







一、单变量线性回归
1. 模型描述
监督学习的流程 & 单变量线性回归函数

代价函数:,其中 m 表示训练样本的数量
公式为预测值与实际值的差,平方为最小二乘法和最佳平方/函数逼近。
目标:最小化代价函数,即
2. 只考虑一个参数 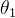
为方便分析,先取为0并改变
的值

3. 参数  都考虑
都考虑

将三维图平面化:等高线的中心对应最小的代价函数

二、梯度下降
1. 算法思路
- 指定
和
- 不断改变
不断减小
- 得到一个最小值或局部最小值时停止
2. 梯度
函数中某一点(x, y)的梯度代表函数在该点变化最快的方向(选用不同的点开始可能达到另一个局部最小值)

关于α:选择太小,会导致每次移动的步幅都很小,最终需要很多步才能最终收敛;
选择太大,会导致每次移动的步幅过大,可能会越过最小值,无法收敛甚至会发散;
实现原理:偏导表示的是斜率,斜率在最低点左边为负,最低点右边为正。 减去一个负数则向右移动,减去一个正数则向左移动。在移动过程中,偏导值会不断变小,进而移动的步幅也不断变小,最后不断收敛直到到达最低点。在最低点处偏导值为0,不再移动。
2.3 线性回归的梯度下降 / Batch梯度下降
最小化线性回归中的平方损失函数。

同时更新:

提示:
凸函数(convex function):只要一个全局最优
批量梯度下降:每次梯度下降使用所有的训练样本

















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









