









摘要:
联邦学习(FL)由于其保护数据隐私的能力,最近受到了广泛的关注。然而,现有的FL范式在广泛的人类活动识别(HAR)应用中表现不理想,因为它们忽略了不同用户数据之间的内在关系。我们提出了ClusterFL,一个相似感知的联邦学习系统,可以为HAR应用程序提供高模型精度和低通信开销。ClusterFL采用了一种新颖的聚类多任务联邦学习框架,可以最大限度地提高多个学习模型的训练精度,同时自动捕获不同节点数据之间的内在聚类关系。基于学习到的聚类关系,ClusterFL可以有效地剔除每个聚类中收敛较慢或与其他节点相关性较小的节点,在保持精度性能的同时,显著加快了收敛速度。我们在NVIDIA边缘测试平台上使用从总共145个用户收集的四个新的HAR数据集评估ClusterFL的性能。结果表明,ClusterFL在整体精度方面优于几种最先进的FL范式,并以可忽略不计的精度下降为代价节省了50%以上的通信开销。
-
- 引言
近年来,深度学习越来越多地应用于人类活动识别[11,51,61]。之前的大部分工作都集中在集中式学习方法上,需要使用从用户收集的所有数据进行集中训练。然而,集中收集传感器数据会对纵向慢性病监测等应用产生重大的隐私问题[65]。此外,由于人类生物学特征、物理环境甚至传感器偏差的不同,不同用户的数据往往表现出高度的异质性,导致模型精度较差[24,26]。联邦学习(FL)[29,38]是一种分布式机器学习方法,它只需要节点上传模型权重,避免在学习过程中暴露用户的原始数据。典型的联邦学习方法(例如,FedAvg)[9]迭代地从所有节点聚集模型权重,直到收敛到全局模型。然而,由于不同用户数据的异质性,这种单一模型学习范式在实际HAR应用中表现不佳[12,50]。最近,有人提出了训练后个性化[12,27],通过对设备上的模型进行个性化来提高全局FL模型的准确性。然而,如何平衡本地个性化和从其他节点学习是一个挑战[47,59]。另一种方法是联邦多任务学习[49],它在分布式设置中同时优化多个模型。然而,目前的联邦多任务学习方法[49,60]仅适用于支持向量机等凸模型,这限制了其在具有挑战性的HAR任务(如图像识别)中的应用。
在本文中,我们提出了ClusterFL,一个相似感知的联邦学习系统,可以达到较高的系统精度和较低的通信开销。ClusterFL设计的动机来自于一个关键的观察,即尽管存在异质性,但不同用户活动的数据分布可能具有显著的时空相似性[11,51]。基于对包含184个用户数据的6个HAR数据集的分析,我们表明在广泛的HAR应用中,这种相似性可以通过聚类结构捕获。
基于这一观察结果,我们提出利用用户数据的相似性来同时提高FL的模型精度和通信效率。首先,ClusterFL具有一种新颖的聚类多任务联邦学习公式。通过引入一个表示用户相似性的聚类指标矩阵,我们的新公式旨在最大限度地减少学习模型的经验损失,同时自动捕获不同用户数据之间的内在聚类结构。为了解决这个问题,我们提出了一种新的分布式优化框架,该框架基于交替方向乘法器(ADMM)[10],交替更新模型权值和聚类结构,直到收敛。此外,为了使ADMM方法适应FL设置,我们将学习过程分解为局部模型权重的更新,以实现节点的数据局部性。与之前基于训练后个性化的解决方案相比[12,27],我们的学习框架实现了相似节点之间的协作学习,适用于一般的非凸学习模型(如DNN和CNN模型)。其次,利用学习到的簇结构,ClusterFL集成了两种新的机制,即基于簇的离散者退出机制和基于相关性的节点选择机制,以降低通信开销。具体来说,服务器将删除每个集群中收敛速度较慢的离散者和与其他节点关联较小的节点,这被证明可以在保持整体精度性能的同时减少总体通信开销。我们使用我们自己收集的四个新数据集来评估ClusterFL在10个NVIDIA边缘设备的硬件测试上的性能,包括一个大规模的HAR数据集,涉及121个主题,使用智能手机应用程序以众包方式收集,以及三个实验室内的HAR数据集。我们的评估表明,通过捕获不同用户活动的异构数据中的聚类关系,ClusterFL在系统精度方面显著优于现有的几种机器学习范式,所提出的通信优化机制可以减少50%以上的通信开销。此外,在服务器和节点之间意外断开的动态网络条件下,ClusterFL的性能是健壮的。
我们的主要贡献总结如下:
-
我们提出了ClusterFL,一个相似感知的联邦学习系统,通过支持相似节点之间的协作学习来实现高模型精度。与现有方法相比,ClusterFL还通过基于学习到的集群结构的分簇离散者退出和基于相关性的节点选择来帮助降低总体通信开销。
-
为了理解ClusterFL核心的可聚性的影响,我们分析了两个公共HAR数据集和四个由总共184个用户的数据组成的新数据集。我们发现聚类关系在用户的HAR数据中广泛表现出来,可以利用聚类关系来提高联邦学习的模型精度。
-
我们收集了四个新的具有显著动态的HAR数据集,包括使用Android应用程序收集的大规模数据集和在室内环境中收集的三个HAR数据集
-
我们使用四个新的HAR数据集在NVIDIA边缘测试平台上进行了广泛的实验。我们展示了在动态系统配置和各种数据集下,与几个最先进的基线相比,ClusterFL的优越性能。
-
- 相关工作
人类活动识别(HAR)。机器学习已经越来越多地应用于人类活动识别领域[48,51,61]。基于手工特征[8,22]和深度神经网络[26,37,44]的各种算法已经被开发出来,以对不同的人类活动进行分类。这一领域的大多数工作都集中在需要在中央服务器上训练算法的集中式方法上,由于需要共享原始用户数据,这带来了重大的隐私问题。最近,在移动设备上运行深度学习模型方面取得了重大进展[31,63]。然而,每个终端设备上的标记数据通常不足以训练出一个好的模型。
联邦学习(FL)[19]是一种分布式机器学习方法,可以在设备上的大量分散数据上进行训练。一些现有的FL方法[9,29]旨在通过平均模型权重来为所有用户学习单个模型。然而,单一的学习模型通常具有有限的通用性,使其不太适合HAR应用程序[12]中的异构用户数据。为了解决这一问题,联邦迁移学习(FTL)被提出[12,15],通过对局部数据进行个性化来提高全局学习模型的准确性。但是,与ClusterFL相比,这种方法通常精度提高有限,不能有效利用大量用户数据之间的内在关系。此外,Smith等人[49]提出在FL设置下同时学习多个模型。然而,他们的方法只适用于凸模型,如支持向量机。相比之下,ClusterFL适用于一般的非凸模型(例如DNN和CNN)。以往对有效通信FL的研究要么从所有节点中选取离散节点(收敛较慢的节点)[9,35],要么集中在量化技术上[29,46],而量化技术不考虑不同节点数据之间的关系。ClusterFL利用在FL设置中学习到的固有集群关系来减少通信开销,同时保持整体精度性能。
HAR与联邦学习。联邦学习最近被应用于HAR以保护用户的数据隐私[12,15,50,60]。具体来说,Sozinov等人[50]利用FedAvg进行HAR,与集中式模型相比,其精度略差。Chen等[12]提出了一种用于帕金森病辅助诊断的联邦迁移学习框架,该框架首先执行FedAvg,然后在设备上构建相对个性化的模型。Feng等人[15]将FL应用于人类移动预测,并提出了一种微调的个人适配器来提高预测性能。然而,这些迁移学习方法都是基于FedAvg模型,没有利用节点之间的关系。Yu et al.[60]采用联邦多任务学习学习智能家居应用的上下文访问控制策略,仅适用于SVM等凸模型。与现有FL工作相比HAR, ClusterFL利用用户的相似性,不仅提高了FL模型的准确性,还降低了整体系统开销。此外,它还可以应用于各种HAR应用的一般深度学习模型。
-
- 动机
在本节中,我们将分析几个真实的HAR数据集,以激发ClusterFL的方法。我们首先研究了现实世界HAR数据集的聚类性,包括两个公共数据集和四个我们自己收集的新数据集(见第7节)。然后我们展示了基于数据的聚类性在相似用户之间学习的主要优势。
3.1 HAR数据的可聚性
不同用户的活动往往表现出一定程度的相似性,这可能源于被试者的生物特征(如性别、身高、体重等)、物理环境(如被试者的活动地点),甚至是传感器的偏差[6,23,64]。我们调查了表1中列出的六个实词HAR数据集的数据相似度,包括基于智能手机的公共人类活动识别(SHAR)数据集[5],公共异构HAR (HHAR)数据集[51];以及我们自己收集的4个新数据集(Depth, IMU, UWB, HARBox数据集)(见第7节)。
具体来说,我们使用来自不同用户的数据的霍普金斯统计量[17]来展示这些HAR数据集的聚类性,这是一个在0到1之间的统计度量,通过测量给定数据集由均匀分布产生的概率来量化数据的聚类趋势。霍普金斯统计值越高,意味着数据的聚类性越强。表1显示了每个数据集的霍普金斯统计量,该统计量是对同一活动的数据进行计算,然后在不同活动之间进行平均。这表明,所有六个HAR数据集的Hopkins统计量都超过0.5,这意味着它们在不同主题的数据之间表现出聚类关系。特别是SHAR、HHAR、Depth和HARBox数据集具有较强的聚类倾向,Hopkins统计值大于0.7。

表1:6个不同HAR数据集的Hopkins统计数据。霍普金斯统计值越高,集群性越强。
在使用主成分分析将特征维数降至2D后,我们通过绘制HHAR数据集中的“行走”数据来进一步可视化数据分布。如图1所示,不同受试者的数据之间存在明显的聚类关系,同一型号智能手机的数据被归为同一个聚类。
3.2聚类性对学习的影响
在本节中,为了激发利用用户的聚类关系的方法,我们设计了一种称为“集中式聚类”的方法,其中我们使用𝐾-means以基于训练数据的集中式方式对主题进行聚类,然后使用属于该集群的所有主题的数据为每个集群训练一个模型。我们将集中式聚类的准确性与四种典型的机器学习范式进行了比较:局部学习,集中式单模型学习(集中-单一),联邦平均(FedAvg)和联邦迁移学习(FTL)使用HHAR数据集。在局部学习中,每个节点使用自己的数据训练一个模型,由于局部数据有限,可能会出现过拟合。在集中式学习中,服务器从所有节点收集数据并学习单个全局模型,这通过共享原始用户数据而带来了重大的隐私问题。FedAvg是谷歌[9,49]提出的一种经典的FL方法,节点只向服务器上传模型权重,通过平均模型权重生成一个模型。联邦迁移学习[12,15]是一种最先进的FL方法,旨在通过根据不同用户自己的数据对学习到的单个FL模型进行个性化来提高FedAvg的性能。我们使用来自HHAR数据集的9名受试者的数据评估了上述方法,该数据集使用三种型号的智能手机收集。这项任务是利用加速度计和陀螺仪对六种人类活动进行分类。表2总结了使用4层神经网络的平均精度。

表2:不同范式的准确性比较。
首先,我们观察到FedAvg不能收敛到集中模型,并且表现得比局部学习还要差。这并不奇怪,因为FedAvg本质上是集中式学习的分布式近似,当节点的数据是异构的时,它的性能很差[36,50]。此外,尽管联邦迁移学习(FTL)旨在为异构用户定制不同的模型,但由于没有明确考虑某些节点的相似性,精度提高(0.94%)仍然有限。集中式单模型学习比上述三种方法表现更好,因为它在从所有科目收集的数据中进行了最大数量的训练。最后,集中式聚类方法的平均准确率达到73.17%,优于集中式单一方法。尽管这种方法需要访问所有数据,并且在分布式环境中不实用,但它证明了利用节点的聚类关系来提高准确性的好处。该案例研究还提出了两个主要观点。首先,如果可以以分布式的方式捕获节点的集群关系,那么自然需要一个高效的FL范式共享数据相似性的节点将在学习中协作,减轻来自其他节点的噪声/异常值的影响。另一个关键优势是集群关系提供了减少通信开销的机会,因为在分布式学习过程中,可以提前删除与其他无关的离群值,以避免冗余通信。
-
- 方法
我们现在介绍ClusterFL,这是一个实用的联邦学习系统,旨在利用一些节点之间的内在相似性来提高人类活动识别的模型准确性和通信效率。我们首先简要讨论了ClusterFL的应用场景,然后描述了系统架构。
应用程序场景。ClusterFL是为广泛的应用程序设计的,在这些应用程序中,用户活动以连续和纵向的方式被跟踪。例如,在阿尔茨海默氏症患者监测场景中[33,62],可穿戴式和环境传感器持续跟踪患者的日常活动,如室内/室外时间、睡眠等,这些都是早期阿尔茨海默氏症诊断的重要数字生物标志物[1]。其他具有代表性的应用包括健身跟踪[28]、家庭日常监测[8]和社交距离检测[57]。在这些应用中,个人设备可以积累一定时间的数据,并使用它来训练机器学习模型进行活动识别。对于此类场景下的每个协作分布式训练会话,设备上的ClusterFL可以通过云进行通信,学习个性化的本地模型。由于用户活动的数据分布和特征可能会随着时间的推移而变化,因此ClusterFL可以定期(例如,每天)运行,以使用最近积累的数据更新本地模型。
系统架构。ClusterFL具有一种新颖的相似性感知联邦学习框架,可以最大限度地减少学习模型的经验训练损失,同时自动捕获不同节点数据之间的内在聚类结构1。具体而言,我们通过引入表示节点相似度的聚类指标矩阵,提出了一个新的聚类多任务联邦学习问题,并提出了一种分布式解决方案,使用交替优化技术迭代更新节点的模型权重和聚类指标矩阵。通过该框架,同一集群中的节点将通过最大化模型相关性来协作提高性能,并且服务器将能够在少量迭代中学习节点之间的集群关系。其次,基于学习到的簇结构,ClusterFL将利用两种新的机制,即基于簇的离散者退出机制和基于相关性的节点选择机制,在保持局部模型准确性的同时减少通信开销。具体来说,服务器将丢弃每个集群中收敛速度比其他节点慢的离散节点。此外,服务器将删除同一集群中与其他节点关联较小的节点。在这种情况下,与服务器交互的节点将更少,从而可以减少总体通信时间,同时保留“更重要”的节点来执行ClusterFL。
图2显示了ClusterFL的整体系统架构。具体而言,每一轮通信由以下步骤组成:(1)节点将上传其当前模型权重和更新服务器的训练损失。(2)服务器将通过优化框架使用聚类指标矩阵量化模型权重之间的关系。因此,在联邦学习的早期阶段,服务器可以动态地将节点分组为具有联合数据分布的集群。(3)服务器根据学习到的聚类指标矩阵,更新协同学习变量供节点更新模型使用,删除每个集群内收敛速度较慢的离散节点和相互关系较低的节点,以降低通信开销。(4)将服务器学习到的聚类指标矩阵、协同学习变量和一个drop指标发送回每个节点。(5)节点将根据接收到的信息更新模型,并根据drop指示器决定是否在下一轮继续学习。
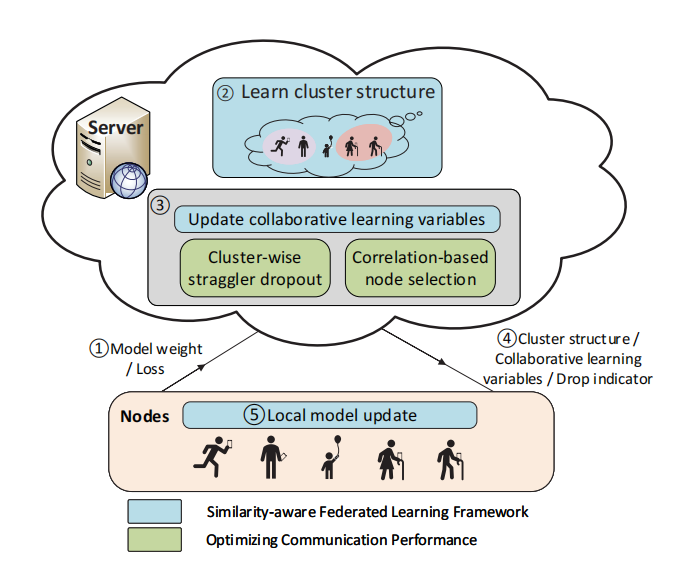
图2:ClusterFL的系统架构
上述步骤将迭代运行,直到收敛,即聚类多任务联邦学习问题的目标函数变化不大。如前所述,为了适应用户活动的动态变化,这种分布式训练过程可以使用最近收集的数据周期性地重复(例如,每天)。
5、相似感知联邦学习框架
ClusterFL的设计基于一个关键的观察,即在人类活动识别中,许多应用程序的数据由于受试者的生物特征、物理环境甚至传感器偏差而具有固有的聚类关系,可以利用这些聚类关系来提高整体模型的精度。因此,我们的目标是捕捉节点之间的聚类关系,并为同一聚类中的节点聚合模型权重,以提高精度。
5.1问题的制定
ClusterFL采用了一种新颖的联邦学习框架,可以最大限度地提高学习模型的准确性,同时通过引入聚类指标矩阵自动捕获不同节点数据之间的内在相似性。具体来说,我们提出了一个聚类多任务联邦学习问题:
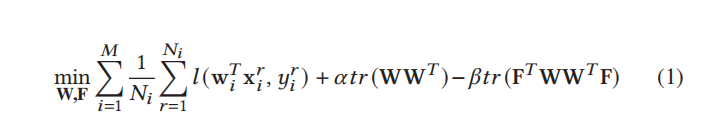
•M为总涉及节点数,𝑁𝑖为节点i中的训练数据样本数,𝛼和𝛽为超参数,𝛼≥𝛽>0.
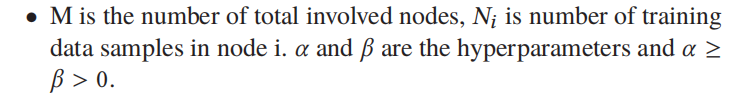
(x𝑟𝑖,𝑦𝑖𝑟)∈R𝐷×R是𝑟-th培训一双𝑖-th节点;W = [au:], w𝑀]𝑇∈R𝑀×𝐷是待估计的权值矩阵,其中每个局部模型是一个活动分类器;𝑙为局部模型的损失函数。

•F∈R𝑀×𝐾为正交聚类指标矩阵,如果节点i属于第j个聚类,则𝐹𝑖,𝑗= 1√𝑁𝑗,否则𝐹𝑖,𝑗= 0。其中𝐾是集群的数量,𝑁𝑗表示第j个集群中的节点数量。我们强调,在我们提出的优化框架中,我们不需要知道K,因为在第5.3节中,F的离散约束将被放松以获得它的连续解。

在上述公式中,第一项是所有节点上活动识别的经验误差之和;第二和第三项可以写成(𝛼−𝛽)𝑀𝑖= 1 | | w𝑖| 2 | 2 +𝛽𝐾𝑗= 1 𝑣∈年代𝑗| | w𝑣−w𝑗| 2 | 2,由模型L2-norm正规化的权重,以防止过度学习和𝐾-means集群整个星团内的距离模型重量降到最低。与FedAvg仅为所有异构数据节点提供一个模型相比,我们的公式将为每个节点定制一个模型,同时保留同一集群中节点的模型权重的相似性。在这种情况下,每个节点的模型将根据其本地数据并参考其他节点的模型进行更新,这将通过在集群内协作学习来显著提高个体性能。

交替优化。在联邦学习设置下,我们在问题(1)中有两个变量W和F需要求解。很容易看出(1)不是wr t W和f的联合凸,同时求解它们是非常困难的。为了解决这一挑战,我们建议使用交替优化方法[7]来解决(1)。在这种情况下,我们将为每次优化的外部迭代固定W或F,并更新另一个变量,在这两个变量的优化之间交替,直到收敛。算法1显示了节点和服务器之间交替优化的集中视图。在第5.2节和第5.3节中,我们将分别介绍如何分布式优化节点的模型权重W以及如何在联邦设置中学习它们的集群结构F。

5.2优化模型权值
当F固定时,问题(1)w.r.t W等价于:
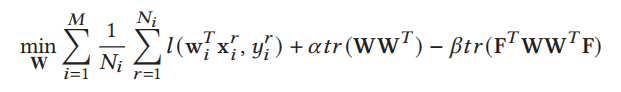
在这里,我们建议使用乘法器的交替方向法(ADMM)方法[10]更新w𝑖(i = 1,…, M)在不共享数据样本信息的情况下分布在节点上。ADMM的思想是在增宽的拉格朗日L𝜌中固定两个变量,并更新剩余的变量,这将以交替或顺序的方式运行。我们注意到,尽管ADMM被广泛用于统计学习问题的分布式优化,但在联邦设置中应用它来优化模型权重W并不是一件简单的事情。

特别地,我们首先需要制定一个新问题,其中两个决策变量受线性约束,以保持一致使用标准ADMM配方。因此,我们定义Ω = F𝑇W∈R𝐾×𝐷,将问题(1)重新表述如下:

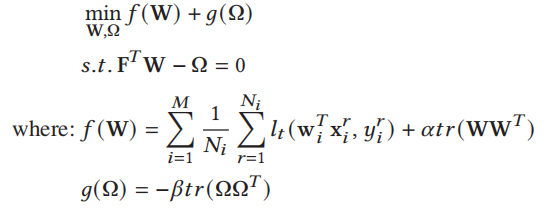
而且,在联邦学习设置中,嵌入在𝑓𝑖(w𝑖)中的经验损失函数需要根据不同节点的数据(x𝑖,y𝑖)进行局部计算。因此,我们必须将W的最小化步骤分解为局部模型权值W的更新组合𝑖(i = 1,…, M),以保持数据的局部性。最后,ADMM更新的迭代t+1包括以下步骤:

-
节点更新(算法1中的第4-5行):每个节点将基于其本地数据(x𝑖,y𝑖)、集群结构F和来自服务器的协作学习变量Ω, U并行优化(例如,使用梯度下降方法)其模型权重w𝑖。
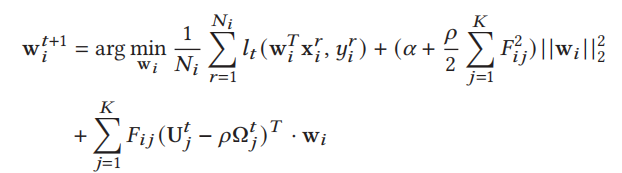
-
服务器更新(算法1中的第6-10行):服务器将进一步利用新更新的节点W的模型权重和集群结构F(在5.3节中进行了优化)来更新协作学习变量Ω, u,对于j = 1,…,K:
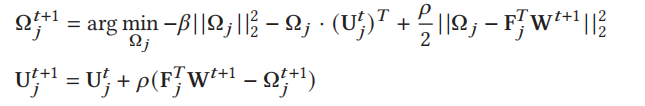
因此,在节点与服务器的一轮通信中,节点需要将更新后的模型权值w𝑖上传到服务器,服务器将权值聚合后向所有节点广播F, Ω, U。这里U𝑗∈R1×𝐷(𝑗= 1,…,𝐾)是ADMM增广拉格朗日引入的对偶变量。

5.3了解集群结构
当W固定时,问题(1)w.r.t F可以看作是一个关于节点模型权值W的𝐾-means聚类问题(以矩阵形式表示)。在服务器上使用节点的模型权值学习节点的聚类关系时,存在两个挑战:如何量化模型权值的相似性,以及如何在不知道集群K个数的情况下动态优化集群结构。
模型权重的相似性。如[16,25,45]所示,基于距离的聚类方法仅适用于具有凸损失函数的模型,在对机器学习模型的相似性建模方面存在严重的局限性。因此,对于一般具有非凸损失函数的DNN模型,我们选择使用Kullback-Leibler divergence (KLD)来度量节点模型的相似度。KLD[30]用于度量一个概率分布与另一个概率分布的不同程度,广泛应用于知识蒸馏[20,40]、模型自适应[58,59]和相似性度量[13,21,52]。两个DNN模型(w𝑖,w𝑗)的KLD可表示为:
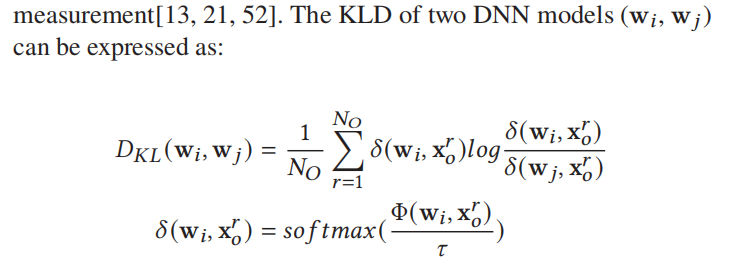
其中Φ(w𝑖,x𝑟𝑜输入数据)表示模型w𝑖在x𝑟𝑜上的预softmax输出。节点i和节点j的KL散度越小,说明模型之间的关系越密切。然后我们计算任意两个模型之间的KL散度,从而得到KL散度矩阵

优化集群关系。接下来,服务器将使用节点的KL发散矩阵D模型学习集群指标矩阵F。根据5.1节定义,F满足约束𝐹𝑖,如果节点i属于第j个集群,则𝑗= 1√𝑁𝑗,否则𝐹𝑖,𝑗= 0。这个约束定义了一个离散可行集,它不仅需要已知的簇总数K,而且使得寻找最优F NP-hard[41]。因此,我们选择放松F的这个约束,得到一个连续解,量化所有节点之间的相关性,然后恢复F。根据[14],主成分是𝐾-means聚类的离散聚类成员指标的连续解。设节点间共有M个簇,则P = Q𝑀−1Q𝑇𝑀−1∈R𝑀×𝑀为F的连续解,其中Q𝑀−1 = (v1,…, v𝑀−1)使用主成分分析(PCA)收集D的𝑀−1主成分。
6、优化通信性能
在传统的FL系统中[9,38],节点与服务器之间需要进行大量的更新迭代,这使得通信开销成为学习过程的瓶颈。先前一些关于通信有效FL的研究主要集中在模型压缩和量化技术[29,46],当通信轮数较大时,这种方法并不总是能降低总通信延迟。还有一些方法从所有节点中选择离散节点(收敛较慢的节点)并同时丢弃它们[9,35],没有考虑离散节点之间的差异。在这项工作中,我们的目标是利用ClusterFL学习的固有簇关系在FL过程中动态删除节点,同时保持整体精度性能。
我们的关键思想是服务器可以利用学习到的集群结构来删除一些节点,以减少通信延迟。特别是,我们框架中的集群结构通常会在早期学习,例如,在几个通信回合中。图3显示了集群指示器矩阵F的更新,其中我们使用F的l1范数来显示F如何随着F更新的次数而变化,使用深度数据集(参见第7节)。这里的任务是使用从三个环境(室外/黑暗/室内)收集的深度图像来识别五种手势。我们可以看到,即使ClusterFL总共更新了25次F,但在更新了8次后F几乎没有变化。它清楚地表明,通过第8次更新中的F,服务器已经捕获了节点之间的集群关系,因此能够使用这些信息来优化通信性能。
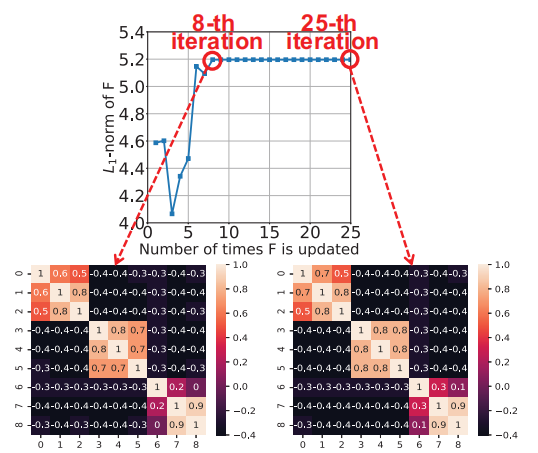
图3:更新多次后可以捕获节点(F)的集群结构。
在这一关键观察的激励下,我们提出了两种新的机制来减少通信开销,同时保持学习模型的准确性。首先,使用聚类关系和节点丢失更新,服务器将对集群中的离散者进行分类并尽早丢弃它们。其次,服务器将删除与同一集群中其他节点的数据相关性较小的节点。
6.1基于集群的离散掉线
我们首先用一个例子来说明在聚类中丢弃离散者的关键优势。图4显示了深度数据集“室外”和“室内”环境中6个节点的丢失更新。如图4a所示,我们的聚类离散者退出可以动态地识别每个聚类中的离散者(即,在第75轮从“室外”聚类中退出一个节点,在第85轮从“室内”聚类中退出另一个节点)。相反,基线识别来自所有节点的掉队者并同时丢弃它们(图4b),导致集群“室内”中只有一个节点被丢弃。这个例子表明,在簇内识别离散者更加灵活和有效,在第8节的实验中也证明了这一点,在保持整体精度性能的同时减少了通信开销。接下来,我们讨论如何测量在特定集群中,节点识别离散节点的收敛性能。对于包含𝑁𝑗节点的集群j (j = 1,…,K),我们定义集群中节点q (q = 1,…,𝑁𝑗)在最近一次𝑇𝑐迭代中的平均收敛速度𝛾𝑞:
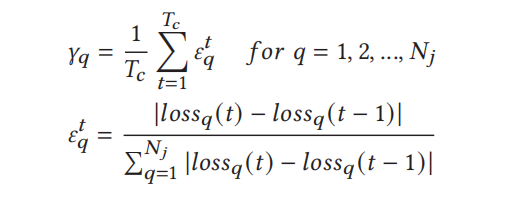
这里𝜀𝑡𝑞是节点q在第t次迭代时相对于集群j中的其他节点的归一化损失更新;𝛾𝑞是𝜀𝑡𝑞在最新的𝑇𝑐迭代中的平均值;𝑇𝑐是确定离散者的迭代阈值,其中较大的𝑇𝑐意味着获得更平滑的损失更新以过滤掉干扰,同时也推迟迭代以识别离散者。
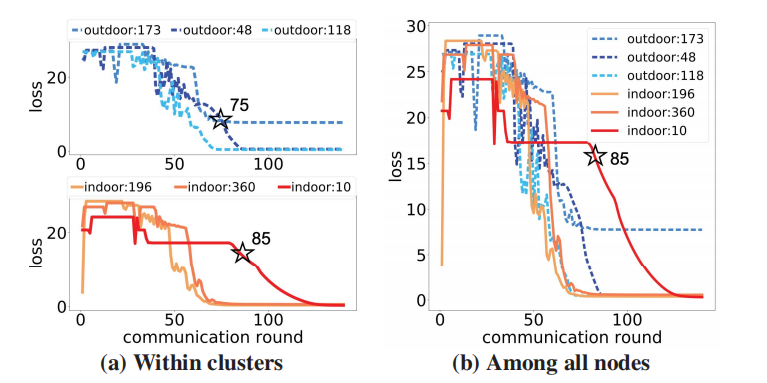
图4:识别集群内的掉队者(a)和所有节点之间的掉队者(b)。我们的集群掉队者dropout可以动态地识别和丢弃每个集群中的掉队者。“indoor:196”表示节点有196个来自环境“indoor”的数据样本。
如果一个节点被服务器丢弃,它将停止与服务器通信,而是在自己的数据和最后更新的模型上进行本地训练,直到本地收敛。由于剩下的节点已经接近收敛,它们的模型更新不会因为去掉离散点而受到实质性的影响。
6.2基于相关性选择节点
在本节中,我们提出了一种基于观察的新方法,即如果集群中的节点子集彼此之间的相关性更强,它们将从协作学习中受益更多。如图5a所示,集群“室外”中的节点0和集群“室内”中的节点6与集群中其他节点的相关性较弱。如果我们在中间阶段删除它们,如图5b所示,同一集群中节点的平均精度只会受到轻微的下降。但是,如果我们选择在同一迭代中删除节点1和节点7,则平均准确率将从89.00%大幅下降到84.44%。因此,服务器将根据节点与其他节点的相关性选择删除节点。
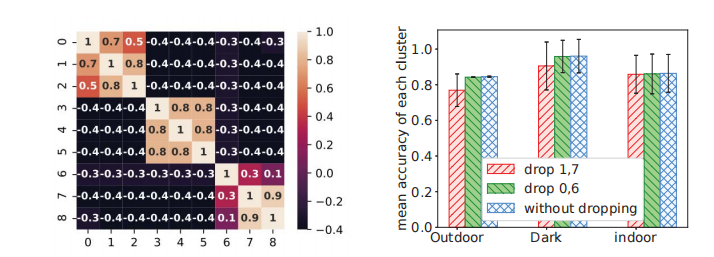
图5:基于相关性的退出效果。左:三个块分别表示集群“室外”,“黑暗”,“室内”。与节点1和节点7相比,节点0和节点6与集群中其他节点的相关性较小。右:删除不太相关的节点后,精度性能略有下降。
具体来说,服务器将使用F的相关矩阵为所有节点计算一个重要性向量𝜎,以衡量它们与每个集群中其他节点的相关程度。假设节点q在包含𝑁𝑗节点的集群j中,我们定义节点q的重要性度量𝜎𝑞如下:
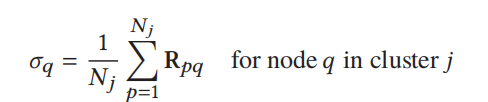
如图5所示,具有较大𝜎𝑞的节点(例如,节点1具有𝜎1 = 0.833,而节点0具有𝜎0 = 0.733)意味着它与同一集群中的其他节点具有较高的相关性。然后,服务器将从大到小排序所有集群的𝜎𝑞,并在迭代𝑇𝑡ℎ𝑟𝑒𝑠ℎ时丢弃最后的𝑀𝑑节点。这样,与服务器通信的节点总数将减少为𝑀−𝑀𝑑。然后,被删除的节点将根据上次更新在本地训练它们的模型,并且不与服务器通信。最后,由于与服务器交互的节点数量较少,因此总通信时间会减少,而在学习过程中保留相对重要的节点,从而提高整体性能。在这里,丢弃节点的数量𝑀𝑑和丢弃迭代𝑇𝑡ℎ𝑟𝑒𝑠ℎ都将基于总体精度和通信性能之间的理想权衡来决定。𝑀𝑑越小,需要丢弃的节点就越少,通信损耗和精度损失就越小。较小的𝑇𝑡ℎ𝑟𝑒𝑠ℎ意味着更早地丢弃节点,导致更多的通信减少和准确性损失。
7 .数据收集
我们在现实环境中收集了四个新的人类活动数据集(表3)。第一个数据集是通过众包方式使用Android App收集的大规模数据集。其他三种是在室内环境中收集的我们使用自收集数据集的原因如下。首先,现有的HAR数据集大多缺乏受试者ID,并且混合了所有受试者的数据,这并不适合FL设置。其次,目前的HAR数据集主要是在动态较少的受控(有时相同)环境中收集的,这与用户、设备和环境高度多样化的现实应用程序不一致。为了解决这个问题,我们在具有显著动态的不同环境中收集了四个新的HAR数据集。最后,目前还没有在现实环境中收集的大规模公共HAR数据集。使用一款新的智能手机App,我们收集了总共121名用户77种不同型号的个人智能手机的数据。我们将向研究界发布这个大规模的高质量数据集。大规模HARBox数据集:近年来,智能手机越来越多地用于监测人们的日常活动或健康状况[18,22]。我们开发并发布了一款名为“HARBox”的Android应用程序,通过众包的方式,利用用户自己的智能手机收集HAR数据。当用户进行行走、跳跃、打电话、挥手、打字等五种日常生活活动(ADL)时,App收集用户智能手机的9轴IMU数据。用户将通过在执行每个活动之前和之后单击应用程序中显示的“开始”和“结束”按钮来标记活动。在从总共137个提交的数据中去除无效和重复的数据后,我们最终获得了来自121个用户(17-55岁)的有效数据提交,他们使用77种不同的智能手机型号。我们以50Hz重新采样原始IMU数据,滑动时间窗口为2s,并为每个数据样本生成900维特征。该数据集更大、更异构,可用于评估不同方法的可伸缩性和鲁棒性。
8实施与评估
我们在PC上设计并实现了一个ClusterFL原型(作为服务器),7个NVIDIA Jetson TX2和3个Jetson AGX Xavier(作为节点)。硬件设置如图10所示。PC (Intel Core i7-9700 CPU 3.0GHz × 8)运行Ubuntu 18.04.5, TX2(6核ARM CPU)和Xavier(8核ARM CPU)运行Ubuntu 18.04。服务器与节点之间通过TP-link TL-SG2016K交换机连接。代码使用Python3实现。
我们的评估集中在ClusterFL的三个方面,包括动态系统性能、不同数据集上的性能和不同模型深度。对于三个小规模数据集的实验,每个节点只在一个边缘设备(TX2或Xavier)上进行训练,以测量它们的能量消耗。功耗采用板载功率监测传感器TIINA3221x[2]测量,仅计算CPU功耗。对于大规模的HARBox数据集,我们让每个CPU运行多个节点以合并多达120个节点。
8.1.2可伸缩性
为了评估ClusterFL的可伸缩性,我们使用来自大规模HARBox数据集的数据评估了不同数量节点(60、90、120)的性能。
整体的精度。图13a显示了不同方法在HARBox数据集上的准确性。一般情况下,随着节点数量的增加,集中学习的平均准确率略有下降,这表明了受试者数据的异质性。此外,FedAvg表现最差,因为它没有收敛到中心化模型。在所有配置下,ClusterFL的性能都优于FTL、local learning、FedAvg,其精度甚至超过了60和90节点的集中学习,说明了ClusterFL的可扩展性。此外,集中学习的节点精度的标准差对于60、90和120节点的配置非常大,而ClusterFL在节点之间的精度变化明显较小,这意味着ClusterFL可以提高大多数节点的模型精度。
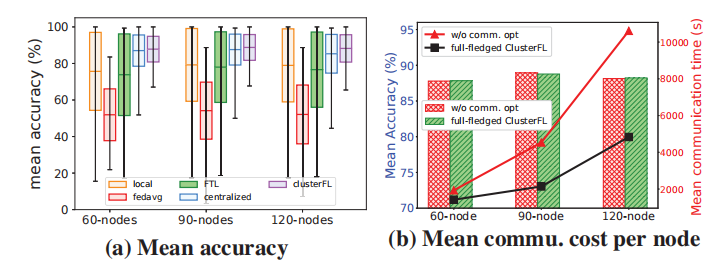
图13:随着节点数量的增加,每个节点的平均精度和通信成本。
通信开销。图13b显示了在不同节点数量的情况下,使用或不使用我们在第6节中提出的两种机制时,每个节点的平均精度和平均通信成本。结果表明,随着节点数量的增加,节点的平均通信成本急剧增加。而我们的两种通信优化机制在不同的系统设置下,在保持精度提升的同时,可以节省50%以上的通信时间,验证了ClusterFL的可扩展性。
不同方法的比较。图12a, 12b和12c描绘了三个数据集的节点上训练样本数量相同(平衡)和不同(不平衡)时的精度性能。不平衡配置的动机是,在现实世界的人类活动识别应用程序中,由于环境异质性,节点通常具有显著不同的数据。一般来说,每种方法的平均准确率随着训练样本数量的增加而增加;当节点数据量的间隔变大(即节点更加倾斜)时,由于某些节点的训练样本量非常小,精度性能会下降。表4总结了每个数据集所有平衡数据设置的平均精度,使用不同的方法;表5总结了不平衡数据设置的情况。ClusterFL在不同的设置下优于local/FedAvg/FTL,甚至在某些节点的数据和学习模型配置下优于集中式学习(例如在IMU数据集的平衡数据设置下为5.99%)。此外,由于节点异构性,FedAvg无法收敛到三个真实HAR数据集的集中模型。

图12:UWB、IMU和Depth数据集的精度性能比较。ClusterFL在各种设置下优于local/FedAvg/FTL,甚至在IMU数据集上优于集中式学习。
不同数据集上的结果。具体来说,对于UWB数据集,集中式学习表现最好(例如,在不平衡的情况下,92.71%设置),因为能够对所有节点的数据进行训练。而且,ClusterFL(在不平衡设置下为92.71%)退化到集中学习并接近其性能。对于IMU数据集,ClusterFl(例如,在平衡设置下为90.47%)优于包括集中式模型在内的其他方法(84.48%)。主要原因是,所有范式都使用只有两个完全连接层的浅机器学习模型。在这种情况下,单一且规模较小的集中式模型不能很好地拟合不同节点的数据分布。然而,ClusterFL可以通过为不同节点定制模型,同时支持相似节点之间的协作学习,进一步提高精度(90.47%)。使用深度学习模型的性能比较将在第8.3节中展示。对于深度数据集,集中式模型优于其他方法(在不平衡数据设置下的96.82%),而其分布式实现FedAvg(63.75%)未能收敛到同一模型。在这种情况下,ClusterFL(70.68%)优于本地学习、FedAvg和不访问用户数据的FTL。系统开销。我们使用NVIDIA测试平台上的三个数据集来评估系统开销,以展示第6节中提出的ClusterFL两种通信优化机制的有效性。表6显示了节点的设置以及通信优化机制所删除的节点。
图15显示了未进行通信优化(w/o comm. opt)和成熟ClusterFL的配置下,节点的平均通信时间、平均计算时间、能耗和准确率的变化。对于这三个数据集,ClusterFL结合了集群离散掉线和基于相关性的节点选择,在保持几乎相同的精度性能的同时,减少了20%以上的通信延迟。此外,完整的ClusterFL可以为IMU、UWB和深度数据集分别节省约50%、16%和12%的能量消耗,验证了设计有效的边缘设备通信优化机制的意义。
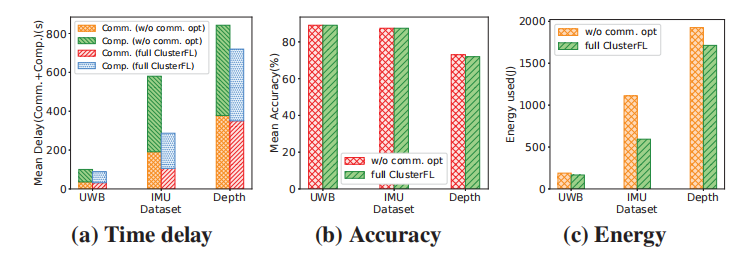
图15:对UWB、IMU、Depth数据集进行ClusterFL通信优化或不进行通信优化的性能。W /o通信. opt表示不进行通信优化。
8.3不同模型深度的性能
在本节中,我们修正了节点的数据配置,并改变了学习模型的深度,以评估不同范例的准确性性能。具体来说,我们使用IMU数据集,每个节点上的数据样本数量分别为10、13、13、49、19、29、31。我们尝试为所有范例使用1、2、4个全连接层的模型。图16总结了精度结果。基本上,当模型越深(从1层到4层),所有方法的准确性都有提高的趋势。一个重要的观察是,当使用1层模型时,集中学习不能拟合所有节点,甚至比局部学习差;然而,随着模型的深入,其性能逐渐接近并超越局部学习。由于数据的异质性,FedAvg无法达到与集中式学习相同的精度性能,并且表现不如局部模型。而且,ClusterFL在不同的学习模型下具有更“稳定”的精度表现,并优于其他学习模型其他方法。然而,当学习模型足够大时,在所有节点数据上训练的单一集中式模型可能会获得最佳性能,这与8.2节中UWB和深度数据集的结果相对应。这些结果也强调了在HAR应用中选择合适的学习模型的重要性。
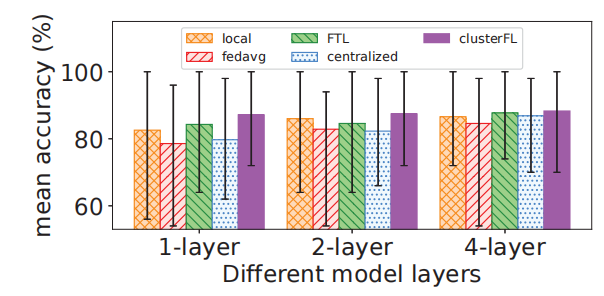
图16:IMU数据集对不同深度模型的精度
9、讨论
ClusterFL的收敛。在我们的实验(第8节)中,ClusterFL被证明可以使用不同的机器学习模型(例如DNN和CNN模型)收敛于四个真实世界的HAR数据集。现在我们对ClusterFL的收敛保证提供一些见解。首先,ADMM更新的惩罚超参数𝜌(见章节5.2)对ClusterFL的收敛起着重要作用。具体来说,当𝜌大于阈值时,ClusterFL可能会收敛(至少收敛到一个静止点);否则,问题(1)的客观值就会发散。其次,我们的实验表明,模型初始化(例如,随机种子或零初始化)不会对学习模型的性能产生重大影响。我们将把研究不同初始化对收敛过程的影响作为未来的工作。未来的工作。在这里我们讨论这项工作的一些扩展。首先,在避免在学习过程中暴露用户原始数据的同时,在ClusterFL中传输的模型更新仍然可能揭示用户活动的某些信息[27,56]。在未来,我们将研究如何集成隐私保护技术[55],并调查隐私和效用之间的权衡[3,53]。其次,我们将把ClusterFL扩展到更广泛的应用程序,其中节点的数据表现出内在的相似性和局部性。例如,在健康监测[4]和道路交通预测[39]应用程序中,节点(例如用户或汽车)的数据由于空间接近性、设备/汽车的模型、用户习惯等原因显示出具有时空相似性。因此,ClusterFL可以应用于这些应用程序,以实现相似节点之间的协作学习。第三,目前在我们的框架中,我们只考虑服务器和节点之间的交互,而没有考虑节点(客户端)之间的直接通信。我们将把我们的方法应用于其他网络拓扑作为未来的工作。
10、结论
在本文中,我们提出了ClusterFL,一个用于人类活动识别的相似性感知联邦学习系统。ClusterFL具有新颖的联邦学习框架,支持相似节点之间的协作学习,并基于学习的集群结构集成了两种有效的通信优化机制。我们使用四个新的真实世界数据集进行的评估表明,ClusterFL优于几种学习范式(例如,局部学习、FedAvg、联邦迁移学习的21.04%、6.46%、5.41%),有时甚至接近集中学习的准确性。此外,ClusterFL可以减少50%以上的通信延迟,代价是精度损失很小。















 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









