






一、引言
一个小小学术比赛交叉赛道的技术佐料,目的是给队友爬下来的某音平台下的三农博主进行分类,思路是根据爬取的每个博主的10个标题,先合并成无空格的标题合并文本,然后对这段文本进行预处理(停用词等)、分词,计算文本相似度,最后进行聚类。
整体文章的很多代码和思路借鉴了深度学习与文本聚类:一篇全面的介绍与实践指南-CSDN博客,但是没有用到里面的深度学习模型训练,仅仅是对文本进行了聚类。关于更好的预处理方法和可视化方法,欢迎大家提出!
二、文本聚类
文本聚类是将文本数据根据其内容的相似性进行分组的过程。G老师给出的整体思路大致如下:
1. 数据预处理:对文本数据进行预处理,包括文本清洗、分词、去停用词、词干提取或词形还原等操作。这些操作有助于减少数据的噪声和冗余信息,提取出文本数据的有效特征。
2. 特征表示:将文本数据表示成计算机可以处理的形式。常用的文本特征表示方法包括词袋模型(Bag-of-Words)、TF-IDF(词频-逆文档频率)等。这些方法将文本数据转换成向量表示,以便进行后续的计算和分析。
3. 聚类算法选择:选择合适的聚类算法对文本数据进行聚类。常用的文本聚类算法包括K均值聚类、层次聚类、密度聚类等。不同的聚类算法有不同的特点和适用场景,需要根据具体情况选择合适的算法。
4. 聚类模型训练:根据选择的聚类算法,对预处理和特征表示后的文本数据进行聚类模型的训练。聚类模型的训练过程就是根据文本数据的特征将数据分成若干个类别的过程。
5. 聚类结果分析:对聚类结果进行分析和评估,检查每个类别的文本数据是否具有一定的内在相似性,是否符合预期。可以通过聚类结果的可视化、评价指标(如轮廓系数、互信息等)等方法来进行分析和评估。
6. 参数调优:根据聚类结果的分析和评估,调整聚类算法的参数或选择不同的算法,重新训练模型,直到得到满意的聚类结果。
三、项目处理
(一)数据集准备
数据集是队友在某音的数据分析网站上爬取的,标签结构如下:
序号,博主名称,性别,地区,年龄,MCN机构,认证信息,达人简介,粉丝总数,粉丝团人数,带货口碑,直播带货力,视频带货力,粉丝量级,主营类型1,主营类型2,带货水平,带货信息1,带货信息2,直播场次_近30天,平均开播时长_近30天,直播累计销量,直播累计销售额_近30天,视频数量_近30天,平均视频时长_近30天,视频累计销量_近30天,视频累计销售额_近30天,直播省级粉丝,直播市级数据,视频省级粉丝,视频市级粉丝,商品1,商品2,商品3,商品4,商品5,商品6,商品7,商品8,商品9,商品10,商品11,视频1,视频2,视频3,视频4,视频5,视频6,视频7,视频8
(二)import packages
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import TruncatedSVD
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from keras.layers import Input, Embedding, Flatten, Dense
from keras.models import Model
from keras.optimizers import Adam
from sklearn.cluster import KMeans
from sklearn.metrics.pairwise import cosine_similarity(三)预处理
1. 合并视频列,删除无视频信息的博主,去除视频标题中的空格
# 处理博主csv文件
import pandas as pd
# 读取原始CSV文件
df = pd.read_csv('data1.csv')
# 只保留第一列博主名称,并将视频1到8列的文字合并在一起放在第二列
df['视频合并'] = df[['视频1', '视频2', '视频3', '视频4', '视频5', '视频6', '视频7', '视频8']].apply(lambda x: ' '.join(x.dropna().astype(str)), axis=1)
# 仅保留博主名称和合并后的视频列
df_new = df[['博主名称', '视频合并']]
# 把没有视频信息的博主删除
df_new.loc[:, '视频合并'] = df_new['视频合并'].str.replace(' ','')
df_new = df_new.dropna(subset = ['视频合并'], how = 'all')
# 使用 apply 方法删除第二列中完全为空的行
df_new = df_new[df_new['视频合并'].apply(lambda x: len(x) > 0)]2. 去除可能影响分类的关键词
在这里除去了三农相关的关键词,因为博主都是三农领域博主,如果不去除三农分词,可能会导致不同博主视频合并文本相似度过高。
# 文本预处理:除去三农、农村等关键词
df_new.loc[:, '视频合并'] = df_new['视频合并'].str.replace('三农','')
df_new.loc[:, '视频合并'] = df_new['视频合并'].str.replace('农村','')
df_new.loc[:, '视频合并'] = df_new['视频合并'].str.replace('农业','')
df_new.loc[:, '视频合并'] = df_new['视频合并'].str.replace('乡村','')
df_new.loc[:, '视频合并'] = df_new['视频合并'].str.replace('农','')
print(df_new['视频合并'])
df_new['视频合并'].to_csv('视频合并.csv')3. 去除停用词
这里停用词表我采用类似最全中文停用词表整理(1893个)-CSDN博客,形成了一个自己的txt。如有需要可以复制。
import jieba
from zhon.hanzi import punctuation
# 读取停用词表
stopwords_path = '停顿词.txt' # 停用词表文件路径
stopwords = set()
with open(stopwords_path, 'r', encoding='utf-8') as f:
for line in f:
stopwords.add(line.strip())
def chinese_word_cut(text):
# 使用jieba进行中文分词,并过滤掉停用词和标点符号
words = jieba.cut(text)
return ' '.join([word for word in words if word not in stopwords and word not in punctuation])
# 对标题文本进行中文分词和清洗
df_new['视频合并'] = df_new['视频合并'].apply(chinese_word_cut)下面是一个停用词表,可复制成自己的txt放在项目里。
!
"
#
$
%
&
'
(
)
*
+
,
-
--
.
..
...
......
...................
./
.一
.数
.日
/
//
0
1
2
3
4
5
6
7
8
9
:
://
::
;
<
=
>
>>
?
@
A
Lex
[
\
]
^
_
`
exp
sub
sup
|
}
~
~~~~
·
×
×××
Δ
Ψ
γ
μ
φ
φ.
В
—
——
———
‘
’
’‘
“
”
”,
…
……
…………………………………………………③
′∈
′|
℃
Ⅲ
↑
→
∈[
∪φ∈
≈
①
②
②c
③
③]
④
⑤
⑥
⑦
⑧
⑨
⑩
──
■
▲
、
。
〈
〉
《
》
》),
」
『
』
【
】
〔
〕
〕〔
㈧
一
一.
一一
一下
一个
一些
一何
一切
一则
一则通过
一天
一定
一方面
一旦
一时
一来
一样
一次
一片
一番
一直
一致
一般
一起
一转眼
一边
一面
七
万一
三
三天两头
三番两次
三番五次
上
上下
上升
上去
上来
上述
上面
下
下列
下去
下来
下面
不
不一
不下
不久
不了
不亦乐乎
不仅
不仅...而且
不仅仅
不仅仅是
不会
不但
不但...而且
不光
不免
不再
不力
不单
不变
不只
不可
不可开交
不可抗拒
不同
不外
不外乎
不够
不大
不如
不妨
不定
不对
不少
不尽
不尽然
不巧
不已
不常
不得
不得不
不得了
不得已
不必
不怎么
不怕
不惟
不成
不拘
不择手段
不敢
不料
不断
不日
不时
不是
不曾
不止
不止一次
不比
不消
不满
不然
不然的话
不特
不独
不由得
不知不觉
不管
不管怎样
不经意
不胜
不能
不能不
不至于
不若
不要
不论
不起
不足
不过
不迭
不问
不限
与
与其
与其说
与否
与此同时
专门
且
且不说
且说
两者
严格
严重
个
个人
个别
中小
中间
丰富
串行
临
临到
为
为主
为了
为什么
为什麽
为何
为止
为此
为着
主张
主要
举凡
举行
乃
乃至
乃至于
么
之
之一
之前
之后
之後
之所以
之类
乌乎
乎
乒
乘
乘势
乘机
乘胜
乘虚
乘隙
九
也
也好
也就是说
也是
也罢
了
了解
争取
二
二来
二话不说
二话没说
于
于是
于是乎
云云
云尔
互
互相
五
些
交口
亦
产生
亲口
亲手
亲眼
亲自
亲身
人
人人
人们
人家
人民
什么
什么样
什麽
仅
仅仅
今
今后
今天
今年
今後
介于
仍
仍旧
仍然
从
从不
从严
从中
从事
从今以后
从优
从古到今
从古至今
从头
从宽
从小
从新
从无到有
从早到晚
从未
从来
从此
从此以后
从而
从轻
从速
从重
他
他人
他们
他是
他的
代替
以
以上
以下
以为
以便
以免
以前
以及
以后
以外
以後
以故
以期
以来
以至
以至于
以致
们
任
任何
任凭
任务
企图
伙同
会
伟大
传
传说
传闻
似乎
似的
但
但凡
但愿
但是
何
何乐而不为
何以
何况
何处
何妨
何尝
何必
何时
何止
何苦
何须
余外
作为
你
你们
你是
你的
使
使得
使用
例如
依
依据
依照
依靠
便
便于
促进
保持
保管
保险
俺
俺们
倍加
倍感
倒不如
倒不如说
倒是
倘
倘使
倘或
倘然
倘若
借
借以
借此
假使
假如
假若
偏偏
做到
偶尔
偶而
傥然
像
儿
允许
元/吨
充其极
充其量
充分
先不先
先后
先後
先生
光
光是
全体
全力
全年
全然
全身心
全部
全都
全面
八
八成
公然
六
兮
共
共同
共总
关于
其
其一
其中
其二
其他
其余
其后
其它
其实
其次
具体
具体地说
具体来说
具体说来
具有
兼之
内
再
再其次
再则
再有
再次
再者
再者说
再说
冒
冲
决不
决定
决非
况且
准备
凑巧
凝神
几
几乎
几度
几时
几番
几经
凡
凡是
凭
凭借
出
出于
出去
出来
出现
分别
分头
分期
分期分批
切
切不可
切切
切勿
切莫
则
则甚
刚
刚好
刚巧
刚才
初
别
别人
别处
别是
别的
别管
别说
到
到了儿
到处
到头
到头来
到底
到目前为止
前后
前此
前者
前进
前面
加上
加之
加以
加入
加强
动不动
动辄
勃然
匆匆
十分
千
千万
千万千万
半
单
单单
单纯
即
即令
即使
即便
即刻
即如
即将
即或
即是说
即若
却
却不
历
原来
去
又
又及
及
及其
及时
及至
双方
反之
反之亦然
反之则
反倒
反倒是
反应
反手
反映
反而
反过来
反过来说
取得
取道
受到
变成
古来
另
另一个
另一方面
另外
另悉
另方面
另行
只
只当
只怕
只是
只有
只消
只要
只限
叫
叫做
召开
叮咚
叮当
可
可以
可好
可是
可能
可见
各
各个
各人
各位
各地
各式
各种
各级
各自
合理
同
同一
同时
同样
后
后来
后者
后面
向
向使
向着
吓
吗
否则
吧
吧哒
吱
呀
呃
呆呆地
呐
呕
呗
呜
呜呼
呢
周围
呵
呵呵
呸
呼哧
呼啦
咋
和
咚
咦
咧
咱
咱们
咳
哇
哈
哈哈
哉
哎
哎呀
哎哟
哗
哗啦
哟
哦
哩
哪
哪个
哪些
哪儿
哪天
哪年
哪怕
哪样
哪边
哪里
哼
哼唷
唉
唯有
啊
啊呀
啊哈
啊哟
啐
啥
啦
啪达
啷当
喀
喂
喏
喔唷
喽
嗡
嗡嗡
嗬
嗯
嗳
嘎
嘎嘎
嘎登
嘘
嘛
嘻
嘿
嘿嘿
四
因
因为
因了
因此
因着
因而
固
固然
在
在下
在于
地
均
坚决
坚持
基于
基本
基本上
处在
处处
处理
复杂
多
多么
多亏
多多
多多少少
多多益善
多少
多年前
多年来
多数
多次
够瞧的
大
大不了
大举
大事
大体
大体上
大凡
大力
大多
大多数
大大
大家
大张旗鼓
大批
大抵
大概
大略
大约
大致
大都
大量
大面儿上
失去
奇
奈
奋勇
她
她们
她是
她的
好
好在
好的
好象
如
如上
如上所述
如下
如今
如何
如其
如前所述
如同
如常
如是
如期
如果
如次
如此
如此等等
如若
始而
姑且
存在
存心
孰料
孰知
宁
宁可
宁愿
宁肯
它
它们
它们的
它是
它的
安全
完全
完成
定
实现
实际
宣布
容易
密切
对
对于
对应
对待
对方
对比
将
将才
将要
将近
小
少数
尔
尔后
尔尔
尔等
尚且
尤其
就
就地
就是
就是了
就是说
就此
就算
就要
尽
尽可能
尽如人意
尽心尽力
尽心竭力
尽快
尽早
尽然
尽管
尽管如此
尽量
局外
居然
届时
属于
屡
屡屡
屡次
屡次三番
岂
岂但
岂止
岂非
川流不息
左右
巨大
巩固
差一点
差不多
己
已
已矣
已经
巴
巴巴
带
帮助
常
常常
常言说
常言说得好
常言道
平素
年复一年
并
并不
并不是
并且
并排
并无
并没
并没有
并肩
并非
广大
广泛
应当
应用
应该
庶乎
庶几
开外
开始
开展
引起
弗
弹指之间
强烈
强调
归
归根到底
归根结底
归齐
当
当下
当中
当儿
当前
当即
当口儿
当地
当场
当头
当庭
当时
当然
当真
当着
形成
彻夜
彻底
彼
彼时
彼此
往
往往
待
待到
很
很多
很少
後来
後面
得
得了
得出
得到
得天独厚
得起
心里
必
必定
必将
必然
必要
必须
快
快要
忽地
忽然
怎
怎么
怎么办
怎么样
怎奈
怎样
怎麽
怕
急匆匆
怪
怪不得
总之
总是
总的来看
总的来说
总的说来
总结
总而言之
恍然
恐怕
恰似
恰好
恰如
恰巧
恰恰
恰恰相反
恰逢
您
您们
您是
惟其
惯常
意思
愤然
愿意
慢说
成为
成年
成年累月
成心
我
我们
我是
我的
或
或则
或多或少
或是
或曰
或者
或许
战斗
截然
截至
所
所以
所在
所幸
所有
所谓
才
才能
扑通
打
打从
打开天窗说亮话
扩大
把
抑或
抽冷子
拦腰
拿
按
按时
按期
按照
按理
按说
挨个
挨家挨户
挨次
挨着
挨门挨户
挨门逐户
换句话说
换言之
据
据实
据悉
据我所知
据此
据称
据说
掌握
接下来
接着
接著
接连不断
放量
故
故意
故此
故而
敞开儿
敢
敢于
敢情
数/
整个
断然
方
方便
方才
方能
方面
旁人
无
无宁
无法
无论
既
既...又
既往
既是
既然
日复一日
日渐
日益
日臻
日见
时候
昂然
明显
明确
是
是不是
是以
是否
是的
显然
显著
普通
普遍
暗中
暗地里
暗自
更
更为
更加
更进一步
曾
曾经
替
替代
最
最后
最大
最好
最後
最近
最高
有
有些
有关
有利
有力
有及
有所
有效
有时
有点
有的
有的是
有着
有著
望
朝
朝着
末##末
本
本人
本地
本着
本身
权时
来
来不及
来得及
来看
来着
来自
来讲
来说
极
极为
极了
极其
极力
极大
极度
极端
构成
果然
果真
某
某个
某些
某某
根据
根本
格外
梆
概
次第
欢迎
欤
正值
正在
正如
正巧
正常
正是
此
此中
此后
此地
此处
此外
此时
此次
此间
殆
毋宁
每
每个
每天
每年
每当
每时每刻
每每
每逢
比
比及
比如
比如说
比方
比照
比起
比较
毕竟
毫不
毫无
毫无例外
毫无保留地
汝
沙沙
没
没奈何
没有
沿
沿着
注意
活
深入
清楚
满
满足
漫说
焉
然
然则
然后
然後
然而
照
照着
牢牢
特别是
特殊
特点
犹且
犹自
独
独自
猛然
猛然间
率尔
率然
现代
现在
理应
理当
理该
瑟瑟
甚且
甚么
甚或
甚而
甚至
甚至于
用
用来
甫
甭
由
由于
由是
由此
由此可见
略
略为
略加
略微
白
白白
的
的确
的话
皆可
目前
直到
直接
相似
相信
相反
相同
相对
相对而言
相应
相当
相等
省得
看
看上去
看出
看到
看来
看样子
看看
看见
看起来
真是
真正
眨眼
着
着呢
矣
矣乎
矣哉
知道
砰
确定
碰巧
社会主义
离
种
积极
移动
究竟
穷年累月
突出
突然
窃
立
立刻
立即
立地
立时
立马
竟
竟然
竟而
第
第二
等
等到
等等
策略地
简直
简而言之
简言之
管
类如
粗
精光
紧接着
累年
累次
纯
纯粹
纵
纵令
纵使
纵然
练习
组成
经
经常
经过
结合
结果
给
绝
绝不
绝对
绝非
绝顶
继之
继后
继续
继而
维持
综上所述
缕缕
罢了
老
老大
老是
老老实实
考虑
者
而
而且
而况
而又
而后
而外
而已
而是
而言
而论
联系
联袂
背地里
背靠背
能
能否
能够
腾
自
自个儿
自从
自各儿
自后
自家
自己
自打
自身
臭
至
至于
至今
至若
致
般的
良好
若
若夫
若是
若果
若非
范围
莫
莫不
莫不然
莫如
莫若
莫非
获得
藉以
虽
虽则
虽然
虽说
蛮
行为
行动
表明
表示
被
要
要不
要不是
要不然
要么
要是
要求
见
规定
觉得
譬喻
譬如
认为
认真
认识
让
许多
论
论说
设使
设或
设若
诚如
诚然
话说
该
该当
说明
说来
说说
请勿
诸
诸位
诸如
谁
谁人
谁料
谁知
谨
豁然
贼死
赖以
赶
赶快
赶早不赶晚
起
起先
起初
起头
起来
起见
起首
趁
趁便
趁势
趁早
趁机
趁热
趁着
越是
距
跟
路经
转动
转变
转贴
轰然
较
较为
较之
较比
边
达到
达旦
迄
迅速
过
过于
过去
过来
运用
近
近几年来
近年来
近来
还
还是
还有
还要
这
这一来
这个
这么
这么些
这么样
这么点儿
这些
这会儿
这儿
这就是说
这时
这样
这次
这点
这种
这般
这边
这里
这麽
进入
进去
进来
进步
进而
进行
连
连同
连声
连日
连日来
连袂
连连
迟早
迫于
适应
适当
适用
逐步
逐渐
通常
通过
造成
逢
遇到
遭到
遵循
遵照
避免
那
那个
那么
那么些
那么样
那些
那会儿
那儿
那时
那末
那样
那般
那边
那里
那麽
部分
都
鄙人
采取
里面
重大
重新
重要
鉴于
针对
长期以来
长此下去
长线
长话短说
问题
间或
防止
阿
附近
陈年
限制
陡然
除
除了
除却
除去
除外
除开
除此
除此之外
除此以外
除此而外
除非
随
随后
随时
随着
随著
隔夜
隔日
难得
难怪
难说
难道
难道说
集中
零
需要
非但
非常
非徒
非得
非特
非独
靠
顶多
顷
顷刻
顷刻之间
顷刻间
顺
顺着
顿时
颇
风雨无阻
饱
首先
马上
高低
高兴
默然
默默地
齐
︿
!
#
$
%
&
'
(
)
)÷(1-
)、
*
+
+ξ
++
,
,也
-
-β
--
-[*]-
.
/
0
0:2
1
1.
12%
2
2.3%
3
4
5
5:0
6
7
8
9
:
;
<
<±
<Δ
<λ
<φ
<<
=
=″
=☆
=(
=-
=[
={
>
>λ
?
@
A
LI
R.L.
ZXFITL
[
[①①]
[①②]
[①③]
[①④]
[①⑤]
[①⑥]
[①⑦]
[①⑧]
[①⑨]
[①A]
[①B]
[①C]
[①D]
[①E]
[①]
[①a]
[①c]
[①d]
[①e]
[①f]
[①g]
[①h]
[①i]
[①o]
[②
[②①]
[②②]
[②③]
[②④
[②⑤]
[②⑥]
[②⑦]
[②⑧]
[②⑩]
[②B]
[②G]
[②]
[②a]
[②b]
[②c]
[②d]
[②e]
[②f]
[②g]
[②h]
[②i]
[②j]
[③①]
[③⑩]
[③F]
[③]
[③a]
[③b]
[③c]
[③d]
[③e]
[③g]
[③h]
[④]
[④a]
[④b]
[④c]
[④d]
[④e]
[⑤]
[⑤]]
[⑤a]
[⑤b]
[⑤d]
[⑤e]
[⑤f]
[⑥]
[⑦]
[⑧]
[⑨]
[⑩]
[*]
[-
[]
]
]∧′=[
][
_
a]
b]
c]
e]
f]
ng昉
{
{-
|
}
}>
~
~±
~+
¥(四) 文本表示与降维
1. 文本表示:使用了 `CountVectorizer` 类来将文本数据转换成词袋模型的表示形式。`CountVectorizer` 将文本数据转换成了文档-词频矩阵,其中每一行代表一个文档,每一列代表一个词,矩阵中的元素表示对应文档中对应词出现的频次。`max_features=100000` 参数限制了词汇表的最大数量,只选择出现频次最高的 100000 个词作为特征。
2. 降维:使用了奇异值分解(SVD)来对文档-词频矩阵进行降维。在这里,使用了 `TruncatedSVD` 类来执行截断奇异值分解,将文档-词频矩阵降维到 500 维。降维的目的是减少特征维度,提取出数据中的主要信息,以便后续的文本分析和处理。
# 文本表示
vectorizer = CountVectorizer(max_features=100000)
X = vectorizer.fit_transform(df_new['视频合并'])
dense_matrix = X.toarray()
svd = TruncatedSVD(n_components=500, n_iter=10, random_state=42)
X = svd.fit_transform(X)最终,`X` 变量存储了降维后的文本表示结果,是一个二维数组,每一行代表一个文档的低维表示。
X的大致形态如下:

(五)聚类
kmeans = KMeans(n_clusters=8)
y = kmeans.fit_predict(X)
# 输出聚类结果
print(y)
len(y)
(六)后续处理
1. 基本信息输出
把类别放在博主后面,便于按类别对博主信息进行输出。
df_new.insert(1, '类别', y)
df_new.to_csv('类别')# 假设 'category' 是包含类别的列名
for category, group in df_new.groupby('类别'):
with open(f'category_{category}.csv', 'w', encoding='utf-8') as f:
f.write(f'第{category}类\n')
for index, row in group.iterrows():
row_str = ','.join([str(val) for val in row.values]) + '\n'
f.write(row_str)得到按类别的输出(比如第0类都是卖果子的,嘻嘻):

这里的原始聚簇个数参数我设置成了8,理论上不需要这么多(太细致了),这里只是一个实例。这8个簇细到什么程度呢,除了卖水果产品类、传统文化宣传类、农业技术分享类,还有一些很可爱的聚簇,比如:
专卖榴莲类博主:
 专卖茶叶类博主(虽然只有一个):
专卖茶叶类博主(虽然只有一个):
 很有趣的一集()
很有趣的一集()
2. 等待指正的可视化:
散点图1:把十万个特征PCA成2个,这个可视化本质上感觉是没有太大意义的(相比第一版将输出限制在一个范围内,就不会出现只有一个点在上面,其他堆在底下的情况)
import matplotlib.pyplot as plt
import seaborn as sns
# 将特征表示 X 进行降维,以便可视化
from sklearn.decomposition import TruncatedSVD
X_reduced = TruncatedSVD(n_components=2, random_state=42).fit_transform(X)
# 创建一个散点图,不同簇用不同颜色表示
plt.figure(figsize=(8, 6))
sns.scatterplot(x=X_reduced[:, 0], y=X_reduced[:, 1], hue=y, palette="viridis", s=50, alpha=0.8)
plt.title("K-Means Clustering Results")
plt.xlabel("Reduced Feature 1")
plt.ylabel("Reduced Feature 2")
plt.show()
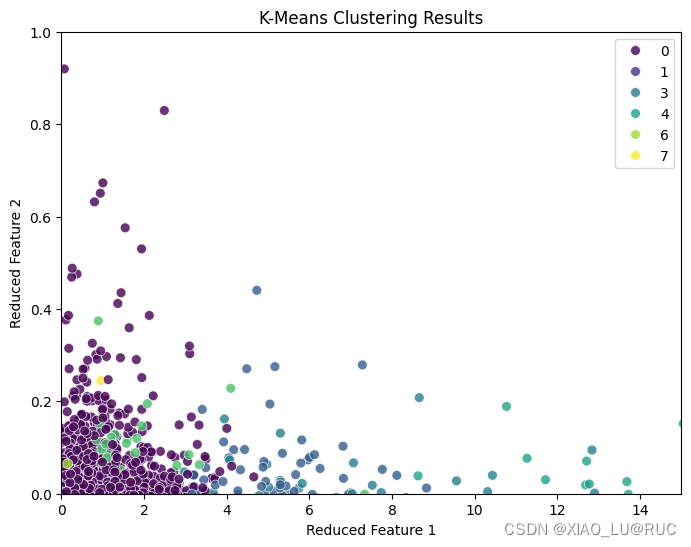 散点图2:
散点图2:
想的是PCA和特征间两两形成散点图的方法相结合,绘制成了这个图:把十万个特征降维成100个,然后绘制这100个小幅度PCA后的特征:
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import TruncatedSVD
# 将特征表示 X 进行降维,以便可视化
X_reduced = TruncatedSVD(n_components=100, random_state=42).fit_transform(X)
# 创建一个散点图,不同簇用不同颜色表示
fig, axs = plt.subplots(20, 5, figsize=(15, 60))
axs = axs.flatten()
for i in range(100):
# 绘制散点图
sns.scatterplot(x=X_reduced[:, i], y=X_reduced[:, (i + 1) % 100], hue=y, palette="viridis", ax=axs[i], s=50, alpha=0.8)
axs[i].set_xlabel(f'Feature {i}')
axs[i].set_ylabel(f'Feature {(i + 1) % 100}')
axs[i].legend()
axs[i].set_xlim(-5, 5)
axs[i].set_ylim(-5, 5)
plt.tight_layout()
plt.show()
因为看起来这个图前面几个特征区分的比较明显,猜想可能前面几个主要特征把文本区分开来了,就想着进一步拆分前面这几个特征,所以下面的散点图尝试不进行PCA,选取前面的特征进行两辆散点分析。
散点图3:
按照上面的思路:
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
# 创建 KMeans 模型并拟合数据
kmeans = KMeans(n_clusters=8, random_state=42)
clusters = kmeans.fit_predict(X[:, :10])
# 创建一个散点图,不同簇用不同颜色表示
fig, axs = plt.subplots(20, 5, figsize=(15, 60))
axs = axs.flatten()
for i in range(100):
# 绘制散点图
sns.scatterplot(x=X[:, i], y=X[:, (i + 1) % 100], hue=clusters, palette="viridis", ax=axs[i], s=50, alpha=0.8)
axs[i].set_xlabel(f'Feature {i}')
axs[i].set_ylabel(f'Feature {(i + 1) % 100}')
axs[i].legend()
axs[i].set_xlim(-15,15)
axs[i].set_ylim(-15,15)
plt.tight_layout()
plt.show()结果如下,可以看到前面几个好像还行,但总觉得缺乏一些科学依据(?):
热力图1:(没有任何进步)
import numpy as np
import seaborn as sns
# 假设 kmeans 是您的 KMeans 模型对象,X 是特征表示
# 计算特征之间的相关性矩阵
correlation_matrix = np.corrcoef(X, rowvar=False)
# 创建一个包含聚类标签的数组
cluster_labels = kmeans.labels_
# 将聚类标签与特征相关性矩阵合并
merged_array = np.column_stack((cluster_labels, X))
# 计算每个聚类的平均特征相关性
cluster_means = []
for cluster in np.unique(cluster_labels):
cluster_data = merged_array[merged_array[:, 0] == cluster][:, 1:]
cluster_means.append(np.mean(cluster_data, axis=0))
cluster_means = np.array(cluster_means)
# 绘制聚类热图
plt.figure(figsize=(12, 8))
sns.heatmap(np.corrcoef(cluster_means, rowvar=False), annot=True, cmap='coolwarm', linewidths=.5)
plt.title('Cluster Correlation Heatmap')
plt.show()
可以看出这是一个惨兮兮的可视化~~~
四、致谢与结语
感谢我可爱的SN实验班的项目队友:牙牙、子涵、铁柱(排名不分先后)
感谢同样可爱的我的室友图灵冉,为二次更新的可视化提供无比强大且专业的技术支持
希望大家都越来越好,没对象的早日脱单,其他的都生活幸福!















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









