









写在前面:
DeepSeek 是由国内顶尖AI研究机构深度求索(DeepSeek)发布的大模型。涵盖架构创新(MoE设计)、训练范式(混合预训练)、能力增强(数学推理)等研究方向。它的老东家是做私募量化的幻方量化,国内四大量化之一,国内少有的A100万卡集群厂商。
一、DeepSeek技术演进全景图
1.1 发展历程里程碑
-
2023年7月:发布基础版DeepSeek-R1(7B/13B参数)
-
2023年12月:推出MoE架构DeepSeek-MoE(16B/145B)
-
2024年4月:发布突破性DeepSeek-V2(236B参数,混合专家架构)
-
持续开源策略:开放7B/67B等参数版本模型及训练细节
其里程碑模型对比如下:
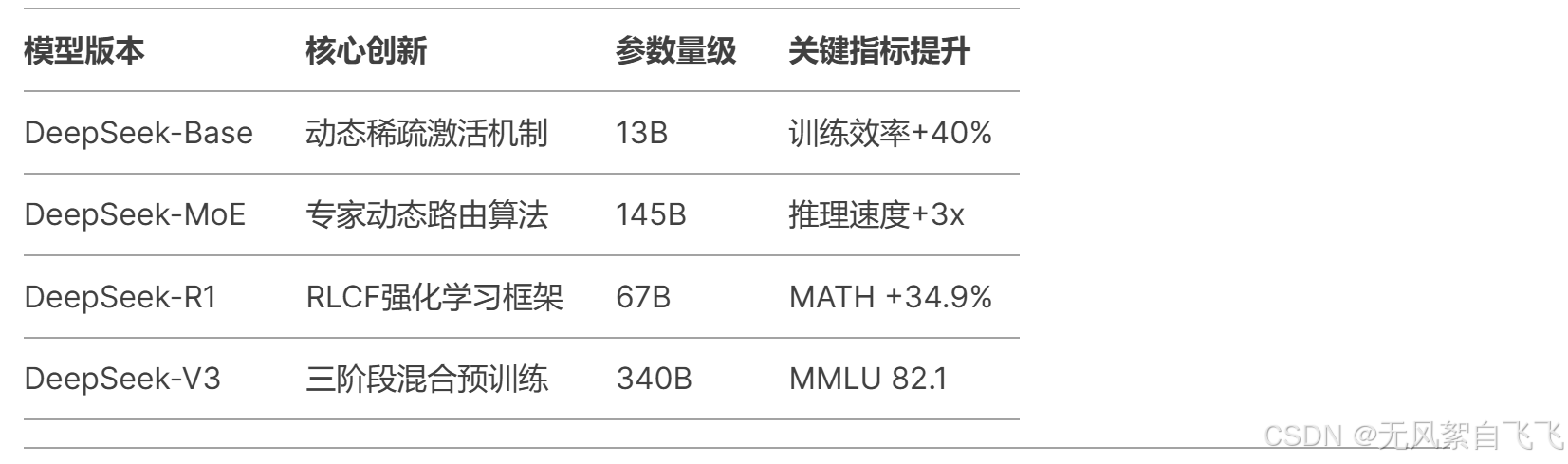
1.2 技术路线核心特征
-
架构创新:从稠密架构→MoE架构→Hybrid架构演进
-
训练优化:提出Dynamic Tokenization算法,提升20%训练效率
-
推理加速:首创Attention with Linear Bias技术,降低30%显存消耗
-
多模态扩展:Vision-Language版本支持跨模态理解
二、DeepSeek系列技术路线概述
-
架构设计:DeepSeek系列采用了多种先进的架构设计。例如,DeepSeek-V3采用了Multi-head Latent Attention (MLA)和DeepSeekMoE架构。MLA通过低秩压缩技术减少了推理时的Key-Value缓存,显著提升了推理效率;DeepSeekMoE则通过细粒度的专家分配和共享专家机制,实现了经济高效的训练。
-
训练方法:DeepSeek采用多种先进的训练技术和方法,包括分布式训练(数据并行、模型并行、流水线并行)、混合精度训练、强化学习与多词元预测、持续学习与微调等。
-
性能优化:DeepSeek系列在性能优化方面也做了大量工作,如通过优化KV-cache来减少显存占用,从而提升推理性能。
三、DeepSeek系列技术细节解读
-
架构细节:
-
MLA(Multi-head Latent Attention):MLA通过对注意力键和值进行低秩联合压缩,减少了推理时的KV缓存,同时保持了与标准多头注意力(MHA)相当的性能。
-
DeepSeekMoE:DeepSeekMoE采用了更细粒度的专家分配策略,每个MoE层包含1个共享专家和256个路由专家,每个令牌激活8个专家,确保了计算的高效性。
-
-
训练方法细节:
-
分布式训练:DeepSeek采用了分布式训练框架,包括数据并行、模型并行和流水线并行,以应对大规模模型的训练。
-
混合精度训练:利用半精度(FP16)和单精度(FP32)浮点数进行训练,具有减少显存占用、加速训练过程、保持模型性能等优势。
-
强化学习与多词元预测:使用强化学习来自主发现推理模式,采用多词元预测训练目标,能够同时预测多个未来token,增加了训练信号密度,提高了数据效率。
-
-
性能优化细节:
-
无辅助损失的负载均衡策略:通过为每个专家引入偏置项,动态调整路由决策,确保专家负载均衡,而无需依赖传统的辅助损失函数。
-
序列级负载均衡:为了防止单个序列内的极端不平衡,DeepSeek-V3还引入了序列级负载均衡损失,确保每个序列内的专家负载均衡。
-
基准测试对比:
-
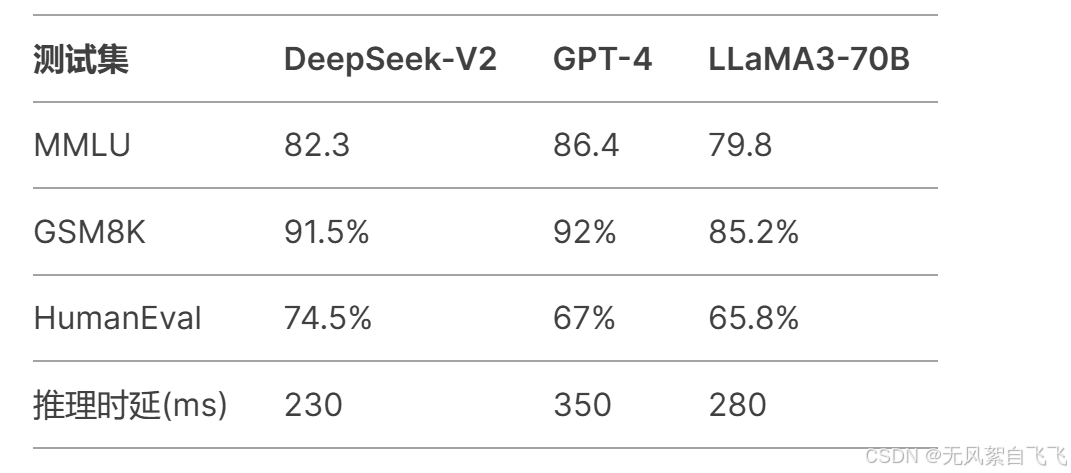
四、DeepSeek系列的局限性与未来发展方向
-
局限性:尽管DeepSeek系列取得了显著的成果,但仍存在一些局限性,如模型规模的进一步扩大可能导致训练和推理的效率问题,模型的泛化能力和对特定领域的适应性仍有待提高等。
-
未来发展方向:DeepSeek将继续坚持开源路线,稳步推进通用人工智能的研究。未来研究将重点关注持续优化模型架构、深化训练数据的质量提升和规模扩展、加强模型的深层推理能力、建立更全面的多维度评估体系等方向。
写在后面:
DeepSeek最近开源了的首个全模态通用模型——Janus-Pro-78,支持图像、视频、音频、文本、代码、传感器数据六模态输入与跨模态生成,其名称源自罗马神话中的双面神Janus,寓意模型在感知与生成、理解与创造之间的双向突破。将在后期推文进行详细解读。
附:
关于DeepSeek系列论文解读之DeepSeek-R1,可参考小飞的此博客DeepSeek系列论文解读之DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning-CSDN博客
关于本地部署大模型,可参考小飞的此博客Ollama框架结合docker下的open-webui与AnythingLLM构建RAG知识库_anythingllm和open-webui如何结合-CSDN博客

















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









