







A Fairness-aware Incentive Scheme for Federated Learning一种公平意识FL激励方案
存在问题
没有提供任何激励机制来激励参与这种假设在实践中可能不成立。数据所有者对联盟的贡献用于构建机器学习模型,而机器学习模型又可用于产生收入。因此,联盟可以将部分收入分配给数据所有者作为奖励。
研究问题是如何量化每个数据所有者的收益,以实现长期的系统福利。 以及模型的培训和商业化需要时间。因此,在联合会有足够的预算偿还参与者之前,会有一些延迟。现有的收益分享计划没有考虑到捐款和奖励之间的暂时不匹配。
本文设计
提出了联合学习激励(FLI)收益共享方案。该方案通过联合最大化集体效用,同时最小化数据所有者之间在收益和收到全额收益的等待时间方面的不平等,动态地在联盟中的数据所有者之间分配给定的预算。
相关工作
三类利润分配博弈中的分配方案:
1. 平均主义: 数据联盟产生的收益在参与者中平均分配(不可用)
2. 边际收益: 按照某个参与者加入联盟时带来的边际收益确定他所应得的收益
线性分配:收益占比与其所贡献的数据质量和数量之乘成正比
工会:按实际加入联盟次序所带来的边际收益确定他所应得的报酬
SV:不受次序影响,边际收益
3. 边际损失:按照某个参与者退出联盟所能带来的边际损失确定他所应得的收益
FLI方案
贡献建模——边际贡献![]() ,没有关注过其产生机制,仅将其作为FLI输入
,没有关注过其产生机制,仅将其作为FLI输入
成本建模——![]() ,多种方法可计算,实用的解决方案是通过拍卖确定的对数据所有者的付款,假设此值可用
,多种方法可计算,实用的解决方案是通过拍卖确定的对数据所有者的付款,假设此值可用
遗憾建模——![]() , 成本代价没有及时得以全额补偿所带来的“遗憾”(regret)
, 成本代价没有及时得以全额补偿所带来的“遗憾”(regret)
![]() (含义为当产生一个成本时,遗憾 增 加,当得到一个收益时,遗憾减少)
(含义为当产生一个成本时,遗憾 增 加,当得到一个收益时,遗憾减少)
![]() ——报酬
——报酬
时间遗憾建模——![]() ,由于预算限制,成本可能太大,无法通过单笔回报支付完全覆盖。在这种情况下,联合会需要计算多轮支付给数据所有者的分期付款。用来计算如何对参与者等待全额补偿所耗的时间进行补偿。
,由于预算限制,成本可能太大,无法通过单笔回报支付完全覆盖。在这种情况下,联合会需要计算多轮支付给数据所有者的分期付款。用来计算如何对参与者等待全额补偿所耗的时间进行补偿。
![]()
其中, 指示函数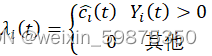
我的理解是遗憾相当于欠款,时间遗憾相当于利息(对还钱的等待时间进行补偿)
由![]() 得
得 ![]() ,该式通过推理可
,该式通过推理可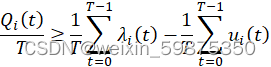
即一个给定的数据联盟可以保证参与者等候全额补偿的时间是有限的。
问题建模
(1)贡献公平:数据所有者i的报酬应与其贡献qi(t)呈正相关;
(2)遗憾分布公平性:数据所有者之间的遗憾和时间遗憾的差异应最小化;零遗憾,和/或有少数数据所有者有非常大的遗憾,两者应尽量减少。
(3)期望公平性:数据所有者的遗憾和时间遗憾值的波动应最小化。

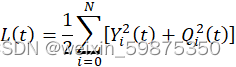
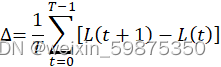


















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









