







论文地址:https://arxiv.org/abs/2007.07296
代码地址:https://github.com/rand2ai/fedboosting
作者本人的文章讲解:https://arxiv.org/abs/2007.07296
摘要:
数据隐私保护—>联邦学习框架—>非独立同分布数据产生权重差异、泛化差、梯度泄漏—>联邦加速算法FedBoosting
使用同态的安全梯度共享协议,引入加密和差分隐私防御梯度泄漏攻击
介绍:
- 对于非独立同分布数据集,训练需要更多的迭代才能达到最优解,并且常常不能收敛,尤其是在批处理规模较小的大规模数据集上训练局部模型或经过大量epoch后对全局模型进行聚合。
- 模型梯度在FL系统中共享是不安全的。

FEdBoosting收敛速度快于FedAvg
情况:当局部模型以小批量训练,而全局经过大量epoch聚合,FedBoosting成功,FedAvg失败
tips:FedAvg对IID和非IID数据都适用,但当局部模型进行大规模训练时,非IID不适用
使用方法:
FedBoost根据本地模型在验证数据集上的实际表现去自适应的更新全局模型。
但是不同的客户端有其自己的训练集和验证集,需要考虑不同客户端本地模型之间的契合度和泛化特性。(用传输本地模型的方法代替传播数据)(客户端模型采用不同的权重自适应合并全局模型)
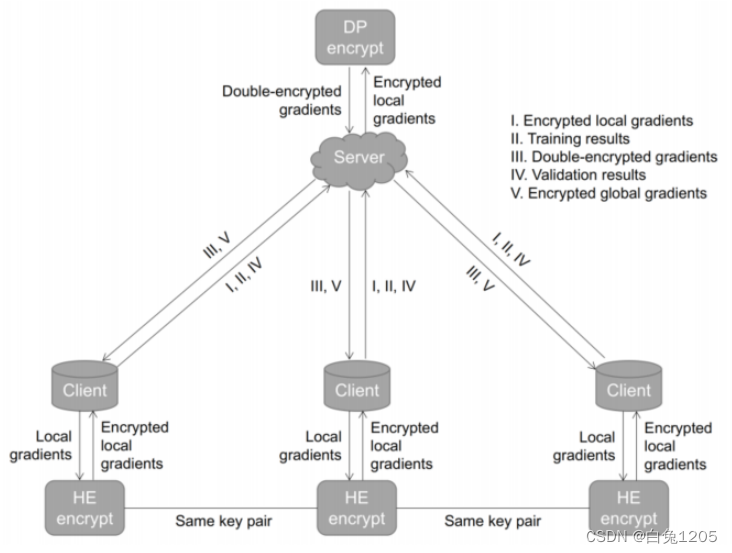
客户端非独立同分布数据的影响,FedAvg聚合会产生强偏置和极端异常值—>FedBoosting:根据不同局部验证数据集上的泛化性能自适应合并局部模型
通过中央服务器交换加密的本地模型,在每个客户端上独立验证
每个客户端生成三个不同的信息:

全局模型的总权重:(训练损失和验证损失共同决定)



















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









