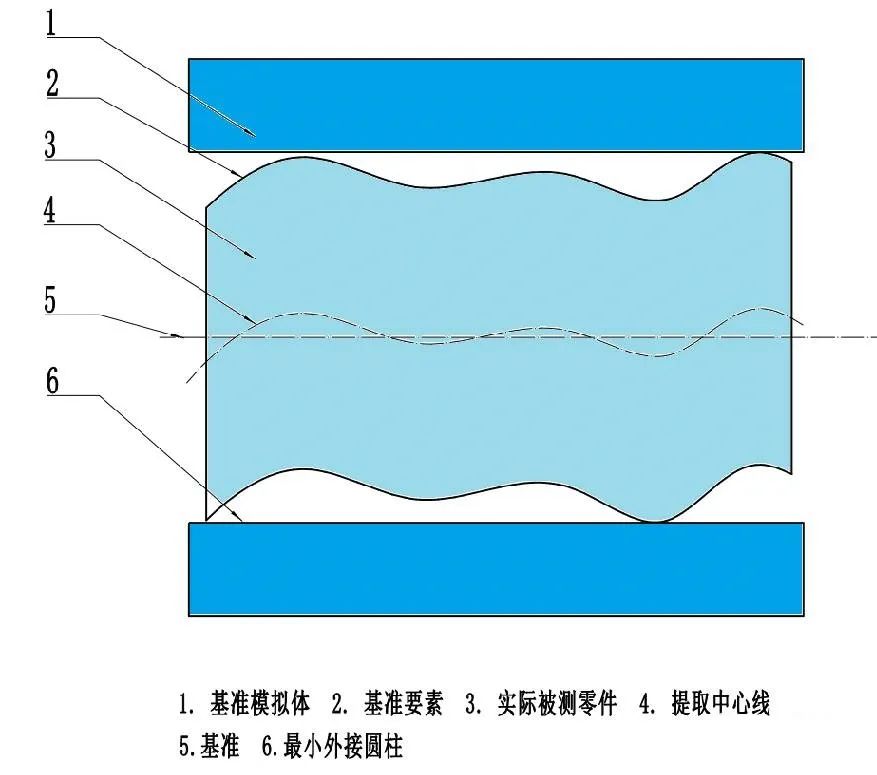
图2 基准轴
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









