







背景
- 最近因加入了导师团队,需要将在AutoDL上的小规模实验数据+代码迁移到学校的HPC集群中进行大规模实验
- 虽说从 单卡3090(24GB) -> 8卡集群 可谓是鸟枪换炮了
- 但要想使用并不容易:
- 学校的集群是已封闭式管理的,没有sudo权限(这和AutoDL类似)
- 而且slurm工作的运行调度逻辑和AutoDL这类服务器有很大差别
- 上传数据的单个文件大小卡在6GB以下,得用7zip分卷(避坑指南可参考博客)
- 之后会持续更新一些个人经验

目录
b. 配置 PyTorch 环境的最佳实践(基于集群现有模块)
步骤 1:编写 SLURM 作业脚本(例如 submit_job.sh)
3. 如何从slurm集群中获得独占显卡(VS Code ssh连接)
在这种受限网络环境下,配置 PyTorch 等环境需依赖以下方式(结合你的集群规则)
1. 使用预装的公共环境(最合规)
- 为什么可行:学校集群为满足教学科研需求,管理员通常会提前安装常用软件(如 CUDA、PyTorch、Python 等),并通过模块系统(如
module load)提供访问,避免用户自行安装带来的安全风险 - 操作方式:
- 登录集群后,通过
module avail命令查看可用的 PyTorch、CUDA 版本(例如module avail pytorch)
- 登录集群后,通过
module avail输出:
------------------------------ /usr/share/Modules/modulefiles -----------------------------
dot module-git module-info modules null use.own
------------------------------ /data/modulefiles/tools ------------------------------------
anaconda3 cmake/3.27.9 cuda/12.1 cuda/12.8 gcc/11.5 glibc/2.32 intel/2018u4 intel/2021u4 mpich/3.4.2 openmpi/4.1.6 python/3.12
cmake/3.17.5 cuda/11.3 cuda/12.4 gcc/4.8.5 gcc/13.3 glibc/2.34 intel/2019u5 intel/2024u2 nvhpc/24.11 openmpi/5.0.6 shangwang
cmake/3.27.0 cuda/11.8 cuda/12.6 gcc/10.5 glibc/2.29 glibc/2.35 intel/2020u4 miniconda3 openmpi/4.1.5 pmix/4.1.1
------------------------------- /data/modulefiles/soft ------------------------------------
comsol/6.2 ffmpeg/4.4.1 ffmpeg/5.1.1 ffmpeg/6.0.1 ffmpeg/7.0.2
---------------------------- /data/modulefiles/opensource ---------------------------------
julia/1.10.2 julia/1.11.3 lammps/2020 lammps/2023 lammps/2024 sparta/2023 sparta/2024a. 可用环境模块分析(结合输出分析)
CUDA 版本(支持 GPU 计算):
cuda/11.3,cuda/11.8,cuda/12.1,cuda/12.4,cuda/12.6,cuda/12.8
(建议根据 PyTorch 支持的 CUDA 版本选择,例如 PyTorch 2.0+ 支持 CUDA 11.8 及以上)Python 环境:
- 系统级 Python:
python/3.12(直接可用)- Conda 环境:
anaconda3、miniconda3(可创建虚拟环境,避免依赖冲突)其他工具:
- 编译器:
gcc/11.5,gcc/13.3等- MPI 库:
openmpi/4.1.6,openmpi/5.0.6等(如需分布式训练)
b. 配置 PyTorch 环境的最佳实践(基于集群现有模块)
即使用预安装的 Conda 环境(推荐,灵活管理依赖)
-
加载 Anaconda 模块并创建虚拟环境
# 登录集群后,先加载 anaconda3 模块 module load anaconda3 # 创建用户级虚拟环境(避免与系统环境冲突) conda create -n pytorch_env python=3.9 # 指定 Python 版本(3.9 是 PyTorch 常用版本) conda activate pytorch_env # 激活环境 -
离线安装 PyTorch(若集群禁止公网访问 - 集群一般都是支持公网访问的)
- 步骤 1:在外部授权设备下载 PyTorch 的 .whl 文件
- 根据集群 CUDA 版本(例如选择
cuda/11.8),在 PyTorch 历史版本页面 下载对应的.whl文件(需匹配 Python 版本和 CUDA 版本)。 - 例如:
torch-2.0.1+cu118-cp39-cp39-linux_x86_64.whl(CUDA 11.8 + Python 3.9)。
- 根据集群 CUDA 版本(例如选择
- 步骤 2:上传文件到集群并安装
- 通过集群允许的文件传输方式(如 WEB 界面的数据管理功能、
scp命令)将.whl文件上传到集群,例如~/pytorch_whl/目录:
- 通过集群允许的文件传输方式(如 WEB 界面的数据管理功能、
conda activate pytorch_env # 确保在虚拟环境中
pip install --user ~/pytorch_whl/torch-2.0.1+cu118-cp39-cp39-linux_x86_64.whl
- 验证环境
-
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"
-
c. SLURM 脚本示例(python命令运行.py)
提交任务时需在脚本中加载模块并激活(conda)环境:
#!/bin/bash
#SBATCH --job-name=pytorch_train # 作业名称(需符合 WEB 界面要求:无中文/空格)
#SBATCH --partition=acd # 队列选择
#SBATCH --nodes=1 # GPU 节点数
#SBATCH --gres=gpu:2 # 每节点 2 张 GPU(根据需求填写)
#SBATCH --cpus-per-task=8 # CPU 核数
#SBATCH --mem=32G # 内存(可选)
# 加载基础模块
module load cuda/11.8 # 匹配 PyTorch 的 CUDA 版本
module load anaconda3 # 加载 Conda 环境
# 激活用户级虚拟环境(路径需替换为你的实际路径)
source /home/chen74/anaconda3/envs/pytorch_env/bin/activate
# 运行 Python 脚本(需填写完整路径,支持自定义参数)
python /home/chen74/data/pytorch_script.py --epochs 100 --lr 0.001
d. 注意事项
CUDA 版本兼容性
- 务必确保下载的 PyTorch
.whl文件与加载的cuda/xx.x版本完全匹配(例如cuda/11.8对应 PyTorch 后缀cu118),否则会报错(如CUDA runtime version is incompatible)文件路径规范
- 在 WEB 界面填写
python执行文件时,若使用 Conda 环境中的 Python,需填写完整路径(例如~/anaconda3/envs/pytorch_env/bin/python)环境变量自动配置
- 加载
cuda/xx.x模块后,CUDA_HOME、LD_LIBRARY_PATH等环境变量会自动设置,无需手动添加,避免路径错误
2. run.sh 脚本运行方式
以执行以下命令为例:
bash run.sh /data/user/chen74/code/openocc/projects/baselines/LiDAR_128x128x10.py 8a. 明确脚本类型:是否为 SLURM 作业脚本?
首先需要确认 run.sh 的内容:
- 如果
run.sh包含#SBATCH头信息(类似你提供的 SLURM 脚本示例):它是 SLURM 作业脚本,需通过sbatch提交给集群调度系统运行,不能直接用bash执行(否则会跳过 SLURM 调度逻辑,可能无法获取 GPU 等资源) - 如果
run.sh不包含#SBATCH头信息:它是普通脚本,直接用bash执行即可(通常用于交互式测试或简单任务)
来看看咱们例子中的 run.sh 脚本:
cd $(readlink -f `dirname $0`)
conda activate OpenOccupancy
export PYTHONPATH="."
echo $1
if [ -f $1 ]; then
config=$1
else
echo "need a config file"
exit
fi
bash tools/dist_train.sh $config $2 ${@:3}
嵌套了一层,内层的dist_train.sh也看看:
#!/usr/bin/env bash
CONFIG=$1
GPUS=$2
NNODES=${NNODES:-1}
NODE_RANK=${NODE_RANK:-0}
PORT=${PORT:-29501}
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch \
--nnodes=$NNODES \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--nproc_per_node=$GPUS \
--master_port=$PORT \
$(dirname "$0")/train.py \
$CONFIG \
--seed 0 \
--launcher pytorch ${@:3}b. 脚本功能解析
首先明确两个脚本的作用:
run.sh:入口脚本,负责环境初始化(激活 Conda 环境、设置PYTHONPATH)、校验配置文件路径,并调用分布式训练脚本tools/dist_train.shtools/dist_train.sh:分布式训练启动脚本,基于torch.distributed.launch配置多 GPU 或多节点训练参数(如 GPU 数量、通信端口等),最终调用实际的训练脚本train.py
c. 在集群上的正确运行方式
由于集群通过 SLURM 管理资源(如 GPU、CPU),必须通过 sbatch 提交作业(直接用 bash 运行会无法获取资源)。需结合 SLURM 脚本模板,将 run.sh 的执行封装到 SLURM 作业中
d. 具体操作步骤
步骤 1:编写 SLURM 作业脚本(例如 submit_job.sh)
在 SLURM 脚本中,需声明资源需求(GPU、CPU、内存等),并调用 run.sh。示例如下:
#!/bin/bash
#SBATCH --job-name=openocc_train # 作业名(无中文/空格)
#SBATCH --partition=acd # 集群队列(根据实际调整)
#SBATCH --nodes=1 # 节点数(单节点训练设为 1)
#SBATCH --gres=gpu:8 # 分配 8 张 GPU(与 run.sh 的第二个参数 8 一致)
#SBATCH --cpus-per-task=32 # CPU 核数(建议为 GPU 数的 4 倍,确保数据加载效率)
#SBATCH --mem=128G # 内存(根据模型大小调整)
#SBATCH --output=slurm-%j.out # 输出日志文件名(%j 会自动替换为作业 ID)
# ------------------- 环境初始化 -------------------
# 加载集群预安装的模块(需与 PyTorch、CUDA 版本匹配)
module load cuda/11.8 # 假设 PyTorch 是 cu118 版本(如 torch-2.0.1+cu118)
module load anaconda3 # 加载 Conda 以激活虚拟环境
# 激活用户级 Conda 环境(路径替换为实际环境)
source /home/chen74/anaconda3/etc/profile.d/conda.sh # 加载 Conda 初始化脚本(避免激活失败)
conda activate OpenOccupancy # 激活 run.sh 中指定的环境
# ------------------- 执行训练脚本 -------------------
# 运行 run.sh,传递配置文件路径和 GPU 数量(8)
bash /data/user/chen74/code/openocc/run.sh \
/data/user/chen74/code/openocc/projects/baselines/LiDAR_128x128x10.py \
8
步骤 2:提交作业到 SLURM
sbatch submit_job.sh # 提交后会返回作业 ID(如 submitted to batch job 12345)
步骤 3:检查作业状态与日志
- 查看作业队列:
squeue -u chen74 # 替换为你的用户名,查看作业是否运行/等待 - 查看输出日志:
SLURM 会生成slurm-12345.out(12345为作业 ID),包含训练过程的输出和错误信息:cat slurm-12345.out
e. 关键注意事项
1. 环境一致性
- Conda 环境激活:
集群中直接执行conda activate可能因环境变量未加载而失败,需先加载 Conda 初始化脚本(如source /home/chen74/anaconda3/etc/profile.d/conda.sh),再激活环境- CUDA 版本匹配:
module load cuda/11.8需与 PyTorch 的 CUDA 后缀(如cu118)完全一致,否则会报CUDA runtime version incompatible错误2. 参数传递与分布式训练
run.sh的第二个参数8对应tools/dist_train.sh中的GPUS=$2,即每节点使用 8 张 GPU(需与#SBATCH --gres=gpu:8一致)- 若需多节点训练(
NNODES>1),SLURM 会自动设置SLURM_NNODES(节点数)、SLURM_NODE_RANK(当前节点编号)等环境变量,需修改tools/dist_train.sh以适配:# 在 tools/dist_train.sh 中添加(替换原有的 NNODES 和 NODE_RANK) NNODES=${SLURM_NNODES:-1} # 从 SLURM 获取节点数(默认 1) NODE_RANK=${SLURM_NODE_RANK:-0} # 从 SLURM 获取当前节点编号(默认 0) MASTER_ADDR=${SLURM_LAUNCH_NODE_IPADDR:-"127.0.0.1"} # 主节点 IP(SLURM 自动分配)3. 路径问题
run.sh中cd $(readlink -f $(dirname $0))会切换到脚本所在的绝对路径目录(如/data/user/chen74/code/openocc),确保tools/dist_train.sh和train.py的路径正确- 配置文件路径(如
LiDAR_128x128x10.py)需使用绝对路径,避免因作业工作目录不同导致文件找不到
f. 常见问题排查
错误:
conda activate失败:
原因是未加载 Conda 初始化脚本。解决方法:在 SLURM 脚本中先执行source /home/chen74/anaconda3/etc/profile.d/conda.sh,再激活环境错误:
CUDA error: no kernel image is available for execution:
原因是 PyTorch 的 CUDA 版本与加载的cuda/xx.x模块不匹配。解决方法:检查 PyTorch 的.whl文件后缀(如cu118)与module load cuda/11.8是否一致错误:
FileNotFoundError: train.py:
原因是tools/dist_train.sh找不到train.py。解决方法:确保run.sh切换到正确目录(cd $(readlink -f $(dirname $0))),或使用绝对路径调用train.py(如/data/user/chen74/code/openocc/tools/train.py)
3. 如何从slurm集群中获得独占显卡(VS Code ssh连接)
在进行代码调试或需要交互式操作时,直接在计算节点上获得独占的GPU资源会非常方便。结合VS Code的SSH远程连接功能,可以实现本地开发环境的无缝体验。
a. VS Code SSH 配置
首先,确保你的VS Code已经安装了 Remote - SSH 插件。接下来,配置SSH连接:
-
打开VS Code。
-
按
Ctrl+Shift+P(或Cmd+Shift+Pon macOS) 打开命令面板。 -
输入
Remote-SSH: Open Configuration File...并选择你的SSH配置文件(通常是~/.ssh/config或C:\Users\YourUsername\.ssh\config)。 -
在配置文件中添加以下内容:
Host xxx # 自定义一个名字 HostName hpclogin.hpc.xxx.edu.cn User xxx # 你的用户名- Host
xxx: xxx这是你为这个连接设置的别名,方便记忆和使用 - HostName
hpclogin.hpc.xxx.edu.cn: 这是学校HPC集群的登录节点地址 - User
yyy: yyy这是你的集群用户名
- Host
b. 通过 VS Code 连接到集群
- 保存SSH配置文件
- 在VS Code的左侧活动栏中,点击 Remote Explorer 图标
- 在SSH Targets下拉列表中,你应该能看到你配置的
xxx - 点击
xxx右侧的连接图标(通常是一个文件夹图标或+图标) - 如果提示,输入你的集群登录密码
- 输入完密码一般要等一会而,再开一个新终端即可

c. 请求独占GPU资源
连接成功后,VS Code会打开一个新的窗口,其终端已经连接到HPC的登录节点。但是,登录节点通常不提供计算资源(如GPU)。你需要通过SLURM请求一个交互式的作业会话:
-
在VS Code的终端中(确保你已经通过SSH连接到
xxx),输入以下命令:srun -p debug --gres=gpu:1 --mem=128G --cpus-per-task=16 --pty "bash"命令参数解析:
srun: SLURM命令,用于运行并行作业。-p debug: 指定作业提交到名为debug的分区(partition)。分区通常有不同的资源限制和优先级,请根据集群的实际情况选择合适的分区。这个指令可参考学校的文档,换成对应的显卡类名,比如我们学校的叫“gpux-xx”,不同的卡价格不同--gres=gpu:1: 请求通用资源(Generic Resource),这里指定需要1张GPU卡 (gpu:1)。这将确保你独占这块卡--mem=128G: 请求128GB的内存--cpus-per-task=16: 为你的任务请求16个CPU核心--pty "bash": 为作业分配一个伪终端(pseudo-terminal)并启动一个bashshell。这样你就可以在这个独占的环境中执行命令了
-
提交命令后,SLURM会为你的作业分配资源。一旦资源分配成功,你的终端提示符会改变,表示你现在正处于一个计算节点上,并且拥有所请求的GPU、内存和CPU资源
看看效果:
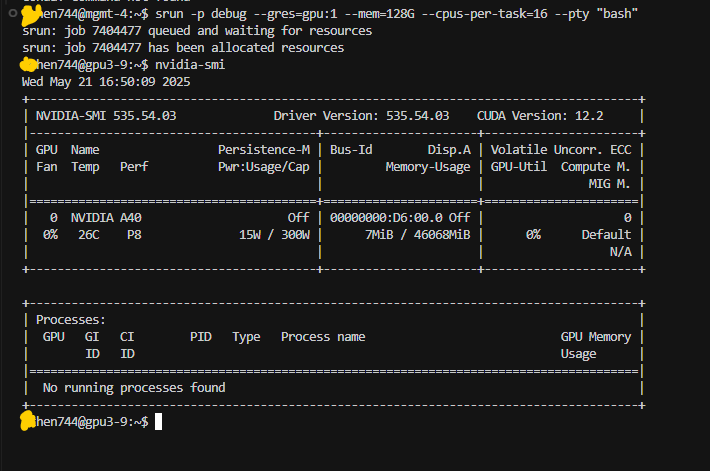
-
💡 提示:作业分配可能需要等待一段时间,具体取决于集群当前的负载和分区策略
d. 在独占环境中工作
现在,你可以在这个交互式会话中加载所需模块、激活Conda环境,并运行你的PyTorch代码,就像在本地一样,同时拥有GPU加速。例如:
# 假设已在计算节点上
module load cuda/11.8 # 或者你PyTorch匹配的CUDA版本
module load anaconda3
source /home/chen74/anaconda3/etc/profile.d/conda.sh # 替换为你的conda路径
conda activate your_pytorch_env # 激活你的PyTorch环境
# 现在可以运行Python脚本或进行调试
python your_script.py
当你完成工作后,只需在 srun 启动的 bash shell中输入 exit(或者control+D),即可释放资源并退出交互式作业会话。VS Code的SSH连接仍然保持,但你会回到登录节点
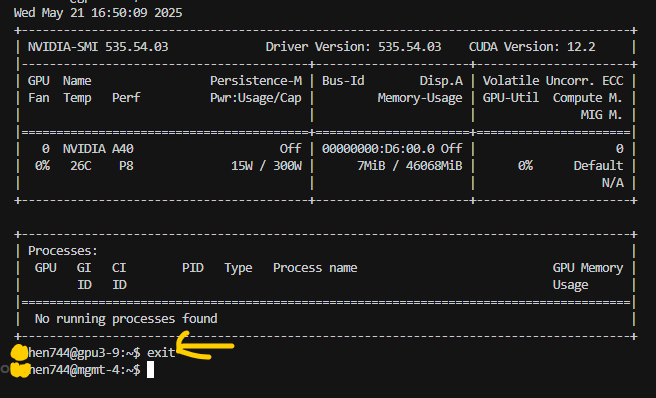
e. 注意事项
- 分区选择 (
-p): 不同的分区可能有不同的最大运行时长、GPU类型和数量限制。请查阅学校HPC的文档或使用sinfo命令了解可用分区及其特性。debug分区通常用于短时间测试,长时间任务可能需要提交到计算分区(如你之前SLURM脚本中的acd) - 资源请求 (
--gres,--mem,--cpus-per-task): 合理请求资源。请求过多不必要的资源可能会导致作业排队时间更长 - 交互式会话时长: 交互式会话通常有时间限制。如果需要长时间运行,建议编写SLURM作业脚本并通过
sbatch提交(一般还是用srun独占多一点,sbatch也可以) - VS Code 终端复用: VS Code的SSH功能非常强大,你可以在连接后打开多个终端,方便同时进行文件编辑、监控和命令执行
(持续更新中)

















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









