







目录
0 参考文献
Portal原论文:Adversarial domain translation networks for integrating large-scale atlas-level single-cell datasets
1 背景介绍
单细胞测序技术的发展使能了新类型细胞的发现、基因调控网络的研究和细胞分化过程的理解。随着近年来单细胞技术的迅速发展,实验通量大大增加,使研究人员能够分析越来越复杂和多样化的样品。对于这些来自不同样本、平台、模态甚至不同物种的数据集的共同分析使得研究人员可以获得细胞行为的更全面、丰富的认识。因此,开发能够准确有效地整合不同数据集的方法成为加速生命科学发展的重要一环。
整合多个单细胞数据集的任务存在一下几点困难:
1)由于技术的发展,现在数据集中包含的细胞数量都在不断增长,有的包含数百万个细胞,因此细胞整合方法必须具有可扩展性。
2)现在的技术允许部分只有很少成员的类型的细胞被发现并保留下来,因此一个好的整合方法应该能够准确地识别并保留出这种小规模细胞类型。
3)现在的数据集具有一系列层面上的的多样性,因此整合算法应该能够灵活地应对异质(可能意味着来自不同物种或者是具有不同模态)数据集。
为了能够应对上面三个挑战,这篇文章的作者们提出Portal。将不同的数据集当成不同的域,因为不同数据集之间会存在域特异的效应(比如由于不同检测技术造成的差异)。Portal将不同的域使用一种对抗性策略将不同的数据集映射到同一个隐空间中。
Portal与其他域变换的方法相比,优势在于:
1)Portal能够准确识别域共有的细胞类型和域独有的细胞类型,防止过校正。
2)在不使用细胞类型标记的情况下,Portal可以找到不同域之间的正确对应并保留生物学差异。
3)通过量身定制的轻量级神经网络设计和小批量优化,Portal可以在几分钟内扩展到数百万个细胞,并且内存使用几乎不变。
2 算法解析
2.1 模型概览
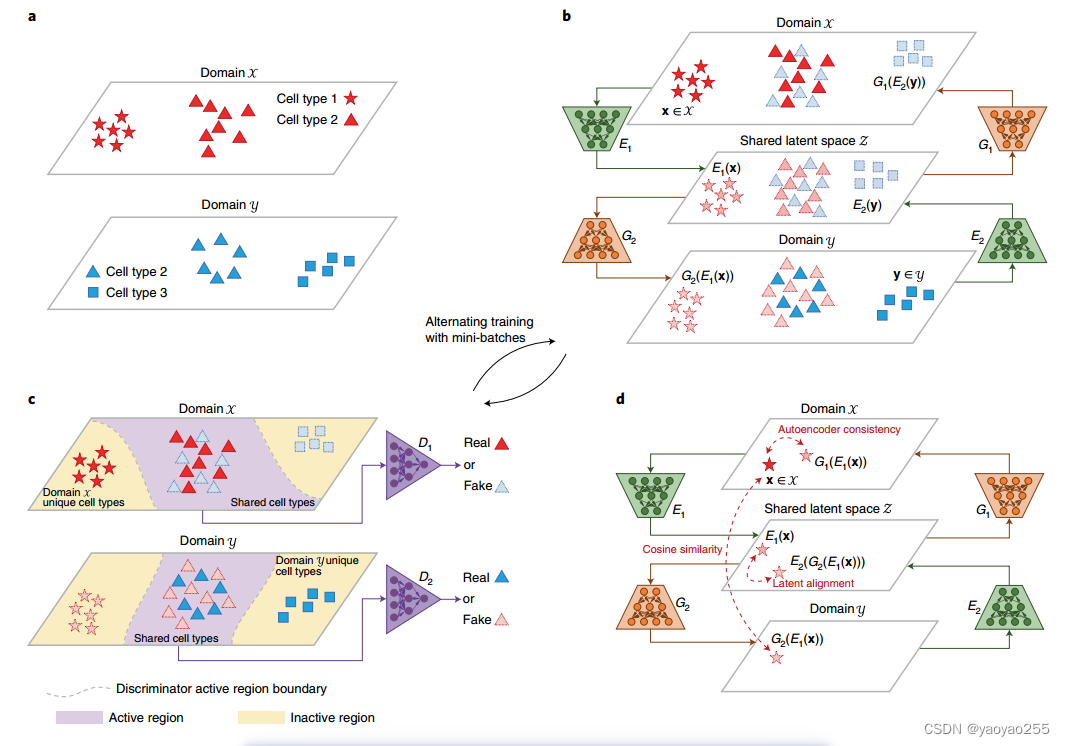
由于域特异效应(不同域之间存在差异的现象,可能由于检测技术不同等因素导致,此处为直译),不同的数据集会形成不同的域。如下图所示
Portal则用于将这些数据集整合,目标是在共同的低维隐空间中学习到来自不同数据集的细胞的低维表示,使得在这个低维隐空间中,相同类型的细胞聚拢,不同类型的细胞分离。
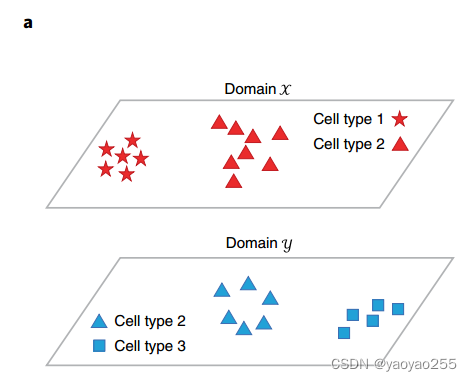
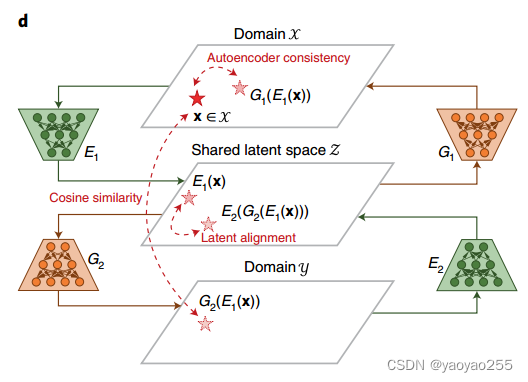
在Portal的整体结构中,编码器用于去除域特异效应,生成器用于模拟域特异效应的产生过程。一个编码器和一个生成器组合成为域变换网络,通过一个隐空间将两个不同域的细胞进行匹配。如下图所示。
对于这张图,x和y两个域分别代表两个数据集,红色的为域x中的细胞,蓝色的为域y中的细胞,这里使用浅色来代表这些细胞本来不属于这个数据集,而是从另一个数据集通过域变换网络映射到当前域的。
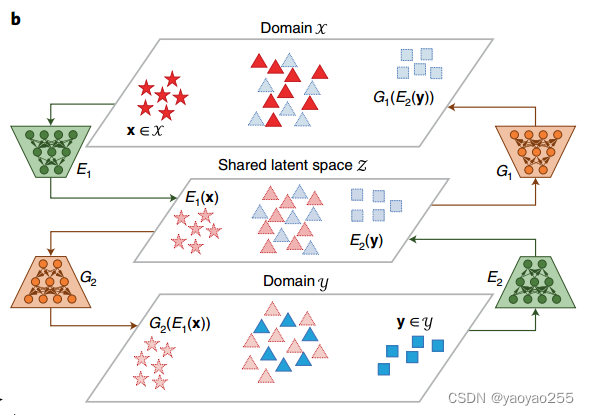
鉴别器用于发现哪些原始细胞(本来就属于该数据集的细胞)和转移细胞(从另一个数据集通过域变换网络变换后的细胞)混合地不理想的地方,并向域变换网络提供反馈信号。具体而言,Portal的鉴别器可以区分域独有细胞类型和域共有细胞类型,从而避免过度校正。如下图所示
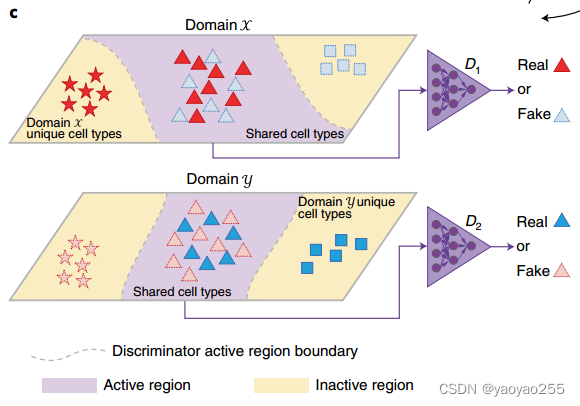
Portal使用三个正则化器来建立不同域之间的正确对齐。如下图所示,这将在后面详细介绍。
2.2 算法细节
将待整合的两个数据集看成是分别从两个域X和Y中产生的。在对于数据进行了标准的预处理之后,Portal在两个数据集的组合上使用PCA(主成分分析),选用前p个主成分,这样可以获得每个细胞的p维向量,作为每个细胞的低维表示,讲这样获得的低维表示成为细胞嵌入(cell embedding)。Portal使用这样的细胞嵌入作为模型输入。
Portal引入了一个q维的隐空间Z来连接域X和Y,这个域不受域特异效应的影响而只保留生物学差异。
令作为两个数据集的细胞嵌入(模型输入)。对于域X,Portal先使用一个编码器
,来获得域X中每一个细胞嵌入x在隐空间Z中的表示
,这个编码器用来去除域X的域特异效应。为了将细胞从域X变换到域Y,Portal使用一个生成器
来建模域Y的数据生成过程(模拟域Y的域特异效应)。
共同组成从域X到域Y的域变换网络
。
同理,编码器和生成器
共同组成从域Y到域X的域变换网络
。
Portal训练域变换网络来使得得到的转移细胞分布
与原本就属于域Y的细胞分布混合。鉴别器
用于发现在域Y中两个分布在哪里区别较大。域变换网络与鉴别器的“竞争”模式被称为对抗训练。
鉴别器会通过反馈信息来提升域变换网络
的效果,直到两个分布混合良好。
同理,对于另一个域变换网络,也存在一个鉴别器
。
需要注意的是,两个分布的完全重合并不一定是期望的,因为来自两个数据集的数据本身就会存在差异,例如域X独有的细胞类型并不应该被强制与域Y的细胞混合。并且,完全混合也可能存在域X的A和B类细胞分别与域Y的B和A类细胞匹配的情况。
为了应对这种问题,首先,Portal为单细胞数据的整合分析提供了量身定制的鉴别器,可以防止一个区域内的独特细胞类型与另一个区域内不同类型的细胞混合。第二,Portal使用三个正则化器来找到正确的对应关系,这在处理域特异效应和在隐空间Z中保留生物性差异中也起着关键作用。
使用如下方式训练域变换网络
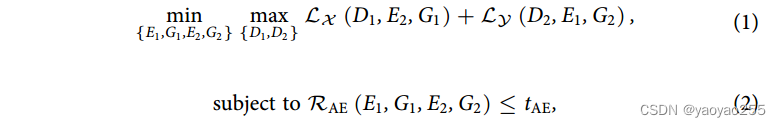
![]()
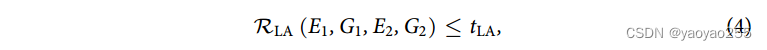
其中(1)是对抗训练的目标函数,(2)、(3)、(4)是三个正则化器,分别用来增强自编码器一致性、余弦相似度一致性和隐空间对齐一致性。
2.3 对抗性学习
鉴别器和域变换网络之间的对抗性训练被表示为最小-最大优化问题,,如上面的(1),其中
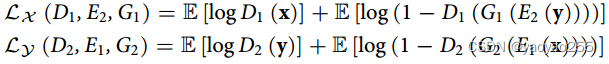
这两个函数分别为对于域X和域Y的对抗学习的目标函数。
给出域变换网络后,鉴别器
用于从域X中的原始细胞x中区分出原属于域Y的转移细胞
,较高的分数代表这个细胞被归为原始细胞,较低的分数则意味着这个细胞被归为另一个域的细胞。这通过优化
以最大化上面的第一个式子来实现。
对于第二个式子同理。
给出了两个鉴别器,域变换网络的训练则可以通过优化两个编码器和两个生成器从而最小化(1)来实现。这尽量使鉴别器难以区分原始细胞和转移细胞。这等价于下式
![]()
论文中提到,由于直接优化将面临梯度消失的问题,因此采用“logD-trick”来稳定训练过程。
令
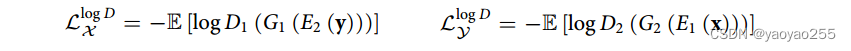
在实际训练时,最小化下面函数
![]()
虽然上述对抗性学习可以使转移细胞和原始细胞很好地混合,但它可能会错误地迫使一个域内独有类型的细胞与另一个域的细胞混合,导致过矫正。
假设有一种细胞类型只存在于域X中而不存在于域Y中。一方面,这意味着鉴别器可以轻松地将这个细胞类型的细胞鉴别为原始细胞,给这些细胞分配很高的分数;另一方面,从这个细胞类型通过域变换网络映射到域Y中的细胞鉴别器会给出很低的分数。
由此可见,域独有的类型会得到比较极端的分数(非常靠近0或1),这种极端的分数会导致过矫正。举个例子,当域独有的原始细胞被分配较高分数,那么该区域周围的细胞也倾向于获得更高的分数,导致一些通过域变换网络被映射到该区域附近的细胞被错误地归类。
为了应对这个问题,为鉴别器分数设置阈值,使得鉴别器在这种细胞上不会过分活跃。
具体而言,标准的鉴别器的输出通过sigmoid函数转换到(0,1)区间。而Portal通过一个区间来限制用于计算sigmoid的logit值。
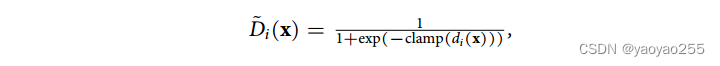
其中,即小于-t的变为-t,大于t的变为t。通过这种改变,Portal则倾向于值对于域共有细胞类型起作用。
2.4 三个正则化器
2.4.1 用于自编码器
编码器和生成器
(注意这里不是
)组成了一个自编码器,其中编码器去除域X的域特异效应,而生成器恢复这种效应。同理对于域Y也有这样的自编码器。
因此通过(2)来保证自编码器一致性
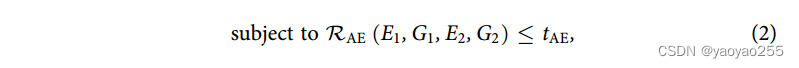
![]()
其中p是域X和Y的维度,即经过PCA后输入的维度。
2.4.2 用于余弦相似度
在不同域的整合中,(3)起到重要作用,主要用于加强来自不同域的细胞的对应。主要思想是认为一个细胞和它在新的域中的位置不应该有过大的区别。
![]()
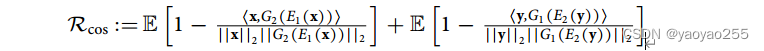
2.4.3 用于隐空间对齐
尽管对抗性学习能够有效地在不同域之间转移细胞,但是他不能去除域特异效应。因此使用(4)来让两个编码器获得去除域特异效应的能力。
![]()
其中q是隐空间Z的维度。
(4)的含义其实就是使得通过编码器映射到隐空间的细胞表示和通过编码器和生成器映射到另一个域的细胞再通过另一个编码器映射到隐空间的细胞表示更加接近。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









