







github链接:3RScan
数据集结构
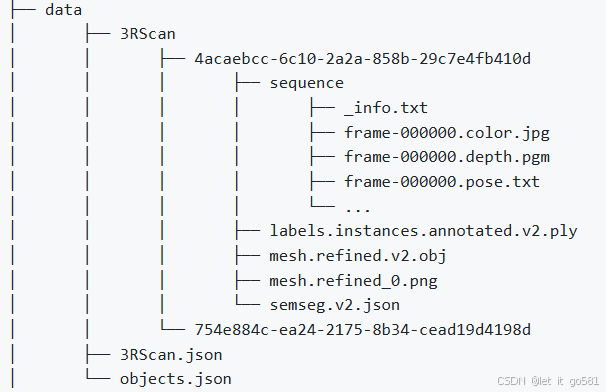
其中3RScan的详细结构
<scanId>/
├── mesh.refined.v2.obj # 重建的网格
├── mesh.refined.mtl # 对应的材质文件
├── mesh.refined_0.png # 对应的网格纹理
├── sequence.zip # 校准的RGB-D传感器数据流(包含彩色和深度帧、相机姿态)
├── labels.instances.annotated.v2.ply # 语义分割的可视化
├── mesh.refined.0.010000.segs.v2.json # 标注网格的过分割
└── semseg.v2.json # 网格的实例分割(包含标签)
3RScan.json
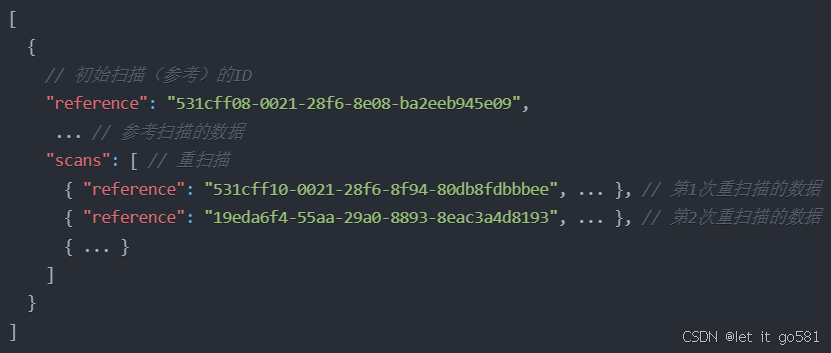
3RScan.json存储了扫描每个场景涉及到的Scanid,其中包括初始扫描的和n次重扫描的id,相当于一个目录
object.json
{
"scans": [
{
"scan": "00d42bed-778d-2ac6-86a7-0e0e5f5f5660", // 唯一的扫描标识符(可能是参考扫描或重扫描)
"objects": [
{
"global_id": "6", // 语义标签的全局Id(对每个语义类别如椅子、床等都是唯一的)
"label": "floor", // 物体的语义标签(与semseg.json中的"label"相同)
"ply_color": "#aec7e8", // 物体在labels.instances.annotated.ply中的颜色
"id": "1", // 物体的实例Id(与semseg.json中的"objectId"或"Id"相同)
"attributes": {
"color": [ "dark", "gray" ], ...
},
...
},
{
"global_id": "36",
"label": "bed",
"ply_color": "#ff7f0e",
"id": "4",
"attributes": {
"state": [ "messy" ],
"shape": [ "square" ]
}
}, ...
]
}, {
"objects": [ ... ],
"scan": "4acaebba-6c10-2a2a-8650-34c2f160db99"
}
]
}记录了所有场景中的object标签/颜色/id/属性,注意区分objectid和global_id, objectId是场景特定的(1在一个场景中可能是地板,但在另一个场景中可能是沙发)。这里在*.ply(见下文)中产生的全局实例ID(检查头文件)与objects.json中的global_id相同。
3RScan
semseg.v2.json

存储了本次扫描中每个object的语义类别 ,json["segGroups"]是该特定场景中实例的列表,其中objectId或Id是3D场景中特定物体实例的实例ID,label是分配的语义标签。物体的3D几何形状存储在labels.instances.annotated.v2.ply中,它与object.json属于分总的逻辑关系。
labels.instances.annotated.v2.ply
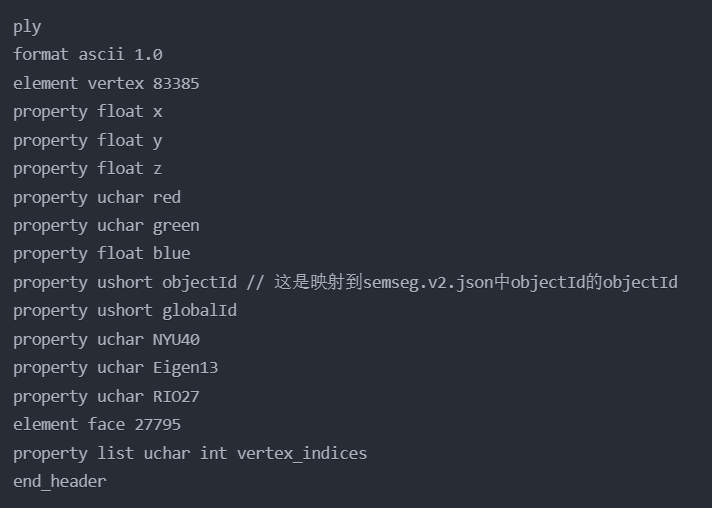
图片是ply文件的头部格式声明,ply文件存储了某个场景下的所有带有语义标签的3D点云,
ply- 声明这是一个PLY格式文件format ascii 1.0- 指定文件格式为ASCII编码,版本1.0element vertex 83385- 声明有83,385个顶点property float x- 每个顶点的x坐标,浮点数类型property float y- 每个顶点的y坐标,浮点数类型property float z- 每个顶点的z坐标,浮点数类型property uchar red- 顶点的红色分量,无符号字符类型(0-255)property uchar green- 顶点的绿色分量,无符号字符类型(0-255)property float blue- 顶点的蓝色分量,浮点数类型property ushort objectId- 物体ID,无符号短整型,映射到semseg.v2.json中的objectIdproperty ushort globalId- 全局ID,无符号短整型property uchar NYU40- NYU40数据集的标签映射property uchar Eigen13- Eigen13数据集的标签映射property uchar RIO27- RIO27数据集的标签映射element face 27795- 声明有27,795个面property list uchar int vertex_indices- 面的顶点索引列表end_header- 头部声明结束
可以获取到的信息:
场景的3D结构:
- 通过83,385个顶点的xyz坐标来描述场景的3D几何形状
- 使用27,795个面(face)来构建3D网格模型
语义标注信息:
- objectId:场景内每个物体实例的唯一标识符,与semseg.v2.json中的物体实例对应
- globalId:全局唯一的物体类别标识符,与objects.json中的global_id对应
- RGB颜色:每个顶点的颜色信息,可用于可视化
标签映射:
- NYU40:与NYU数据集的40类标签映射
- Eigen13:与Eigen数据集的13类标签映射
- RIO27:与RIO数据集的27类标签映射
注意:每个object是由多个3D顶点构成,
- 举个例子: 假设一个椅子的objectId是15,那么:
Copy
- 顶点A:{x, y, z, r, g, b, objectId=15, ...}
- 顶点B:{x, y, z, r, g, b, objectId=15, ...}
- 顶点C:{x, y, z, r, g, b, objectId=15, ...}
...等多个顶点这些标记为objectId=15的顶点共同构成了这把椅子的3D形状。
- 数据组织:
- 在semseg.v2.json中定义了每个objectId对应的语义标签(如"chair")
- 在PLY文件中,所有具有相同objectId的顶点属于同一个物体实例
- 通过face信息将这些顶点连接成三角面片,形成完整的3D网格模型
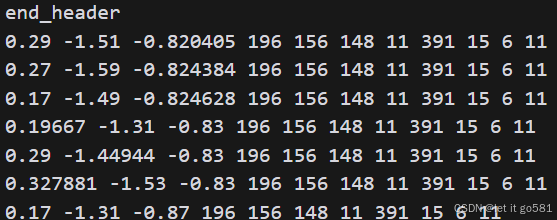
每行代表一个顶点,按头部定义的顺序排列,例如第一行
- x=1.35, y=-0.565348, z=-1.03 (3D坐标)
- red=140, green=86, blue=75 (RGB颜色)
- objectId=12 (物体实例编号)
- globalId=503 (全局类别编号)
- NYU40=1 (NYU40数据集映射标签)
- Eigen13=12 (Eigen13数据集映射标签)
- RIO27=1 (RIO27数据集映射标签)
mesh.refined.v2.obj
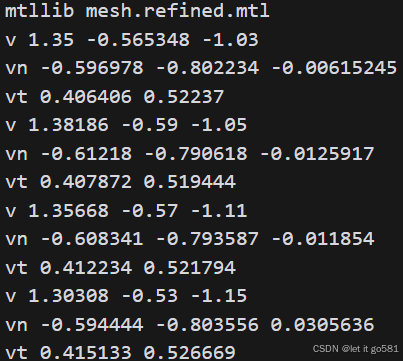
其中mtllib mesh.refined.mtl(下文会介绍),指定了材质库文件的位置,这个文件定义了3D模型的材质属性
v 1.35 -0.565348 -1.03v表示这是一个顶点- 后面三个数字是这个顶点在3D空间中的(x,y,z)坐标
- 比如这个顶点在x=1.35, y=-0.565348, z=-1.03的位置
vn -0.596978 -0.802234 -0.00615245vn表示这是一个顶点法线向量- 法线是垂直于表面的方向向量
- 用于计算光照效果,使模型表面看起来更真实
vt 0.406406 0.52237vt表示这是一个纹理坐标- 两个数字是(u,v)坐标,用于定义如何将纹理图像映射到3D模型表面
- u和v的范围通常在0到1之间
sequence.zip
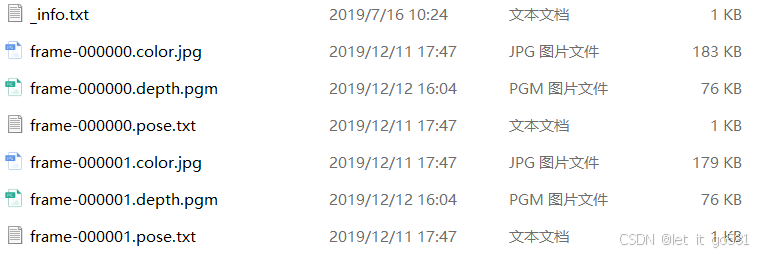
其中_info.txt:

equence.zip包含了校准的RGB-D传感器数据流。解压后的文件表示了每一帧的数据:
按帧组织
frame-000000是第0帧frame-000001是第1帧- 每一帧包含三个文件
每帧文件构成
.color.jpg:彩色图像文件- 例如:
frame-000000.color.jpg(183KB) 是第0帧的RGB图像 frame-000001.color.jpg(179KB) 是第1帧的RGB图像
- 例如:
.depth.pgm:深度图像文件- 例如:
frame-000000.depth.pgm(76KB) 是第0帧的深度图 frame-000001.depth.pgm(76KB) 是第1帧的深度图- 根据前面的说明,深度值以毫米为单位存储为16位图像
- 例如:
.pose.txt:相机姿态文件- 例如:
frame-000000.pose.txt(1KB) 是第0帧的相机姿态 frame-000001.pose.txt(1KB) 是第1帧的相机姿态- 存储了RGB相机到世界坐标系的变换矩阵
- 例如:
_info.txt
- 包含相机标定参数
- 存储了RGB和深度相机的内参矩阵K
这些文件共同构成了一个完整的RGB-D序列
mesh.refined.mtl 和 mesh.refined_0.png
- MTL文件定义了材质属性
- PNG文件是纹理图片,用于给3D模型添加真实的外观
mesh.refined.0.010000.segs.v2.json
- 网格的过分割结果
- 将网格分成更小的片段,便于标注和处理
各个文件之间的关联
3RScan.json-3RScan文件夹
3RScan.json存储了扫描每个场景涉及到的Scanid,3RScan文件夹则记录了每次扫描的各种信息,比如点云位置,语义标签等
semseg.v2.json-object.json
semseg.v2.json记录了每次扫描对应的场景中涉及到的object类别/颜色等信息,而object.json记录了所有场景中的object类别/颜色/属性等信息,属于分总关系
mesh.refined.v2.obj-semseg.v2.json-labels.instances.annotated.v2.ply
点构成物体,物体构成场景,场景由mesh表示,mesh由顶点(vertices)和面(faces)组成
- 几何信息:
mesh.refined.v2.obj存储整个场景的完整几何信息 - 语义分割:
labels.instances.annotated.v2.ply定义了每个顶点属于哪个物体实例 - 实例信息:
semseg.v2.json描述了每个物体实例的信息(标签、边界框等)
他们共同组成一个场景
数据集下载
关于如何下载,官方写的比较复杂,如果只是下载数据集而不进行其他操作可以看我下面写的内容,如果有更多需求直接参考官方文档比较详细
先填写表格获取download.py文件,使用指令python download1.py -o xxx --type sequence.zip(可以换成你需要的type),不加--type默认下载所有的文件,即可获得3RScan内的所有的文件(使用魔法上网且打开虚拟网卡会时不时卡断)
关于Object.json和3RScan文件可直接使用linux指令 wget https://www.campar.in.tum.de/public_datasets/3RScan/3RScan.json
以及wget https://www.campar.in.tum.de/public_datasets/3RScan/Object.json
渲染文件:从服务器下载渲染文件wget https://www.campar.in.tum.de/public_datasets/2023_cvpr_wusc/rendered.zip
生成对齐的实例ply文件:在三维数据处理中,“对齐” 指的是将不同视角、不同时间采集的 三维实例(如物体点云、场景点云)通过坐标变换统一到 同一个全局坐标系 中的过程。这是多视角融合和场景理解的关键步骤。标注文件(labels.instances.annotated.v2.ply)基于全局坐标系,对齐确保实例点云与标注信息在空间上一一对应。
这里推荐参考3DSSG,cd到scripts后,使用指令py_transform_ply -c config_file --thread thread_number即可
注意:https://www.campar.in.tum.de/public_datasets是禁止访问的
建议:数据集较大,可以修改下代码,使用tqdm显示下载进度,不然你不知道到底有没有在下载
数据集应用
3D SGG(注:我的研究方向是3DSGG,除了以上数据外,还需要3DSGG的关于object-relation-object等的注释文件,可参考VL-SAT/Open3DSG)
3D semantic segmentation
SLAM
so on

















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









