






环境:python - 3.12 funasr 1.2.2
官方文档:https://github.com/yeyupiaoling/FunASR/blob/main/README_zh.md
from funasr import AutoModel
# paraformer-zh is a multi-functional asr model
# use vad, punc, spk or not as you need
path = r"path-audio.wav"
model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
spk_model="cam++", spk_model_revision="v2.0.2",
)
res = model.generate(input= path,
batch_size_s=300,
hotword='微信')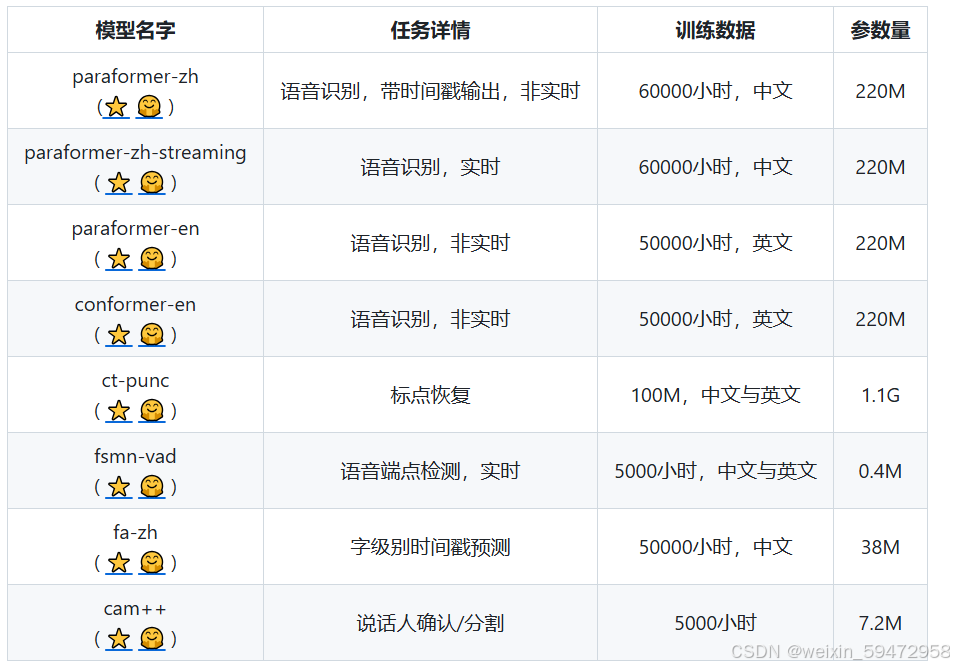
实现说话人分割的主要是cam++ 使用下来效果不错
模型出来的结果包含说话人以及说话片段 现在需要用embedding模型把语音解析成低维的向量数据
# 加载预训练模型
embed_model = Model.from_pretrained(r"D:\hugging-face-model\speaker-diarization-2.1\embedding\pytorch_model.bin")
# 创建推理对象,使用整个音频文件进行推理
inference = Inference(embed_model, window="whole")
# 提取音频文件的嵌入特征
audio_path = r"./标准声音模板.wav"
embeddings = inference(audio_path)我这里用的是2.1版本 生成的是一个512维向量数据

用这个数据就可以做特征比对
特征比对
欧式距离:通过计算两个人声音的特征向量之间的欧氏距离,你可以得出它们之间的相似性,距离越小表示声音越相似。
余弦相似度:余弦相似度是衡量两个向量在方向上的相似度,而不是它们的距离。它的值范围在 -1 到 1 之间,1 表示完全相似,-1 表示完全相反,0 表示无相似性
# 向量匹配
import math
import pymysql
import numpy as np
import ast
import re
from scipy import spatial
from sklearn.metrics.pairwise import cosine_similarity
def euclidean_distance(point1, point2):
distance = 0
# 检查两个点的维度是否相同
if len(point1) != len(point2):
# raise ValueError("Points must have the same number of dimensions")
#目标长度不够 需要重新新建对象存入数据
point1.extend([0] * (len(point2) - len(point1))) # 填充point1
# 计算每个维度的差的平方和
for i in range(len(point1)):
distance += math.pow(point1[i] - point2[i], 2)
# 计算平方和的平方根
distance = math.sqrt(distance)
return distance
def get_db_embedding_data():
db = pymysql.connect(host='127.0.0.1',
port=3306,
user='root',
passwd='123456',
database='test_audio',
charset='utf8')
cursor = db.cursor()
cursor.execute("SELECT user_feature from user_feature")
results = cursor.fetchall()
return results
if __name__ == '__main__':
# db获取向量数据
datas = get_db_embedding_data()
example_data = [-0.275, -0.216, 0.013, -0.178, -0.0435] # 你的第二个声音的特征向量
# v2 = [-1.44331515e-01 , 2.47361273e-01, -4.33351427e-01 ,-2.49071032e-01, -2.42790550e-01] # 你的第二个声音的特征向量
for row in datas:
# 使用正则表达式替换多个空格为逗号
str_data = re.sub(r'\s+', ', ', row[0].strip('[]'))
# 构造合法的列表字符串
str_data = f"[{str_data}]"
array = ast.literal_eval(str_data)
# 欧式距离
# distance = euclidean_distance(example_data, array)
# print(f" 欧式距离Euclidean Distance: {distance}")
#余弦相似度
# 如果余弦相似度接近 1,说明两个声音的特征非常相似。
# 如果余弦相似度接近 0,说明两个声音的特征不太相似。
# 如果余弦相似度接近 -1,说明两个声音的特征非常不同。
# similarity = 1 - spatial.distance.cosine(example_data, array)
example_data.extend([0] * (len(array) - len(example_data)))
similarity = cosine_similarity([example_data], [array])
print(f"余弦相似度Cosine Similarity: {similarity}")
最开始使用speaker-diarization做的语音识别 因为最开始调研发现这个模型发布比较早并且能实现embeddind(语音矢量化) 和 segementation(语音分割) 但是后续发现配置参数的时候找不到最佳效果 也是踩了很多坑 总结一下代码

















 5408
5408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









