







如何制作和训练自己的数据集
- 标注
- 自己获得数据集(手动)-人工标注
- 自己获得数据集-半人工标注
- 仿真数据集(GAN、数字图像处理的方式(抠图贴图,具体位置是可知的))
可以搜索:synthetic data object detection github



首先创建--data 文件
- path为根目录
path: ../datasets/coco128 # dataset root dir - 训练集和验证集的相对位置
train: images/train2017 # train images (relative to 'path') 128 imagesval: images/train2017 # val images (relative to 'path') 128 images
3.指定训练类别
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
...
77: teddy bear
78: hair drier
79: toothbrush
二、制作自己的数据集
下载四张汽车照片




添加标签
标注数据集地址:https://www.makesense.ai/
GET STARTED
点击添加图片
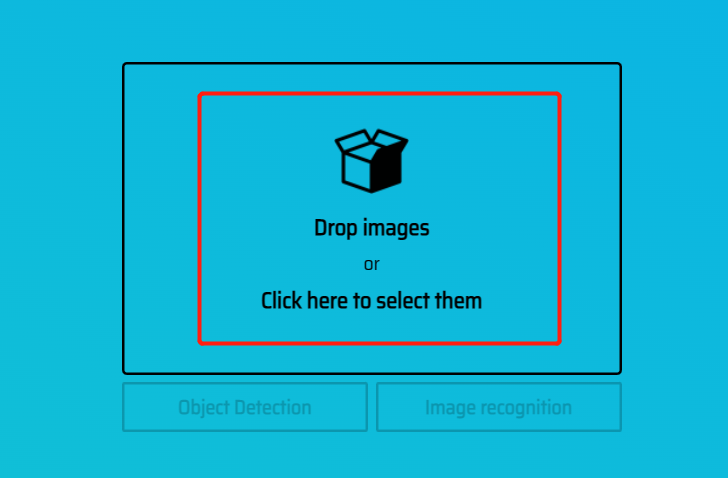
选择并确定
Object Detection 目标检测
Image recognition 图像识别
选择目标检测
3.用文件添加label类别:换行分割

上传label.txt,显示找到两个labels
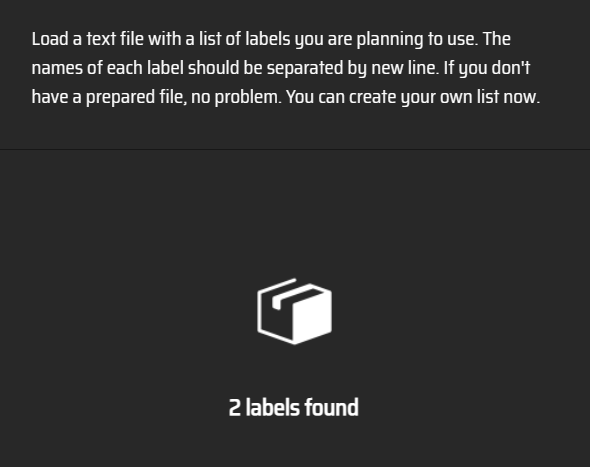
重新编辑labels
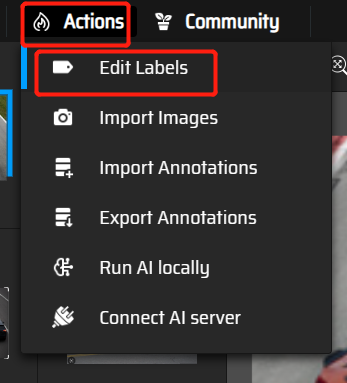
添加一列自行车
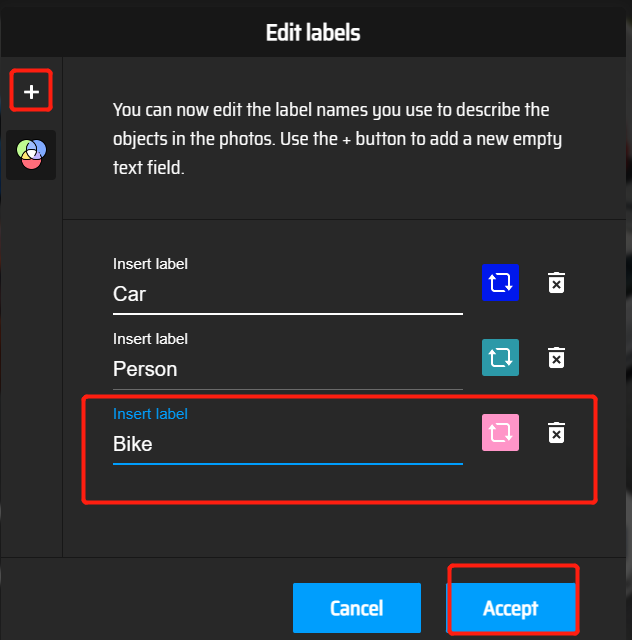
参数解释:
Import Images:导入图片
Import Annotations :导入标注
Export Annotations:导出标注
Run AI locally:使用AI模型辅助标注
手动标注:Rect:矩阵标注;Point:点标注;Line:线标注;Polygon:多边形标注
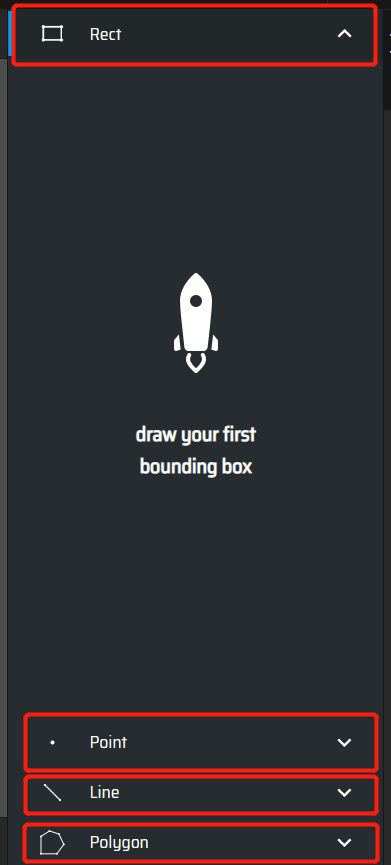
框选出车,并在右边选择类别

标注人

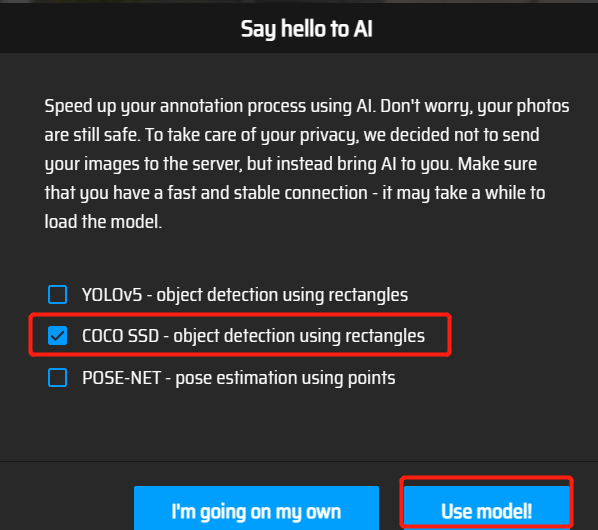
使用人工智能标注
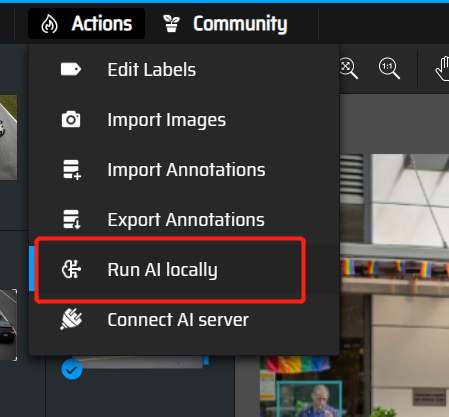
选coco数据集
出错:因为car与Car大小写而以为有新的类别,故拒绝
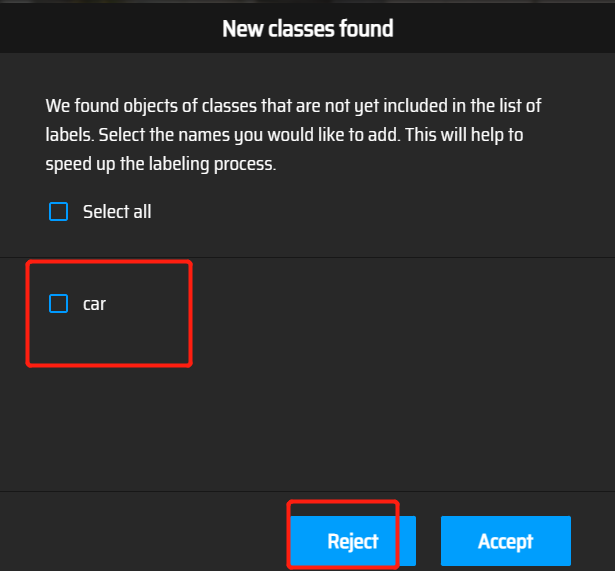
人工智能发现的图像,鼠标移到左上角点击“+”,右边选择类别

添加后效果

将重复的框删除,没标注的手动标注上
4.导出标注数据
选择Export Annotations
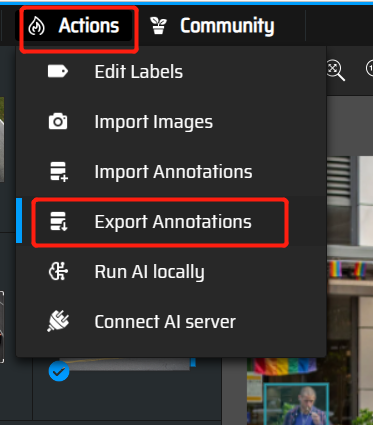
选yolo格式并导出
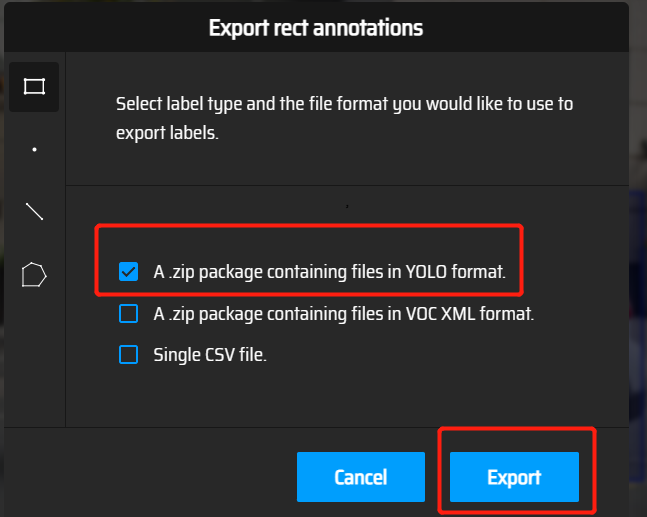
下载好的文件
解压打开

0 代表汽车 x中心,y中心,宽度,高度 yolo格式是归一化的坐标
1是Person 2是Bike
三、组织数据集
建一个文件夹为images,再建一个labels对应,在images和labels下在建立train和test
../datasets/coco128/images/im0.jpg # image ../datasets/coco128/labels/im0.txt # label
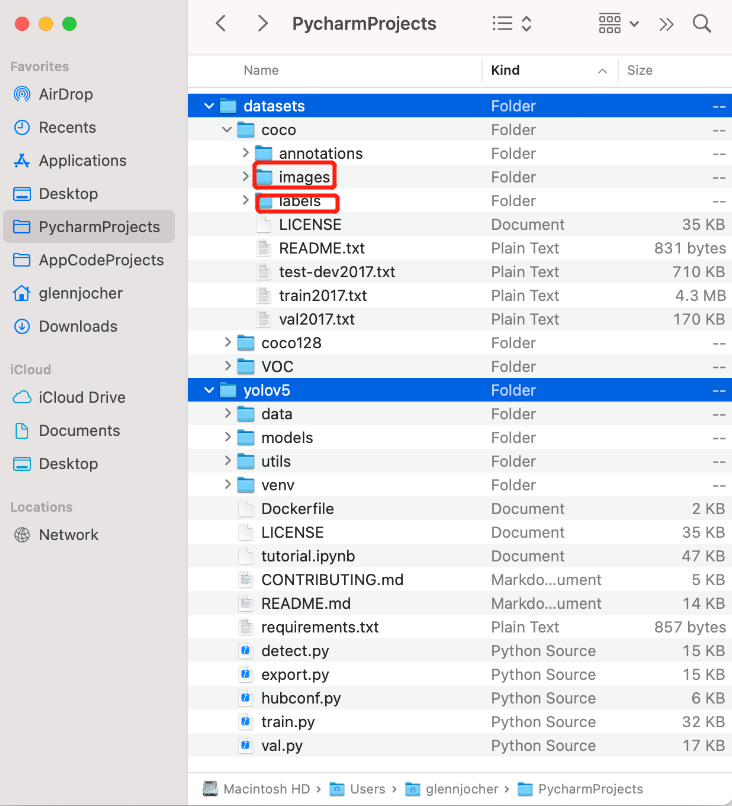
在yolov5中创建mydata,再创建images和labels文件夹,按如下操作,注意对应
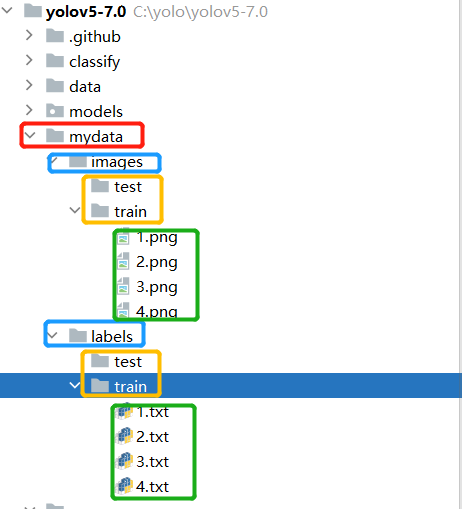
四、写--data 文件
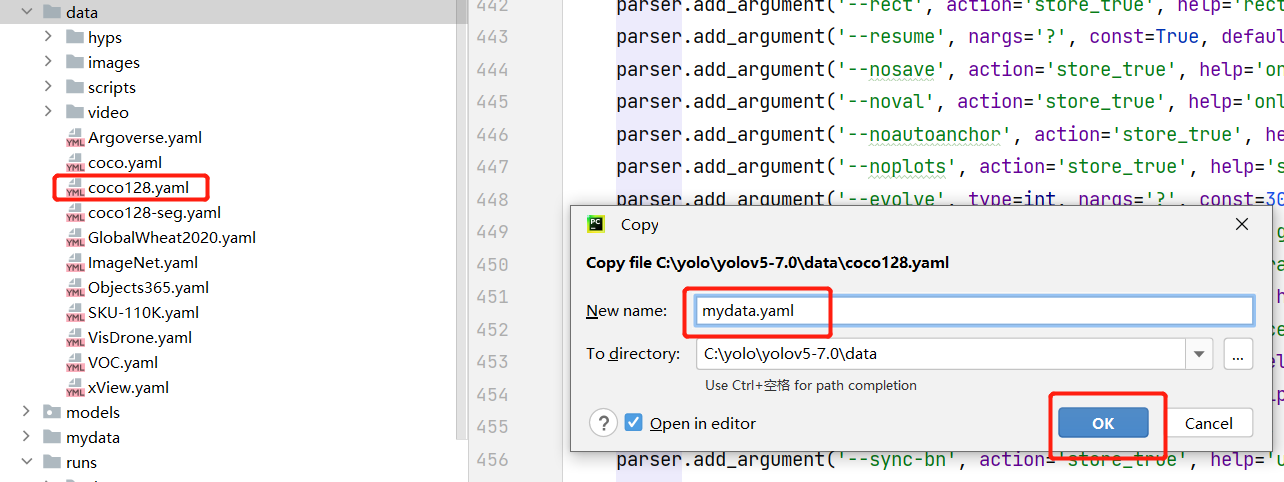
将data/coco128.yaml复制并重命名为mydata.yaml
copy并重命名
train是训练集,
val是训练过程中的测试集,是为了让你在边训练边看到训练的结果,及时判断学习状态。
test就是训练模型结束后,用于评价模型结果的测试集。
只有train就可以训练,val不是必须的,比例也可以设置很小。
test对于model训练也不是必须的,但是一般都要预留一些用来检测,通常推荐比例是8:1:1
按如下修改地址和类别:
path: mydata # dataset root dir train: images/train # train images (relative to 'path') 128 images val: images/train # val images (relative to 'path') 128 images test: # test images (optional)
修改类别:可以不需要大写,因为对应的是类别数字
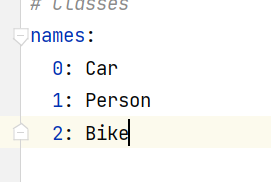
删除download
保存文件
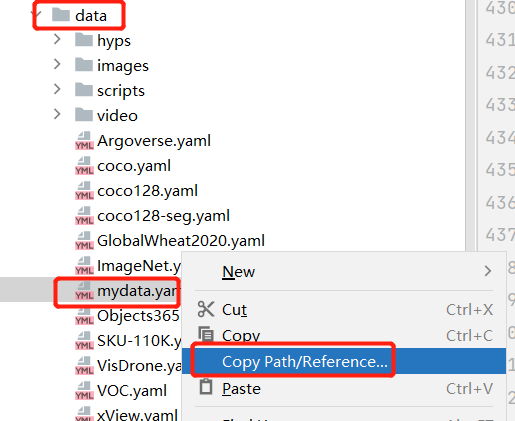
将mydata.yaml路径拷贝到对应train.py --data default参数中
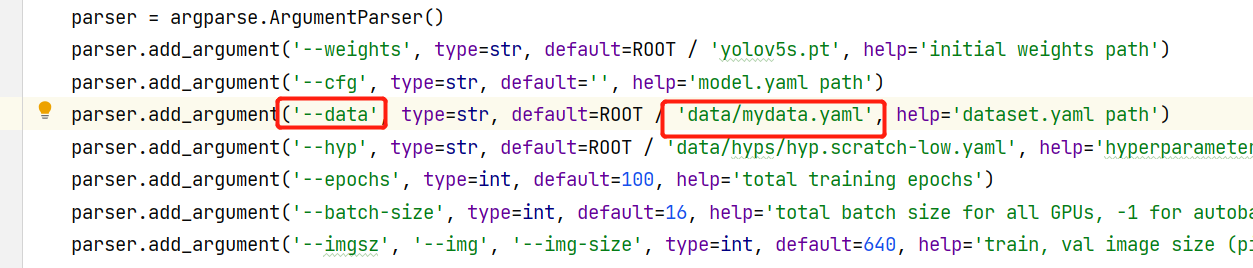
五、运行train.py

结果保存在:
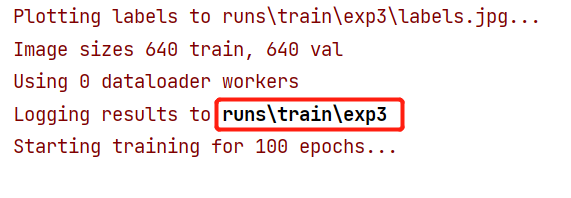
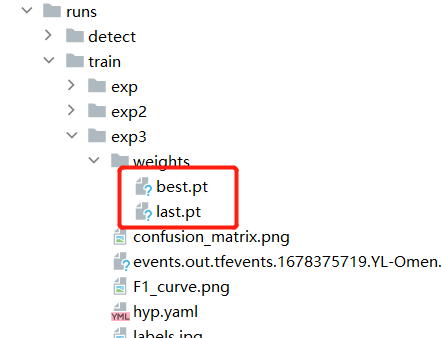
训练结束
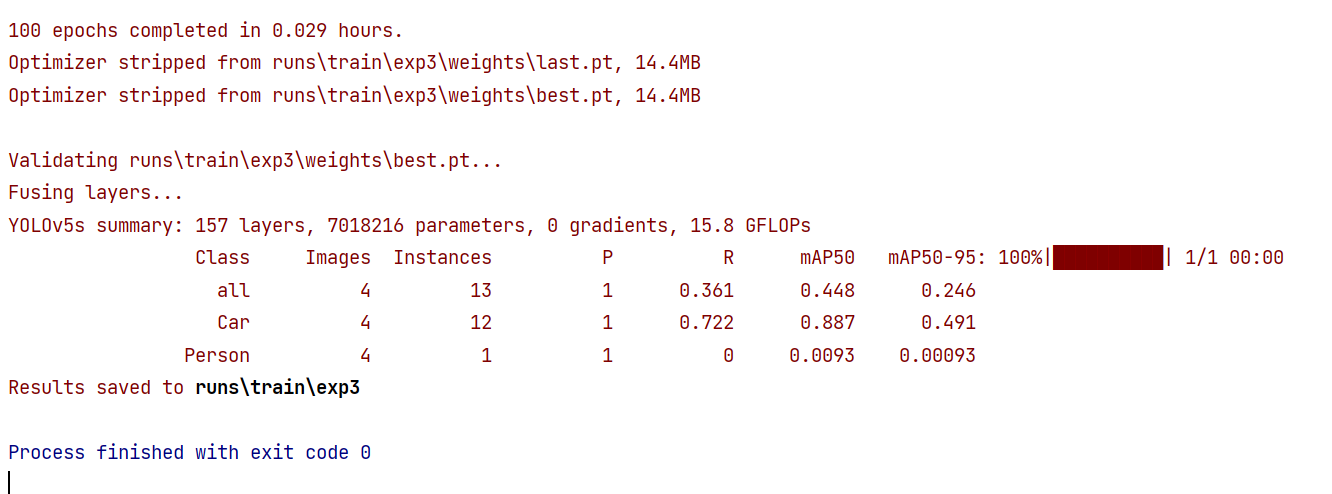 六、测试权重
六、测试权重
修改detect.py中的--weights 为 best.pt

设置--source 为训练数据集

检测结果如下:
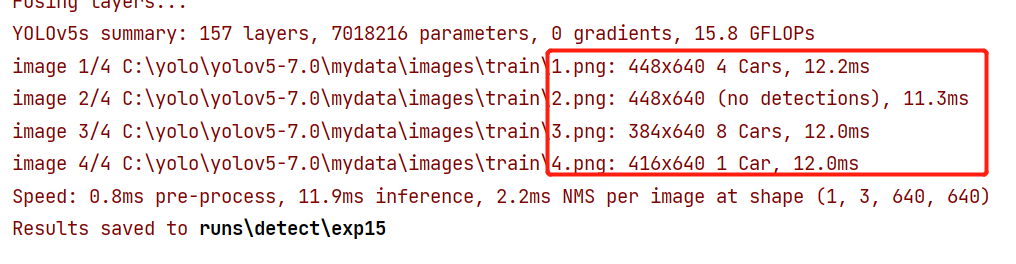


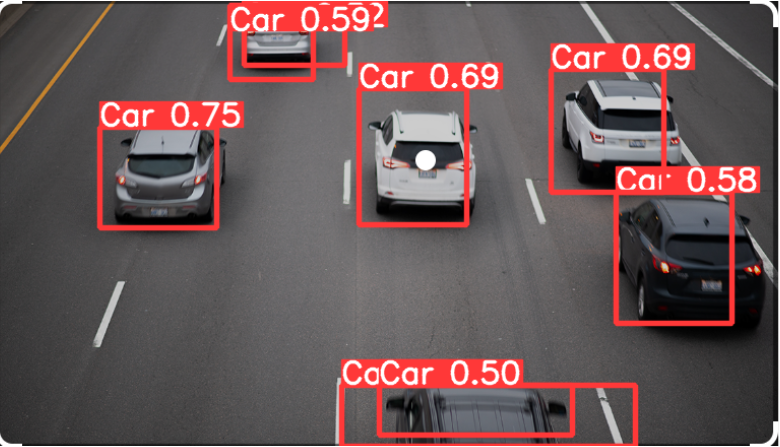

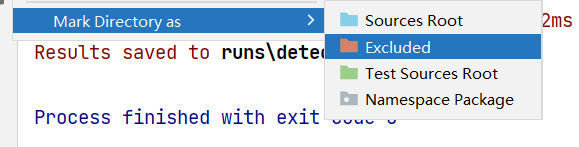
把数据集放到项目外面可以避免Pycharm检索浪费时间,或者调为exclude,这样pycharm就不会检索了















 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









