






任务 1.1 读取“LR.csv”,提取表 1 中所列字段的数据,筛选出字段“Typrep”值为“A”的数据,将筛选出的数据另存为文件“LR_1.csv”(文件编码设置为UTF-8),并在报告中呈现筛选后的数据行数、列数。
import pandas as pd
df = pd.read_csv('LR.csv')
df.head()
data = df[df['Typrep'] == 'A']
data.reset_index(drop = True)
data.to_csv('LR_1.csv',index = None, encoding='utf-8')
print(f'LR数据集的行数为{data.shape[0]},列数为{data.shape[1]}')任务 1.2 读取“LR_1.csv”、“ZCFZ.csv”、“Stk_ind.csv”三个数据文件。根据“Stkcd”、“Accper”和“Typrep”三个字段,提取“ZCFZ.csv”中字段为“A002000000”和“A001000000”的相应数据,合并到“LR_1.csv”中。根据字段“Stkcd”,提取“Stk_ind.csv”中字段为“Indnme”和“Nindnme”的相应数据,合并到“LR_1.csv”中。将完成合并的数据另存为文件“LR_2.csv”(文件编码设置为 UTF-8),并在报告中呈现合并后数据的行数、列数。
import pandas as pd
#读取“LR_1.csv”、“ZCFZ.csv”、“Stk_ind.csv”三个数据文件
LR_1 = pd.read_csv('LR_1.csv')
ZCFZ = pd.read_csv('ZCFZ.csv')
stk_ind = pd.read_csv('Stk_ind.csv',encoding='gbk')
#根据“Stkcd”、“Accper”和“Typrep”三个字段,提取“ZCFZ.csv”中字段为“A002000000”和“A001000000”的相应数据,合并到“LR_1.csv”中。
data = ZCFZ[['Stkcd' ,'Accper', 'Typrep', 'A002000000', 'A001000000']]
data.head()
merge_data = pd.merge(LR_1,data,on = ['Stkcd' ,'Accper', 'Typrep'])
merge_data.head()
'''
根据字段“Stkcd”,提取“Stk_ind.csv”中字段为“Indnme”和“Nindnme”的相应数据,合并到“LR_1.csv”中
'''
data1 = stk_ind[['Stkcd', 'Indnme', 'Nindnme']]
data1.head()
merge_data1 = pd.merge(merge_data, data1, on = 'Stkcd')
merge_data1.head()
'''
将完成合并的数据另存为文件“LR_2.csv”(文件编码设置为 UTF-8),并在报告中呈现合并后数据的行数、列数
'''
merge_data1.to_csv('LR_2.csv', index = None, encoding = 'utf-8')
print(f'LR_2数据集的行数为{merge_data1.shape[0]},列数为{merge_data1.shape[1]}')任务 1.3 读取“LR_2.csv”,删除空值占比达 70%及以上的数据列,将处理后的数据另存为文件“LR_3.csv”(文件编码设置为 UTF-8),并在报告中呈现处理后数据的列数。
import pandas as pd
'''
读取“LR_2.csv”,删除空值占比达 70%及以上的数据列,将处理后的数据另存为文件“LR_3.csv”(文件编码设置为 UTF-8),并在报告中呈现处理后数据的列数。
'''
df = pd.read_csv('LR_2.csv')
df.head()
data = df[df.columns[df.isnull().sum()/df.isnull().count() < 0.7]]
data.head()
data.to_csv('LR_3.csv', index = None, encoding='utf-8')
print(f'LR_3数据集的行数为{data.shape[0]},列数为{data.shape[1]}')任务 1.4 读取“LR_3.csv”,删除包含空值的行,将处理后的数据另存为文件“LR_4.csv”(文件编码设置为 UTF-8),并在报告中呈现处理后数据的行数。
import pandas as pd
df = pd.read_csv('LR_3.csv')
df.head()
df = df.dropna(axis = 0)
df.head()
df.to_csv('LR_4.csv', index = None, encoding='utf-8')
print(f'LR_4数据集的行数为{df.shape[0]},列数为{df.shape[1]}')任务 1.5 读取“LR_4.csv”,将字段“Accper”的日期数据转换为“YYYY-mm-dd”的格式,例如:“2018-1-31”转换为“2018-01-31”,将处理后的数据另存为文件“LR_5.csv”(文件编码设置为 UTF-8)
import pandas as pd
df = pd.read_csv('LR_4.csv')
df.head()
df['Accper'] = pd.to_datetime(df['Accper'].astype('datetime64[s]'), format="%Y-%d-%m")
df.head()
df.to_csv('LR_5.csv', index = None, encoding='utf-8')任务 1.6 读取“LR_5.csv”,插入“利润率”和“资产负债率”两列。根据下表公式,计算对应的利润率和资产负债率,追加到“LR_5.csv”对应字段。分别删除表中利润率、资产负债率不在[-300%,300%]范围内的行,将处理后的数据另存为文件“LR_new.csv”(文件编码设置为 UTF-8),并在报告呈现处理后的数据行数、列数,及前 5 个企业的利润率、资产负债率
import pandas as pd
'''
读取“LR_5.csv”,插入“利润率”和“资产负债率”两列。根据下表公式,计算对应的利润率和资产负债率,追加到“LR_5.csv”对应字段。
'''
df = pd.read_csv('LR_5.csv')
df.head()
#利润总额(B001000000)/营业总收入(B001100000)
#负债合计(A002000000)/资产总计(A001000000)
df['profit_rate'] = df['B001000000']/df['B001100000']
df['asset_liability_ratio'] = df['A002000000']/df['A001000000']
df.head()
'''
分别删除表中利润率、资产负债率不在[-300%,300%]范围内的行,将处理后的数据另存为文件“LR_new.csv”(文件编码设置为 UTF-8),并在报告中呈现处理后的数据行数、列数,及前 5 个企业的利润率、资产负债率
'''
data = df.iloc[df.index[(df['profit_rate'] >= -3) & (df['profit_rate'] <= 3)],:]
data.reset_index(drop = True, inplace = True)
data = data.iloc[data.index[(data['asset_liability_ratio'] >= -3) & (data['asset_liability_ratio'] <= 3)],:]
data.reset_index(drop = True, inplace = True)
data.to_csv('LR_new.csv', index = None, encoding='utf-8')
print(f'LR_new数据集的行数为{data.shape[0]},列数为{data.shape[1]}')
data[['profit_rate','asset_liability_ratio']].head()任务 2.1 读取“LR_new.csv”,根据表 3 要求统计数据,绘制相关的“行业营业利润对比分析”图,每张图表需在报告中进行呈现及分析。
import pandas as pd
'''
读取“LR_new.csv”,根据表 3 要求统计数据,绘制相关的“行业营业利润对比分析”图,每张图表需在报告中进行呈现及分析。
'''
df = pd.read_csv('LR_new.csv')
df.head()
data = df.loc[df['Accper'].apply(lambda x : x.split('-')[0]+'-'+x.split('-')[1]) == '2019-09',:]
data.reset_index(drop = True, inplace = True)
data.head()
plt_data1 = data[['Nindnme','B001000000']].groupby('Nindnme').mean()
plt_data1.reset_index(inplace=True)
plt_data1.head()
from matplotlib import pyplot as plt
import matplotlib
import warnings
plt.rcParams['font.family'] = 'SimHei' # 设置默认字体为SimHei
warnings.filterwarnings('ignore')
plt.figure(facecolor='#fff', figsize=(20,12))
plt.bar(plt_data1['Nindnme'], plt_data1['B001000000'], color = ['red' if value < 0 else 'green' for value in plt_data1['B001000000']])
plt.xticks(plt_data1['Nindnme'].values.tolist()[::3], rotation = 330)
plt.title('2019 年 9 月各行业大类的利润对比 ',fontdict={'fontsize':18})
plt.show()
from datetime import datetime
# 假设数据存在一个csv文件中,使用pandas读取数据
df['Accper'] = pd.to_datetime(df['Accper'])
# 对行业大类和利润率进行统计,计算每季度的均值
plt_data2 = df.groupby([pd.Grouper(key='Accper', freq='Q'), 'Nindnme'])['profit_rate'].mean().reset_index()
plt_data2 = pd.pivot_table(plt_data2, columns = 'Nindnme', index = 'Accper', values = 'profit_rate')
plt_data2.head()
# 上述代码将按照行业大类和季度分组,并计算每个组的利润率均值。结果会包括行业大类、日期(以季度形式)以及利润率均值。
plt.figure(facecolor='#fff', figsize=(20,12))
plt.plot(
plt_data2.index.tolist(),
plt_data2.values.tolist()
)
plt.xticks(plt_data2.index.tolist())
plt.legend(plt_data2.columns.tolist(),loc=4, markerscale=0.1)
plt.title('2018 年 1 月至2019 年 9 月各行业大类利润率变化', fontdict={'fontsize':18})
plt.show()
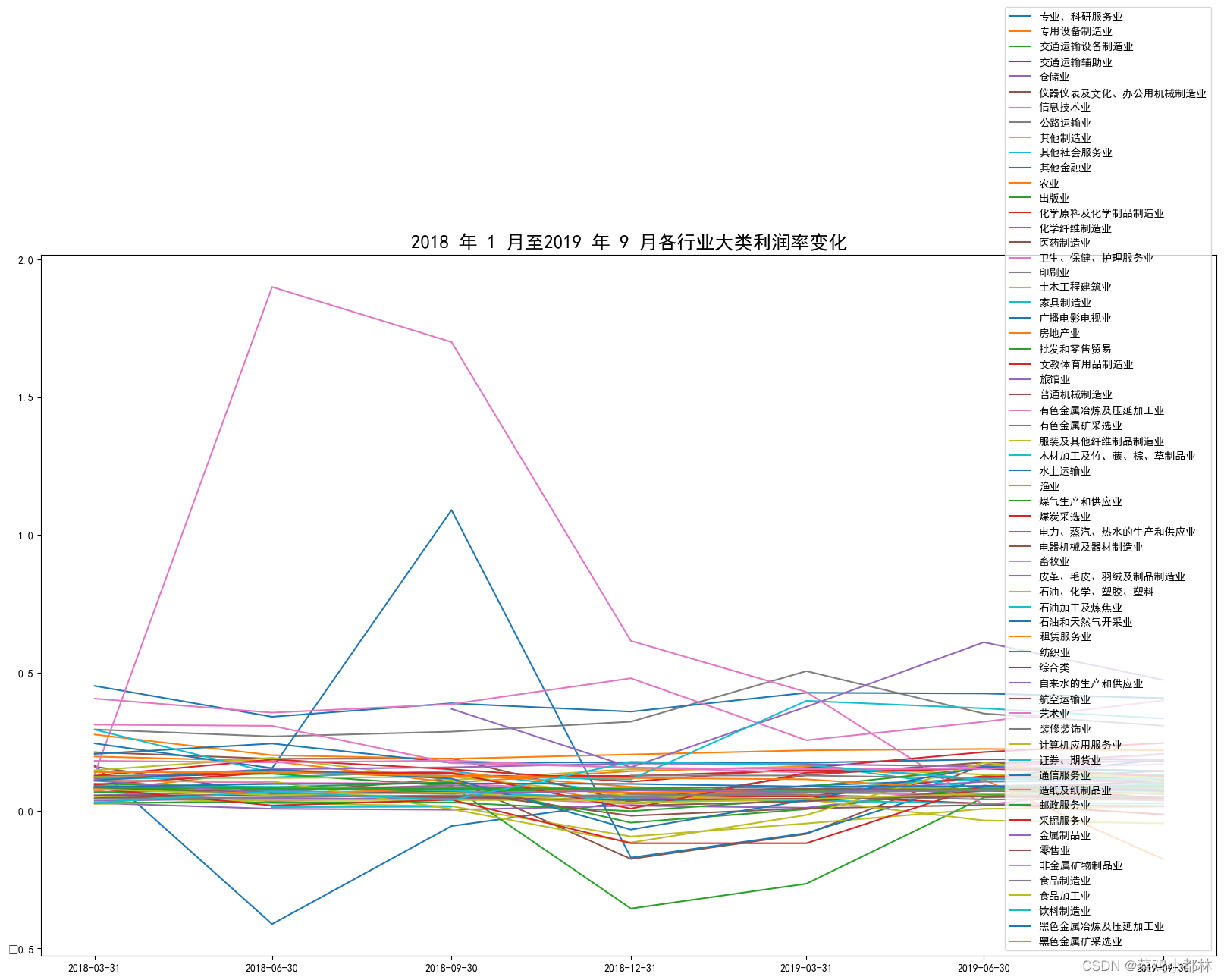
任务 2.2 读取“LR_new.csv”,根据任务 2.1 结果,确定 2019 年 9 月营业利润率均值排名第 1 的行业大类,并按表 4 要求绘制该行业大类相关的“行业企业营收分析”图,每张图表需在报告中进行呈现及分析。
import pandas as pd
df = pd.read_csv('LR_new.csv')
df.head()
df['年月'] = df['Accper'].apply(lambda x : x.split('-')[0] + '-' + x.split('-')[1])
data = df[df['年月'] == '2019-09'][['Stkcd','Indnme','Nindnme', 'profit_rate', 'B001201000', 'B001207000', 'B001209000', 'B001211000',
'B001100000', 'B001200000']]
data.reset_index(drop = True, inplace= True)
data.head()
# 第一大类的第一名
print(data.iloc[:,(data.columns != 'Nindnme')].groupby('Indnme').mean()['profit_rate'].sort_values(ascending = False).index[0])
result = data[data['Indnme'] == '金融'].sort_values('profit_rate',ascending=False).reset_index(drop = True)
result.head()
print(result[['Nindnme', 'profit_rate']].groupby('Nindnme').mean().reset_index())
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
c = (
Bar(init_opts=opts.InitOpts(bg_color='#fff'))
.add_xaxis(result[['Nindnme', 'profit_rate']].groupby('Nindnme').mean().reset_index()['Nindnme'].values.tolist())
.add_yaxis("利润率均值",
[round(i,3) for i in result[['Nindnme', 'profit_rate']].groupby('Nindnme').mean().reset_index()['profit_rate'].values.tolist()],
itemstyle_opts=opts.ItemStyleOpts(color="lightpink")
)
.set_series_opts(label_opts=opts.LabelOpts(position="top"))
.set_global_opts(
title_opts=opts.TitleOpts(title="2019年该行业各细类利润率对比"),
legend_opts = opts.LegendOpts(type_="scroll", pos_left="80%", orient='vertical', pos_top="4%")
)
)
c.render_notebook()
data[(data['Nindnme'] == '其他金融业') & (data['Indnme'] == '金融')]
c = (
Bar(init_opts=opts.InitOpts(bg_color='#fff'))
.add_xaxis(data[(data['Nindnme'] == '其他金融业') & (data['Indnme'] == '金融')]['Stkcd'].values.tolist())
.add_yaxis("利润率",
[round(i,3) for i in data[(data['Nindnme'] == '其他金融业') & (data['Indnme'] == '金融')]['profit_rate'].values.tolist()],
itemstyle_opts=opts.ItemStyleOpts(color="lightpink")
)
.set_series_opts(label_opts=opts.LabelOpts(position="top"))
.set_global_opts(title_opts=opts.TitleOpts(title="2019年该行业利润率排名第1细类的企业利润率对比"),
legend_opts = opts.LegendOpts(type_="scroll", pos_left="80%", orient='vertical', pos_top="4%"))
)
c.render_notebook()
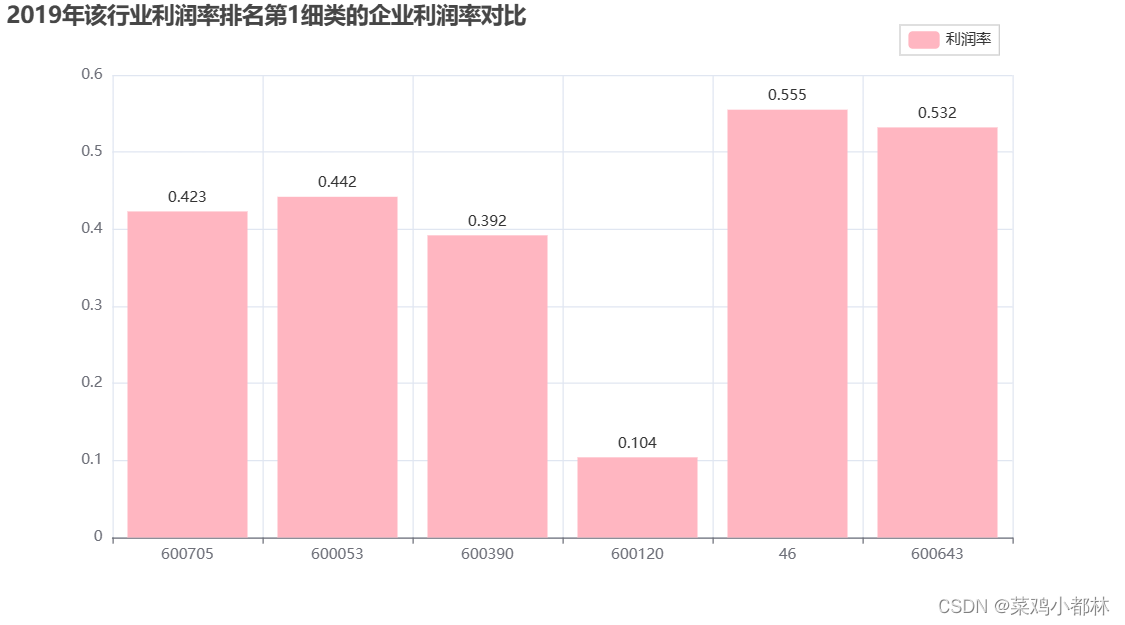
后面两张图看不懂“T1”企业是啥东西,不懂咋画!
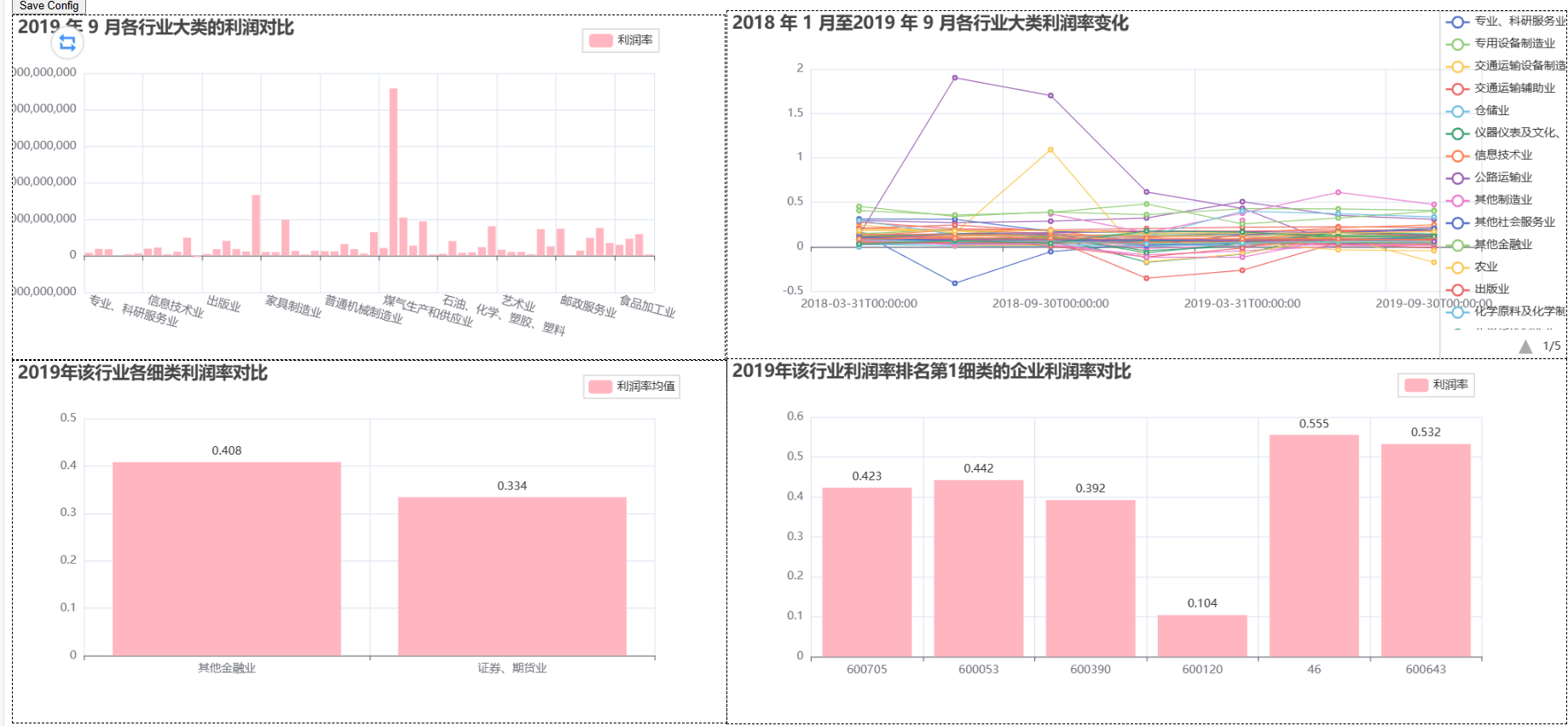
任务 2.3 利用可视化大屏制作工具,将任务 2.1 和任务 2.2 所列的 6 张图制作成一个大屏,大屏命名为“行业与企业营业数据分析”,并在报告中呈现。要求大屏整体设计美观、布局清晰直观。
from pyecharts import options as opts
from pyecharts.charts import Bar, Grid, Line, Liquid, Page, Pie
from pyecharts.commons.utils import JsCode
from pyecharts.components import Table
from pyecharts.faker import Faker
def bar_datazoom_slider() -> Bar:
c = (
Bar(init_opts=opts.InitOpts(bg_color='#fff'))
.add_xaxis(plt_data1['Nindnme'].values.tolist())
.add_yaxis("利润率",
plt_data1['B001000000'].values.tolist(),
itemstyle_opts=opts.ItemStyleOpts(color="lightpink")
)
.set_series_opts(label_opts=opts.LabelOpts(position="top"))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="2019 年 9 月各行业大类的利润对比"),
legend_opts = opts.LegendOpts(type_="scroll", pos_left="80%", orient='vertical', pos_top="4%"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15))
)
)
return c
def line_markpoint() -> Line:
from pyecharts.charts import Line
c = (
Line(init_opts=opts.InitOpts(bg_color='#fff'))
.add_xaxis(plt_data2.columns.tolist())
.add_yaxis("专业、科研服务业",plt_data2.values.tolist()[0])
.add_yaxis("专用设备制造业",plt_data2.values.tolist()[1])
.add_yaxis("交通运输设备制造业",plt_data2.values.tolist()[2])
.add_yaxis("交通运输辅助业",plt_data2.values.tolist()[3])
.add_yaxis("仓储业",plt_data2.values.tolist()[4])
.add_yaxis("仪器仪表及文化、办公用机械制造业",plt_data2.values.tolist()[5])
.add_yaxis("信息技术业",plt_data2.values.tolist()[6])
.add_yaxis("公路运输业",plt_data2.values.tolist()[7])
.add_yaxis("其他制造业",plt_data2.values.tolist()[8])
.add_yaxis("其他社会服务业",plt_data2.values.tolist()[9])
.add_yaxis("其他金融业",plt_data2.values.tolist()[10])
.add_yaxis("农业",plt_data2.values.tolist()[11])
.add_yaxis("出版业",plt_data2.values.tolist()[12])
.add_yaxis("化学原料及化学制品制造业",plt_data2.values.tolist()[13])
.add_yaxis("化学纤维制造业",plt_data2.values.tolist()[14])
.add_yaxis("医药制造业",plt_data2.values.tolist()[15])
.add_yaxis("卫生、保健、护理服务业",plt_data2.values.tolist()[16])
.add_yaxis("印刷业",plt_data2.values.tolist()[17])
.add_yaxis("土木工程建筑业",plt_data2.values.tolist()[18])
.add_yaxis("家具制造业",plt_data2.values.tolist()[19])
.add_yaxis("广播电影电视业",plt_data2.values.tolist()[20])
.add_yaxis("房地产业",plt_data2.values.tolist()[21])
.add_yaxis("批发和零售贸易",plt_data2.values.tolist()[22])
.add_yaxis("文教体育用品制造业",plt_data2.values.tolist()[23])
.add_yaxis("旅馆业",plt_data2.values.tolist()[24])
.add_yaxis("普通机械制造业",plt_data2.values.tolist()[25])
.add_yaxis("有色金属冶炼及压延加工业",plt_data2.values.tolist()[26])
.add_yaxis("有色金属矿采选业",plt_data2.values.tolist()[27])
.add_yaxis("服装及其他纤维制品制造业",plt_data2.values.tolist()[28])
.add_yaxis("木材加工及竹、藤、棕、草制品业",plt_data2.values.tolist()[29])
.add_yaxis("水上运输业",plt_data2.values.tolist()[30])
.add_yaxis("渔业",plt_data2.values.tolist()[31])
.add_yaxis("煤气生产和供应业",plt_data2.values.tolist()[32])
.add_yaxis("煤炭采选业",plt_data2.values.tolist()[33])
.add_yaxis("电力、蒸汽、热水的生产和供应业",plt_data2.values.tolist()[34])
.add_yaxis("电器机械及器材制造业",plt_data2.values.tolist()[35])
.add_yaxis("畜牧业",plt_data2.values.tolist()[36])
.add_yaxis("皮革、毛皮、羽绒及制品制造业",plt_data2.values.tolist()[37])
.add_yaxis("石油、化学、塑胶、塑料",plt_data2.values.tolist()[38])
.add_yaxis("石油加工及炼焦业",plt_data2.values.tolist()[39])
.add_yaxis("石油和天然气开采业",plt_data2.values.tolist()[40])
.add_yaxis("租赁服务业",plt_data2.values.tolist()[41])
.add_yaxis("纺织业",plt_data2.values.tolist()[42])
.add_yaxis("综合类",plt_data2.values.tolist()[43])
.add_yaxis("自来水的生产和供应业",plt_data2.values.tolist()[44])
.add_yaxis("航空运输业",plt_data2.values.tolist()[45])
.add_yaxis("艺术业",plt_data2.values.tolist()[46])
.add_yaxis("装修装饰业",plt_data2.values.tolist()[47])
.add_yaxis("计算机应用服务业",plt_data2.values.tolist()[48])
.add_yaxis("证券、期货业",plt_data2.values.tolist()[49])
.add_yaxis("通信服务业",plt_data2.values.tolist()[50])
.add_yaxis("造纸及纸制品业",plt_data2.values.tolist()[51])
.add_yaxis("邮政服务业",plt_data2.values.tolist()[52])
.add_yaxis("采掘服务业",plt_data2.values.tolist()[53])
.add_yaxis("金属制品业",plt_data2.values.tolist()[54])
.add_yaxis("零售业",plt_data2.values.tolist()[55])
.add_yaxis("非金属矿物制品业",plt_data2.values.tolist()[56])
.add_yaxis("食品制造业",plt_data2.values.tolist()[57])
.add_yaxis("食品加工业",plt_data2.values.tolist()[58])
.add_yaxis("饮料制造业",plt_data2.values.tolist()[59])
.add_yaxis("黑色金属冶炼及压延加工业",plt_data2.values.tolist()[60])
.add_yaxis("黑色金属矿采选业",plt_data2.values.tolist()[61])
.set_global_opts(title_opts=opts.TitleOpts(title="2018 年 1 月至2019 年 9 月各行业大类利润率变化"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="85%", orient="vertical"))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
return c
def pie_rosetype() -> Pie:
c = (
Bar(init_opts=opts.InitOpts(bg_color='#fff'))
.add_xaxis(result[['Nindnme', 'profit_rate']].groupby('Nindnme').mean().reset_index()['Nindnme'].values.tolist())
.add_yaxis("利润率均值",
[round(i,3) for i in result[['Nindnme', 'profit_rate']].groupby('Nindnme').mean().reset_index()['profit_rate'].values.tolist()],
itemstyle_opts=opts.ItemStyleOpts(color="lightpink")
)
.set_series_opts(label_opts=opts.LabelOpts(position="top"))
.set_global_opts(
title_opts=opts.TitleOpts(title="2019年该行业各细类利润率对比"),
legend_opts = opts.LegendOpts(type_="scroll", pos_left="80%", orient='vertical', pos_top="4%")
)
)
return c
def grid_mutil_yaxis() -> Grid:
c = (
Bar(init_opts=opts.InitOpts(bg_color='#fff'))
.add_xaxis(data[(data['Nindnme'] == '其他金融业') & (data['Indnme'] == '金融')]['Stkcd'].values.tolist())
.add_yaxis("利润率",
[round(i,3) for i in data[(data['Nindnme'] == '其他金融业') & (data['Indnme'] == '金融')]['profit_rate'].values.tolist()],
itemstyle_opts=opts.ItemStyleOpts(color="lightpink")
)
.set_series_opts(label_opts=opts.LabelOpts(position="top"))
.set_global_opts(title_opts=opts.TitleOpts(title="2019年该行业利润率排名第1细类的企业利润率对比"),
legend_opts = opts.LegendOpts(type_="scroll", pos_left="80%", orient='vertical', pos_top="4%"))
)
return c
def page_draggable_layout():
page = Page(layout=Page.DraggablePageLayout)
page.add(
bar_datazoom_slider(),
line_markpoint(),
pie_rosetype(),
grid_mutil_yaxis(),
)
page.render("page_draggable_layout.html")
if __name__ == "__main__":
page_draggable_layout()
任务 3.1 读取“financial_data.csv”,计算各个指标与利润总额的相关性,挑选相关度最高的 5 个指标。
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('financial_data.csv')
df.head()
pearson = df.iloc[:,2:-1].corr(method="pearson")
pearson
pearson['LRZE'].apply(lambda x : abs(x)).sort_values(ascending = False).head(6)这部分内容直接使用了皮尔逊相关系数计算,但一般使用前需要对数据进行是否是线性关系、数据是否为连续型数据、数据是否服从正态分布等相关检验的判断。如果不满足上述任意一种条件,则需要考虑使用斯皮尔曼相关系数、肯德尔相关系数或者其他独立性检验的方法。这里省略了这一部分的检验结果!!!
任务 3.2 利用挑选的 5 个指标建立企业利润预测模型,运用建立的模型预测“test.csv”表中给定企业的利润总额,并将预测结果以表格的形式在报告中呈现
import pandas as pd
df = pd.read_csv('financial_data.csv')
df.head()
data = df[['LRZE', 'YYSR', 'YWFY', 'YYCB', 'YYSJJFJ', 'ZCJZSS']]
y = data[['LRZE']]
x = data.iloc[:,1:]
data.head()
# 划分数据集
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(x.values,y.values,test_size=0.2,random_state=42)
# 建立初步模型
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score,mean_squared_error
rfg = RandomForestRegressor(random_state=42).fit(Xtrain,Ytrain)
y_pred = rfg.predict(Xtest)
print(r2_score(y_pred,Ytest))
print(mean_squared_error(y_pred,Ytest))
# 经过调优后确定的模型参数
rfg = RandomForestRegressor(
n_estimators=186,
max_depth=28,
min_samples_leaf=1,
min_samples_split=2,
random_state=42).fit(Xtrain,Ytrain)
y_pred = rfg.predict(Xtest)
print(r2_score(y_pred,Ytest))
print(mean_squared_error(y_pred,Ytest))
from matplotlib import pyplot as plt
import matplotlib
plt.figure(facecolor='#fff', figsize=(20,6))
x = list(range(len(y_pred)))
plt.plot(x, Ytest)
plt.plot(x, y_pred)
plt.legend(['实际值','预测值'])
plt.show()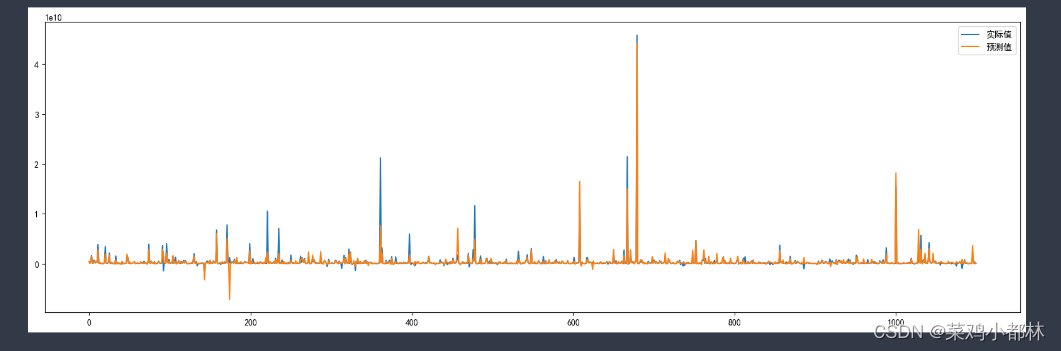 这里只给了随机森林回归模型的训练代码,由于数据集的质量比较不错,训练得到的预测结果比较好。如果训练结果一般,可以考虑其他的预测模型。
这里只给了随机森林回归模型的训练代码,由于数据集的质量比较不错,训练得到的预测结果比较好。如果训练结果一般,可以考虑其他的预测模型。
任务 3.3 “financial_data.csv”中包含一个“FLAG”字段用于标识财务数据造 假 ( “ 1 ” 表 示 财 务 造 假 ) 。 请 利 用 表 6 所 列 关 键 因 子 , 对 样 本 数 据“financial_data.csv”进行分析,挖掘财务造假的识别特征。根据你们的分析,对“financial_data_new.csv”所列 5 个企业的财务数据进行筛查,识别其中唯一的1 个涉嫌财务造假企业,并在报告中描述分析方法与结果。
import pandas as pd
df = pd.read_csv('financial_data.csv')
df.head()
data = df[['FLAG','LDBL','ZCFZL','CHZZL','ZCBCL','YSZKZZL']]
data.head()
from sklearn.model_selection import train_test_split
y = data['FLAG']
x = data.iloc[:,1:]
Xtrain, Xtest, Ytrain, Ytest = train_test_split(x.values,y.values,test_size=0.2,random_state=42)
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import r2_score,mean_squared_error
rfc = RandomForestClassifier(random_state=42).fit(Xtrain,Ytrain)
y_pred = rfc.predict(Xtest)
print(r2_score(y_pred,Ytest))
print(mean_squared_error(y_pred,Ytest))
df1 = pd.read_csv('financial_data_new.csv')
df1.head()
Input = df1[['LDBL','ZCFZL','CHZZL','ZCBCL','YSZKZZL']].values
print(rfc.predict(Input))按照给的数据集先进行模型训练,再预测新的数据集给出结果。可能数据集的质量太好了,默认参数的模型预测R方直接为1,说明全部预测成功。代入待预测数据集,得到代码为4897311是造假的。















 1597
1597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









