








前言
之前已经讲过SDXL_LORA,SD1.5_LORA训练过程,基本说的比较清楚了,有兴趣可以去看看,下面我将讲解一下SD1.5大模型的炼制。
SDXL_LORA:https://tian-feng.blog.csdn.net/article/details/132955577
SD1.5_LORA:https://tian-feng.blog.csdn.net/article/details/132133361
DreamBooth 是一种定制个性化的 TextToImage 扩散模型的方法。仅需少量训练数据就可以获得极佳的效果。Dreambooth 基于 Imagen 研发,使用时只需将模型导出为 ckpt,然后就可以被加载到各种 UI 中。
然而,Imagen 的模型和预训练的权重都不可用。所以最初的 Dreambooth 并不适用于稳定扩散。但后面 diffusers 实现了 Dreambooth 这一功能,并且完全适配了 Stable Diffusion。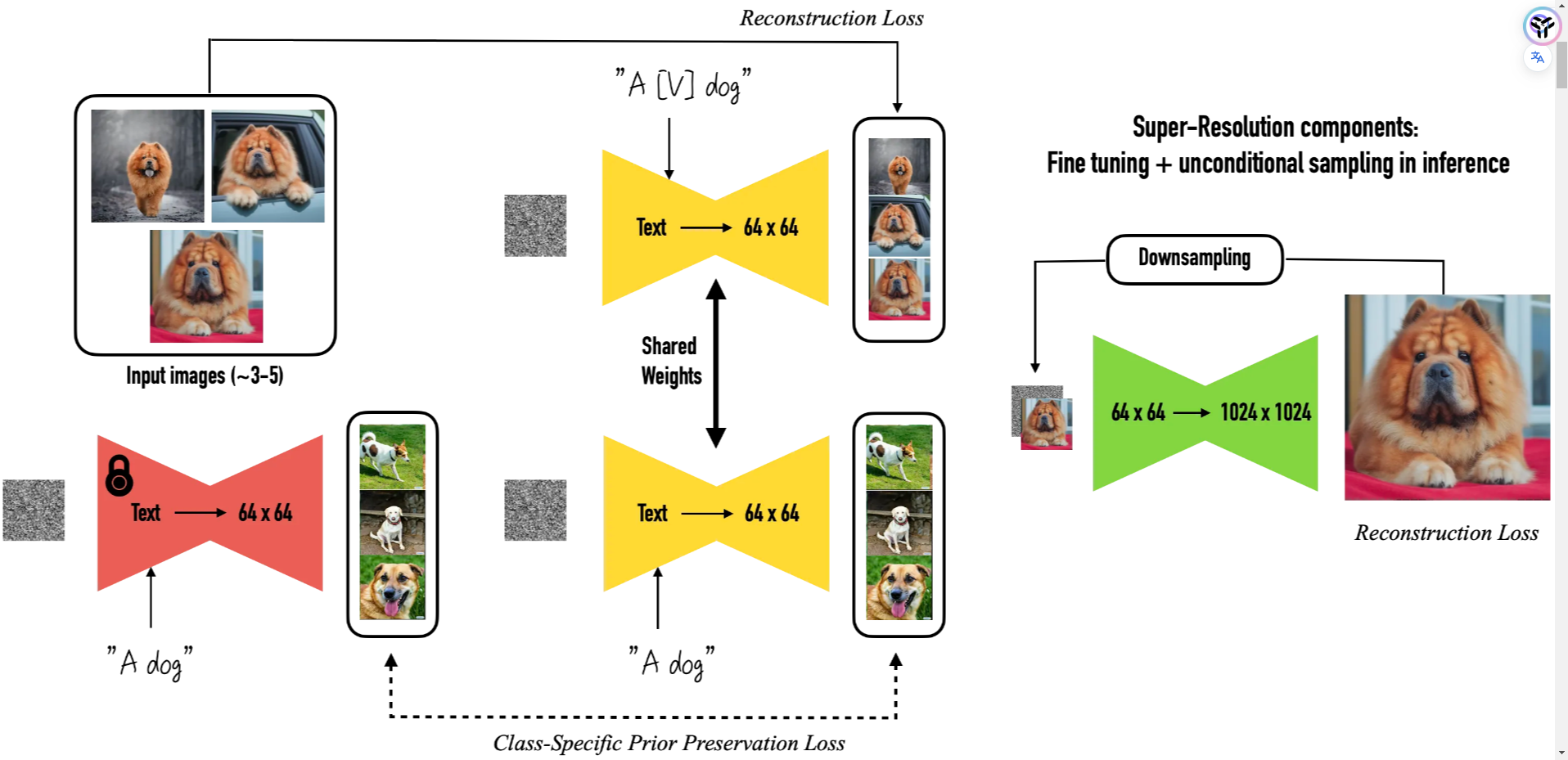
模型炼制
数据准备
和LORA一样,裁剪成512x512的大小后打tag,数据处理参考之前文章,不赘述了,数据的多少根据你的任务来(真人,二次元,画风),先别急,最好听我把流程讲完,你再准备数据开始炼制。
二次元:20-50(建议抠图填白,脸部训练影响不大,不过自己可以试试,说不定效果更好)
真人:50-100张(建议抠图填白,加强脸部训练)
画风:1000往上
这只是参考区间,如果你的图片质量都是一级棒。那当然是越多越好,别强行为了数量把一些一般照片放进去,可能数量上去了,反而训练的很烂。
假设我来炼制一个真人模型,这是我的数据集,只是打个样

抠图后,赛博丹炉下有两个文件夹,分别是裁剪后的人物和脸型
之后把你的底膜准备好,与你图片炼制风格相近的,之后一起压缩上传百度网盘,这样是为了下载方便,因为你可以新建一个文件夹在Autodl和百度云盘共享一个空间,如果手动拖动文件到Autodl,那真是速度很慢;特别是大模型2个G,这个教程请看SDXL_LORA文章,这个不难,中文教程说的很明白了,一步步按他说的弄。
Autodl炼制
直接搜素dreambooth就出来了,立即创建
镜像名: Akegarasu/dreambooth-autodl/dreambooth-autodl:v3
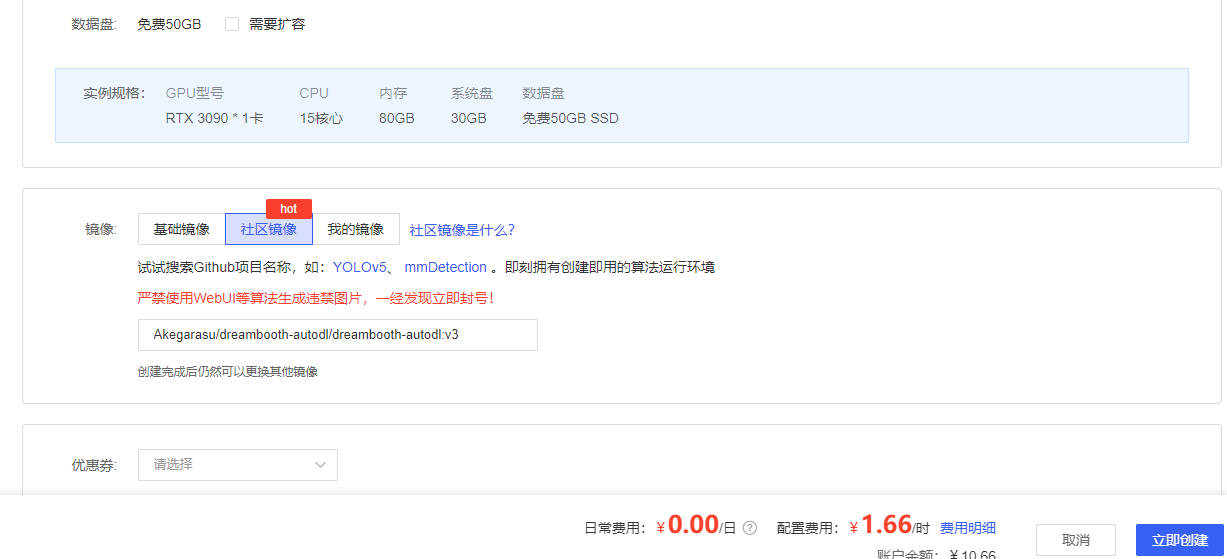
打开终端,把系统盘的dreambooth-aki移动到数据盘中,因为系统只有30G,数据盘有50G,
mv /root/dreambooth-aki/ /root/autodl-tmp/
ipython kernel install --user --name=diffusers 下载diffusers内核等下测试用
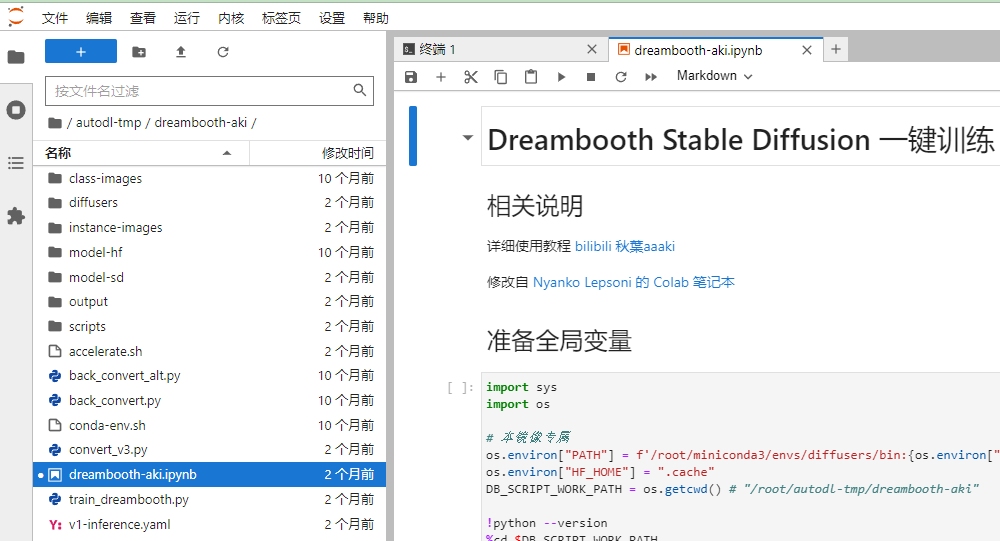
点击ipynb文件训练脚本
直接方式:简单但上传速度一般
文件放置路径:模型文件直接放到model-sd,数据集图片直接放到instance-images,手动拖动即可
间接方式:需要建立共享空间但上传速度快
下载完文件在Autodl-tmp路径下
强调:最好都是压缩zip上传,解压指令如下
unzip /root/autodl-tmp/dreambooth-aki/文件名.zip
移动文件
数据集移动
mv /root/autodl-tmp/dreambooth-aki/文件名/* /root/autodl-tmp/dreambooth-aki/instance-images/
模型移动
mv /root/autodl-tmp/dreambooth-aki/模型名 /root/autodl-tmp/dreambooth-aki/model-sd/
mv是move意思,把文件从源地址移动到目的地址
数据准备完毕
训练参数
autodl-tmp/dreambooth-aki/dreambooth-aki.ipynb
其实秋叶大佬讲的挺清楚了,基本改一下文件路径即可,直接一步步运行,不管我还是一步步讲一下
定义了一些模型转换文件和全局变量等等,直接Ctrl enter运行,
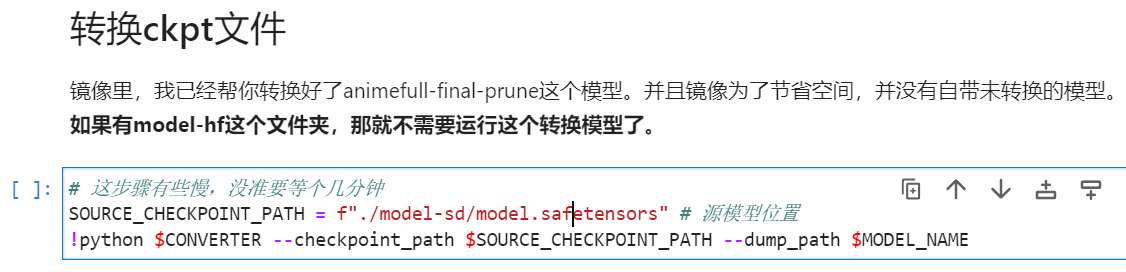
秋叶已经转换好了一个动漫底膜,在model-hf下,之前我们已经把真人底模放在了model-sd中,把model.safetensors改成自己底模的名字,运行后自动覆盖model-hf下文件
可以看到分完后,模型被拆解为文本编码器,分词器,unet,vae

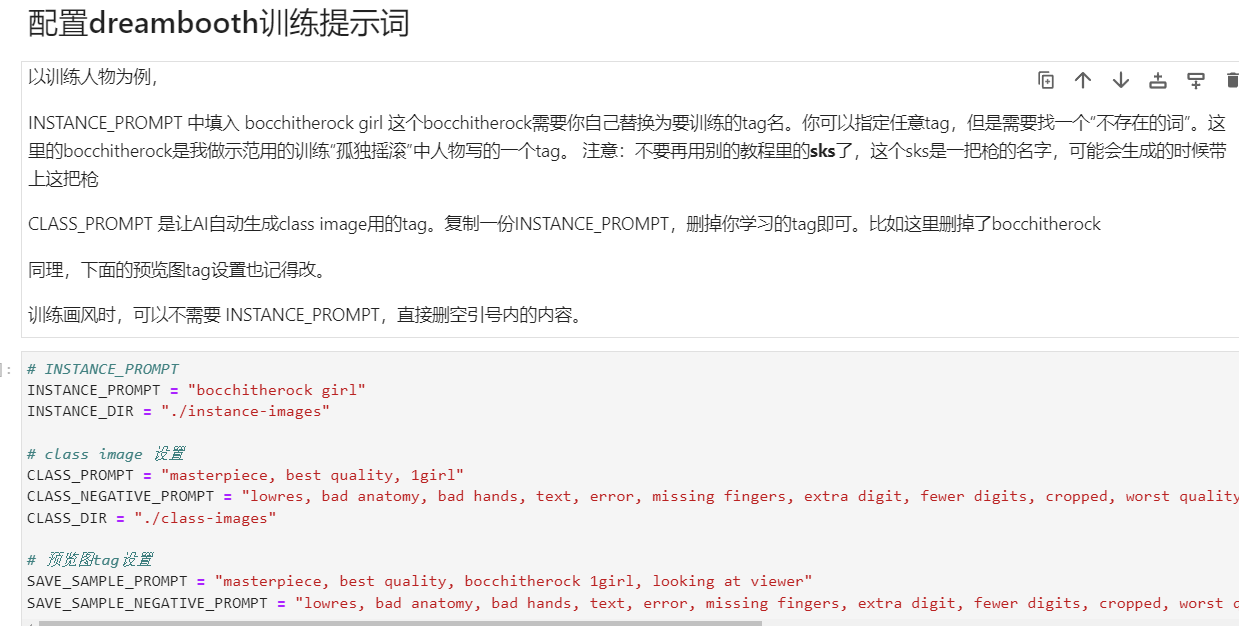
bocchitherock改成一个自己命名的tag(但是不存在的英文单词),就像触发词一样,这样进行训练文本编码器会把这个词和你训练的图片画风挂钩,你的自定义tag更容易生成你训练图片的画风
- Instance Image
你所训练的目标数据集。 - Instance Prompt(就是自定义tag)
默认实现为全局共享一个 prompt, 就是把这个tag放到所有训练图片标签中 - Class/Regularization Image 就是正则化,应该为 自动生成 即 auto-generated 的图像,用于检测 AI 的先验知识。不应该放任何非 AI 生成的图像。自动生成不用管
- Class Prompt 就是根据你训练的人物写一个简单的tag,例如训练一个女孩模型,就是1girl再加点质量词
基本不用改动,运行
这两个不用改直接运行
# 常用参数 我就不一一讲了,有兴趣看看我sdxl_lora训练,参数讲的挺清楚了,没有的我讲一下
## 最大训练步数
max_train_steps = 3000 #二次元步数3000-5000;真人5000-10000;画风那就使劲把
## 学习率调整
learning_rate = 5e-6 #默认数值,根据训练loss调整,
## 学习率调整策略
## ["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup", "cosine_with_restarts_mod", "cosine_mod"]
lr_scheduler = "cosine_with_restarts"
lr_warmup_steps = 100
train_batch_size = 1 # batch_size
num_class_images = 20 # 自动生成的 class_images 数量
with_prior_preservation = True #训练人物开启;训练画风关闭
train_text_encoder = False # 训练文本编码器
use_aspect_ratio_bucket = False # 使用 ARB
# 从文件名读取 prompt
read_prompt_from_filename = False
# 从 txt 读取prompt
read_prompt_from_txt = False
append_prompt = "instance"
# 保存间隔
save_interval = 500 #没多少步保存,基本得1000以上要不你数据盘保存几个就满了
# 使用deepdanbooru
use_deepdanbooru = False
# 高级参数
resolution = 512
gradient_accumulation_steps = 1
seed = 1337
log_interval = 10
clip_skip = 1
sample_batch_size = 4
prior_loss_weight = 1.0 #越低则越难过拟合,但是也越难学到东西。
# 一种学习率调度策略,通常用于训练深度学习模型时的优化器。这个策略的主要思想是随着训练的进行,
#逐渐减小学习率的大小,以帮助模型更好地收敛。
scale_lr = False
scale_lr_sqrt = False # 同上
gradient_checkpointing = True
pad_tokens = False
debug_arb = False
debug_prompt = False
use_ema = False
#only works with _mod scheduler
restart_cycle = 1
last_epoch = -1
基本调这几个就行
Finetune基础学习率:3e-6;自动打标准确率:0.35以上
batch size:
- 小样本集(百张级别)3以内可以开scale/sqrt Ir
- 大样本集(千、万张)能开多大是多大
- 步数:百张左右1w步图片多的情况5 epoch以上
确定batch_size后就是调你的学习率了,运行
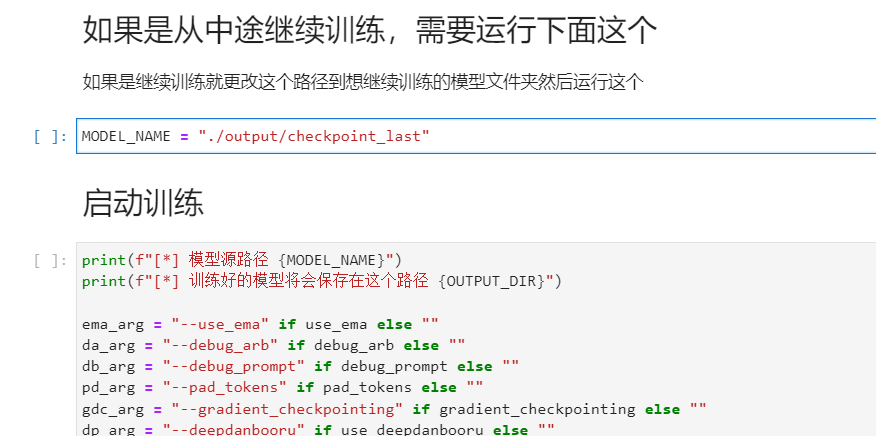
可以接着上次结果训练,第一次,不用运行,直接到启动训练运行完事
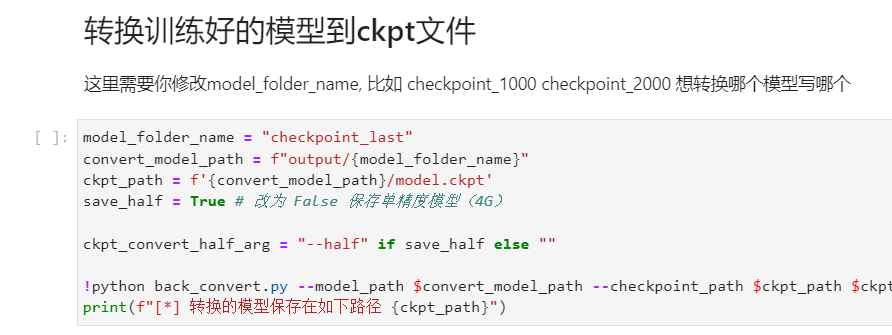
然后转换为ckpt文件,修改你output下保存的模型名,就可以转换了,运行
接下来就是测试了,可以大概看一下你的模型是否还行决定是否下载,但是和本地不太一样,可能效果差一点。修改测试的模型名,和上面一样
运行
总结
其实模型的炼制只是一部分,现在所有的大模型都是在原始模型基础上一步步进行微调,因为想重新自己炼制一个大模型,对于我们来说基本不可能,但是微调却让我们都能参与进来,可以看到,现在sd1.5的生态圈在不同作者的努力下,已经百花齐放;
模型创作者更像一个调酒师,就像之前看到的麦橘大佬所说,基于不同的大模型不同比例融合,如何融出一个更好的大模型,这点好像大家都知道,但是都不怎么说这个事,毕竟公开融合他人模型多多少少会有点问题,所以我也浅谈为止,以后有机会再细说把!!!


















 1499
1499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











