







 StarGAN是一种生成对抗网络,通过同时使用图像和域信息,用一个生成器实现多域图像转换。它采用对抗、域分类和重建损失,以及WassersteinGAN的改进,允许跨多个数据集训练,提高了效率和效果。
StarGAN是一种生成对抗网络,通过同时使用图像和域信息,用一个生成器实现多域图像转换。它采用对抗、域分类和重建损失,以及WassersteinGAN的改进,允许跨多个数据集训练,提高了效率和效果。
0 参考文献
StarGAN原论文:StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
1 算法背景
生成对抗网络(GAN)的主要思想是通过训练两个网络,生成器和判别器,彼此博弈,以达到生成逼真数据的目的。这通常是作用于两个域(两个分布)。一些之前的工作基于此已经能够在两个图像域之间的image-to-image变换取得较好的效果。
图像到图像变换是将一类图像转换为另一类图像的任务,例如改变一个人的面部表情,或者改变一个人头发的颜色,如下图。

给出两个图像域的数据(例如微笑和皱眉),这些模型可以学习将一种图像转换为另一种图像。
然而这些方法都具有较差的扩展性和鲁棒性,因为在实现多个域之间的image-to-image变换时,需要对每一对域之间单独建立模型。例如存在k个图像域时,普通的方法需要训练k(k-1)个生成器,并且每个生成器只能利用到与之相关的两个域的数据,这导致了在涉及到多域变换时训练的效率和效果都有待提升。
为了能够解决这种困难,这篇文章提出了StarGAN,一种可以学习多域图像变换的生成对抗网络。StarGAN同时使用所有域的训练数据,仅使用一个生成器完成上述任务。
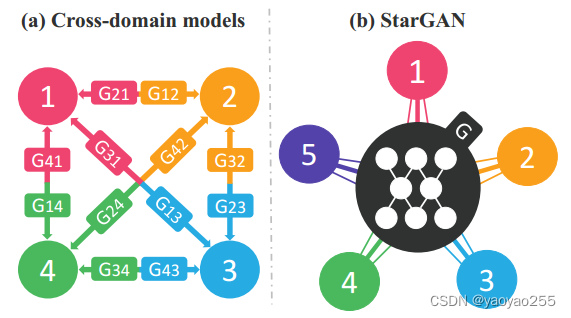
核心思想是,StarGAN同时使用图像和域信息(独热码标签)作为模型输入,从而灵活地学习到将输入图片转换到不同域的方式。
2 算法解析
2.1 多域图像到图像变换
StarGAN的目标是训练单一的生成器G以实现多域变换。StarGAN训练G将输入图像x在目标域标签c的指导下变换为输出图像y,即。其中在训练时,目标标签c是随机生成的。此外,StarGAN使用一个辅助分类器,使得单一的鉴别器可以处理多个域,即鉴别器D输出对于图像源和域标签的概率分布
。
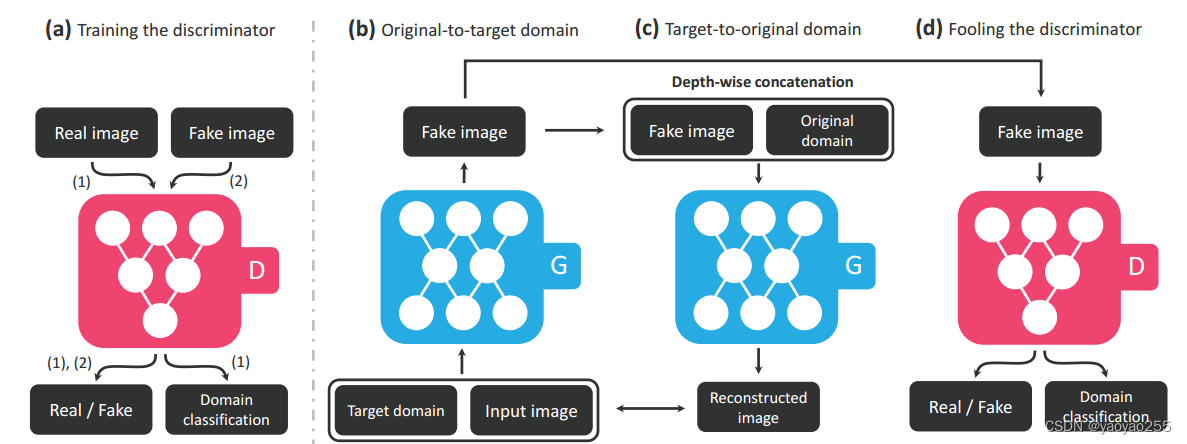
2.2 目标函数
2.2.1 对抗损失函数
为了使生成的图像难以与真实图像区分开,因此采用如下对抗损失函数
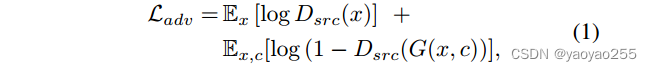
鉴别器尝试将真实图片与生成图片区分开,将看做是由鉴别器给出的图像源的概率分布(图像是真实图像的概率)。
生成器G试图减小这个损失函数的值,而鉴别器D试图增大它。
2.2.2 域分类损失函数
对于一个输入图像x和一个目标域标签c,产生一个输出图像y,图像y应该是倾向于归类为目标域c的。为了达到这种条件,StarGAN使用了一个辅助分类器,并添加域分类损失函数来优化鉴别器D和生成器G。
域分类损失函数包含两个部分,一个真实图像的域分类损失用于优化D,一个生成图像的域分类损失用于优化G。
前者如下定义
![]()
其中表示有鉴别器计算出来的对于x的类别标签概率分布,通过最小化上面这个目标函数,D学习将真是图像x分类为该图像的原始域c',原始图像和原始域标签对(x,c')是由训练数据给出的。
后者定义如下
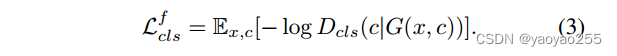
生成器G尽可能使生成的图像会被鉴别器归为目标域类别中。
2.2.3 重建损失函数
通过最小化上面两个函数,生成器被训练得尽可能生成类似真实图片的并且属于目标类别的图片。然而,这不能保证变换后的图像只改变输入中与域相关的部分,而保留其输入图像的其他内容(例如想要改变表情的时候应该保留与表情无关的内容,如头发的颜色等)。
为了应对这个问题,StarGAN才用了一个循环一致性损失,即重建损失。如下定义
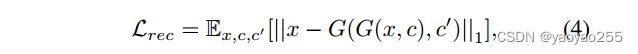
一个属于类别c'的输入图片x,通过生成器和目标域标签c,变换为一个新的图片。生成器再以这个生成图片和原始类别c'作为输入,生成一个属于类别c’的图片。上面的损失衡量了原始图片,与经过两次变换的重建图片之间的差距。
最小化上述损失函数以尽可能保证与域不相关的内容在变换的过程中被保留。
2.2.4 整体目标函数
有了上面几个损失函数,就可以构建整个StarGAN的目标函数如下
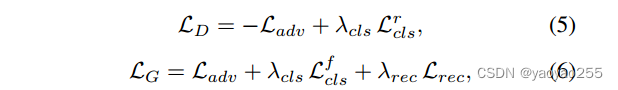
其中上下两个函数分别是鉴别器和生成器的损失函数,是超参数,在论文的实验中采用
。
2.3 多数据集训练
StarGAN另一个亮点在于它可以同时使用多个带有不同类别标签的数据集进行训练,从而使得在测试时,可以应对这些数据集所包含的所有标签。
然而,当从多个数据集学习时,一个问题是每个数据集的标签信息可能包含地并不全面。例如碎玉CelebA和RaFD数据集,前者只包含有关发色和性别的标签但是不包含任何有关面部表情的标签,而后者包含面部表情的标签。但是在重建输入图片时,完整的类别标签c'是很重要的。
为了应对这种问题,StarGAN引入掩码向量m,使其忽略未指明的标签,而只关心已经由特定数据集明确给出的标签信息。掩码向量m是一个n维独热向量,n是数据集的数量,m表示了该图像属于哪个数据集。
定义域标签和掩码向量的组合向量如下
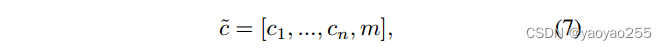
其中代表第i个数据集的域标签(独热向量)。对于其余n-1个未知标签(由于该图像不属于那n-1个数据集)都分配零值。
在训练时,生成器结构基本不变,只改变输入标签的维度,鉴别器则同时生成对于所有数据集的标签的概率分布。鉴别器只试图最小化与图像所属数据集相关的标签的分类损失。
2.4 实际实现
为了稳定训练过程,生成更高质量的图像,StarGAN将上面的对抗损失函数(1)替换为带有梯度惩罚(gradient penalty)的Wasserstein GAN目标函数如下
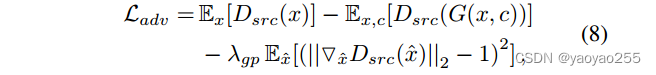
Gradient penalty(梯度惩罚)通常是在生成对抗网络(GANs)中用于提高训练稳定性和生成器质量的一种技术。
在原始的GANs中,生成器试图生成逼真的数据,而判别器则努力区分真实数据和生成数据。为了实现这个目标,通常使用了二元交叉熵损失函数。然而,训练GANs时可能会出现训练不稳定、模式崩溃(mode collapse)等问题。
Gradient penalty 是通过在训练过程中添加一个额外的梯度项,来对生成器和判别器之间的距离进行惩罚。具体而言,对于判别器的输出,梯度惩罚会惩罚过大的梯度,使得判别器不能太过激烈地对生成器的改进做出响应。
在Wasserstein GAN(WGAN)中,梯度惩罚的目标是将判别器的输出的梯度的范数固定在一个合理的范围内,从而防止梯度爆炸或梯度消失。
其中采样点是通过在真实图像和生成图像之间的直线上均匀采样得到的,并有
。

















 2064
2064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









