






一、AR、MA和ARMA模型解释
1. 自回归(AR)模型
自回归模型(Autoregressive Model, AR)是一种统计模型,它使用时间序列之前的观测值(即滞后值)来预测当前值。AR模型的基本形式是: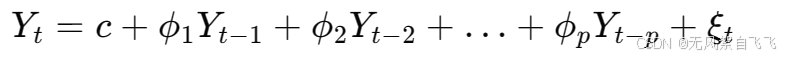

2. 移动平均(MA)模型
移动平均模型(Moving Average Model, MA)是通过过去的随机误差(或称为创新)来预测当前值的模型。MA模型的基本形式是: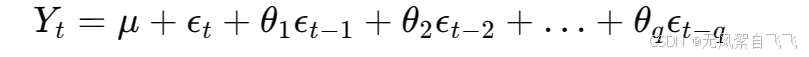

3. 混合自回归移动平均(ARMA)模型
ARMA模型结合了AR模型和MA模型的特点,它既考虑了时间序列值之间的线性关系,也考虑了随机误差之间的关系。ARMA模型的基本形式是: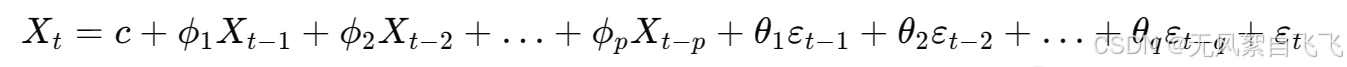
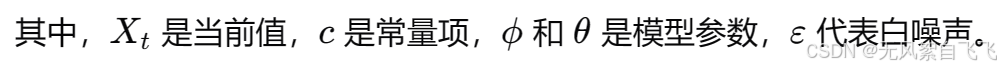 ARMA模型由两部分组成:自回归(AR)项和滑动平均(MA)项。自回归部分利用之前的值来预测当前值,而滑动平均部分则通过考虑过去的随机误差来进行预测。ARMA模型能够有效捕捉数据中的依赖关系,适用于线性时间序列数据的建模。
ARMA模型由两部分组成:自回归(AR)项和滑动平均(MA)项。自回归部分利用之前的值来预测当前值,而滑动平均部分则通过考虑过去的随机误差来进行预测。ARMA模型能够有效捕捉数据中的依赖关系,适用于线性时间序列数据的建模。
二、ARMA模型的建立以及代码仿真
1、必要的包导入
import numpy as np
import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from itertools import product
from statsmodels.tsa.stattools import adfuller, acf, pacf
import warnings
warnings.filterwarnings('ignore')
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
2、全面的时间序列分析的建立
def analyze_time_series(data):
"""
全面的时间序列分析
"""
# ADF检验
result = adfuller(data)
print('ADF检验结果:')
print('ADF统计量:', result[0])
print('p值:', result[1])
print('临界值:', result[4])
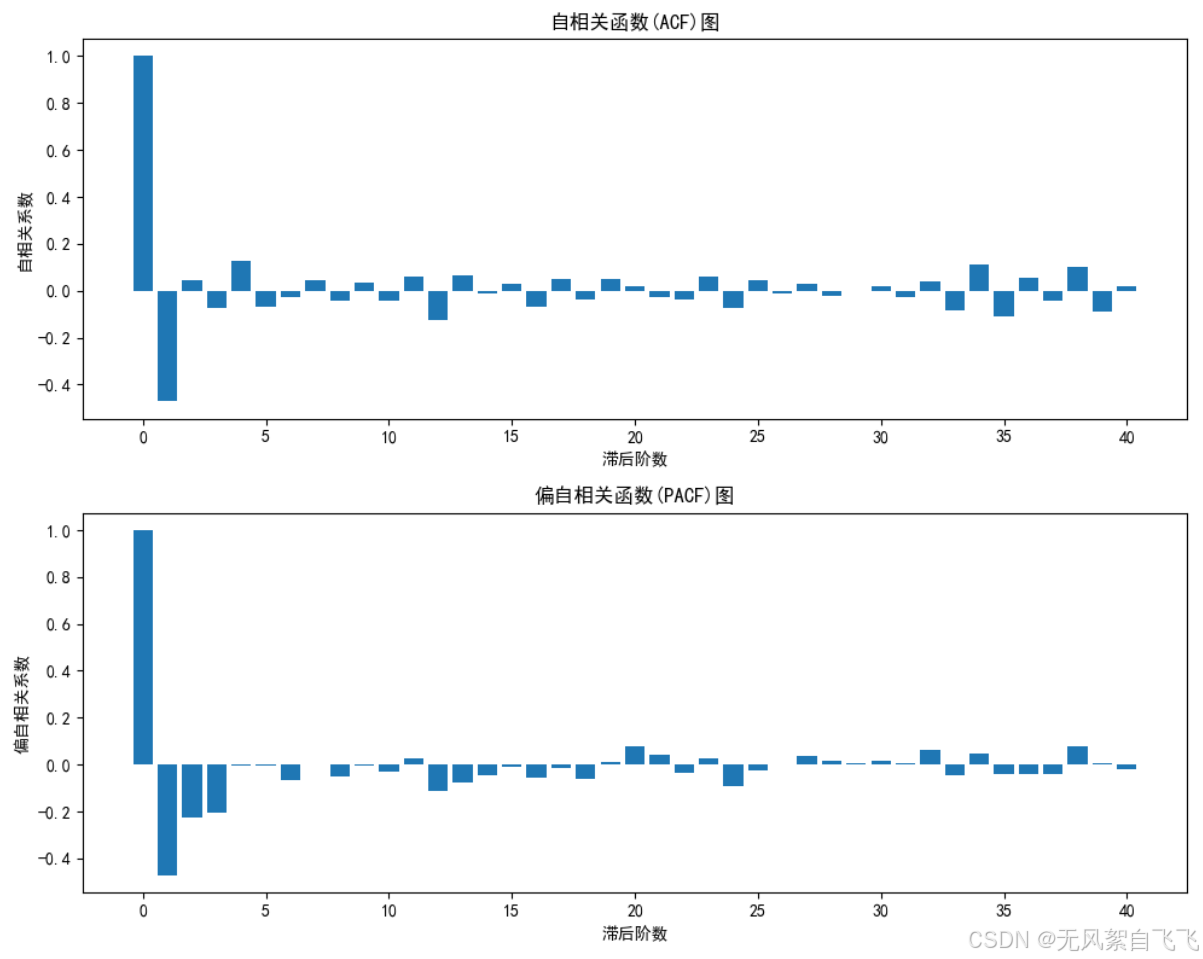
# 计算ACF和PACF
acf_values = acf(data, nlags=40)
pacf_values = pacf(data, nlags=40)
# 绘制ACF和PACF图
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 8))
# ACF图
ax1.bar(range(len(acf_values)), acf_values)
ax1.set_title('自相关函数(ACF)图')
ax1.set_xlabel('滞后阶数')
ax1.set_ylabel('自相关系数')
# PACF图
ax2.bar(range(len(pacf_values)), pacf_values)
ax2.set_title('偏自相关函数(PACF)图')
ax2.set_xlabel('滞后阶数')
ax2.set_ylabel('偏自相关系数')
plt.tight_layout()
plt.savefig('acf_pacf_plot.png')
plt.close()
return result[1] < 0.05
3、数据预处理:差分、标准化等
首先,我们需要对数据进行预处理。通过ADF检验,我们可以判断数据的平稳性。如果数据不平稳,我们将进行差分处理以使其平稳。
def preprocess_data(data):
"""
数据预处理:差分、标准化等
"""
# 首先进行时间序列分析
print("原始数据分析:")
is_stationary = analyze_time_series(data)
# 检查是否需要差分
if not is_stationary:
print("\n数据不平稳,进行差分处理...")
data_diff = data.diff().dropna()
print("\n一阶差分后数据分析:")
if analyze_time_series(data_diff):
print("一阶差分后数据平稳")
return data_diff, 1
else:
print("\n一阶差分后仍不平稳,进行二阶差分...")
data_diff2 = data_diff.diff().dropna()
print("\n二阶差分后数据分析:")
analyze_time_series(data_diff2)
return data_diff2, 2
return data, 04、优化后的网格搜索函数
我们使用网格搜索来选择SARIMA模型的最佳参数组合。通过最小化AIC(赤池信息准则),我们可以找到最优的模型参数。
def grid_search_sarima(data, max_p=2, max_d=1, max_q=2, max_P=1, max_D=1, max_Q=1, s=12):
"""
优化后的网格搜索函数
"""
best_aic = float('inf')
best_params = None
# 减小搜索范围
p_range = range(max_p + 1)
d_range = range(max_d + 1)
q_range = range(max_q + 1)
P_range = range(max_P + 1)
D_range = range(max_D + 1)
Q_range = range(max_Q + 1)
total_combinations = (max_p + 1) * (max_d + 1) * (max_q + 1) * (max_P + 1) * (max_D + 1) * (max_Q + 1)
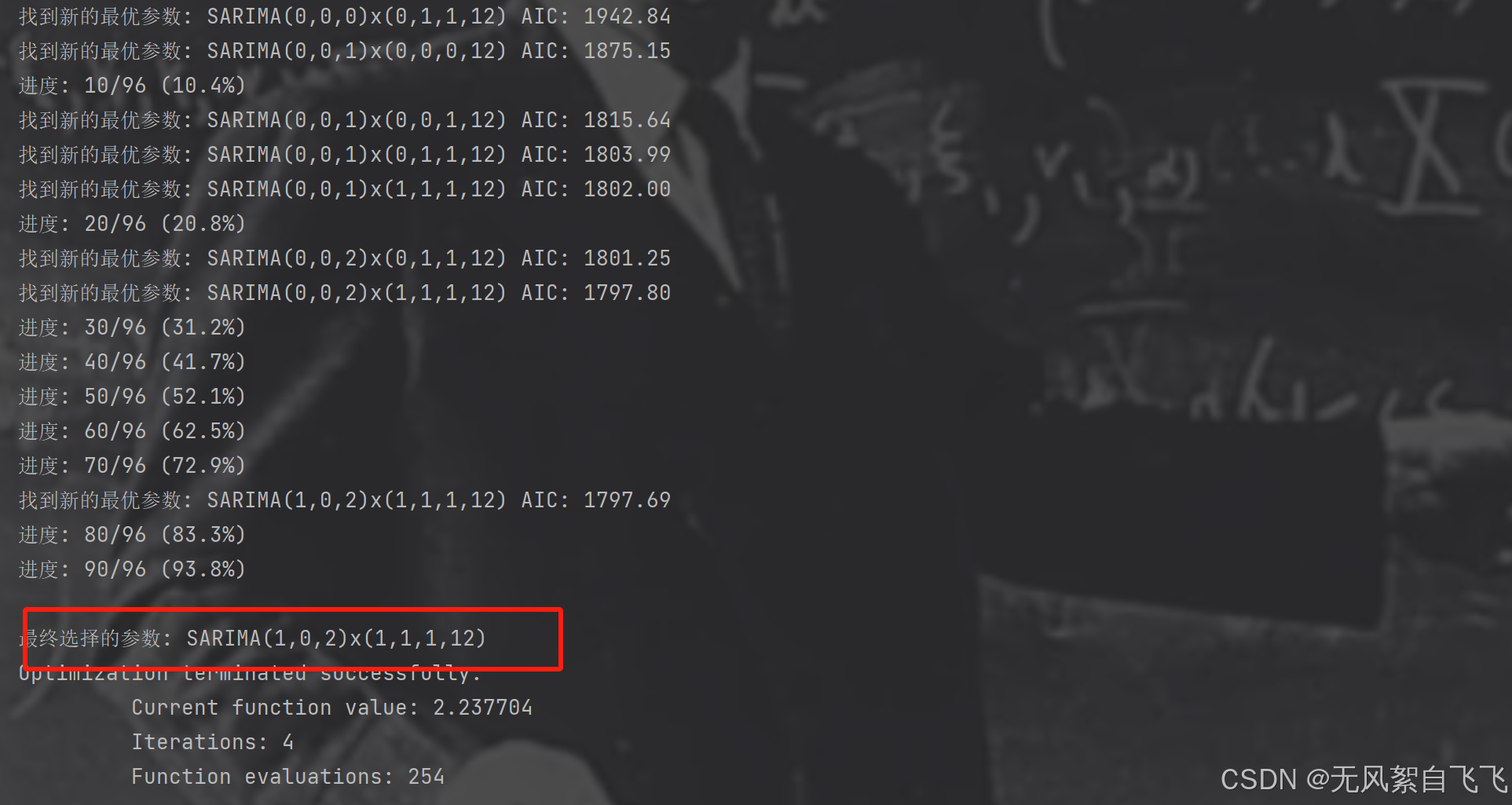
print(f"开始搜索最优参数,共 {total_combinations} 种组合...")
current = 0
for p, d, q, P, D, Q in product(p_range, d_range, q_range, P_range, D_range, Q_range):
current += 1
if current % 10 == 0: # 每10次迭代显示一次进度
print(f"进度: {current}/{total_combinations} ({(current / total_combinations * 100):.1f}%)")
if p == 0 and q == 0 and P == 0 and Q == 0:
continue
try:
model = SARIMAX(
data,
order=(p, d, q),
seasonal_order=(P, D, Q, s),
enforce_stationarity=False,
enforce_invertibility=False
)
results = model.fit(method='powell', disp=False, maxiter=50) # 减少最大迭代次数
aic = results.aic
if aic < best_aic:
best_aic = aic
best_params = (p, d, q, P, D, Q)
print(f'找到新的最优参数: SARIMA({p},{d},{q})x({P},{D},{Q},{s}) AIC: {aic:.2f}')
except:
continue
return best_params
5、拟合SARIMA模型(添加更多训练选项)
一旦确定了最佳参数,我们就可以拟合SARIMA模型并进行预测。我们还可以计算预测的置信区间,以评估预测的不确定性。
def fit_sarima(data, order, seasonal_order):
"""
拟合SARIMA模型(添加更多训练选项)
"""
model = SARIMAX(
data,
order=order,
seasonal_order=seasonal_order,
enforce_stationarity=False,
enforce_invertibility=False
)
model_fit = model.fit(method='powell', maxiter=100)
return model_fit
6、使用拟合好的模型进行预测(添加置信区间)
def make_predictions(model_fit, steps=100, return_conf_int=True):
"""
使用拟合好的模型进行预测(添加置信区间)
"""
try:
if return_conf_int:
# 使用get_forecast替代forecast
forecast_result = model_fit.get_forecast(steps=steps)
forecast = forecast_result.predicted_mean
conf_int = forecast_result.conf_int(alpha=0.05)
return forecast, conf_int
return model_fit.forecast(steps=steps)
except Exception as e:
print(f"预测过程中出现错误: {str(e)}")
# 如果获取置信区间失败,仅返回预测值
forecast = model_fit.forecast(steps=steps)
return forecast, None
7、绘制结果(添加错误处理)
通过绘制预测结果和实际值的对比图,我们可以直观地评估模型的预测效果。我们还可以计算MSE、RMSE、MAE和MAPE等指标来量化预测误差。
def plot_results(test, predictions, conf_int=None, filename='sarima_predictions.png'):
"""
绘制结果(添加错误处理)
"""
plt.figure(figsize=(15, 7))
plt.plot(test.index, test.values, label='实际值', alpha=0.7)
plt.plot(test.index, predictions, label='预测值', color='red', alpha=0.7)
if conf_int is not None:
try:
plt.fill_between(test.index,
conf_int[:, 0],
conf_int[:, 1],
color='red',
alpha=0.1,
label='95%置信区间')
except Exception as e:
print(f"绘制置信区间时出现错误: {str(e)}")
plt.title('SARIMA模型预测结果')
plt.xlabel('日期')
plt.ylabel('值')
plt.legend()
plt.grid(True, alpha=0.3)
plt.savefig(filename, dpi=300, bbox_inches='tight')
plt.close()
print(f"图表已保存为: {filename}")
8、主函数
def main():
try:
data = pd.read_csv('your_data.csv', parse_dates=['date'], index_col='date')
series = data['value']
except:
print("使用示例数据...")
np.random.seed(1)
n_points = 500 # 减少数据点数量
time_index = pd.date_range(start='2020-01-01', periods=n_points, freq='D')
seasonal = 10 * np.sin(2 * np.pi * np.arange(n_points) / 365.25)
trend = np.random.normal(0, 1, n_points).cumsum()
data = trend + seasonal + np.random.normal(0, 2, n_points)
series = pd.Series(data, index=time_index)
# 数据预处理和时间序列分析
processed_data, diff_order = preprocess_data(series)
# 分训练集和测试集
train_size = int(len(processed_data) * 0.8)
train = processed_data[:train_size]
test = processed_data[train_size:]
# 使用更小的参数范围
try:
p, d, q, P, D, Q = grid_search_sarima(
train,
max_p=1, # 进一步减小范围
max_d=1,
max_q=2,
max_P=1,
max_D=1,
max_Q=1,
s=12
)
print(f"\n最终选择的参数: SARIMA({p},{d},{q})x({P},{D},{Q},12)")
# 使用最优参数拟合模型
order = (p, d, q)
seasonal_order = (P, D, Q, 12)
model_fit = fit_sarima(train, order, seasonal_order)
# 进行预测
predictions, conf_int = make_predictions(model_fit, steps=len(test))
# 如果进行了差分,需要还原预测值
if diff_order > 0:
predictions = predictions.cumsum() + series[train_size - 1]
test = test.cumsum() + series[train_size - 1]
# 评估模型
mse = np.mean((test - predictions) ** 2)
rmse = np.sqrt(mse)
mae = np.mean(np.abs(test - predictions))
mape = np.mean(np.abs((test - predictions) / test)) * 100
print('\n模型评估指标:')
print(f'MSE: {mse:.2f}')
print(f'RMSE: {rmse:.2f}')
print(f'MAE: {mae:.2f}')
print(f'MAPE: {mape:.2f}%')
# 绘制结果
plot_results(test, predictions, conf_int)
# 打印模型摘要
print("\n模型详细信息:")
print(model_fit.summary())
except Exception as e:
print(f"模型训练或预测过程中出现错误: {str(e)}")
if __name__ == "__main__":
main() 三、仿真结果分析
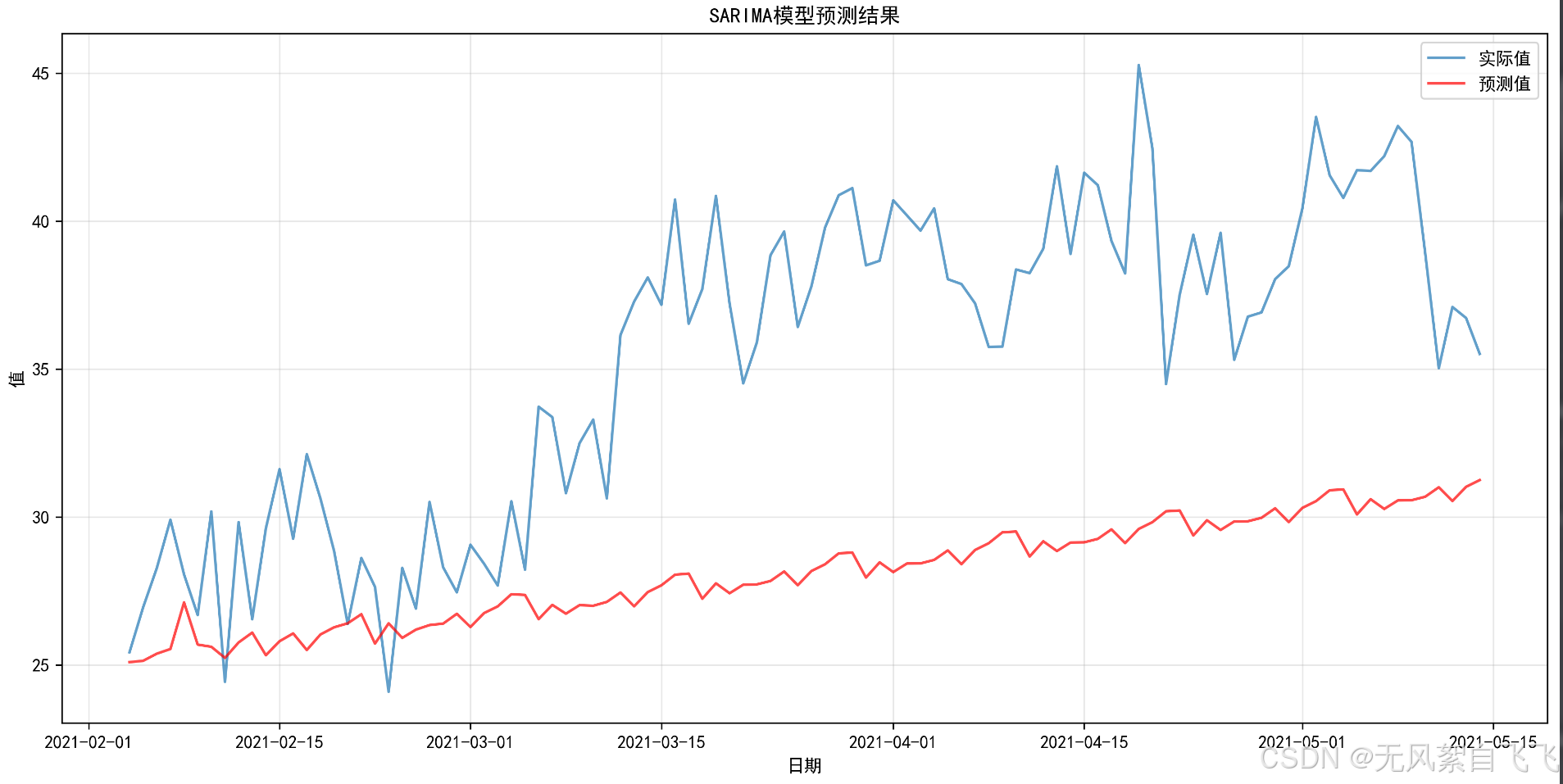
从图表来看,预测值(红线)的趋势与实际值(蓝线)有一定差距,这可能是因为:
•
数据存在较强的非线性特征
•
可能存在结构性变化
•
季节性模式可能不够稳定。
四、总结:
关于ARMA模型的几个重要注意点:
1、参数选择:
(1)p(AR阶数)和q(MA阶数)的选择很重要
(2)可以使用AIC或BIC准则来选择最优参数
(3)也可以使用网格搜索来找到最佳参数组合
2、平稳性要求:
(1)ARMA模型要求时间序列是平稳的
(2)如果数据不平稳,需要先进行差分处理(这就变成ARIMA模型了)
3、模型诊断:
(1)需要检查残差是否为白噪声
(2)可以使用Q-Q图和自相关图进行诊断
4、预测限制:
(1)ARMA模型对短期预测较为有效
(2)长期预测的准确性会随着时间推移而降低
以上就是ARMA的介绍以及代码仿真,如有需要完整代码仿真,可后台④我哦!
如对您有帮助,记得点赞收藏加关注哈!

















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









