







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
-p result/tax/sum_c.txt \
-w 183 -v 59 -s 7 -l 10 -L Class \
-o result/compare/${compare}.manhattan.c.pdf
# 显示完整图例,再用AI拼图
bash ${db}/script/compare_manhattan.sh -i result/compare/${compare}.txt \
-t result/taxonomy.txt \
-p result/tax/sum_c.txt \
-w 183 -v 149 -s 7 -l 10 -L Class \
-o result/compare/${compare}.manhattan.c.legend.pdf
1.5 单个特征的绘制
# 筛选显示差异ASV,按KO组丰度降序列,取ID展示前10
awk '$4<0.05' result/compare/KO-WT.txt | sort -k7,7nr | cut -f1 | head
# 差异OTU细节展示
Rscript ${db}/script/alpha_boxplot.R --alpha_index ASV_2 \
--input result/otutab.txt --design result/metadata.txt \
--transpose TRUE --scale TRUE \
--width 89 --height 59 \
--group Group --output result/compare/feature_
# ID不存在会报错: Error in data.frame(..., check.names = FALSE) : 参数值意味着不同的行数: 0, 18 Calls: alpha_boxplot -> cbind -> cbind -> data.frame
# 指定某列排序:按属丰度均值All降序
csvtk -t sort -k All:nr result/tax/sum_g.txt | head
# 差属细节展示
Rscript ${db}/script/alpha_boxplot.R --alpha_index Lysobacter \
--input result/tax/sum_g.txt --design result/metadata.txt \
--transpose TRUE \
--width 89 --height 59 \
--group Group --output result/compare/feature_
1.5 三元图
#参考示例见:result\compare\ternary\ternary.Rmd 文档
#备选教程246.三元图的应用与绘图实战
2. STAMP输入文件准备
2.1 生成输入文件
Rscript ${db}/script/format2stamp.R -h
mkdir -p result/stamp
Rscript ${db}/script/format2stamp.R --input result/otutab.txt \
--taxonomy result/taxonomy.txt --threshold 0.01 \
--output result/stamp/tax
# 可选Rmd文档见result/format2stamp.Rmd
2.2 绘制扩展柱状图和表
compare="KO-WT"
# 替换ASV(result/otutab.txt)为属(result/tax/sum_g.txt)
Rscript ${db}/script/compare_stamp.R \
--input result/stamp/tax_5Family.txt --metadata result/metadata.txt \
--group Group --compare ${compare} --threshold 0.1 \
--method "t.test" --pvalue 0.05 --fdr "none" \
--width 189 --height 159 \
--output result/stamp/${compare}
# 可选Rmd文档见result/CompareStamp.Rmd
3. LEfSe输入文件准备
### 3.1. 命令行生成文件
# 可选命令行生成输入文件
Rscript ${db}/script/format2lefse.R -h
mkdir -p result/lefse
# threshold控制丰度筛选以控制作图中的枝数量
Rscript ${db}/script/format2lefse.R --input result/otutab.txt \
--taxonomy result/taxonomy.txt --design result/metadata.txt \
--group Group --threshold 0.4 \
--output result/lefse/LEfSe
### 3.2 Rmd生成输入文件(可选)
#1. result目录中存在otutab.txt, metadata.txt, taxonomy.txt三个文件;
#2. Rstudio打开EasyAmplicon中format2lefse.Rmd,另存至result目录并Knit生成输入文件和可重复计算网页;
### 3.3 LEfSe分析
#方法1. 打开LEfSe.txt并在线提交 https://www.bic.ac.cn/BIC/#/analysis?page=b%27MzY%3D%27
#方法2. LEfSe本地分析(限Linux系统、选学),参考代码见附录
#方法3. LEfSe官网在线使用
25、QIIME 2分析流程
# 代码详见 qiime2/pipeline_qiime2.sh
31、功能预测
1. PICRUSt功能预测
PICRUSt 1.0
# 方法1. 使用 http://www.ehbio.com/ImageGP 在线分析 gg/otutab.txt
# 方法2. Linux服务器用户可参考"附录2. PICRUSt功能预测"实现软件安装和分析
# 然后结果使用STAMP/R进行差异比较
# R语言绘图
# 输入文件格式调整
l=L2
sed '/# Const/d;s/OTU //' result/picrust/all_level.ko.${l}.txt > result/picrust/${l}.txt
num=`head -n1 result/picrust/${l}.txt|wc -w`
paste <(cut -f $num result/picrust/${l}.txt) <(cut -f 1-$[num-1] result/picrust/${l}.txt) \
> result/picrust/${l}.spf
cut -f 2- result/picrust/${l}.spf > result/picrust/${l}.mat.txt
awk 'BEGIN{FS=OFS="\t"} {print $2,$1}' result/picrust/${l}.spf | sed 's/;/\t/' | sed '1 s/ID/Pathway\tCategory/' \
> result/picrust/${l}.anno.txt
# 差异比较
compare="KO-WT"
Rscript ${db}/script/compare.R \
--input result/picrust/${l}.mat.txt --design result/metadata.txt \
--group Group --compare ${compare} --threshold 0 \
--method wilcox --pvalue 0.05 --fdr 0.2 \
--output result/picrust/
# 可对结果${compare}.txt筛选
# 绘制指定组(A/B)的柱状图,按高分类级着色和分面
Rscript ${db}/script/compare_hierarchy_facet.R \
--input result/picrust/${compare}.txt \
--data MeanA \
--annotation result/picrust/${l}.anno.txt \
--output result/picrust/${compare}.MeanA.bar.pdf
# 绘制两组显著差异柱状图,按高分类级分面
Rscript ${db}/script/compare_hierarchy_facet2.R \
--input result/picrust/${compare}.txt \
--pvalue 0.05 --fdr 0.1 \
--annotation result/picrust/${l}.anno.txt \
--output result/picrust/${compare}.bar.pdf
PICRUSt 2.0
# 软件安装见附录6. PICRUSt环境导出和导入
# (可选)PICRUSt2(Linux/Windows下Linux子系统,要求>16GB内存)
# 安装参考附录5的方式直接下载安装包并解压即可使用
# Linux中加载conda环境
conda activate picrust2
# 进入工作目录,服务器要修改工作目录
wd=/mnt/d/amplicon/result/picrust2
mkdir -p ${wd} && cd ${wd}
# 运行流程,内存15.7GB,耗时12m
picrust2_pipeline.py -s ../otus.fa -i ../otutab.txt -o ./out -p 8
# 添加EC/KO/Pathway注释
cd out
add_descriptions.py -i pathways_out/path_abun_unstrat.tsv.gz -m METACYC \
-o METACYC.tsv
add_descriptions.py -i EC_metagenome_out/pred_metagenome_unstrat.tsv.gz -m EC \
-o EC.tsv
add_descriptions.py -i KO_metagenome_out/pred_metagenome_unstrat.tsv.gz -m KO \
-o KO.tsv
# KEGG按层级合并
db=/mnt/d/EasyMicrobiome/
python3 ${db}/script/summarizeAbundance.py \
-i KO.tsv \
-m ${db}/kegg/KO1-4.txt \
-c 2,3,4 -s ',+,+,' -n raw \
-o KEGG
# 统计各层级特征数量
wc -l KEGG*
# 可视化见picrust2文件夹中ggpicrust2.Rmd
2. 元素循环FAPROTAX
## 方法1. 在线分析,推荐使用 http://www.bic.ac.cn/ImageGP/index.php/Home/Index/FAPROTAX.html 在线分析
## 方法2. Linux下分析、如QIIME 2环境下
# 设置工作目录
wd=/mnt/d/amplicon/result/faprotax/
mkdir -p ${wd} && cd ${wd}
# 设置脚本目录
sd=/mnt/d/EasyMicrobiome/script/FAPROTAX_1.2.7
### 1. 软件安装
# 注:软件已经下载至 EasyMicrobiome/script目录,在qiime2环境下运行可满足依赖关系
#(可选)下载软件新版本,以1.2.7版为例, 2023/7/14更新数据库
#wget -c https://pages.uoregon.edu/slouca/LoucaLab/archive/FAPROTAX/SECTION_Download/MODULE_Downloads/CLASS_Latest%20release/UNIT_FAPROTAX_1.2.7/FAPROTAX_1.2.7.zip
#解压
#unzip FAPROTAX_1.2.7.zip
#新建一个python3环境并配置依赖关系,或进入qiime2 python3环境
conda activate qiime2-2023.7
# source /home/silico_biotech/miniconda3/envs/qiime2/bin/activate
#测试是否可运行,弹出帮助即正常工作
python $sd/collapse_table.py
### 2. 制作输入OTU表
#txt转换为biom json格式
biom convert -i ../otutab_rare.txt -o otutab_rare.biom --table-type="OTU table" --to-json
#添加物种注释
biom add-metadata -i otutab_rare.biom --observation-metadata-fp ../taxonomy2.txt \
-o otutab_rare_tax.biom --sc-separated taxonomy \
--observation-header OTUID,taxonomy
#指定输入文件、物种注释、输出文件、注释列名、属性列名
### 3. FAPROTAX功能预测
#python运行collapse_table.py脚本、输入带有物种注释OTU表tax.biom、
#-g指定数据库位置,物种注释列名,输出过程信息,强制覆盖结果,结果文件和细节
#下载faprotax.txt,配合实验设计可进行统计分析
#faprotax_report.txt查看每个类别中具体来源哪些OTUs
python ${sd}/collapse_table.py -i otutab_rare_tax.biom \
-g ${sd}/FAPROTAX.txt \
--collapse_by_metadata 'taxonomy' -v --force \
-o faprotax.txt -r faprotax_report.txt
### 4. 制作OTU对应功能注释有无矩阵
# 对ASV(OTU)注释行,及前一行标题进行筛选
grep 'ASV_' -B 1 faprotax_report.txt | grep -v -P '^--$' > faprotax_report.clean
# faprotax_report_sum.pl脚本将数据整理为表格,位于public/scrit中
perl ${sd}/../faprotax_report_sum.pl -i faprotax_report.clean -o faprotax_report
# 查看功能有无矩阵,-S不换行
less -S faprotax_report.mat
3. Bugbase细菌表型预测
### 1. Bugbase命令行分析
cd ${wd}/result
bugbase=${db}/script/BugBase
rm -rf bugbase/
# 脚本已经优化适合R4.0,biom包更新为biomformat
Rscript ${bugbase}/bin/run.bugbase.r -L ${bugbase} \
-i gg/otutab.txt -m metadata.txt -c Group -o bugbase/
### 2. 其它可用分析
# 使用 http://www.bic.ac.cn/ImageGP/index.php/Home/Index/BugBase.html
# 官网,https://bugbase.cs.umn.edu/ ,有报错,不推荐
# Bugbase细菌表型预测Linux,详见附录3. Bugbase细菌表型预测
32、MachineLearning机器学习
# RandomForest包使用的R代码见advanced/RandomForestClassification和RandomForestRegression
## Silme2随机森林/Adaboost使用代码见EasyMicrobiome/script/slime2目录中的slime2.py,详见附录4
# 使用实战(使用QIIME 2的Python3环境,以在Windows中为例)
conda activate qiime2-2023.7
cd /mnt/d/EasyMicrobiome/script/slime2
#使用adaboost计算10000次(16.7s),推荐千万次
./slime2.py otutab.txt design.txt --normalize --tag ab_e4 ab -n 10000
#使用RandomForest计算10000次(14.5s),推荐百万次,支持多线程
./slime2.py otutab.txt design.txt --normalize --tag rf_e4 rf -n 10000
33、Evolution进化树
cd ${wd}
mkdir -p result/tree
cd ${wd}/result/tree
1. 筛选高丰度/指定的特征
#方法1. 按丰度筛选特征,一般选0.001或0.005,且OTU数量在30-150个范围内
#统计特征表中ASV数量,如总计1609个
tail -n+2 ../otutab_rare.txt | wc -l
#按相对丰度0.2%筛选高丰度OTU
usearch -otutab_trim ../otutab_rare.txt \
-min_otu_freq 0.002 \
-output otutab.txt
#统计筛选OTU表特征数量,总计~81个
tail -n+2 otutab.txt | wc -l
#方法2. 按数量筛选
# #按丰度排序,默认由大到小
# usearch -otutab_sortotus ../otutab_rare.txt \
# -output otutab_sort.txt
# #提取高丰度中指定Top数量的OTU ID,如Top100,
# sed '1 s/#OTU ID/OTUID/' otutab_sort.txt \
# | head -n101 > otutab.txt
#修改特征ID列名
sed -i '1 s/#OTU ID/OTUID/' otutab.txt
#提取ID用于提取序列
cut -f 1 otutab.txt > otutab_high.id
# 筛选高丰度菌/指定差异菌对应OTU序列
usearch -fastx_getseqs ../otus.fa -labels otutab_high.id \
-fastaout otus.fa
head -n 2 otus.fa
## 筛选OTU对物种注释
awk 'NR==FNR{a[$1]=$0} NR>FNR{print a[$1]}' ../taxonomy.txt \
otutab_high.id > otutab_high.tax
#获得OTU对应组均值,用于样本热图
#依赖之前otu_mean.R计算过按Group分组的均值
awk 'NR==FNR{a[$1]=$0} NR>FNR{print a[$1]}' ../otutab_mean.txt otutab_high.id \
| sed 's/#OTU ID/OTUID/' > otutab_high.mean
head -n3 otutab_high.mean
#合并物种注释和丰度为注释文件
cut -f 2- otutab_high.mean > temp
paste otutab_high.tax temp > annotation.txt
head -n 3 annotation.txt
2. 构建进化树
# 起始文件为 result/tree目录中 otus.fa(序列)、annotation.txt(物种和相对丰度)文件
# Muscle软件进行序列对齐,3s
muscle -in otus.fa -out otus_aligned.fas
### 方法1. 利用IQ-TREE快速构建ML进化树,2m
rm -rf iqtree
mkdir -p iqtree
iqtree -s otus_aligned.fas \
-bb 1000 -redo -alrt 1000 -nt AUTO \
-pre iqtree/otus
### 方法2. FastTree快速建树(Linux)
# 注意FastTree软件输入文件为fasta格式的文件,而不是通常用的Phylip格式。输出文件是Newick格式。
# 该方法适合于大数据,例如几百个OTUs的系统发育树!
# Ubuntu上安装fasttree可以使用`apt install fasttree`
# fasttree -gtr -nt otus_aligned.fas > otus.nwk
3. 进化树美化
# 访问http://itol.embl.de/,上传otus.nwk,再拖拽下方生成的注释方案于树上即美化
## 方案1. 外圈颜色、形状分类和丰度方案
# annotation.txt OTU对应物种注释和丰度,
# -a 找不到输入列将终止运行(默认不执行)-c 将整数列转换为factor或具有小数点的数字,-t 偏离提示标签时转换ID列,-w 颜色带,区域宽度等, -D输出目录,-i OTU列名,-l OTU显示名称如种/属/科名,
# cd ${wd}/result/tree
Rscript ${db}/script/table2itol.R -a -c double -D plan1 -i OTUID -l Genus -t %s -w 0.5 annotation.txt
# 生成注释文件中每列为单独一个文件
## 方案2. 生成丰度柱形图注释文件
Rscript ${db}/script/table2itol.R -a -d -c none -D plan2 -b Phylum -i OTUID -l Genus -t %s -w 0.5 annotation.txt
## 方案3. 生成热图注释文件
Rscript ${db}/script/table2itol.R -c keep -D plan3 -i OTUID -t %s otutab.txt
## 方案4. 将整数转化成因子生成注释文件
Rscript ${db}/script/table2itol.R -a -c factor -D plan4 -i OTUID -l Genus -t %s -w 0 annotation.txt
# 树iqtree/otus.contree在 http://itol.embl.de/ 上展示,拖拽不同Plan中的文件添加树注释
# 返回工作目录
cd ${wd}
4. 进化树可视化
https://www.bic.ac.cn/BIC/#/ 提供了更简易的可视化方式
附加视频
# 目录 Supp,网课有对应视频(可能编号不同,找关键字)
S1. 网络分析R/CytoGephi
# 目录 Supp/S1NetWork
S2. 溯源和马尔可夫链
# 目录 Supp/S2SourcetrackerFeastMarkov
S11、网络分析ggClusterNet
# 代码:advanced/ggClusterNet/Practice.Rmd
S12、Microeco包数据可视化
# 代码:advanced/microeco/Practice.Rmd
附录:Linux服务器下分析(选学)
#注:Windows下可能无法运行以下代码,推荐在Linux,或Windows下Linux子系统下conda安装相关程序
1. LEfSe分析
mkdir -p ~/amplicon/lefse
cd ~/amplicon/lefse
# format2lefse.Rmd代码制作或上传输入文件LEfSe.txt
# 安装lefse
# conda install lefse
#格式转换为lefse内部格式
lefse-format_input.py LEfSe.txt input.in -c 1 -o 1000000
#运行lefse
run_lefse.py input.in input.res
#绘制物种树注释差异
lefse-plot_cladogram.py input.res cladogram.pdf --format pdf
#绘制所有差异features柱状图
lefse-plot_res.py input.res res.pdf --format pdf
#绘制单个features柱状图(同STAMP中barplot)
head input.res #查看差异features列表
lefse-plot_features.py -f one --feature_name "Bacteria.Firmicutes.Bacilli.Bacillales.Planococcaceae.Paenisporosarcina" \
--format pdf input.in input.res Bacilli.pdf
#批量绘制所有差异features柱状图,慎用(几百张差异结果柱状图阅读也很困难)
mkdir -p features
lefse-plot_features.py -f diff --archive none --format pdf \
input.in input.res features/
2. PICRUSt功能预测
#推荐使用 http://www.bic.ac.cn/BIC/#/analysis?tool_type=tool&page=b%27Mzk%3D%27 在线分析
#有Linux服务器用户可参考以下代码搭建本地流程
n=picrust
conda create -n ${n} ${n} -c bioconda -y
wd=/mnt/d/amplicon
cd $wd/result/gg
# 启动环境
conda activate picrust
#上传gg/otutab.txt至当前目录
#转换为OTU表通用格式,方便下游分析和统计
biom convert -i otutab.txt \
-o otutab.biom \
--table-type="OTU table" --to-json
# 设置数据库目录,如 /mnt/d/db
db=~/db
#校正拷贝数,30s, 102M
normalize_by_copy_number.py -i otutab.biom \
-o otutab_norm.biom \
-c ${db}/picrust/16S_13_5_precalculated.tab.gz
#预测宏基因组KO表,3m,1.5G,biom方便下游归类,txt方便查看分析
predict_metagenomes.py -i otutab_norm.biom \
-o ko.biom \
-c ${db}/picrust/ko_13_5_precalculated.tab.gz
predict_metagenomes.py -f -i otutab_norm.biom \
-o ko.txt \
-c ${db}/picrust/ko_13_5_precalculated.tab.gz
#按功能级别分类汇总, -c输出KEGG_Pathways,分1-3级
sed -i '/# Constru/d;s/#OTU //' ko.txt
num=`head -n1 ko.txt|wc -w`
paste <(cut -f $num ko.txt) <(cut -f 1-$[num-1] ko.txt) > ko.spf
for i in 1 2 3;do
categorize_by_function.py -f -i ko.biom -c KEGG_Pathways -l ${i} -o pathway${i}.txt
sed -i '/# Const/d;s/#OTU //' pathway${i}.txt
paste <(cut -f $num pathway${i}.txt) <(cut -f 1-$[num-1] pathway${i}.txt) > pathway${i}.spf
done
wc -l *.spf
3. Bugbase细菌表型预测
### 1. 软件安装(己整合到EasyMicrobiome中,原代码需要更新才能在当前运行)
#有两种方法可选,推荐第一种,可选第二种,仅需运行一次
# #方法1. git下载,需要有git
# git clone https://github.com/knights-lab/BugBase
# #方法2. 下载并解压
# wget -c https://github.com/knights-lab/BugBase/archive/master.zip
# mv master.zip BugBase.zip
# unzip BugBase.zip
# mv BugBase-master/ BugBase
cd BugBase
#安装依赖包
export BUGBASE_PATH=`pwd`
export PATH=$PATH:`pwd`/bin
#安装了所有依赖包
run.bugbase.r -h
#测试数据
run.bugbase.r -i doc/data/HMP_s15.txt -m doc/data/HMP_map.txt -c HMPBODYSUBSITE -o output
### 2. 准备输入文件
cd ~/amplicon/result
#输入文件:基于greengene OTU表的biom格式(本地分析支持txt格式无需转换)和mapping file(metadata.txt首行添加#)
#上传实验设计+刚才生成的otutab_gg.txt
#生成在线分析使用的biom1.0格式
biom convert -i gg/otutab.txt -o otutab_gg.biom --table-type="OTU table" --to-json
sed '1 s/^/#/' metadata.txt > MappingFile.txt
#下载otutab_gg.biom 和 MappingFile.txt用于在线分析
### 3. 本地分析
export BUGBASE_PATH=`pwd`
export PATH=$PATH:`pwd`/bin
run.bugbase.r -i otutab_gg.txt -m MappingFile.txt -c Group -o phenotype/
4. Silme2随机森林/Adaboost
#下载安装
# cd ~/software/
# wget https://github.com/swo/slime2/archive/master.zip
# mv master.zip slime2.zip
# unzip slime2.zip
# mv slime2-master/ slime2
# cp slime2/slime2.py ~/bin/
# chmod +x ~/bin/slime2.py
#安装依赖包
# sudo pip3 install --upgrade pip
# sudo pip3 install pandas
# sudo pip3 install sklearn
5. PICRUSt2环境导出和导入
# 方法1. 下载安装包并解压
# 下载安装包,备用链接见百度云:https://pan.baidu.com/s/1Ikd_47HHODOqC3Rcx6eJ6Q?pwd=0315
wget -c ftp://download.nmdc.cn/tools/conda/picrust2.tar.gz
# 指定安装目录并解压
mkdir -p ~/miniconda3/envs/picrust2
tar -xvzf picrust2.tar.gz -C ~/miniconda3/envs/picrust2
# 激活环境并初始化
conda activate picrust2
conda unpack
# 方法2. 直接安装或打包安装环境
n=picrust2
conda create -n ${n} -c bioconda -c conda-forge ${n}=2.3.0_b
# 加载环境
conda activate ${n}
# 打包环境(可选)
conda pack -n ${n} -o ${n}.tar.gz
常见问题
1. 文件phred质量错误——Fastq质量值64转33
# 使用head查看fastq文件,phred64质量值多为小写字母,需要使用vsearch的--fastq_convert命令转换为通用的phred33格式。
cd /c/amplicon/FAQ/01Q64Q33
# 预览phred64格式,注意看第4行质量值多为小写字母
head -n4 test_64.fq
# 转换质量值64编码格式为33
vsearch --fastq_convert test_64.fq \
--fastq_ascii 64 --fastq_asciiout 33 \
--fastqout test.fq
# 查看转换后33编码格式,质量值多为大写字母
head -n4 test.fq
# 如果是Ion torrent测序结果,由于是非主流测序平台,需要公司转换帮助转换为标准的Phred33格式文件才可以使用。
2. 序列双端已经合并——单端序列添加样本名
# 扩增子分析要求序列名为样品名+序列编号,双端序列在合并同时可直接添加样本名。单端序列,或双端合并的序列需单独添加。这里使用vsearch的--fastq_convert命令中的--relabel参加添加样本名
cd /c/amplicon/FAQ/02relabel
# 查看文件序列名
head -n1 test.fq
# 序列按样本重命名
vsearch --fastq_convert test.fq \
--relabel WT1. \
--fastqout WT1.fq
# 查看重命名结果
head -n1 WT1.fq
3. 数据过大无法使用usearch聚类或去噪,替换vsearch
# 仅限usearch免费版受限时,可通过提高minuniquesize参数减少非冗余数据量。OTU/ASV过万下游分析等待时间过长,确保OTU/ASV数据小于5000,一般不会受限,而且也有利于下游开展快速分析。
# 备选vsearch聚类生成OTU,但无自动de novo去嵌合功能。输入2155条序列,聚类后输出661。
cd /c/amplicon/FAQ/03feature
# 重命名relabel、按相似id=97%聚类,不屏蔽qmask
# 记录输入sizein和输出频率sizeout
vsearch --cluster_size uniques.fa \
--relabel OTU_ --id 0.97 \
--qmask none --sizein --sizeout \
--centroids otus_raw.fa
# 再de novo去嵌合。55个嵌合,606个非嵌合。把OTU_1都去除了,没有Usearch内置去嵌合的方法合理。
# 自身比对去嵌合
vsearch --uchime_denovo otus_raw.fa \
--nonchimeras otus.fa
# 删除序列频率
sed -i 's/;.*//' otus.fa
4. 读长计数(Read counts)标准化为相对丰度
cd /c/amplicon/FAQ/04norm
# 求取各个OTU在样品中的丰度频率(标准化为总和1)
usearch -otutab_counts2freqs otutab.txt \
-output otutab_freq.txt
5. 运行R提示Permission denied
# 例如write.table保存表时,报错信息示例如下:意思是写入文件无权限,一般为目标文件正在被打开,请关闭相关文件后重试
Error in file(file, ifelse(append, "a", "w")) :
Calls: write.table -> file
: Warning message:
In file(file, ifelse(append, "a", "w")) :
'result/raw/otutab_nonBac.txt': Permission denied
6. 文件批量命名
# 如我们有文件A1和A2,编写一个样本名对应目标名的表格metadata.txt,检查样本名是否唯一,使用awk进行批量改名
cd /c/amplicon/FAQ/06rename
# (可选)快速生成文件列表,用于编辑metadata.txt,如A1.fq修改为WT1.fastq,以此类推,参考metadata.bak.txt
ls *.fq > metadata.txt
# 编辑列表,第二名为最终命名,确定名称唯一
# 转换行尾换行符
sed -i 's/\r//' metadata.txt
# 检查手动命名列2是否唯一
cut -f 2 metadata.txt|wc -l
cut -f 2 metadata.txt|sort|uniq|wc -l
# 如果两次结果一致,则命名非冗余
# 可选移动mv,复制cp,硬链ln,或软链ln -s
# 此处使用复制cp
awk '{system("cp "$1" "$2)}' metadata.txt
7. Rstudio中Terminal找不到Linux命令
# 需要把 C:\Program Files\Git\usr\bin 目录添加到系统环境变量
# 文件资源管理器——此电脑——属性——高级系统设置——环境变量——系统变量——Path——编辑——新建——填写“C:\Program Files\Git\usr\bin”——确定——确定——确定
# 注意win10系统是一个目录一行;win7中多个目录用分号分隔,注意向后添加目录
8. usearch -alpha_div_rare结果前两行出现“-”
#问题:抽样0时补“-”,且缺失制表符
#处理:替换“-”为"制作符\t+0"即可恢复
cd /c/amplicon/FAQ/08rare
sed "s/-/\t0.0/g" alpha_rare_wrong.txt\
> alpha_rare.txt
9. 物种注释otus.sintax方向全为“-”,需要序列取反向互补
#是原始序列方向错误,将filtered.fa序列需要取反向互补。再从头开始分析
cd /c/amplicon/FAQ/09revcom
vsearch --fastx_revcomp filtered_RC.fa \
--fastaout filtered.fa
10. windows换行符查看和删除
#Windows换行符为换行($)+^M,等于Linux换行+mac换行。分析数据中以linux格式为通用标准,因此windows中如excel编写并存为文本文件(制表符分隔)(*.txt)的表格,行尾有不可见的^M符号,导致分析出错。可使用cat -A命令查看此符号,可用sed删除。
cd /c/amplicon/FAQ/10^M
# 查看行尾是否有^M
cat -A metadata.txt
# 删除^M,并写入新文件
sed 's/\r//' metadata.txt > metadata.mod.txt
# 检查是否成功
cat -A metadata.mod.txt
# 直接原文件删除
sed -i 's/\r//' metadata.txt
11. UNITE数据库分析报错
#USEARCH使用UNITE下载的utax数据库,提示各种错误
cd /c/amplicon/FAQ/11unite
# 解压Unite的useach使用物种注释库
gunzip -c utax_reference_dataset_all_04.02.2020.fasta.gz > unite.fa
# 对ITS序列进行注释,默认阈值0.8
usearch --sintax otus.fa \
--db unite.fa \
--tabbedout otus.sintax --strand plus
--sintax_cutoff 0.6
#报错信息如下:
---Fatal error---
Missing x: in name >JN874928|SH1144646.08FU;tax=d:Metazoa,p:Cnidaria,c:Hydrozoa,o:Trachylina,f:,g:Craspedacusta,s:Craspedacusta_sowerbii_SH1144646.08FU;
“Unprintable ASCII character no 195 on or right before line 236492”
# 分析原因为分类级存在空缺。可用sed补全即可解决
# 分类级存在空缺,sed补全
sed -i 's/,;/,Unnamed;/;s/:,/:Unnamed,/g' unite.fa
# 再运行前面usearch --sintax命令
#注:vsearch有问题,推荐用usearch,结尾添加--strand plus才能成功运行
12. Windows的Linux子系统本地安装qiime2
# 详见 qiime2/pipeline_qiime2.sh
n=qiime2-2023.2
# 安装包下载链接
wget -c ftp://download.nmdc.cn/tools/conda/${n}.tar.gz
# 新环境安装
mkdir -p ~/miniconda3/envs/${n}
tar -xzf ${n}.tar.gz -C ~/miniconda3/envs/${n}
# 激活并初始化环境
conda activate ${n}
conda unpack
13. RDP 16-18注释结果比较
# 统计序列中门的数量,从60降为39
grep '>' ${db}/usearch/rdp_16s_v16_sp.fa|cut -f2 -d ';'|cut -f1-2 -d ','|sort|uniq|wc -l
grep '>' ${db}/usearch/rdp_16s_v18.fa|cut -f2 -d ';'|cut -f1-2 -d ','|sort|uniq|wc -l
# 统计序列中属的数量,从2517增长为3061
grep '>' ${db}/usearch/rdp_16s_v16_sp.fa|cut -f2 -d ';'|cut -f1-6 -d ','|sort|uniq|wc -l
grep '>' ${db}/usearch/rdp_16s_v18.fa|cut -f2 -d ';'|cut -f1-6 -d ','|sort|uniq|wc -l
cd /c/amplicon/FAQ/13rdp16_18
# 门由15个降为13个
tail -n+2 rdp16_sintax.txt|cut -f3|sort|uniq -c|wc -l
tail -n+2 rdp18_sintax.txt|cut -f3|sort|uniq -c|wc -l
# 属由176个降为144个
tail -n+2 rdp16_sintax.txt|cut -f7|sort|uniq -c|wc -l
tail -n+2 rdp18_sintax.txt|cut -f7|sort|uniq -c|wc -l
14. usearch生成OTU表小样本比vsearch更快
# usearch生成特征表,小样本(<30)快;但大样本受限且多线程效率低,83.2%, 4核17s
time usearch -otutab temp/filtered.fa \
-otus result/raw/otus.fa \
-threads 4 \
-otutabout result/raw/otutab.txt
# vsearch比对,更准更慢,但并行24-96线程更强
vsearch --usearch_global temp/filtered.fa --db ${db}/gg/97_otus.fa \
--otutabout result/gg/otutab.txt --id 0.97 --threads 12
# 比对率81.04%, 1核30m, 12核7m
版本更新记录
- 2021/4/3 EasyAmplicon 1.11:
- R包amplicon升级为 1.11.0,解决metadata两列报错的问题。
- 调整课程顺序,每天上午9点-12点2节,下午1点半-6点3节。
- 提供附加课程Supp目录。
- 2021/7/23 EasyAmplicon 1.12:
- R运行环境升级为4.1.0,配套有4.1.zip的全套包
- R包amplicon升级为 1.12.0,alpha_boxplot去掉Y轴的index
- alpha_boxplot.R增加标准化、转置等参数,可用于绘制任何特征箱线图
- beta_pcoa/cpcoa.R增加控制椭圆、标签显示等参数
- tax_stackplot.R增加多种配色方案
- picurst流程更新,并提供打包的conda下载
- picurst2新增KO合并为KEGG通路1-3级代码,并提供打包的conda下载
- 随机森林:提供分类级筛选、随机数筛选、可视化代码
- 2021/10/15 EasyAmplicon 1.13:
- R运行环境升级为4.1.1,配套有4.1.zip的最新全套包
- 元数据方差分解PERMANOVA:在Diversity-tutorial.Rmd中Beta多样性分析中新增adonis计算变量对群落的解析率和显著性分析
- 树图treemap升级后无颜色,改为代码供参考,并在Diversity_tutrial.Rmd中删除此部分
- alpha_boxplot输出无默认目录,可指定文件名头,添加无ID报错注释
- 2022/1/7 EasyAmplicon 1.14:
- R运行环境升级为4.1.2,配套有4.1.zip的最新全套包
- RStudio更新为2021.09.1
- 文涛重写amplicon包中tax_maptree函数,不依赖其他包,解决无法着色问题
- EasyMicrobiome中添加compare_stamp.R脚本,直接差异比较绘制STAMP扩展柱状图;代码详见result/CompareStamp.Rmd
- EasyMicrobiome中添加compare_hierarchy_facet.R和compare_hierarchy_facet2.R,展示KEGG的1,2级总览和差异
- 更新高级分析目录advanced:包括环境因子、马尔可无链、网络模块、网络比较、随机森林分类、随机森林回归、微生态等
- 2023/2/3 EasyAmplicon 1.18:
- R运行环境升级为4.2.2,配套有4.2.zip的最新全套包
- RStudio更新为2022.12.0
- amplicon、EasyAmplicon和EasyMicrobiome更新为1.18
- QIIME 2更新为v2023.2
- vsearch更新为v2.22.1
- 新增ggClusterNet课程-文涛
- 2023/10/13 EasyAmplicon 1.20:
- R运行环境升级为4.3.1,配套有4.3.zip的最新全套包
- RStudio更新为2023.12.0
- amplicon、EasyAmplicon和EasyMicrobiome更新为1.20
- QIIME 2更新为v2023.7,数据库更新为greengene2 2022.10
- 新增ggpicrust2分析picrust2结果可视化
- 更新FAPROTAX为1.2.7
每季度视频课程安排:http://www.ehbio.com/trainLongTerm/TrainLongTerm/amplicongenomeLearnGuide.html
使用此脚本,请引用下文:
If used this script, please cited:
Yong-Xin Liu, Lei Chen, Tengfei Ma, et al. 2023.
EasyAmplicon: An easy-to-use, open-source, reproducible, and community-based pipeline for amplicon data analysis in microbiome research.
iMeta 2: e83. https://doi.org/10.1002/imt2.83
Copyright 2016-2023 Yong-Xin Liu liuyongxin@caas.cn, Tao Wen taowen@njau.edu.cn, Tong Chen chent@nrc.ac.cn
**宏基因组学分析流程,绝对值得参考**
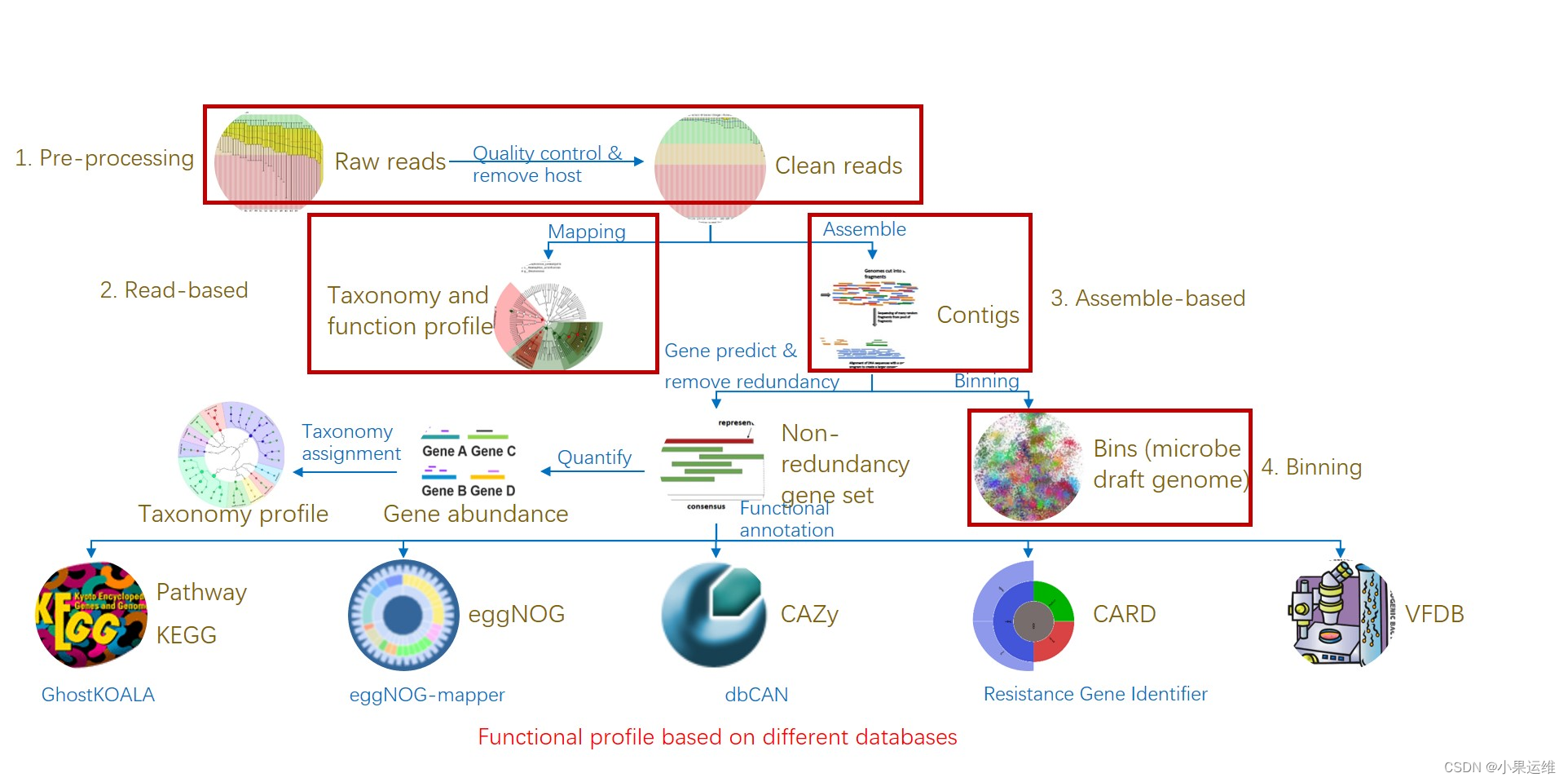
易宏基因组流程 EasyMetagenome Pipeline
# 版本Version: 1.20, 2023/11/23
# 操作系统Operation System: Linux Ubuntu 22.04+ / CentOS 7.7+
一、数据预处理 Data preprocessing
1.1 准备工作 Preparing
- 首次使用请参照
0Install.sh脚本,安装软件和数据库(大约1-3天,仅一次) - 易宏基因组(EasyMetagenome)流程
1Pipeline.sh复制到项目文件夹,如本次为meta - 项目文件夹准备测序数据(seq/*.fq.gz)和样本元数据(result/metadata.txt)
环境变量设置 Environment variable settings
分析前必须运行,设置数据库、软件和工作目录
# Conda软件安装目录,`conda env list`查看,如/anaconda3
soft=~/miniconda3
# 数据库database(db)位置,如管理员/db,个人~/db
db=~/db
# 设置工作目录work directory(wd),如meta
wd=~/meta
# 创建并进入工作目录
mkdir -p $wd && cd $wd
# 创建3个常用子目录:序列,临时文件和结果
mkdir -p seq temp result
# 添加分析所需的软件、脚本至环境变量,添加至~/.bashrc中自动加载
PATH=$soft/bin:$soft/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:$db/EasyMicrobiome/linux:$db/EasyMicrobiome/script
echo $PATH
元数据和序列文件 Metadata and Sequence Files
元数据
# 上传元数据metadata.txt至result目录,此处下载并重命名
wget http://www.imeta.science/github/EasyMetagenome/result/metadata.txt
mv metadata.txt result/metadata.txt
# 检查文件格式,^I为制表符,$为Linux换行,^M$为Windows回车,^M为Mac换行符
cat -A result/metadata.txt
# 根据样本文件生成元数据,可筛选子集,如EB开头
ls seq/EB*|grep '_1'|cut -f1 -d '_'|cut -f 2 -d '/'|sed'1 i SampleID'>result/metadataEB.txt
cp result/metadataEB.txt result/metadata.txt
# 元数据细节优化
# 转换Windows回车为Linux换行
sed -i 's/\r//' result/metadata.txt
# 去除数据中的一个多余空格
sed -i 's/Male /Male/' result/metadata.txt
cat -A result/metadata.txt
序列文件
# 用户使用filezilla上传测序文件至seq目录,本次从网络下载
# seq 目录下已经有测试文件,下载跳过
cd seq/
awk '{system("wget -c http://www.imeta.science/github/EasyMetagenome/seq/"$1"_1.fq.gz")}' <(tail -n+2 ../result/metadata.txt)
awk '{system("wget -c http://www.imeta.science/github/EasyMetagenome/seq/"$1"_2.fq.gz")}' <(tail -n+2 ../result/metadata.txt)
cd ..
# ls查看文件大小,-l 列出详细信息 (l: list),-sh 显示人类可读方式文件大小 (s: size; h: human readable)
ls -lsh seq/*.fq.gz
序列文件格式检查
zless/zcat查看可压缩文件,检查序列质量格式(质量值大写字母为标准Phred33格式,小写字母为Phred64,需参考附录:质量值转换);检查双端序列ID是否重名,如重名需要改名。参考附录 —— 质控kneaddata,去宿主后双端不匹配;序列改名。
# 设置某个样本名为变量i,以后再无需修改
i=C1
# zless查看压缩文件,空格翻页,q退出; head指定显示行数
zless seq/${i}_1.fq.gz | head -n4
工作目录和文件结构总结
# ├── pipeline.sh
# ├── result
# │ └── metadata.txt
# ├── seq
# │ ├── C1_1.fq.gz
# │ ├── ...
# │ └── N1_2.fq.gz
# └── temp
- 1pipeline.sh是分析流程代码;
- seq目录中有2个样本Illumina双端测序,4个序列文件;
- temp是临时文件夹,存储分析中间文件,结束可全部删除节约空间
- result是重要节点文件和整理化的分析结果图表,
- 实验设计metadata.txt也在此
1.2 Fastp质量控制 Quality Control
# 创建目录,记录软件版本和引文
mkdir -p temp/qc result/qc
fastp
# 单样本质控
i=C1
fastp -i seq/${i}_1.fq.gz -I seq/${i}_2.fq.gz \
-o temp/qc/${i}_1.fastq -O temp/qc/${i}_2.fastq
# 多样本并行
# -j 2: 表示同时处理2个样本
time tail -n+2 result/metadata.txt|cut -f1|rush -j 2 \
"fastp -i seq/{1}_1.fq.gz -I seq/{1}_2.fq.gz \
-j temp/qc/{1}_fastp.json -h temp/qc/{1}_fastp.html \
-o temp/qc/{1}_1.fastq -O temp/qc/{1}_2.fastq \
> temp/qc/{1}.log 2>&1 "
# 质控后结果汇总
echo -e "SampleID\tRaw\tClean" > temp/fastp
for i in `tail -n+2 result/metadata.txt|cut -f1`;do
echo -e -n "$i\t" >> temp/fastp
grep 'total reads' temp/qc/${i}.log|uniq|cut -f2 -d ':'|tr '\n' '\t' >> temp/fastp
echo "" >> temp/fastp
done
sed -i 's/ //g;s/\t$//' temp/fastp
# 按metadata排序
awk 'BEGIN{FS=OFS="\t"}NR==FNR{a[$1]=$0}NR>FNR{print a[$1]}' temp/fastp result/metadata.txt \
> result/qc/fastp.txt
cat result/qc/fastp.txt
1.3 KneadData去宿主 Host removal
kneaddata是流程主要依赖bowtie2比对宿主,然后筛选非宿主序列用于下游分析。
# 创建目录、启动环境、记录版本
mkdir -p temp/hr
conda activate kneaddata
kneaddata --version # 0.12.0
多样品并行去宿主,16p 4h
time tail -n+2 result/metadata.txt|cut -f1|rush -j 2 \
"sed '1~4 s/ 1:/.1:/;1~4 s/$/\/1/' temp/qc/{}_1.fastq > /tmp/{}_1.fastq; \
sed '1~4 s/ 2:/.1:/;1~4 s/$/\/2/' temp/qc/{}_2.fastq > /tmp/{}_2.fastq; \
kneaddata -i1 /tmp/{1}_1.fastq -i2 /tmp/{1}_2.fastq \
-o temp/hr --output-prefix {1} \
--bypass-trim --bypass-trf --reorder \
--bowtie2-options '--very-sensitive --dovetail' \
-db ${db}/kneaddata/human/hg37dec_v0.1 \
--remove-intermediate-output -v -t 3; \
rm /tmp/{}_1.fastq /tmp/{}_2.fastq"
# * 匹配任意多个字符,? 匹配任意一个字符
ls -shtr temp/hr/*_paired_?.fastq
简化改名
# Ubuntu系统改名
rename 's/paired_//' temp/hr/*.fastq
# CentOS系统改名
rename 'paired_' '' temp/hr/*.fastq
大文件清理,高宿主含量样本可节约>90%空间
# 使用命令的绝对路径确保使用无参数的命令,管理员用alias自定义命令含参数,影响操作结果
/bin/rm -rf temp/hr/*contam* temp/hr/*unmatched* temp/hr/reformatted* temp/hr/_temp*
ls -l temp/hr/
质控结果汇总
kneaddata_read_count_table --input temp/hr \
--output temp/kneaddata.txt
# 筛选重点结果列
cut -f 1,2,5,6 temp/kneaddata.txt | sed 's/_1_kneaddata//' > result/qc/sum.txt
# 对齐方式查看表格
csvtk -t pretty result/qc/sum.txt
二、基于读长分析 Read-based (HUMAnN3+MetaPhlAn4+Kraken2)
2.1 准备HUMAnN输入文件
HUMAnN要求双端序列合并的文件作为输入,for循环根据实验设计样本名批量双端序列合并。注意星号(*)和问号(?),分别代表多个和单个字符。当然大家更不能溜号,行分割的代码行末有一个\
mkdir -p temp/concat
# 双端合并为单个文件
for i in `tail -n+2 result/metadata.txt|cut -f1`;do
cat temp/hr/${i}_?.fastq \
> temp/concat/${i}.fq; done
# 查看样品数量和大小
ls -shl temp/concat/*.fq
# 数据太大,计算时间长,可用head对单端分析截取20M序列,即3G,行数为80M行,详见附录:HUMAnN2减少输入文件加速
2.2 HUMAnN计算物种和功能组成
- 物种组成调用MetaPhlAn4
- 输入文件:temp/concat/*.fq 每个样品质控后双端合并后的fastq序列
- 输出文件:temp/humann3/ 目录下
- C1_pathabundance.tsv
- C1_pathcoverage.tsv
- C1_genefamilies.tsv
- 整合后的输出:
- result/metaphlan4/taxonomy.tsv 物种丰度表
- result/metaphlan4/taxonomy.spf 物种丰度表(用于stamp分析)
- result/humann3/pathabundance_relab_unstratified.tsv 通路丰度表
- result/humann3/pathabundance_relab_stratified.tsv 通路物种组成丰度表
- stratified(每个菌对此功能通路组成的贡献)和unstratified(功能组成)
启动humann3环境,检查数据库配置
conda activate humann3
# 备选source加载指定环境
# source ~/miniconda3/envs/humann3/bin/activate
mkdir -p temp/humann3
humann --version # v3.7
humann_config
单样本1.25M PE150运行测试,8p,2.5M,1~2h;0.2M, 34m;0.1M,30m;0.01M,25m;16p,18m
i=C1
# 3p,26m; 数据库使用ssd缩短到19m;16p,8m
time humann --input temp/concat/${i}.fq --output temp/humann3 --threads 3 --metaphlan-options '--bowtie2db /db/metaphlan4 --index mpa_vOct22_CHOCOPhlAnSGB_202212 --offline'
多样本并行计算,测试数据约30m,推荐16p,3小时/样本
# 如果服务器性能好,请设置--threads值为8/16/32
tail -n+2 result/metadata.txt | cut -f1 | rush -j 2 \
"humann --input temp/concat/{1}.fq \
--output temp/humann3/ --threads 3 --metaphlan-options '--bowtie2db /db/metaphlan4 --index mpa_vOct22_CHOCOPhlAnSGB_202212 --offline'"
# 移动重要文件至humann3目录
# $(cmd) 与 `cmd` 通常是等价的;`cmd`写法更简单,但要注意反引号是键盘左上角ESC下面的按键,$(cmd)更通用,适合嵌套使用
for i in $(tail -n+2 result/metadata.txt | cut -f1); do
mv temp/humann3/${i}_humann_temp/${i}_metaphlan_bugs_list.tsv temp/humann3/
done
# 删除临时文件,极占用空间
/bin/rm -rf temp/concat/* temp/humann3/*_humann_temp
(可选)单独运行MetaPhlAn4
mkdir -p temp/humann3
i=C1
# 仅物种注释极快4p, 2m, 1m读取数据库
time metaphlan --input_type fastq temp/qc/${i}_1.fastq \
temp/humann3/${i}.txt --bowtie2db /db/metaphlan4 --index mpa_vOct22_CHOCOPhlAnSGB_202212 --offline \
--nproc 4
2.3 物种组成表
样品结果合并
mkdir -p result/metaphlan4
# 合并、修正样本名、预览
merge_metaphlan_tables.py temp/humann3/*_metaphlan_bugs_list.tsv | \
sed 's/_metaphlan_bugs_list//g' | tail -n+2 | sed '1 s/clade_name/ID/' | sed '2i #metaphlan4'> result/metaphlan4/taxonomy.tsv
csvtk -t stat result/metaphlan4/taxonomy.tsv
head -n5 result/metaphlan4/taxonomy.tsv
转换为stamp的spf格式
# metaphlan4较2增加更多unclassified和重复结果,用sort和uniq去除
metaphlan_to_stamp.pl result/metaphlan4/taxonomy.tsv \
|sort -r | uniq > result/metaphlan4/taxonomy.spf
head result/metaphlan4/taxonomy.spf
# STAMP不支持unclassified,需要过滤掉再使用
grep -v 'unclassified' result/metaphlan4/taxonomy.spf > result/metaphlan4/taxonomy2.spf
# 下载metadata.txt和taxonomy2.spf使用stamp分析
2.4 功能组成分析
功能组成样本合并合并
mkdir -p result/humann3
humann_join_tables --input temp/humann3 \
--file_name pathabundance \
--output result/humann3/pathabundance.tsv
# 样本名调整:删除列名多余信息
sed -i 's/_Abundance//g' result/humann3/pathabundance.tsv
# 统计和预览
csvtk -t stat result/humann3/pathabundance.tsv
head -n5 result/humann3/pathabundance.tsv
标准化为相对丰度relab(1)或百万比cpm(1,000,000)
humann_renorm_table \
--input result/humann3/pathabundance.tsv \
--units relab \
--output result/humann3/pathabundance_relab.tsv
head -n5 result/humann3/pathabundance_relab.tsv
分层结果:功能和对应物种表(stratified)和功能组成表(unstratified)
humann_split_stratified_table \
--input result/humann3/pathabundance_relab.tsv \
--output result/humann3/
差异比较和柱状图
两样本无法组间比较,在pcl层面替换为HMP数据进行统计和可视化。
- 输入数据:通路丰度表格 result/humann3/pathabundance.tsv和实验设计 result/metadata.txt
- 中间数据:包含分组信息的通路丰度表格文件 result/humann3/pathabundance.pcl
- 输出结果:result/humann3/associate.txt
在通路丰度中添加分组
## 提取样品列表
head -n1 result/humann3/pathabundance.tsv | sed 's/# Pathway/SampleID/' | tr '\t' '\n' > temp/header
## 对应分组,本示例分组为第2列($2),根据实际情况修改
awk 'BEGIN{FS=OFS="\t"}NR==FNR{a[$1]=$2}NR>FNR{print a[$1]}' result/metadata.txt temp/header | tr '\n' '\t'|sed 's/\t$/\n/' > temp/group
# 合成样本、分组+数据
cat <(head -n1 result/humann3/pathabundance.tsv) temp/group <(tail -n+2 result/humann3/pathabundance.tsv) \
> result/humann3/pathabundance.pcl
head -n5 result/humann3/pathabundance.pcl
tail -n5 result/humann3/pathabundance.pcl
组间比较,样本量少无差异,结果为4列的文件:通路名字,通路在各个分组的丰度,差异P-value,校正后的Q-value。
演示数据2样本无法统计,此处替换为HMP的结果演示统计和绘图(上传hmp_pathabund.pcl,替换pathabundance.pcl为hmp_pathabund.pcl)。
wget -c http://www.imeta.science/github/EasyMetagenome/result/humann2/hmp_pathabund.pcl
/bin/cp -f hmp_pathabund.pcl result/humann3/
# 设置输入文件名
pcl=result/humann3/hmp_pathabund.pcl
# 统计表格行、列数量
csvtk -t stat ${pcl}
head -n3 ${pcl} | cut -f 1-5
# 按分组KW检验,注意第二列的分组列名
humann_associate --input ${pcl} \
--focal-metadatum Group --focal-type categorical \
--last-metadatum Group --fdr 0.05 \
--output result/humann3/associate.txt
wc -l result/humann3/associate.txt
head -n5 result/humann3/associate.txt
barplot展示通路的物种组成,如:腺苷核苷酸合成
# 指定差异通路,如 P163-PWY,--sort sum metadata 按丰度和分组排序
path=P163-PWY
humann_barplot \
--input ${pcl} --focal-feature ${path} \
--focal-metadata Group --last-metadata Group \
--output result/humann3/barplot_${path}.pdf --sort sum metadata
KEGG注释
支持GO、PFAM、eggNOG、level4ec、KEGG的D级KO等注释,详见humann_regroup_table -h。
# 转换基因家族为KO(uniref90_ko),可选eggNOG(uniref90_eggnog)或酶(uniref90_level4ec)
for i in `tail -n+2 result/metadata.txt|cut -f1`;do
humann_regroup_table \
-i temp/humann3/${i}_genefamilies.tsv \
-g uniref90_ko \
-o temp/humann3/${i}_ko.tsv
done
# 合并,并修正样本名
humann_join_tables \
--input temp/humann3/ \
--file_name ko \
--output result/humann3/ko.tsv
sed -i '1s/_Abundance-RPKs//g' result/humann3/ko.tsv
tail result/humann3/ko.tsv
# 与pathabundance类似,可进行标准化renorm、分层stratified、柱状图barplot等操作
# 分层结果:功能和对应物种表(stratified)和功能组成表(unstratified)
humann_split_stratified_table \
--input result/humann3/ko.tsv \
--output result/humann3/
wc -l result/humann3/ko*
# KO合并为高层次L2, L1通路代码KO to level 1/2/3
summarizeAbundance.py \
-i result/humann3/ko_unstratified.tsv \
-m ${db}/EasyMicrobiome/kegg/KO1-4.txt \
-c 2,3,4 -s ',+,+,' -n raw \
-o result/humann3/KEGG
wc -l result/humann3/KEGG*
2.5 GraPhlAn图
# metaphlan2 to graphlan
conda activate humann2
export2graphlan.py --skip_rows 1,2 -i result/metaphlan4/taxonomy.tsv \
--tree temp/merged_abundance.tree.txt \
--annotation temp/merged_abundance.annot.txt \
--most_abundant 1000 --abundance_threshold 20 --least_biomarkers 10 \
--annotations 3,4 --external_annotations 7
# 参数说明见PPT,或运行 export2graphlan.py --help
# graphlan annotation
graphlan_annotate.py --annot temp/merged_abundance.annot.txt \
temp/merged_abundance.tree.txt temp/merged_abundance.xml
# output PDF figure, annoat and legend
graphlan.py temp/merged_abundance.xml result/metaphlan4/graphlan.pdf \
--external_legends
# GraPhlAn Plot(测试中)
graphlan_plot.r --input result/metaphlan4/taxonomy.spf \
--design result/metadata.txt --number 100 \
--group all --type heatmap \
--output result/metaphlan4/heatmap
2.6 LEfSe差异分析物种
- 输入文件:物种丰度表result/metaphlan2/taxonomy.tsv
- 输入文件:样品分组信息 result/metadata.txt
- 中间文件:整合后用于LefSe分析的文件 result/metaphlan2/lefse.txt,这个文件可以提供给www.ehbio.com/ImageGP 用于在线LefSE分析
- LefSe结果输出:result/metaphlan2/目录下lefse开头和feature开头的文件
前面演示数据仅有2个样本,无法进行差异比较。下面使用result12目录中由12个样本生成的结果表进行演示
# 设置结果目录,自己的数据使用result,演示用result12
result=result12
# 如果没有,请下载演示数据
wget -c http://www.imeta.science/db/EasyMetagenome/result12.zip
unzip result12.zip
准备输入文件,修改样本品为组名(可手动修改)
# 提取样本行替换为每个样本一行,修改ID为SampleID
head -n1 $result/metaphlan2/taxonomy.tsv|tr '\t' '\n'|sed '1 s/ID/SampleID/' >temp/sampleid
head -n3 temp/sampleid
# 提取SampleID对应的分组Group(假设为metadata.txt中第二列$2),替换换行\n为制表符\t,再把行末制表符\t替换回换行
awk 'BEGIN{OFS=FS="\t"}NR==FNR{a[$1]=$2}NR>FNR{print a[$1]}' $result/metadata.txt temp/sampleid|tr '\n' '\t'|sed 's/\t$/\n/' >groupid
cat groupid
# 合并分组和数据(替换表头)
cat groupid <(tail -n+2 $result/metaphlan2/taxonomy.tsv) > $result/metaphlan2/lefse.txt
head -n3 $result/metaphlan2/lefse.txt
方法1. 推荐在线 https://www.bic.ac.cn/ImageGP/ 中LEfSe一键分析
方法2. LEfSe命令行分析
conda activate lefse
result=result12
# 格式转换为lefse内部格式
lefse-format_input.py $result/metaphlan2/lefse.txt \
temp/input.in -c 1 -o 1000000
# 运行lefse(样本必须有重复和分组)
run_lefse.py temp/input.in temp/input.res
# 绘制物种树注释差异
lefse-plot_cladogram.py temp/input.res \
$result/metaphlan2/lefse_cladogram.pdf --format pdf
# 绘制所有差异features柱状图
lefse-plot_res.py temp/input.res \
$result/metaphlan2/lefse_res.pdf --format pdf
# 绘制单个features柱状图
# 查看显著差异features,按丰度排序
grep -v '-' temp/input.res | sort -k3,3n
# 手动选择指定feature绘图,如Firmicutes
lefse-plot_features.py -f one --format pdf \
--feature_name "k__Bacteria.p__Firmicutes" \
temp/input.in temp/input.res \
$result/metaphlan2/lefse_Firmicutes.pdf
# 批量绘制所有差异features柱状图
lefse-plot_features.py -f diff \
--archive none --format pdf \
temp/input.in temp/input.res \
$result/metaphlan2/lefse_
2.7 Kraken2+Bracken物种注释和丰度估计
Kraken2可以快速完成读长(read)层面的物种注释和定量,还可以进行重叠群(contig)、基因(gene)、宏基因组组装基因组(MAG/bin)层面的序列物种注释。
# 启动kraken2工作环境
conda activate kraken2
# 记录软件版本
kraken2 --version # 2.1.2
mkdir -p temp/kraken2
Kraken2物种注释
输入:temp/qc/{1}_?.fastq 质控后的数据,{1}代表样本名;
参考数据库:-db ${db}/kraken2/pluspfp16g/
输出结果:每个样本单独输出,temp/kraken2/中的{1}_report和{1}_output
整合物种丰度表输出结果:result/kraken2/taxonomy_count.txt
(可选) 单样本注释,5m,50G大数据库较5G库注释比例提高10~20%。以C1为例,在2023/3/14版中,8g: 31.75%; 16g: 52.35%; 150g: 71.98%;同为16g,2023/10/9版本为63.88%
# 根据电脑内存由小到大选择下面3个数据库
# pluspf16g/pluspfp(55G)/plusppfp(120G)
i=C1
time kraken2 --db ${db}/kraken2/pluspf16g/ \
--paired temp/qc/${i}_?.fastq \
--threads 2 --use-names --report-zero-counts \
--report temp/kraken2/${i}.report \
--output temp/kraken2/${i}.output
多样本并行生成report,1样本8线程逐个运行,内存大但速度快,不建议用多任务并行
for i in `tail -n+2 result/metadata.txt | cut -f1`;do
kraken2 --db ${db}/kraken2/pluspf16g \
--paired temp/qc/${i}_?.fastq \
--threads 2 --use-names --report-zero-counts \
--report temp/kraken2/${i}.report \
--output temp/kraken2/${i}.output; done
使用krakentools转换report为mpa格式
for i in `tail -n+2 result/metadata.txt | cut -f1`;do
kreport2mpa.py -r temp/kraken2/${i}.report \
--display-header -o temp/kraken2/${i}.mpa; done
合并样本为表格
mkdir -p result/kraken2
# 输出结果行数相同,但不一定顺序一致,要重新排序
tail -n+2 result/metadata.txt | cut -f1 | rush -j 1 \
'tail -n+2 temp/kraken2/{1}.mpa | LC_ALL=C sort | cut -f 2 | sed "1 s/^/{1}\n/" > temp/kraken2/{1}_count '
# 提取第一样本品行名为表行名
header=`tail -n 1 result/metadata.txt | cut -f 1`
echo $header
tail -n+2 temp/kraken2/${header}.mpa | LC_ALL=C sort | cut -f 1 | \
sed "1 s/^/Taxonomy\n/" > temp/kraken2/0header_count
head -n3 temp/kraken2/0header_count
# paste合并样本为表格
ls temp/kraken2/*count
paste temp/kraken2/*count > result/kraken2/tax_count.mpa
# 检查表格及统计
csvtk -t stat result/kraken2/tax_count.mpa
head -n 5 result/kraken2/tax_count.mpa
Bracken丰度估计
参数简介:
- -d为数据库,-i为输入kraken2报告文件
- r是读长,此处为100,通常为150,o输出重新估计的值
- l为分类级,可选域D、门P、纲C、目O、科F、属G、种S级别丰度估计
- t是阈值,默认为0,越大越可靠,但可用数据越少
循环重新估计每个样品的丰度,请修改tax分别重新计算P和S各1次
# 设置估算的分类级别D,P,C,O,F,G,S,常用门P和种S
# 测序6G起样本-t 10过滤低丰度物种
tax=S
mkdir -p temp/bracken
for i in `tail -n+2 result/metadata.txt | cut -f1`;do
# i=C1
bracken -d ${db}/kraken2/pluspf16g/ \
-i temp/kraken2/${i}.report \
-r 100 -l ${tax} -t 0 \
-o temp/bracken/${i}.brk \
-w temp/bracken/${i}.report; done
# bracken结果合并成表: 需按表头排序,提取第6列reads count,并添加样本名
tail -n+2 result/metadata.txt | cut -f1 | rush -j 1 \
'tail -n+2 temp/bracken/{1}.brk | LC_ALL=C sort | cut -f6 | sed "1 s/^/{1}\n/" \
> temp/bracken/{1}.count'
# 提取第一样本品行名为表行名
h=`tail -n1 result/metadata.txt|cut -f1`
tail -n+2 temp/bracken/${h}.brk | sort | cut -f1 | \
sed "1 s/^/Taxonomy\n/" > temp/bracken/0header.count
# 检查文件数,为n+1
ls temp/bracken/*count | wc
# paste合并样本为表格,并删除非零行
paste temp/bracken/*count > result/kraken2/bracken.${tax}.txt
# 统计行列,默认去除表头
csvtk -t stat result/kraken2/bracken.${tax}.txt
# 按频率过滤,-r可标准化,-e过滤(microbiome_helper)
Rscript ${db}/EasyMicrobiome/script/filter_feature_table.R \
-i result/kraken2/bracken.${tax}.txt \
-p 0.01 \
-o result/kraken2/bracken.${tax}.0.01
csvtk -t stat result/kraken2/bracken.${tax}.0.01
个性化结果筛选
# 门水平去除脊索动物(人)
grep 'Chordata' result/kraken2/bracken.P.0.01
grep -v 'Chordata' result/kraken2/bracken.P.0.01 > result/kraken2/bracken.P.0.01-H
# 按物种名手动去除宿主污染,以人为例(需按种水平计算相关结果)
# 种水平去除人类P:Chordata,S:Homo sapiens
grep 'Homo sapiens' result/kraken2/bracken.S.0.01
grep -v 'Homo sapiens' result/kraken2/bracken.S.0.01 \
> result/kraken2/bracken.S.0.01-H
分析后清理每条序列的注释大文件
/bin/rm -rf temp/kraken2/*.output
多样性和可视化
alpha多样性计算:Berger Parker’s (BP), Simpson’s (Si), inverse Simpson’s (ISi), Shannon’s (Sh) # Fisher’s (F)依赖scipy.optimize包,默认未安装
mkdir -p result/kraken2
echo -e "SampleID\tBerger Parker\tSimpson\tinverse Simpson\tShannon" > result/kraken2/alpha.txt
for i in `tail -n+2 result/metadata.txt|cut -f1`;do
echo -e -n "$i\t" >> result/kraken2/alpha.txt
for a in BP Si ISi Sh;do
alpha_diversity.py -f temp/bracken/${i}.brk -a $a | cut -f 2 -d ':' | tr '\n' '\t' >> result/kraken2/alpha.txt
done
echo "" >> result/kraken2/alpha.txt
done
cat result/kraken2/alpha.txt
beta多样性计算
beta_diversity.py -i temp/bracken/*.brk --type bracken \
> result/kraken2/beta.txt
cat result/kraken2/beta.txt
Krona图
for i in `tail -n+2 result/metadata.txt|cut -f1`;do
kreport2krona.py -r temp/bracken/${i}.report -o temp/bracken/${i}.krona --no-intermediate-ranks
ktImportText temp/bracken/${i}.krona -o result/kraken2/krona.${i}.html
done
Pavian桑基图:https://fbreitwieser.shinyapps.io/pavian/ 在线可视化:,左侧菜单,Upload sample set (temp/bracken/*.report),支持多样本同时上传;Sample查看结果,Configure Sankey配置图样式,Save Network下载图网页
多样性分析/物种组成,详见3StatPlot.sh,Kraken2结果筛选序列见附录
三、组装分析流程 Assemble-based
组装
# 启动工作环境
conda activate megahit
MEGAHIT组装Assembly
# 删除旧文件夹,否则megahit无法运行
# /bin/rm -rf temp/megahit
# 组装,10~30m,TB级数据需几天至几周
megahit -t 3 \
-1 `tail -n+2 result/metadata.txt|cut -f1|sed 's/^/temp\/hr\//;s/$/_1.fastq/'|tr '\n' ','|sed 's/,$//'` \
-2 `tail -n+2 result/metadata.txt|cut -f1|sed 's/^/temp\/hr\//;s/$/_2.fastq/'|tr '\n' ','|sed 's/,$//'` \
-o temp/megahit
# 统计大小通常300M~5G,如果contigs太多,可以按长度筛选,降低数据量,提高基因完整度,详见附录megahit
seqkit stat temp/megahit/final.contigs.fa
# 预览重叠群最前6行,前60列字符
head -n6 temp/megahit/final.contigs.fa | cut -c1-60
# 备份重要结果
mkdir -p result/megahit/
ln -f temp/megahit/final.contigs.fa result/megahit/
# 删除临时文件
/bin/rm -rf temp/megahit/intermediate_contigs
(可选)metaSPAdes精细组装
# 精细但使用内存和时间更多,15~65m
/usr/bin/time -v -o metaspades.py.log metaspades.py -t 3 -m 100 \
`tail -n+2 result/metadata.txt|cut -f1|sed 's/^/temp\/qc\//;s/$/_1.fastq/'|sed 's/^/-1 /'| tr '\n' ' '` \
`tail -n+2 result/metadata.txt|cut -f1|sed 's/^/temp\/qc\//;s/$/_2.fastq/'|sed 's/^/-2 /'| tr '\n' ' '` \
-o temp/metaspades
# 查看软件时间User time和内存Maximum resident set size
cat metaspades.py.log
# 2.3M,contigs体积更大
ls -sh temp/metaspades/contigs.fasta
seqkit stat temp/metaspades/contigs.fasta
# 备份重要结果
mkdir -p result/metaspades/
ln -f temp/metaspades/contigs.fasta result/metaspades/
# 删除临时文件
/bin/rm -rf temp/metaspades
注:metaSPAdes支持二、三代混合组装,见附录,此外还有OPERA-MS组装二、三代方案
QUAST评估
# QUAST评估,生成report文本tsv/txt、网页html、PDF等格式报告
quast.py result/megahit/final.contigs.fa \
-o result/megahit/quast -t 2
# (可选) megahit和metaspades比较
quast.py --label "megahit,metapasdes" \
result/megahit/final.contigs.fa \
result/metaspades/contigs.fasta \
-o result/quast
# (可选)metaquast评估,更全面,但需下载相关数据库,受网速影响可能时间很长(经常失败)
# metaquast based on silva, and top 50 species genome, 18min
time metaquast.py result/megahit/final.contigs.fa \
-o result/megahit/metaquast
3.2 基因预测、去冗余和定量Gene prediction, cluster & quantitfy
metaProdigal基因预测Gene prediction
# 输入文件:组装的序列 result/megahit/final.contigs.fa
# 输出文件:prodigal预测的基因序列 temp/prodigal/gene.fa
# 基因大,可参考附录prodigal拆分基因文件,并行计算
mkdir -p temp/prodigal
# prodigal的meta模式预测基因,>和2>&1记录分析过程至gene.log
prodigal -i result/megahit/final.contigs.fa \
-d temp/prodigal/gene.fa \
-o temp/prodigal/gene.gff \
-p meta -f gff > temp/prodigal/gene.log 2>&1
# 查看日志是否运行完成,有无错误
tail temp/prodigal/gene.log
# 统计基因数量
seqkit stat temp/prodigal/gene.fa
# 统计完整基因数量,数据量大可只用完整基因部分
grep -c 'partial=00' temp/prodigal/gene.fa
# 提取完整基因(完整片段获得的基因全为完整,如成环的细菌基因组)
grep 'partial=00' temp/prodigal/gene.fa | cut -f1 -d ' '| sed 's/>//' > temp/prodigal/full_length.id
seqkit grep -f temp/prodigal/full_length.id temp/prodigal/gene.fa > temp/prodigal/full_length.fa
seqkit stat temp/prodigal/full_length.fa
cd-hit基因聚类/去冗余cluster & redundancy
# 输入文件:prodigal预测的基因序列 temp/prodigal/gene.fa
# 输出文件:去冗余后的基因和蛋白序列:result/NR/nucleotide.fa, result/NR/protein.fa
mkdir -p result/NR
# aS覆盖度,c相似度,G局部比对,g最优解,T多线程,M内存0不限制
# 2万基因2m,2千万需要2000h,多线程可加速
cd-hit-est -i temp/prodigal/gene.fa \
-o result/NR/nucleotide.fa \
-aS 0.9 -c 0.95 -G 0 -g 0 -T 0 -M 0
# 统计非冗余基因数量,单次拼接结果数量下降不大,多批拼接冗余度高
grep -c '>' result/NR/nucleotide.fa
# 翻译核酸为对应蛋白序列, --trim去除结尾的*
seqkit translate --trim result/NR/nucleotide.fa \
> result/NR/protein.fa
# 两批数据去冗余使用cd-hit-est-2d加速,见附录
salmon基因定量quantitfy
# 输入文件:去冗余后的基因序列:result/NR/nucleotide.fa
# 输出文件:Salmon定量:result/salmon/gene.count, gene.TPM
mkdir -p temp/salmon
salmon -v # 1.8.0
# 建索引, -t序列, -i 索引,10s
salmon index -t result/NR/nucleotide.fa \
-p 3 -i temp/salmon/index
# 定量,l文库类型自动选择,p线程,--meta宏基因组模式, 2个任务并行2个样
tail -n+2 result/metadata.txt | cut -f1 | rush -j 2 \
"salmon quant -i temp/salmon/index -l A -p 3 --meta \
-1 temp/qc/{1}_1.fastq -2 temp/qc/{1}_2.fastq \
-o temp/salmon/{1}.quant"
# 合并
mkdir -p result/salmon
salmon quantmerge --quants temp/salmon/*.quant \
-o result/salmon/gene.TPM
salmon quantmerge --quants temp/salmon/*.quant \
--column NumReads -o result/salmon/gene.count
sed -i '1 s/.quant//g' result/salmon/gene.*
# 预览结果表格
head -n3 result/salmon/gene.*
3.3 功能基因注释Functional gene annotation
# 输入数据:上一步预测的蛋白序列 result/NR/protein.fa
# 中间结果:temp/eggnog/protein.emapper.seed_orthologs
# temp/eggnog/output.emapper.annotations
# temp/eggnog/output
# COG定量表:result/eggnog/cogtab.count
# result/eggnog/cogtab.count.spf (用于STAMP)
# KO定量表:result/eggnog/kotab.count
# result/eggnog/kotab.count.spf (用于STAMP)
# CAZy碳水化合物注释和定量:result/dbcan3/cazytab.count
# result/dbcan3/cazytab.count.spf (用于STAMP)
# 抗生素抗性:result/resfam/resfam.count
# result/resfam/resfam.count.spf (用于STAMP)
# 这部分可以拓展到其它数据库
eggNOG基因注释gene annotation(COG/KEGG/CAZy)
软件主页:https://github.com/eggnogdb/eggnog-mapper
# 运行并记录软件版本
conda activate eggnog
emapper.py --version
# emapper-2.1.7 / Expected eggNOG DB version: 5.0.2
# Diamond version found: diamond version 2.0.15
# 运行emapper,18m,默认diamond 1e-3
mkdir -p temp/eggnog
time emapper.py --data_dir ${db}/eggnog \
-i result/NR/protein.fa --cpu 3 -m diamond --override \
-o temp/eggnog/output
# 格式化结果并显示表头
grep -v '^##' temp/eggnog/output.emapper.annotations | sed '1 s/^#//' \
> temp/eggnog/output
csvtk -t headers -v temp/eggnog/output
# 生成COG/KO/CAZy丰度汇总表
mkdir -p result/eggnog
# 显示帮助
summarizeAbundance.py -h
# 汇总,7列COG_category按字母分隔,12列KEGG_ko和19列CAZy按逗号分隔,原始值累加
summarizeAbundance.py \
-i result/salmon/gene.TPM \
-m temp/eggnog/output --dropkeycolumn \
-c '7,12,19' -s '*+,+,' -n raw \
-o result/eggnog/eggnog
sed -i 's#^ko:##' result/eggnog/eggnog.KEGG_ko.raw.txt
sed -i '/^-/d' result/eggnog/eggnog*
head -n3 result/eggnog/eggnog*
# eggnog.CAZy.raw.txt eggnog.COG_category.raw.txt eggnog.KEGG_ko.raw.txt
# 添加注释生成STAMP的spf格式
awk 'BEGIN{FS=OFS="\t"} NR==FNR{a[$1]=$2} NR>FNR{print a[$1],$0}' \
${db}/EasyMicrobiome/kegg/KO_description.txt \
result/eggnog/eggnog.KEGG_ko.raw.txt | \
sed 's/^\t/Unannotated\t/' \
> result/eggnog/eggnog.KEGG_ko.TPM.spf
head -n 5 result/eggnog/eggnog.KEGG_ko.TPM.spf
# KO to level 1/2/3
summarizeAbundance.py \
-i result/eggnog/eggnog.KEGG_ko.raw.txt \
-m ${db}/EasyMicrobiome/kegg/KO1-4.txt \
-c 2,3,4 -s ',+,+,' -n raw --dropkeycolumn \
-o result/eggnog/KEGG
head -n3 result/eggnog/KEGG*
# CAZy
awk 'BEGIN{FS=OFS="\t"} NR==FNR{a[$1]=$2} NR>FNR{print a[$1],$0}' \
${db}/EasyMicrobiome/dbcan2/CAZy_description.txt result/eggnog/eggnog.CAZy.raw.txt | \
sed 's/^\t/Unannotated\t/' > result/eggnog/eggnog.CAZy.TPM.spf
head -n 3 result/eggnog/eggnog.CAZy.TPM.spf
# COG
awk 'BEGIN{FS=OFS="\t"} NR==FNR{a[$1]=$2"\t"$3} NR>FNR{print a[$1],$0}' \
${db}/EasyMicrobiome/eggnog/COG.anno result/eggnog/eggnog.COG_category.raw.txt > \
result/eggnog/eggnog.COG_category.TPM.spf
head -n 3 result/eggnog/eggnog.COG_category.TPM.spf
CAZy碳水化合物酶
# 比对CAZy数据库, 用时2~18m
mkdir -p temp/dbcan3 result/dbcan3
# --sensitive慢10倍,dbcan3e值为1e-102,此处以1e-3演示
time diamond blastp \
--db ${db}/dbcan3/CAZyDB \
--query result/NR/protein.fa \
--threads 2 -e 1e-3 --outfmt 6 --max-target-seqs 1 --quiet \
--out temp/dbcan3/gene_diamond.f6
wc -l temp/dbcan3/gene_diamond.f6
# 提取基因与dbcan分类对应表
format_dbcan2list.pl \
-i temp/dbcan3/gene_diamond.f6 \
-o temp/dbcan3/gene.list
# 按对应表累计丰度,依赖
summarizeAbundance.py \
-i result/salmon/gene.TPM \
-m temp/dbcan3/gene.list \
-c 2 -s ',' -n raw --dropkeycolumn \
-o result/dbcan3/TPM
# 添加注释生成STAMP的spf格式,结合metadata.txt进行差异比较
awk 'BEGIN{FS=OFS="\t"} NR==FNR{a[$1]=$2} NR>FNR{print a[$1],$0}' \
${db}/EasyMicrobiome/dbcan2/CAZy_description.txt result/dbcan3/TPM.CAZy.raw.txt | \
sed 's/^\t/Unannotated\t/' \
> result/dbcan3/TPM.CAZy.raw.spf
head result/dbcan3/TPM.CAZy.raw.spf
# 检查未注释数量,有则需要检查原因
grep 'Unannotated' result/dbcan3/TPM.CAZy.raw.spf|wc -l
CARD耐药基因
CARD在线分析平台:https://card.mcmaster.ca/
本地软件使用教程: https://github.com/arpcard/rgi
参考文献:http://doi.org/10.1093/nar/gkz935
结果说明:protein.json,在线可视化;protein.txt,注释基因列表
mkdir -p result/card
# 启动rgi环境和记录版本
conda activate rgi6
rgi main -v # 6.0.3
# 简化蛋白ID
cut -f 1 -d ' ' result/NR/protein.fa > temp/protein.fa
# 这个错误忽略即可,不是报错,没有任何影响 grep: 写错误: 断开的管道
grep '>' result/NR/protein.fa | head -n 3
grep '>' temp/protein.fa | head -n 3
# 蛋白层面注释ARG
rgi main -i temp/protein.fa -t protein \
-n 9 -a DIAMOND --include_loose --clean \
-o result/card/protein
head -n3 result/card/protein.txt
# 基因层面注释ARG
cut -f 1 -d ' ' result/NR/nucleotide.fa > temp/nucleotide.fa
grep '>' temp/nucleotide.fa | head -n3
rgi main -i temp/nucleotide.fa -t contig \
-n 9 -a DIAMOND --include_loose --clean \
-o result/card/nucleotide
head -n3 result/card/nucleotide.txt
# 重叠群层面注释ARG
cut -f 1 -d ' ' result/megahit/final.contigs.fa > temp/contigs.fa
grep '>' temp/contigs.fa | head -n3
rgi main -i temp/contigs.fa -t contig \
-n 9 -a DIAMOND --include_loose --clean \
-o result/card/contigs
head result/card/contigs.txt
3.4 基因物种注释
# Generate report in default taxid output
conda activate kraken2
kraken2 --db ${db}/kraken2/pluspf16g \
result/NR/nucleotide.fa \
--threads 3 \
--report temp/NRgene.report \
--output temp/NRgene.output
# Genes & taxid list
grep '^C' temp/NRgene.output | cut -f 2,3 | sed '1 i Name\ttaxid' \
> temp/NRgene.taxid
# Add taxonomy
awk 'BEGIN{FS=OFS="\t"} NR==FNR{a[$1]=$0} NR>FNR{print $1,a[$2]}' \
$db/EasyMicrobiome/kraken2/taxonomy.txt \
temp/NRgene.taxid > result/NR/nucleotide.tax
conda activate eggnog
summarizeAbundance.py \
-i result/salmon/gene.TPM \
-m result/NR/nucleotide.tax --dropkeycolumn \
-c '2,3,4,5,6,7,8,9' -s ',+,+,+,+,+,+,+,' -n raw \
-o result/NR/tax
wc -l result/NR/tax*|sort -n
四、分箱挖掘单菌基因组Binning
4.1 MetaWRAP混合样本分箱 Samples binning
主页:https://github.com/bxlab/metaWRAP
教程: https://github.com/bxlab/metaWRAP/blob/master/Usage_tutorial.md
挖掘单菌基因组,需要研究对象复杂度越低、测序深度越大,结果质量越好。要求单样本6GB+,复杂样本如土壤推荐数据量30GB+,至少3个样本
演示数据12个样仅140MB,无法获得单菌基因组,这里使用官方测序数据演示讲解
软件和数据库布置需1-3天,演示数据分析过程超10h,30G样也需1-30天,由服务器性能决定。
# 设置并进入工作目录
wd=~/meta/binning
mkdir -p ${wd} && cd ${wd}
# 初始化项目
mkdir -p temp/hr seq result
# 启动metawrap环境
conda activate metawrap
数据和环境变量 Data and enviroment
这里基于质控clean数据和拼接好的重叠群contigs,基于上游结果继续分析。由于上游测试数据过小,分箱无结果。 本次采用软件推荐的7G数据,我们进入一个新文件夹开展分析。
输入输出文件介绍:
# 输入:质控后序列,文件名格式为*_1.fastq和*_2.fastq,temp/qc 目录下,如C1_1.fastq、C1_2.fastq
# 组装的重叠群文件:result/megahit/final.contigs.fa
# 输出:
# Binning结果:temp/binning
# 提纯后的Bin统计结果:temp/bin_refinement/metawrap_50_10_bins.stats
# Bin定量结果文件和图:binning/temp/bin_quant/bin_abundance_table.tab 和 bin_abundance_heatmap.png
# Bin物种注释:binning/temp/bin_classify/bin_taxonomy.tab
# Prokka基因预测:binning/temp/bin_annotate/prokka_out/bin.*.ffn 核酸序列
# Bin可视化图表:binning/temp/bloblogy/final.contigs.binned.blobplot (数据表) 和 blobplot_figures (可视化图)
准备输入文件:原始数据+组装结果
# 质控后数据位于temp/qc中,此处需下载并解压
# 方法1. 直接拷贝
/bin/cp -rf /db/metawrap/*.fastq ~/meta/binning/temp/hr/
# 方法2. 在线下载
cd temp/hr
for i in `seq 7 9`;do
wget -c ftp.sra.ebi.ac.uk/vol1/fastq/ERR011/ERR01134${i}/ERR01134${i}_1.fastq.gz
wget -c ftp.sra.ebi.ac.uk/vol1/fastq/ERR011/ERR01134${i}/ERR01134${i}_2.fastq.gz
done
gunzip -k *.gz
# 批量修改扩展名fq为fastq
# rename .fq .fastq *.fq
# megahit拼接结果
cd ${wd}
mkdir -p temp/megahit
cd temp/megahit
# 可从EasyMetagenome目录复制,或链接下载
wget -c http://www.imeta.science/db/metawrap/final.contigs.fa.gz
gunzip -k *.gz
cd ${wd}
分箱Binning
# 加载运行环境
cd ${wd}
conda activate metawrap
metawrap -v # 1.3.2
# 输入文件为contig和clean reads
# 调用maxbin2, metabat2,8p线程2h,24p耗时1h;-concoct 3h
nohup metawrap binning -o temp/binning \
-t 3 -a temp/megahit/final.contigs.fa \
--metabat2 --maxbin2 \
temp/hr/*.fastq
# --concoct > /dev/null 2>&1 增加3~10倍计算量,添加/dev/null清除海量Warning信息
分箱提纯Bin refinement
# 8线程2h, 24p 1.3h;2方法16p 20m
metawrap bin_refinement \
-o temp/bin_refinement \
-A temp/binning/metabat2_bins/ \
-B temp/binning/maxbin2_bins/ \
-c 50 -x 10 -t 8
# -C temp/binning/concoct_bins/ \
# 统计高质量Bin的数量,2方法6个,3方法9个
tail -n+2 temp/bin_refinement/metawrap_50_10_bins.stats|wc -l
# 分析比较图见 temp/bin_refinement/figures/
所有分箱至同一目录All bins in one directory
mkdir -p temp/drep_in
# 混合组装分箱链接和重命名
ln -s `pwd`/temp/bin_refinement/metawrap_50_10_bins/bin.* temp/drep_in/
ls -l temp/drep_in/
# 改名CentOS
rename 'bin.' 'Mx_All_' temp/drep_in/bin.*
# 改名Ubuntu
rename s/bin./Mx_All_/ temp/drep_in/bin.*
ls temp/drep_in/Mx*
(可选Opt)单样本分箱Single sample binning
多样本受硬件、计算时间限制无法完成时,需要单样本组装、分箱。多样本信息丰度,分箱结果更多,更容易降低污染。详见:- Nature Methods | 单样本与多样本宏基因组分箱的比较揭示了广泛存在的隐藏性污染
设置全局线程、并行任务数和筛选分箱的条件
# p:threads线程数,job任务数,complete完整度x:contaminate污染率
conda activate metawrap
p=16
j=3
c=50
x=10
(可选)并行需要样本列表,请提前编写metadata.txt保存于result中
# 快速读取文件生成样本ID列表再继续编写
ls temp/hr/ | grep _1 | cut -f 1 -d '_' | sort -u | sed '1 i SampleID' > result/metadata.txt
# 预览
cat result/metadata.txt
组装Assemble
单样本并行组装;支持中断继续运行
tail -n+2 result/metadata.txt|cut -f1|rush -j ${j} \
"metawrap assembly -m 200 -t ${p} --megahit \
-1 temp/hr/{}_1.fastq -2 temp/hr/{}_2.fastq \
-o temp/megahit/{}"
分箱binning
单样本并行分箱,192p, 15m (concoct使用超多线程);16p 2d/sample, >/dev/null 16p 12h/sample
time tail -n+2 result/metadata.txt|cut -f1|rush -j ${j} \
"metawrap binning \
-o temp/binning/{} -t ${p} \
-a temp/megahit/{}/final_assembly.fasta \
--metabat2 --maxbin2 --concoct \
temp/hr/{}_*.fastq > /dev/null 2>&1"
分箱提纯bin refinement
time tail -n+2 result/metadata.txt|cut -f1|rush -j ${j} \
"metawrap bin_refinement \
-o temp/bin_refinement/{} -t ${p} \
-A temp/binning/{}/metabat2_bins/ \
-B temp/binning/{}/maxbin2_bins/ \
-C temp/binning/{}/concoct_bins/ \
-c ${c} -x ${x} "
# 分别为1,2,2个
tail -n+2 result/metadata.txt|cut -f1|rush -j 1 \
"tail -n+2 temp/bin_refinement/{}/metawrap_50_10_bins.stats|wc -l "
单样品分箱链接和重命名
for i in `tail -n+2 result/metadata.txt|cut -f1`;do
ln -s `pwd`/temp/bin_refinement/${i}/metawrap_50_10_bins/bin.* temp/drep_in/
# CentOS
rename 'bin.' "Sg_${i}_" temp/drep_in/bin.*
# Ubuntu
rename "s/bin./Sg_${i}_/" temp/drep_in/bin.*
done
# 删除空白中无效链接
/bin/rm -f temp/drep_in/*\*
# 统计混合和单样本来源数据,10个混,5个单;不同系统结果略有差异
ls temp/drep_in/|cut -f 1 -d '_'|uniq -c
# 统计混合批次/单样本来源
ls temp/drep_in/|cut -f 2 -d '_'|cut -f 1 -d '.' |uniq -c
(可选Opt)分组分箱 Subgroup binning
样本>30或数据量>300G在1TB内存胖结点上完成混合组装和分箱可能内存不足、且时间>1周甚至1月,需要对研究相近条件、地点进行分小组,且每组编写一个metadata??.txt。
conda activate metawrap
# 小组ID: A1/A2/A3
g=A1
组装Assemble:<30个或<300G样本,~12h
metawrap assembly -m 600 -t 32 --megahit \
-1 `tail -n+2 result/metadata${g}.txt|cut -f1|sed 's/^/temp\/hr\//;s/$/_1.fastq/'|tr '\n' ','|sed 's/,$//'` \
-2 `tail -n+2 result/metadata${g}.txt|cut -f1|sed 's/^/temp\/hr\//;s/$/_2.fastq/'|tr '\n' ','|sed 's/,$//'` \
-o temp/megahit_${g}
分箱Binning,~18h
# 链接文件到临时位置
mkdir -p temp/${g}/
for i in `tail -n+2 result/metadata${g}.txt|cut -f1`;do
ln -s `pwd`/temp/hr/${i}*.fastq temp/${g}/
done
# 按组分箱
metawrap binning -o temp/binning_${g} \
-t 32 -a temp/megahit_${g}/final_assembly.fasta \
--metabat2 --maxbin2 \
temp/${g}/*.fastq
分箱提纯Bin refinement
metawrap bin_refinement \
-o temp/bin_refinement_${g} \
-A temp/binning_${g}/metabat2_bins/ \
-B temp/binning_${g}/maxbin2_bins/ \
-c 50 -x 10 -t 32
# 统计高质量Bin的数量
wc -l temp/bin_refinement_${g}/metawrap_50_10_bins.stats
改名汇总 Rename & merge
mkdir -p temp/drep_in
# 混合组装分箱链接和重命名
ln -s `pwd`/temp/bin_refinement_${g}/metawrap_50_10_bins/bin.* temp/drep_in/
# 改名
rename "s/bin./Gp_${g}_/" temp/drep_in/bin.* # Ubuntu
# rename 'bin.' "Gp_${g}_" temp/drep_in/bin.* # CentOS
# 统计
mkdir -p result/bin
echo -n $g >> result/bin/groupNo.txt
ls temp/drep_in/Gp_${g}_*|wc>> result/bin/groupNo.txt
cat result/bin/groupNo.txt
4.2 dRep去冗余种/株基因组集
# 进入虚拟环境drep和工作目录
conda activate drep
cd ${wd}
按种水平去冗余:6~40min,15个为10个,8个来自混拼,2个来自单拼
mkdir -p temp/drep95
# /bin/rm -rf temp/drep95/data/checkM
time dRep dereplicate temp/drep95/ \
-g temp/drep_in/*.fa \
-sa 0.95 -nc 0.30 -comp 50 -con 10 -p 5
# 报错日志在temp/drep95/log/cmd_logs中查看,加-d显示更多
ls temp/drep95/dereplicated_genomes/|cut -f 1 -d '_'|sort|uniq -c
主要结果temp/drep95中:
- 非冗余基因组集:temp/drep95/dereplicated_genomes/*.fa
- 聚类信息表:temp/drep95/data_tables/Cdb.csv
- 聚类和质量图:temp/drep95/figures/clustering
(可选)按株水平99%去冗余,20-30min,本处也为10个
mkdir -p temp/drep99
time dRep dereplicate temp/drep99/ \
-g temp/drep_in/*.fa \
-sa 0.99 -nc 0.30 -comp 50 -con 10 -p 5
ls -l temp/drep99/dereplicated_genomes/ | grep '.fa' | wc -l
4.3 CoverM基因组定量
# 启动环境
conda activate coverm
mkdir -p temp/coverm
# (可选)单样本测试, 3min
i=ERR011347
time coverm genome --coupled temp/hr/${i}_1.fastq temp/hr/${i}_2.fastq \
--genome-fasta-directory temp/drep95/dereplicated_genomes/ -x fa \
-o temp/coverm/${i}.txt
cat temp/coverm/${i}.txt
# 并行计算, 4min
tail -n+2 result/metadata.txt|cut -f1|rush -j 2 \
"coverm genome --coupled temp/hr/{}_1.fastq temp/hr/{}_2.fastq \
--genome-fasta-directory temp/drep95/dereplicated_genomes/ -x fa \
-o temp/coverm/{}.txt"
# 结果合并
mkdir -p result/coverm
conda activate humann3
sed -i 's/_1.fastq Relative Abundance (%)//' temp/coverm/*.txt
humann_join_tables --input temp/coverm \
--file_name txt \
--output result/coverm/abundance.tsv
# 按组求均值,需要metadata中有3列且每个组有多个样本
Rscript ${db}/EasyMicrobiome/script/otu_mean.R --input result/coverm/abundance.tsv \
--metadata result/metadata.txt \
--group Group --thre 0 \
--scale TRUE --zoom 100 --all TRUE --type mean \
--output result/coverm/group_mean.txt
# https://www.bic.ac.cn/ImageGP/ 直接选择热图可视化
4.4 GTDB-tk物种注释和进化树
启动软件所在虚拟环境
conda activate gtdbtk2.3
export GTDBTK_DATA_PATH="${db}/gtdb"
gtdbtk -v # 2.3.2
代表性细菌基因组物种注释
mkdir -p temp/gtdb_classify
# 10个基因组,24p,100min 152G内存; 6p, 22基因组,1h
gtdbtk classify_wf \
--genome_dir temp/drep95/dereplicated_genomes \
--out_dir temp/gtdb_classify \
--extension fa --skip_ani_screen \
--prefix tax \
--cpus 6
# less -S按行查看,按q退出
less -S temp/gtdb_classify/tax.bac120.summary.tsv
less -S temp/gtdb_classify/tax.ar53.summary.tsv
代表种注释:以上面鉴定的10个种为例,注意扩展名要与输入文件一致,可使用压缩格式gz。主要结果文件描述:此9个细菌基因组在tax.bac120.summary.tsv。古菌在tax.ar53开头的文件中。
(可选)所有MAG物种注释
mkdir -p temp/gtdb_all
# 10000个基因组,32p,100min
time gtdbtk classify_wf \
--genome_dir temp/drep_in/ \
--out_dir temp/gtdb_all \
--extension fa --skip_ani_screen \
--prefix tax \
--cpus 6
less -S temp/gtdb_all/tax.bac120.summary.tsv
less -S temp/gtdb_all/tax.ar53.summary.tsv
多序列对齐结果建树
# 以9个细菌基因组的120个单拷贝基因建树,1s
mkdir -p temp/gtdb_infer
gtdbtk infer --msa_file temp/gtdb_classify/align/tax.bac120.user_msa.fasta.gz \
--out_dir temp/gtdb_infer --prefix tax --cpus 3
树文件tax.unrooted.tree可使用iTOL在线美化,也可使用GraphLan本地美化。
制作树注释文件:以gtdb-tk物种注释(tax.bac120.summary.tsv)和drep基因组评估(Widb.csv)信息为注释信息
mkdir -p result/itol
# 制作分类学表
tail -n+2 temp/gtdb_classify/tax.bac120.summary.tsv|cut -f 1-2|sed 's/;/\t/g'|sed '1 s/^/ID\tDomain\tPhylum\tClass\tOrder\tFamily\tGenus\tSpecies\n/' \
> result/itol/tax.txt
head result/itol/tax.txt
# 基因组评估信息
sed 's/,/\t/g;s/.fa//' temp/drep95/data_tables/Widb.csv|cut -f 1-7,11|sed '1 s/genome/ID/' \
> result/itol/genome.txt
head result/itol/genome.txt
# 整合注释文件
awk 'BEGIN{OFS=FS="\t"} NR==FNR{a[$1]=$0} NR>FNR{print $0,a[$1]}' result/itol/genome.txt result/itol/tax.txt|cut -f 1-8,10- > result/itol/annotation.txt
head result/itol/annotation.txt
# 添加各样本相对丰度(各组替换均值)
awk 'BEGIN{OFS=FS="\t"} NR==FNR{a[$1]=$0} NR>FNR{print $0,a[$1]}' <(sed '1 s/Genome/ID/' result/coverm/abundance.tsv) result/itol/annotation.txt|cut -f 1-15,17- > result/itol/annotation2.txt
head result/itol/annotation2.txt
CheckM2重新评估
conda activate checkm2
mkdir -p temp/checkm2 result/checkm2
# 10 genomes, 2m
time checkm2 predict --input temp/drep95/dereplicated_genomes/* --output-directory temp/checkm2 --threads 8
ln temp/checkm2/quality_report.tsv result/checkm2/
# 查看结果
less result/checkm2//quality_report.tsv
5 (可选)单菌基因组
5.1 Fastp质量控制
# 每个样本~30s,173个j2共
mkdir -p temp/qc/
time tail -n+2 result/metadata.txt | cut -f1 | rush -j 2 \
"time fastp -i seq/{1}_1.fq.gz -I seq/{1}_2.fq.gz \
-j temp/qc/{1}_fastp.json -h temp/qc/{1}_fastp.html \
-o temp/qc/{1}_1.fastq -O temp/qc/{1}_2.fastq \
> temp/qc/{1}.log 2>&1"
5.2 metaspades组装
conda activate megahit
spades.py -v # v3.15.4,>3.14.0才支持--isolate模式
mkdir -p temp/spades result/spades
# 127 genoms, 1m17s
time tail -n+2 result/metadata.txt|cut -f1|rush -j 3 \
"spades.py --pe1-1 temp/qc/{1}_1.fastq \
--pe1-2 temp/qc/{1}_2.fastq \
-t 16 --isolate --cov-cutoff auto \
-o temp/spades/{1}"
# 筛选>1k的序列并汇总、统计
time tail -n+2 result/metadata.txt|cut -f1|rush -j 3 \
"seqkit seq -m 1000 temp/spades/{1}/contigs.fasta \
> temp/spades/{1}.fa"
seqkit stat temp/spades/*.fa | sed 's/temp\/spades\///;s/.fa//' > result/spades/stat1k.txt
5.3 checkm质量评估
checkm评估质量
conda activate drep
checkm # CheckM v1.1.2
mkdir -p temp/checkm result/checkm
# 127 genoms, 1m17s
time checkm lineage_wf -t 8 -x fa temp/spades/ temp/checkm
# format checkm jason to tab
checkmJason2tsv.R -i temp/checkm/storage/bin_stats_ext.tsv \
-o temp/checkm/bin_stats.txt
csvtk -t pretty temp/checkm/bin_stats.txt | less
(可选)checkm2评估(测试中…)
conda activate checkm2
mkdir -p temp/checkm2
time checkm2 predict --threads 8 --input temp/spades/ --output-directory temp/checkm2
筛选污染和高质量基因组 >5% contamination and high quailty
awk '$5<90 || $10>5' temp/checkm/bin_stats.txt | csvtk -t cut -f 1,5,10,4,9,2 > temp/checkm/contamination5.txt
tail -n+2 temp/checkm/contamination5.txt|wc -l
# 筛选高质量用于下游分析 <5% high-quality for down-stream analysis
awk '$5>=90 && $10<=5' temp/checkm/bin_stats.txt | csvtk -t cut -f 1,5,10,4,9,2 | sed '1 i ID\tCompleteness\tContamination\tGC\tN50\tsize' > result/checkm/Comp90Cont5.txt
tail -n+2 result/checkm/Comp90Cont5.txt|wc -l
# 链接高质量基因组至新目录,单菌完整度通常>99%
mkdir -p temp/drep_in/
for n in `tail -n+2 result/checkm/Comp90Cont5.txt|cut -f 1`;do
ln temp/spades/${n}.fa temp/drep_in/
done
5.4 混菌metawarp分箱
分箱和提纯binning & refinement
conda activate metawrap
mkdir -p temp/binning temp/bin
time tail -n+2 temp/checkm/contamination5.txt|cut -f1|rush -j 3 \
"metawrap binning \
-o temp/binning/{} -t 8 \
-a temp/spades/{}/contigs.fasta \
--metabat2 --maxbin2 \
temp/qc/{}_*.fastq"
time tail -n+2 temp/checkm/contamination5.txt|cut -f1|rush -j 15 \
"metawrap bin_refinement \
-o temp/bin/{} -t 8 \
-A temp/binning/{}/metabat2_bins/ \
-B temp/binning/{}/maxbin2_bins/ \
-c 50 -x 10"
分箱结果汇总
echo -n -e "" > temp/bin/metawrap.stat
for m in `tail -n+2 temp/checkm/contamination5.txt|cut -f1`;do
echo ${m} >> temp/bin/metawrap.stat
cut -f1-4,6-7 temp/bin/${m}/metawrap_50_10_bins.stats >> temp/bin/metawrap.stat
done
# 分箱后的按b1,b2,b3重命名共培养,单菌也可能减少污染
for m in `tail -n+2 temp/checkm/contamination5.txt|cut -f1`;do
c=1
for n in `tail -n+2 temp/bin/$m/metawrap_50_10_bins.stats|cut -f 1`;do
cp temp/bin/$m/metawrap_50_10_bins/${n}.fa temp/drep_in/${m}b${c}.fa
((c++))
done
done
分箱前后统计比较
# 如107个测序分箱为352个基因组,共418个基因组
tail -n+2 temp/checkm/contamination5.txt|wc -l
ls temp/drep_in/*b?.fa | wc -l
ls temp/drep_in/*.fa | wc -l
# 重建新ID列表,A代表所有,B代表Bin分箱过的单菌
ls temp/drep_in/*.fa|cut -f 3 -d '/'|sed 's/.fa//'|sed '1 i ID'|less -S>result/metadataA.txt
ls temp/drep_in/*b?.fa|cut -f 3 -d '/'|sed 's/.fa//'|sed '1 i ID'|less -S>result/metadataB.txt
可视化混菌中覆盖度分布,以第一污染菌为例
i=`tail -n+2 temp/checkm/contamination5.txt|head -n1|cut -f1`
# grep '>' temp/spades/${i}.fa|cut -f 2,4,6 -d '_'|sed 's/^/C/;s/_/\t/g'|sed '1i Contig\tLength\tCoverage'>temp/spades/${i}.len
grep '>' temp/drep_in/${i}*|cut -f 3 -d '/'|sed 's/.fa:>NODE//'|cut -f 1,2,4,6 -d '_'|sed 's/_/\t/g'|sed '1i Genome\tContig\tLength\tvalue' > temp/drep_in/${i}.cov
sp_lines.sh -f temp/drep_in/${i}.cov -m TRUE -A TRUE -a Contig -H Genome
5.5 drep基因组去冗余
mkdir -p temp/drep95/
conda activate drep
# 相似度sa 0.99995 去重复, 0.99 株水平, 0.95 种水平
dRep dereplicate \
-g temp/drep_in/*.fa \
-sa 0.95 -nc 0.3 -p 16 -comp 50 -con 10 \
temp/drep95
# 统计总和使用基因组数据,确保没有异常丢弃stat total and used genomes, keep no abnormal discard
ls temp/drep_in/*.fa|wc -l
grep 'passed checkM' temp/drep95/log/logger.log|sed 's/[ ][ ]*/ /g'|cut -f 4 -d ' '
# 去冗余后数量,418变为49种
ls temp/drep95/dereplicated_genomes/|wc -l
# 唯一和重复的基因组unique and duplicate genome
csvtk cut -f 11 temp/drep95/data_tables/Widb.csv | sort | uniq -c
# 整理种列表
echo "SampleID" > result/metadataS.txt
ls temp/drep95/dereplicated_genomes/|sed 's/\.fa//' >> result/metadataS.txt
5.6 gtdb物种注释
conda activate gtdbtk2.3
# 所有基因组注释,400g, 1h, 1T
mkdir -p temp/gtdb_all result/gtdb_all
memusg -t gtdbtk classify_wf \
--genome_dir temp/drep_in/ \
--out_dir temp/gtdb_all/ \
--extension fa --skip_ani_screen \
--prefix tax \
--cpus 16
# 基因组信息genomeInfo.csv
sed 's/,/\t/g;s/.fa//' temp/drep95/data_tables/genomeInfo.csv |sed '1 s/genome/ID/' > result/gtdb_all/genome.txt
# 95%聚类种基因组注释,40g, 1h, 500G
mkdir -p temp/gtdb_95 result/gtdb_95
# Taxonomy classify
memusg -t gtdbtk classify_wf \
--genome_dir temp/drep95/dereplicated_genomes/ \
--out_dir temp/gtdb_95 \
--extension fa --skip_ani_screen \
--prefix tax \
--cpus 8
# Phylogenetic tree infer
memusg -t gtdbtk infer \
--msa_file temp/gtdb_95/align/tax.bac120.user_msa.fasta.gz \
--out_dir temp/gtdb_95 \
--cpus 8 --prefix g >> temp/gtdb_95/infer.log 2>&1
ln `pwd`/temp/gtdb_95/infer/intermediate_results/g.unrooted.tree result/gtdb_95/
# 细菌format to standard 7 levels taxonomy
tail -n+2 temp/gtdb_95/classify/tax.bac120.summary.tsv|cut -f 1-2|sed 's/;/\t/g'|sed '1 s/^/ID\tKingdom\tPhylum\tClass\tOrder\tFamily\tGenus\tSpecies\n/' > result/gtdb_95/tax.bac.txt
# 古菌(可选)
tail -n+2 temp/gtdb_95/classify/tax.ar122.summary.tsv|cut -f 1-2|sed 's/;/\t/g'|sed '1 s/^/ID\tKingdom\tPhylum\tClass\tOrder\tFamily\tGenus\tSpecies\n/' > result/gtdb_95/tax.ar.txt
cat result/gtdb_95/tax.bac.txt <(tail -n+2 result/gtdb_95/tax.ar.txt) > result/gtdb_95/tax.txt
# Widb.csv 非冗余基因组信息
sed 's/,/\t/g;s/.fa//' temp/drep95/data_tables/Widb.csv|cut -f 1-7,11|sed '1 s/genome/ID/' > result/gtdb_95/genome.txt
# 整合物种注释和基因组信息 Integrated taxonomy and genomic info
awk 'BEGIN{OFS=FS="\t"} NR==FNR{a[$1]=$0} NR>FNR{print $0,a[$1]}' result/gtdb_95/genome.txt result/gtdb_95/tax.txt|cut -f 1-8,10- > result/gtdb_95/annotation.txt
# csvtk -t headers -v result/gtdb_95/annotation.txt
# 制作itol files
cd result/gtdb_95
table2itol.R -D plan1 -a -c double -i ID -l Genus -t %s -w 0.5 annotation.txt
table2itol.R -D plan2 -a -d -c none -b Phylum -i ID -l Genus -t %s -w 0.5 annotation.txt
table2itol.R -D plan3 -c keep -i ID -t %s annotation.txt
table2itol.R -D plan4 -a -c factor -i ID -l Genus -t %s -w 0 annotation.txt
# Stat each level
echo -e 'Taxonomy\tKnown\tNew' > tax.stat
for i in `seq 2 8`;do
head -n1 tax.txt|cut -f ${i}|tr '\n' '\t' >> tax.stat
tail -n+2 tax.txt|cut -f ${i}|grep -v '__$'|sort|uniq -c|wc -l|tr '\n' '\t' >> tax.stat
tail -n+2 tax.txt|cut -f ${i}|grep '__$'|wc -l >> tax.stat; done
cat tax.stat
tail -n+2 tax.txt|cut -f3|sort|uniq -c|awk '{print $2"\t"$1}'|sort -k2,2nr > count.phylum
cat count.phylum
cd ../..
5.7 功能注释eggnog/dbcan/arg/antismash
基因注释
mkdir -p temp/prodigal

最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
awk ‘BEGIN{OFS=FS=“\t”} NR==FNR{a[$1]=$0} NR>FNR{print $0,a[$1]}’ result/gtdb_95/genome.txt result/gtdb_95/tax.txt|cut -f 1-8,10- > result/gtdb_95/annotation.txt
# csvtk -t headers -v result/gtdb_95/annotation.txt
# 制作itol files
cd result/gtdb_95
table2itol.R -D plan1 -a -c double -i ID -l Genus -t %s -w 0.5 annotation.txt
table2itol.R -D plan2 -a -d -c none -b Phylum -i ID -l Genus -t %s -w 0.5 annotation.txt
table2itol.R -D plan3 -c keep -i ID -t %s annotation.txt
table2itol.R -D plan4 -a -c factor -i ID -l Genus -t %s -w 0 annotation.txt
# Stat each level
echo -e 'Taxonomy\tKnown\tNew' > tax.stat
for i in `seq 2 8`;do
head -n1 tax.txt|cut -f ${i}|tr '\n' '\t' >> tax.stat
tail -n+2 tax.txt|cut -f ${i}|grep -v '__$'|sort|uniq -c|wc -l|tr '\n' '\t' >> tax.stat
tail -n+2 tax.txt|cut -f ${i}|grep '__$'|wc -l >> tax.stat; done
cat tax.stat
tail -n+2 tax.txt|cut -f3|sort|uniq -c|awk '{print $2"\t"$1}'|sort -k2,2nr > count.phylum
cat count.phylum
cd ../..
5.7 功能注释eggnog/dbcan/arg/antismash
基因注释
mkdir -p temp/prodigal
最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow
第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。
本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
[外链图片转存中…(img-42d6k73E-1713321966071)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2286
2286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









