







1.在上篇Transformer解读中可以知道输入部分是一句话,而在VIT中,需要输入的是图片,那该怎么办呢?
输入一句话,每个字都可以转化为数字,相当于就是输入图片中图像的像素点(也是数字)
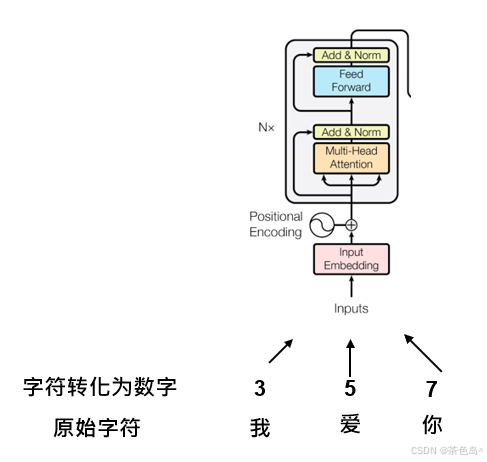
2.如何把图片融入到TRM中去?
看下图,可以将图片中像素化成一列,一起输入
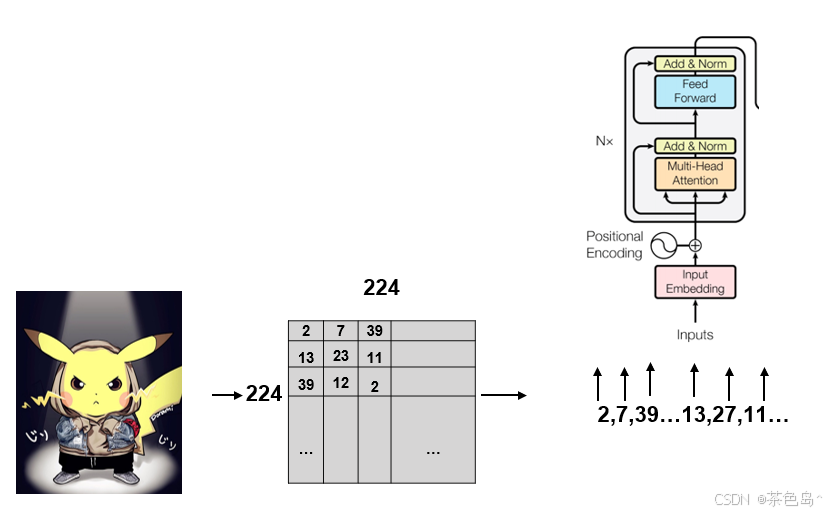
3.将图片中像素点(也是数字)合成一列输入,长度太长,超出BERT最大长度,如何解决?
BERT的最大长度是512,相当于100倍
1.局部注意力机制
有很多中方法:
2.改进attention公式
一个简单的改进方式:图像化整为零,切分patch
也就说原来是一个像素点代表一个token, 现在是一大块的token一个patch作为一个token
4.解读VIT模型
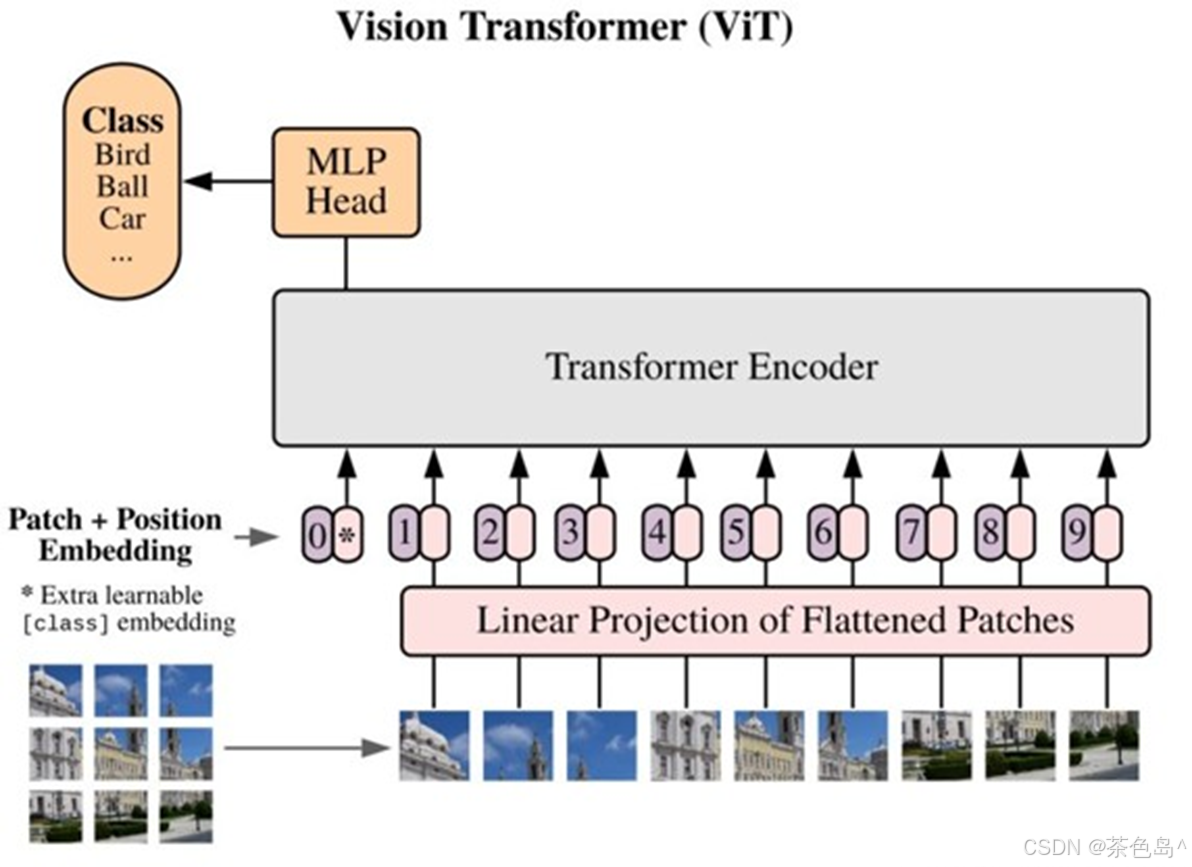
1. 图片切分为patch
2. patch转化为embedding
3.位置embedding和tokens embedding相加
3.1 生成CLS符号的token embedding
3.2 生成所有序列的位置编码
3.3 tokens+位置编码
4.输入到TRM模型
5.CLS 输出做多分类任务

在整合最后输出信息的时候,有多种方式,两种方式,一种是使用【CLS】token,另一种就是对所有tokens的输出做一个平均
如果采用一个平均,会涉及到所有tonkens的输出;而MLM任务又会涉及到其中的部分mask的tokens的输出;CSL符号一定程度在让两个任务保持一种相对的独立;但是VIT不涉及到MLM这种形式的任务,只会有一个多分类任务,所以CLS符号不是必须的
下面是主要的VIT模型的步骤
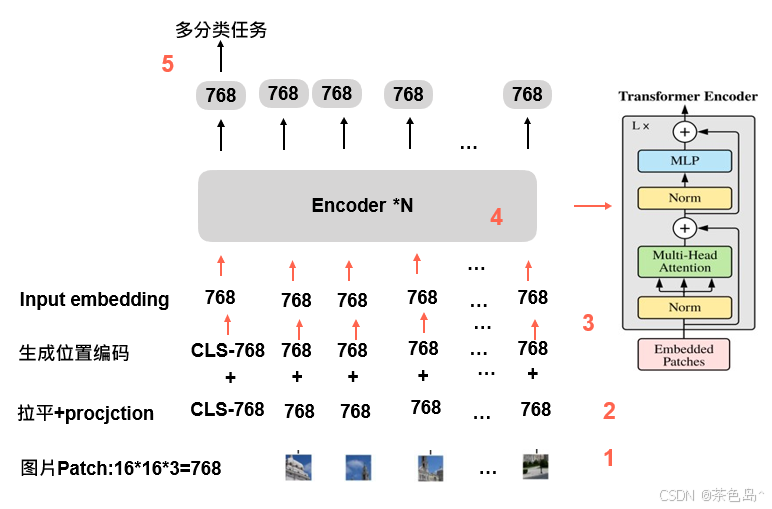
Vision Transformer(ViT)是一种创新的图像分类模型,它借鉴了Transformer在自然语言处理中的成功经验。不同于传统的卷积神经网络(CNN),ViT将输入图像划分为一系列固定大小的图像块(patches),并将这些图像块展平成向量。通过线性变换和位置编码,图像块被转化为具有位置信息的嵌入向量。随后,这些嵌入向量被输入到多层Transformer编码器中进行处理。在整个过程中,ViT利用自注意力机制有效地捕捉图像中的全局特征,生成一个全局表示。模型最终通过一个全连接层将全局表示用于图像分类任务。ViT的独特设计使其在大规模图像数据上表现出色,展示了Transformer在计算机视觉领域的巨大潜力。无论是学术研究还是工业应用,ViT都为图像处理开辟了新的方向。
一、对BERT采用[CLS]符号的更详细解释
1.
CLS符号在BERT中的作用统一的全局表示:
CLS(Classification)符号是一个特定的标记符号,通常在输入序列的最前面添加。- 在BERT模型中,
CLS符号的初始嵌入向量经过多层Transformer的编码后,最终会生成一个表示整个序列的全局特征向量。- 这个特征向量可以直接用于后续的分类任务,例如句子分类或下一句预测(Next Sentence Prediction, NSP)。
任务独立性:
- 正如你所提到的,
CLS符号的引入使得不同任务之间相对独立。- 在MLM(Masked Language Modeling)任务中,只需要关注被遮蔽的token及其上下文,但
CLS符号不会被遮蔽,它的表示不会直接受到mask的影响。- 在NSP任务中,
CLS符号表示整个句子的特征,这种特征可以直接用于判断两句子是否连续。2. 为什么不用平均或其他聚合方法
平均池化的局限:
- 平均池化(average pooling)会将输入序列的所有token的表示取平均,这样做虽然简单,但会混淆各个token的具体信息,失去一些细粒度的信息。
- 另外,平均池化无法专门为分类任务生成一个全局的特征向量,这在一些特定任务上可能不如一个专门的
CLS符号的表示效果好。任务复杂性:
- 采用
CLS符号可以让模型更灵活地处理复杂的任务,例如多任务学习(Multi-task Learning)中的不同任务可以利用同一个CLS符号的表示,而不需要专门设计不同的聚合方法。3. ViT中的情况
单一任务:
- Vision Transformer(ViT)主要用于图像分类任务,这类任务通常只需要一个全局的图像表示。
- ViT中,
CLS符号同样被用来表示整个图像的全局信息,并将其用于分类任务。可选情况:
- 虽然
CLS符号在ViT中也起到类似的作用,但对于某些特定的视觉任务和模型设计,CLS符号并不是必须的。设计者可以选择采用其他聚合方法,如全局平均池化或最大池化来生成图像的全局特征表示。4. 总结
BERT引入
CLS符号的主要目的是为了提供一个统一的全局特征表示,便于处理多种任务,并保持任务间的独立性。对于ViT,尽管它也采用了CLS符号来生成全局图像表示,但由于其任务单一(主要用于图像分类),在某些情况下,CLS符号并不是必须的,可以用其他聚合方法替代。总体来说,CLS符号的引入为BERT和ViT模型提供了灵活性和统一性,有助于提升模型的表现和适应性。
二、为什么加入一个CLS符号
在Vision Transformer(ViT)模型中,加入一个特殊的[CLS](Classification)符号是为了实现图像分类任务。这里是详细的解释:
1. [CLS] Token 的引入
在ViT模型中,输入图像被划分为多个小块(patches),然后这些patches被转换为固定维度的向量表示(token embeddings)。除了这些patch token外,还引入了一个特殊的[CLS] token,它的位置通常放在序列的最前面。
2. [CLS] Token 的作用
2.1 聚合信息
- 全局表示:当Transformer处理这些token时,[CLS] token会在每一层的自注意力机制中与其他token交互。通过这样的交互,[CLS] token会逐渐聚合所有其他token的信息,形成一个全局的图像表示。
- 信息汇总:因为[CLS] token在每一层中都能与所有其他token交互,并通过自注意力机制“看到”整个图像的所有部分,最终在Transformer的输出层中,[CLS] token包含了整个图像的综合信息。
2.2 分类任务
- 分类头(Classification Head):在模型的最后一层,通常会对[CLS] token的输出应用一个全连接层(或称为分类头),将其映射到目标类别的数量。这就完成了图像的分类任务。
- 输出表示:该全连接层的输出即为模型对图像的分类预测结果。
3. 类比于BERT中的[CLS] Token
ViT模型中的[CLS] token的设计借鉴了Transformer在自然语言处理(NLP)中的应用,比如BERT模型中的[CLS] token。在BERT中,[CLS] token用于句子的整体表示和下游任务(如分类、回归等)。在ViT中,[CLS] token用于图像的整体表示,特别是图像分类任务。
4. 具体过程
以下是[CLS] token在ViT模型中的具体处理流程:
- 图像切分:将输入图像划分为大小相同的patches。
- token嵌入:将每个patch展平并通过线性变换映射为一个固定维度的向量(token embedding)。
- 加入[CLS] token:在token序列的最前面加入一个[CLS] token。
- 位置编码:为每个token(包括[CLS] token)添加位置编码,以保留位置信息。
- Transformer处理:将这些token序列输入到Transformer模型中,通过多层自注意力和前馈神经网络进行处理。
- 分类输出:在模型的输出层,取出[CLS] token的表示,传递到一个全连接层,用于图像分类任务。
5. 总结
引入[CLS] token在ViT模型中是为了提供一个统一的位置来聚合和表示整个图像的信息,从而实现高效的图像分类。这种设计有效地将Transformer中的自然语言处理策略应用于计算机视觉任务。
三、为什么[CLS] token能够在每一层中与所有其他token交互?
在Vision Transformer(ViT)中,[CLS] token能够在每一层中与所有其他token交互,主要是因为自注意力机制的特点。以下是详细原因:
1.自注意力机制
全局交互:
- 自注意力机制允许每个token在处理时考虑输入序列中所有其他token的信息。这意味着在每一层中,[CLS] token可以接触到所有其他patch token的信息。
权重计算:
- 自注意力计算每个token与其他token之间的相关性(即注意力权重),这些权重用于加权汇总其他token的信息。因此,[CLS] token可以通过这些加权和的方式“看到”整个图像的各个patch。
2.逐层聚合
层层累积:
- 由于[CLS] token在每一层都能与所有token交互,通过多层的自注意力处理,[CLS] token会逐步累积和整合整个图像的信息。
综合表示:
- 多层次的信息聚合使得最后一层的[CLS] token能够形成一个综合的全局表示,捕获图像的整体特征。
3.设计目的
任务需求:
- 这种结构设计的目的在于利用[CLS] token作为图像全局信息的容器,最后用于分类任务。
参考NLP:
- 类似于自然语言处理中的BERT模型,[CLS] token用于整体语义的表示,这一设计在图像领域的ViT中同样适用。
4.具体流程
- 输入处理:加入[CLS] token,并将图像分块为patches。
- 层内交互:每一层中,[CLS] token通过自注意力与所有patch token交互。
- 全局整合:经过多层处理后,[CLS] token累积了全局信息。
- 输出分类:最终通过分类头进行映射,实现图像的分类。
5.总结
通过自注意力机制,[CLS] token在每一层中可以与所有其他token交互,随着层数增加,不断汇总和整合全局信息,从而形成完整的图像表示,达到有效分类的目的。
四、为什么自注意力机制允许每个token在处理时考虑输入序列中所有其他token的信息?
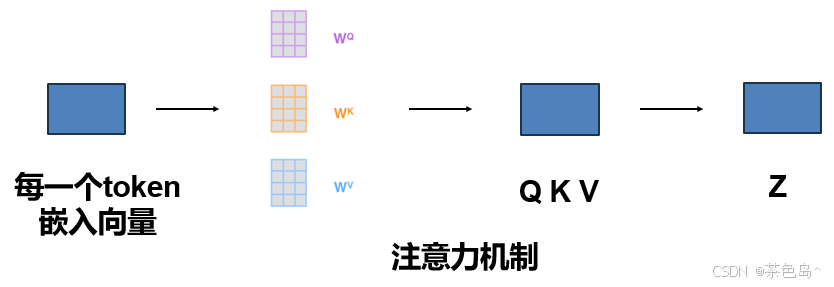
1. 自注意力机制的工作原理
自注意力机制的核心思想是计算输入序列中每个token与其他所有token之间的相关性(即注意力权重),并利用这些权重来加权求和其他token的信息。具体步骤如下:
1.1 计算Query, Key, Value向量
- Query (Q), Key (K), Value (V) 向量:每个token的嵌入向量通过同一项三个不同的线性变换分别映射到Query向量、Key向量和Value向量。这三个向量是用于计算注意力权重和加权求和的。
1.2 计算注意力权重
- 点积注意力:对于输入序列中的每个token,其Query向量与所有其他token的Key向量进行点积运算,得到注意力得分。
- 归一化:将注意力得分通过Softmax函数归一化,得到注意力权重,这些权重表示每个token对当前token的重要性。
1.3 加权求和
- 加权求和:每个token的最终表示通过加权求和所有token的Value向量,权重就是前一步计算的注意力权重。
2. 为什么自注意力机制允许全局信息交互
2.1 全局依赖关系
- 全局性:自注意力机制在计算注意力权重时,涉及到整个输入序列中的所有token。这意味着每个token在生成最终表示时都可以"看到"整个序列中的信息,捕捉到全局依赖关系。
2.2 灵活性
- 动态加权:注意力权重是动态计算的,能根据当前token的Query向量和其他token的Key向量的相关性来调整,这使得模型在捕捉不同上下文信息时具有很高的灵活性。
3. 优势
3.1 并行计算
- 并行性:自注意力机制允许所有token的表示同时计算(并行),这与传统的递归神经网络(RNN)需要顺序处理的方式不同,大大提高了计算效率。
3.2 长程依赖
- 捕捉长程依赖:自注意力机制天然适用于捕捉序列中的长程依赖关系,因为每个token可以直接与序列中的任意其他token交互,不受序列长度的限制。
4. 实际应用
在Transformer架构中,自注意力机制被广泛应用于自然语言处理(NLP)和计算机视觉(CV)等领域。其主要优势在于能够高效地捕捉全局信息和长程依赖关系,从而提升模型的性能和泛化能力。
5. 总结
自注意力机制允许每个token在处理时考虑输入序列中所有其他token的信息,是通过计算每个token与其他token之间的相关性(注意力权重),并利用这些权重加权求和其他token的信息来实现的。这种设计使得模型能够有效地捕捉全局依赖关系和长程依赖,提高了信息交互的灵活性和计算效率。
五、理解自注意力机制中的加权求和
自注意力机制中的步骤




















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











