







《Two-Stream Convolutional Networks for Action Recognition in Videos》是由Karen Simonyan 和 Andrew Zisserman 于2014年提出的一篇重要论文。视频中的动作识别是计算机视觉中的一个重要问题,传统的图像分类方法,虽然在静态图像上表现得很好,但在视频数据的处理上存在很大的挑战。视频不仅包含空间信息(单一帧的图像信息),还包含时间信息(帧与帧之间的运动信息)。因此,传统的基于卷积神经网络(CNN)的图像识别方法不能有效地捕捉视频中的动态信息。该论文提出了一种新的方法,用于从视频中识别动作(动作识别),并且其核心思想就是双流卷积网络(Two-Stream Convolutional Network),同时利用空间信息和时间信息来进行视频动作识别。
论文原文:Two-Stream Convolutional Networks for Action Recognition in Videos

一、介绍
在视频分类任务中,卷积神经网络(CNN)在处理静态图像时表现优异,但视频不仅仅是静态图像,它还包含了时间动态信息,CNN在处理这些时序信息时往往遇到困难。因此,单纯依赖CNN进行视频分类容易“碰壁”。但问题并不是深度学习无法理解视频,而是方法选择不当。视频的核心在于时空信息,深度学习能够通过适当的方式来同时处理空间和时间特征。动作识别在视频分类中变得尤为重要,因为大多数视频内容与人的动作有关,例如运动、舞蹈、新闻等,这些视频的核心就是对人类活动的识别。识别视频中的动作,实际上就是理解视频的动态变化,这对于视频分类至关重要。特别从数据收集的角度来看,人的动作视频比其他类型的视频更加常见,且具有更大的研究价值。
双流网络(Two-Stream Network)是一种用于处理视频数据的神经网络架构,它通过同时处理视频中的空间信息和时间信息来提升动作识别的精度。传统的神经网络虽然在图像分类任务中表现出色,但面对视频数据时,单一网络往往无法有效捕捉视频中的时空特征。视频不仅包含静态的图像信息,还包含动态的运动规律,而这些运动规律需要通过专门的方式来提取和理解。为了弥补这一不足,双流网络提出了空间流和时间流两个并行的卷积神经网络,分别处理视频的空间信息和时间信息。空间流主要通过卷积网络提取每一帧中的静态特征,而时间流则通过光流提取视频中的运动特征。光流本质上是描述视频中物体运动的矢量场,它反映了两帧图像之间像素的位移。在光流预测中,背景通常不动,而前景中的运动物体会表现为亮色。通过这种方式,光流能够捕捉到视频中的运动信息,而忽略了静态背景的干扰,进而帮助模型理解视频的动态变化。
光流的优势在于,它专注于视频中的运动信息,直接将运动特征提取出来。这样,模型不仅能够学到视频中的外观信息(appearance),还能够通过学习运动模式来捕捉动态变化。深度卷积网络尤其擅长进行这种映射学习,它能够从光流中提取深层的特征,并通过训练来理解运动规律。一些研究表明,直接在光流图像上训练的神经网络也能取得非常好的效果。
最终,双流网络通过将空间流和时间流的输出进行加权平均或其他融合方式,得出视频的最终分类结果。这种方法大大提高了动作识别的精度,因为它能够同时利用视频中的静态视觉信息和动态运动信息,有效地提升了对复杂动作的识别能力。

二、网络架构
视频可以拆分为空间和时间部分,空间部分提取静态特征,时间部分提取运动特征。将两者的输出通过加权平均或特征拼接来融合,以提升视频分类的精度。空间流网络在处理静态图像时效果很好,可以通过ImageNet预训练来获得更好的特征提取能力。这种预训练使空间流网络在视频处理中更加高效,能够为时间流的运动信息学习提供基础。结合空间和时间流,双流网络能够更准确地理解视频中的静态和动态特征,提高分类和动作识别的效果。

如何构造时间流
构造时间流的核心在于利用光流来捕捉视频中的运动信息。每两帧图像之间可以计算得到一个光流,表示水平方向和竖直方向上的位移。对于一段视频,L帧图像就会产生L-1个光流图。使用一个光流图进行训练是远远不够的,所以需要将这些光流图叠加在一起,论文中提出两种方式:
- 最简单的是直接叠加光流图,但这样没有充分利用光流信息;
- 根据光流的轨迹进行向量叠加,这样能够更有效地提取运动信息。
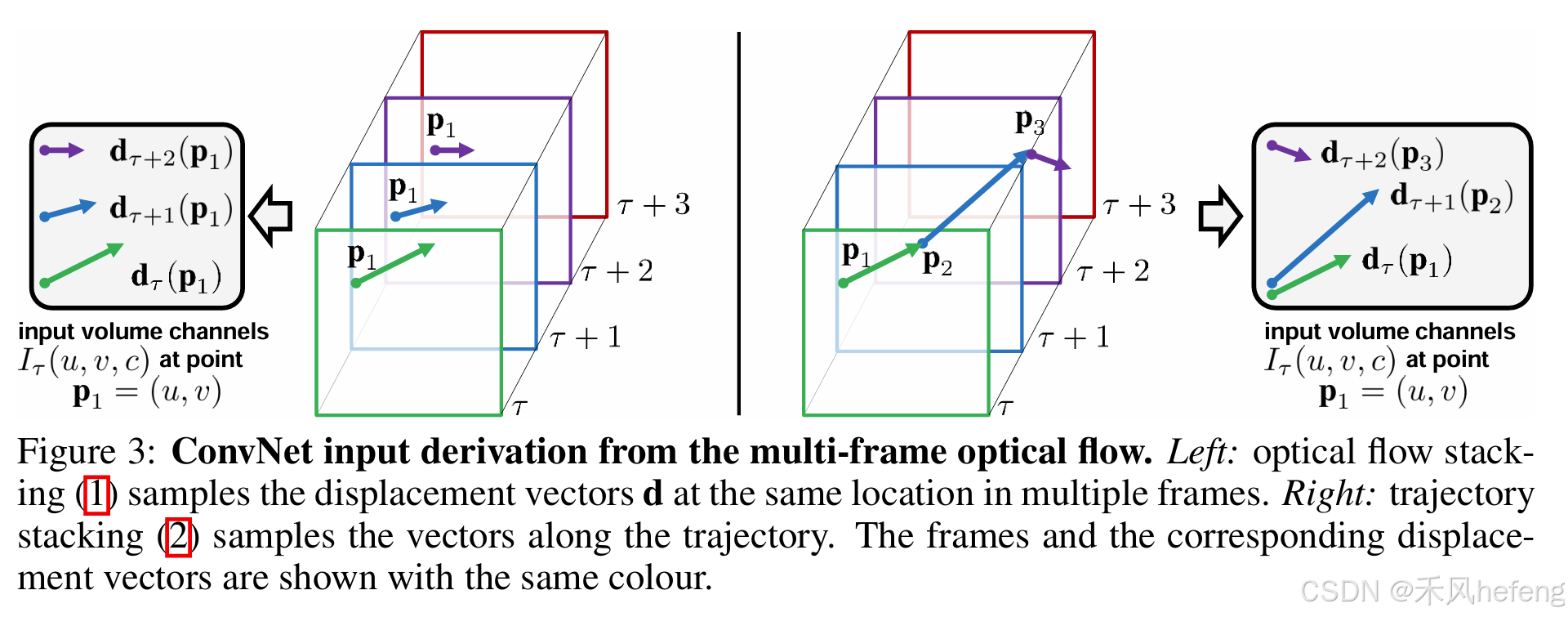
但是根据实验之后发现,理论上根据光流轨迹进行向量叠加的方式的效果不如简单的直接叠加的方式。论文中还使用了双向光流,就像BERT,这种方式跟金字塔、级联等方法一样,一般加入都能将模型效果提升,这样的话需要计算正向光流和反向光流,最终得到的光流图数量为2L。在整体结构图中可以看到,空间流和时间流的操作是一样的,将AlexNet进行变体。但是输入维度不同,空间流的输入维度为RGB三通道,而时间流的输入维度为2L。在时间流光流图的叠加时,先叠加水平位移,再叠加竖直位移。最后的输出是通过softmax进行分类,将得到的两个向量加起来取平均即late fusion操作,引入了一个额外的时间流。在训练和推理阶段,空间流和时间流的特征被融合,有两种方式:
- 加权平均:通过对空间流和时间流的输出进行加权平均,得到最终的分类结果。
- 拼接(Concatenation):将空间流和时间流的特征拼接在一起,进行后续的全连接层分类。
三、网络训练和测试
训练过程
训练过程中,使用小批量随机梯度下降(Mini-batch Stochastic Gradient Descent, SGD)进行网络权重的学习,动量(Momentum)设置为0.9。每次迭代时,从训练集中均匀抽取256个视频样本,组成一个小批量(Mini-batch)。从每个视频中随机选择一帧作为输入。
- 空间流网络训练(Spatial Net Training):
- 在空间流网络的训练中,选定的单帧图像会经过一系列数据增强操作:首先,从图像中随机裁剪出一个224x224的子图像。
- 然后,对该图像进行随机的水平翻转和RGB颜色扰动(RGB jittering)。视频帧会先被缩放处理,使得图像的最小边长为256像素。
- 需要注意的是,与之前的工作不同,这里裁剪子图像时会从整个图像中随机选取,而不仅仅是从中心部分裁剪256x256的区域。
-
时间流网络训练(Temporal Net Training):
- 在时间流网络的训练中,首先计算选定帧的光流(Optical Flow)。光流是描述视频帧之间像素运动的图像,具体计算方法在论文的第三部分进行了介绍。
- 对计算得到的光流数据进行处理:从光流数据中随机裁剪出固定大小的224x224的子图像,并执行随机翻转(flipping)。
-
学习率调度:
- 学习率的初始值为0.01(即10^-2),并按照预定的固定计划逐步降低:
- 训练开始后的50,000次迭代,将学习率降低到0.001(即10^-3)。
- 训练开始后的70,000次迭代,再次将学习率降低到0.0001(即10^-4)。
- 训练在80,000次迭代后停止。
- 在微调(Fine-tuning)阶段,学习率的变化方式如下:
- 训练开始后的14,000次迭代,学习率调整为0.001(即10^-3)。
- 训练在20,000次迭代后停止。
- 学习率的初始值为0.01(即10^-2),并按照预定的固定计划逐步降低:
测试过程
-
视频帧抽样(Frame Sampling):测试时,对于每个视频,从视频中均匀抽取25帧图像(即在时间轴上等间距抽取)。
-
数据增强(Data Augmentation):对于每一帧图像,从中裁剪并翻转四个角和图像中心,总共生成10个不同的输入图像(通过裁剪和翻转操作生成不同的视角)。
-
分类预测:使用训练好的卷积神经网络(ConvNet)对每个视频中的所有帧进行预测。通过对每帧的分类结果进行平均,得到该视频的最终类别预测结果。
-
类别得分计算:最终的视频分类得分是通过对所有采样帧的得分进行平均得到的,这样做能够更好地捕捉到视频中的时序信息和空间特征。
实验与结果
- 在UCF101和HMDB51等视频动作识别数据集上,双流网络的表现大大优于传统方法,取得了最高的精度。
- 双流网络不仅利用了静态图像的空间信息,还能够捕捉视频中的时序特征,因此在识别视频中的动作时具有很大的优势。


总结
论文提出的双流卷积网络为视频中的动作识别问题提供了一个新的解决方案。通过同时处理视频的空间信息和时间信息,该方法显著提升了视频分析任务的效果,尤其是在动作识别领域。双流网络的思想后来被广泛应用于其他视频分析任务,如视频分类、目标检测、视频摘要等。
参考资料:
【论文&模型讲解】Two-Stream Convolutional Networks for Action Recognition in Videos-CSDN博客
【论文学习】Two-Stream Convolutional Networks for Action Recognition in Videos-CSDN博客


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









