







LDPC(低密度奇偶校验码)是一种高效的纠错编码技术,广泛应用于现代通信和存储系统。由由Robert G. Gallager于1962年提出,后因Turbo码的竞争一度被忽视,1990年代因逼近香农限的性能被重新重视。LDPC码是一种基于稀疏校验矩阵的线性分组码,其校验矩阵( H矩阵 )中非零元素极少(低密度)。由于其稀疏性,即校验矩阵中非零元素占比低,能够降低编解码的复杂度。
编码原理
在传统通信中,编码过程需要用到生成矩阵,而解码过程需要用到校验矩阵。在LDPC编码中,校验矩阵(H矩阵)由0和1组成,满足 ,其中
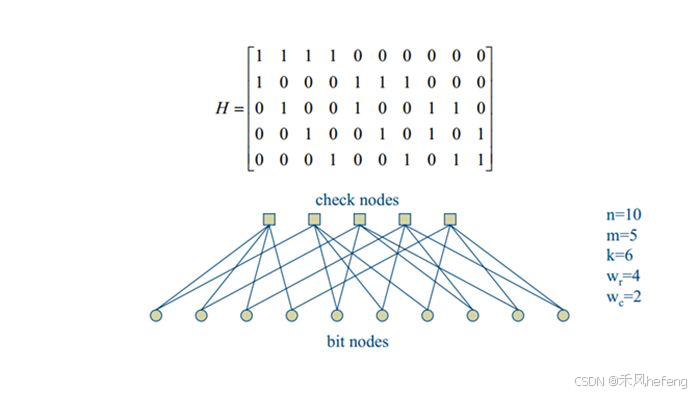
为码字。而H矩阵根据LDPC码的不同设计,规则的LDPC码的H矩阵每行或列的非零元素数量固定(如每行6个1,每列3个1),而不规则的LDPC码的非零元素数量可变,通常性能更优但设计复杂。生成矩阵(G矩阵)将信息位
编码为码字
。通过H矩阵分解(如高斯消去法)得到系统形式的G矩阵:
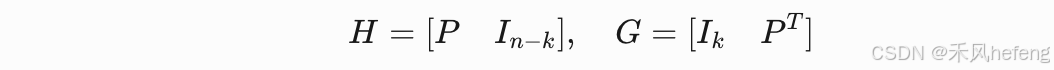
其中 为单位矩阵,
为校验位生成矩阵。
代码
编码过程
1. 参数定义与码长计算
def ldpc_encode(data_tensor, d_v, d_c, malv, snr=10):
n = int(data_tensor.shape[1] * malv)输入参数 :
- data_tensor : 输入数据张量,形状为 [batch_size, data_length] ,表示批量二进制信息位
- d_v : 变量节点度数(每个变量节点连接的校验节点数)
- d_c : 校验节点度数(每个校验节点连接的变量节点数)
- malv : 码长扩展倍数( n = data_length * malv )
- snr : 信噪比(用于模拟信道噪声)
变量节点度数(d_v):每个变量节点(对应编码后的一个比特)连接的校验节点数量 。对于规则LDPC码来说,所有变量节点的度数相同,均为 d_v ;而对于不规则LDPC码来说,变量节点度数可不同,但平均度数为 d_v 。
- d_v 越大→ 每个变量节点参与的校验方程越多 → 更多约束信息用于纠错 → 纠错能力增强,但过高的 d_v 会导致短环(cycles) 增多(如4环),影响消息传递算法的收敛性。
- d_v 越大→ 每个变量节点需处理更多来自校验节点的消息 → 解码迭代复杂度增加。
校验节点度数(d_c):每个校验节点(对应一个校验方程)连接的变量节点数量 。对于规则LDPC码 来说,所有校验节点度数相同,均为 d_c ;而对于不规则LDPC码来说,校验节点度数可不同,但平均度数为 d_c 。
- d_c 越大→ 每个校验方程覆盖更多变量节点 → 校验约束更严格 → 可检测更多错误组合。但过高的 d_c 会导致校验矩阵密度增加,削弱LDPC的“低密度”优势, 解码收敛速度下降 。
- 码率 R = 1 - (d_v / d_c) (近似关系,实际由H矩阵维度决定)
码长计算 :
- n 为编码后码字长度,通过输入数据长度 data_length 乘以 malv 得到。例如,输入长度100且 malv=2 ,则 n=200 。
2. 生成LDPC矩阵
H, G = pyldpc.make_ldpc(n, d_v, d_c, systematic=True, sparse=True)
k = G.shape[1] # 确定消息长度k- make_ldpc 函数 : 生成稀疏校验矩阵 H 【尺寸 (n-k) x n 】和生成矩阵 G 【系统码形式,尺寸 n x k 】。systematic=True 确保编码后前 k 位为原始信息位,后 n-k 位为校验位。
- 消息长度 k : 由生成矩阵 G 的列数确定,满足码率 R = k/n 。
3. 数据对齐与补零
encoded_data_list = []
for data in data_tensor.numpy():# 遍历输入数据
concat_array_list = [0 for _ in range(k - data.shape[0])] # 生成补零列表,使数据总长度达到 k
data = np.concatenate([data, np.array(concat_array_list)]) # 将原始数据与补零数组合并
if data.shape[0] != k: # 长度校验
raise ValueError(f"输入数据的第二维长度必须为{k}。")- 补零逻辑 : 将每个数据样本从 data_length 补零至长度 k 。例如,若 data_length=150 且 k=200 ,补50个零。 确保输入数据长度不超过 k ,否则抛出异常。 目的是为了适配生成矩阵 G 的维度,满足矩阵乘法 encoded_data = G * data 的要求。
4. LDPC编码与噪声添加
encoded_data = pyldpc.encode(G, data, snr=snr)
encoded_data_list.append(torch.tensor(encoded_data))- pyldpc.encode : 使用生成矩阵 G 进行编码,输出码字 encoded_data (长度 n )。
- snr 参数:模拟AWGN(加性高斯白噪声)信道,根据信噪比添加噪声。 此处噪声添加实际属于信道模拟步骤,非编码本身。
5. 返回结果
encoded_data_tensor = torch.stack(encoded_data_list, dim=0)
return encoded_data_tensor, H- encoded_data_tensor : 形状 [batch_size, n] 的编码数据张量。
- H : 校验矩阵,用于后续解码。
解码过程
1. 参数定义
def ldpc_decode(encoded_data_tensor, H, k, snr=10, ldpc_max_iter=100):输入参数 :
- encoded_data_tensor : 编码后的含噪数据(形状 [batch_size, n] )。
- H : 编码时生成的校验矩阵。
- k : 原始信息位长度(需与编码时一致)。
- snr : 信噪比(需与编码时相同,用于解码算法中的置信传播)。
- ldpc_max_iter : 最大解码迭代次数。
2. 迭代解码
decoded_data_list = []
for encoded_data in encoded_data_tensor.numpy().astype(np.float64):# 转换为 NumPy数组,并转换为 64位双精度浮点数
decoded_data = pyldpc.decode(H, encoded_data, snr=snr, maxiter=ldpc_max_iter)- pyldpc.decode : 基于置信传播(Belief Propagation, BP)算法,利用校验矩阵 H 进行迭代解码。 snr 参数用于计算初始似然比(LLR),影响解码收敛性。 maxiter 限制最大迭代次数,防止无限循环。
3. 硬判决与数据截断
decoded_data = np.array(decoded_data >= 0.5, dtype=int)
decoded_data = decoded_data[:k]- 硬判决 : 将解码输出的概率值(0~1)转换为二进制(≥0.5判为1,否则0)。
- 截断操作 : 取前 k 位作为原始信息位(因编码为系统码,前 k 位即原始数据)。
4. 返回结果
decoded_data_tensor = torch.stack(decoded_data_list, dim=0)
return decoded_data_tensor- 输出 : decoded_data_tensor : 形状 [batch_size, k] 的解码数据张量。


















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









