






Feature Scaling问题
在多变量情况下,各个变量的值域可能有很大区别。例如,的值域可能在(1,10)之间,而的值域可能(1,10000)之间。值域差异过大,很容易造成在计算过程中溢出或无法收敛。而通过对数据进行归一化(Normalization)处理,可以较好的解决这个问题
1、查看【house_price.csv】文件中的数据,保存到代码同级目录
house_price.csv
链接:https://pan.baidu.com/s/1uLdMedY9edNKTfAtwHkN-g?pwd=6688
提取码:66882、Area:房屋面积;Rooms:房间数;Price:房屋出售价格。其中Area和Rooms是自变量;Price是因变量
3、Area:的值一般在"数千"这个级别上,而Rooms则是个位数,值域差异明显
4、归一化方法:
5、有多种种归一化方法,一般可采用下列办法: 
6、其中,该列数据的平均值,std(x)是该列数据的标准差
使用sklearn.linear_model.LinearRegression处理
无需对自变量进行归一化处理,也能得到良好的结果。针对训练数据的R方约为0.73
''' 使用LinearRegression,没有进行归一化预处理 '''
import numpy as np
from sklearn.linear_model import LinearRegression
trainData = np.loadtxt(open('house_price.csv', 'r'), delimiter=",",skiprows=1)
xTrain = np.array(trainData[:, 0:2]) # 取前2列 [0,1]
yTrain = np.array(trainData[:, -1]) # 取第2列及最后1列
# xTest = np.array(trainData[30::, 0:2])
# yTest = np.array(trainData[30::, -1])
# print(xTest)
# print(yTest)
xTrain = np.c_[xTrain, np.ones(len(xTrain))]
# xTest = np.c_[xTest, np.ones(len(xTest))]
model = LinearRegression()
model.fit(xTrain, yTrain)
print("LinearRegression计算TrainR方:", model.score(xTrain, yTrain))
# print("LinearRegression计算TestR方:", model.score(xTest, yTest))
''' 使用LinearRegression,进行归一化预处理 '''
import numpy as np
from sklearn.linear_model import LinearRegression
def normalizeData(X):
# 每列(每个Feature)分别求出均值和标准差,然后与X的每个元素分别进行操作
return (X - X.mean(axis=0))/X.std(axis=0) # axis=0 按列计算
trainData = np.loadtxt(open('house_price.csv', 'r'), delimiter=",",skiprows=1)
xTrain = np.array(trainData[:, 0:2])
yTrain = np.array(trainData[:, 2])
xTrain = normalizeData(xTrain)
print(xTrain)
xTrain = np.c_[xTrain, np.ones(len(xTrain))] # 归一化完成后再添加intercept item列
# xTest = np.array(xTrain[30::, 0:3])
# yTest = np.array(xTrain[30::, -1])
# print(xTest)
# print(yTest)
model = LinearRegression()
model.fit(xTrain, yTrain)
print("LinearRegression计算R方:", model.score(xTrain, yTrain))
# print("LinearRegression计算TestR方:", model.score(xTest, yTest))使用自定义的批量梯度下降法
1、在未对自变量归一化处理的情况下,运算出现异常,无法收敛 2、 归一化处理后,能够得到与LinearRegression类似的结果
''' 使用自定义BGD,未作归一化处理,可能无法收敛 '''
import numpy as np
import bgd_resolver
def costFn(theta, X, y):
temp = X.dot(theta) - y
return (temp.T.dot(temp)) / (2 * len(X))
def gradientFn(theta, X, y):
return (X.T).dot(X.dot(theta) - y) / len(X)
trainData = np.loadtxt(open('house_price.csv', 'r'), delimiter=",",skiprows=1)
xTrain = np.array(trainData[:, 0:2])
yTrain = np.array(trainData[:, 2])
xTrain = np.c_[xTrain, np.ones(len(xTrain))]
init_theta = np.random.randn(xTrain.shape[1])
# 如果数据不进行Normalize,则下面的梯度算法有可能不收敛
theta = bgd_resolver.batch_gradient_descent(costFn, gradientFn, init_theta, xTrain, yTrain)
rsquare = bgd_resolver.batch_gradient_descent_rsquare(theta, xTrain, yTrain)
print("梯度下降法计算R方:", rsquare)''' 使用自定义BGD,作归一化处理 '''
import numpy as np
import bgd_resolver
def normalizeData(X):
# 每列(每个Feature)分别求出均值和标准差,然后与X的每个元素分别进行操作
return (X - X.mean(axis=0))/X.std(axis=0)
def costFn(theta, X, y):
temp = X.dot(theta) - y
return (temp.T.dot(temp)) / (2 * len(X))
def gradientFn(theta, X, y):
return (X.T).dot(X.dot(theta) - y) / len(X)
trainData = np.loadtxt(open('house_price.csv', 'r'), delimiter=",",skiprows=1)
xTrain = np.array(trainData[:, 0:2])
yTrain = np.array(trainData[:, 2])
xTrain = normalizeData(xTrain)
xTrain = np.c_[xTrain, np.ones(len(xTrain))]
init_theta = np.random.randn(xTrain.shape[1])
# 如果数据不进行Normalize,则下面的梯度算法有可能不收敛
theta = bgd_resolver.batch_gradient_descent(costFn, gradientFn, init_theta, xTrain, yTrain)
rsquare = bgd_resolver.batch_gradient_descent_rsquare(theta, xTrain, yTrain)
print("梯度下降法计算R方:", rsquare)学习速率(learning rate)对计算的影响
1、 一般情况下,学习速率越小,其收敛的可能性越大(不容易因为步长过大,而“错过”极值点),但是需要更多次循环才能到达极值点。
2、 学习速率越大,能够朝着极值点更快前进,但有可能因错过极值点而造成无法收敛
3、 在实际的梯度下降算法中,会先选择一个较大的learning rate,随着不断逼近极值点,逐渐减小learning rate。
(1) 机器学习:0.01—0.001
(2) 深度学习:0.00001—-0.000001
(3) 动态设置
(4)参数/权重参数 w0,w1,w2,…,wn 梯度下降数值优化计算出来的
(5)超参数:如学习率()……自行设定,然后通过验证数据集取最佳
(6) 超参数组合:
下面的例子演示了,如果设置过大(0.1)的学习速率,会导致计算不收敛
''' 测试learning rate过大的问题 '''
import numpy as np
import matplotlib.pyplot as plt
import bgd_resolver
def costFn(theta, X, y): # 定义线性回归的成本函数
temp = X.dot(theta) - y
return temp.dot(temp) / (2*len(X))
def gradientFn(theta, X, y): # 根据成本函数,分别对x0和x1求导数(梯度)
return (X.T).dot(X.dot(theta) - y) / len(X)
xTrain = np.array([6, 8, 10, 14, 18])[:, np.newaxis]
yTrain = np.array([7, 9, 13, 17.5, 18])
xTrain_ext = np.c_[xTrain, np.ones(len(xTrain))]
np.random.seed(0)
theta_init = np.random.randn(xTrain_ext.shape[1])
# 直接设置learning_rate为0.1,速率过大,导致计算不收敛
theta = bgd_resolver.batch_gradient_descent(costFn, gradientFn, theta_init, xTrain_ext, yTrain, learning_rate=0.01)
print(theta)高阶拟合
1、已知训练样本数据点:(6,7),(8,9),(10,13),(14,17.5),(18,18)
2、以及测试样本数据点:(8,11),(9,8.5),(11,15),(16,18),(12,11)
3、分别使用一阶曲线(直线)、二阶曲线和三阶曲线进行拟合,并检查拟合效果
4、在拟合数据点时,一般来说,对于一个自变量的,拟合出来是一条直线;对于两个自变量的,拟合出来时一个直平面。这种拟合结果是严格意义上的“线性”回归。但是有时候,采用“曲线”或“曲面”的方式来拟合,能够对训练数据产生更逼近的效果。这就是“高阶拟合”。
例如,对于一个自变量的情形,可以采用3阶拟合:
对于两个自变量的情形,可以采用更复杂的高阶拟合:
(1)以"线性回归"的方式来拟合高阶曲线
(2) 以单变量高阶拟合为例。训练数据中,仅有一列自变量数据
(3) 通过Intercept Term,扩展一列全是1的自变量数据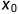
(4)将的每个元素分别平方,得到第三列自变量数据 
(5)将的每个元素分别立方,得到第四列自变量数据
(6)将(,,,)看成具有四个自变量的多线性回归情形,通过LinearRegression对象进行多变量线性回归计算
(7)生成,等高阶自变量数据,可借助PolynomialFeatures对象的fit_transform方法来实现
(8) 高阶曲线对于训练数据的拟合程度较好,但对于测试数据,却不一定有较好的R方
步骤1:查看要拟合的数据
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
xTrain = np.array([6, 8, 10, 14, 18])[:, np.newaxis] # 训练数据(直径)
yTrain = np.array([7, 9, 13, 17.5, 18]) # 训练数据(价格)
xTest = np.array([8, 9, 11, 16, 12])[:, np.newaxis] # 测试数据(直径)
yTest = np.array([11, 8.5, 15, 18, 11]) # 测试数据(价格)
plotData = np.array(np.linspace(0, 26, 100))[:,np.newaxis] # 作图用的数据点
def initPlot():
plt.figure()
plt.title('Pizza Price vs Diameter')
plt.xlabel('Diameter')
plt.ylabel('Price')
plt.axis([0, 25, 0, 25])
plt.grid(True)
return plt
plt = initPlot()
plt.plot(xTrain, yTrain, 'r.') # 训练点数据(红色)
plt.plot(xTest, yTest, 'b.') # 测试点数据(蓝色)步骤2:一阶(线性)拟合实现
from sklearn.linear_model import LinearRegression
# 线性拟合
linearModel = LinearRegression()
linearModel.fit(xTrain, yTrain)
linearModelTrainResult = linearModel.predict(plotData)
# 计算R方
linearModelRSquare = linearModel.score(xTest, yTest)
print("线性拟合R方:", linearModelRSquare)
plt = initPlot()
plt.plot(xTrain, yTrain, 'r.') # 训练点数据(红色)
plt.plot(xTest, yTest, 'b.') # 测试点数据(蓝色)
plt.plot(plotData, linearModelTrainResult, 'y-') # 线性拟合线步骤3:二阶曲线拟合
1、PolynomialFeatures.fit_transform提供了将1阶数据扩展到高阶数据的方法
2、 训练样本和测试样本都需要进行扩充
from sklearn.preprocessing import PolynomialFeatures
# 二阶曲线拟合 theta0 + theta1*x + theta2*x*x x*x => z theta0+theta1*x+theta2*z
quadratic_featurizer = PolynomialFeatures(degree=2)
xTrain_quadratic = quadratic_featurizer.fit_transform(xTrain)
print(xTrain_quadratic) # 查看扩展后的特征矩阵
quadraticModel = LinearRegression()
quadraticModel.fit(xTrain_quadratic, yTrain)
# 计算R方(针对测试数据)
xTest_quadratic = quadratic_featurizer.fit_transform(xTest)
quadraticModelRSquare = quadraticModel.score(xTest_quadratic, yTest)
print("二阶拟合R方:", quadraticModelRSquare)
# 绘图点也同样需要进行高阶扩充以便使用曲线进行拟合
plotData_quadratic = quadratic_featurizer.fit_transform(plotData)
quadraticModelTrainResult = quadraticModel.predict(plotData_quadratic)
plt = initPlot()
plt.plot(xTrain, yTrain, 'r.') # 训练点数据(红色)
plt.plot(xTest, yTest, 'b.') # 测试点数据(蓝色)
plt.plot(plotData, quadraticModelTrainResult, 'g-') # 二阶拟合线
plt.show()步骤4:二阶曲线拟合
# 三阶曲线拟合
cubic_featurizer = PolynomialFeatures(degree=3)
xTrain_cubic = cubic_featurizer.fit_transform(xTrain)
cubicModel = LinearRegression()
cubicModel.fit(xTrain_cubic, yTrain)
plotData_cubic = cubic_featurizer.fit_transform(plotData)
cubicModelTrainResult = cubicModel.predict(plotData_cubic)
# 计算R方(针对测试数据)
xTest_cubic = cubic_featurizer.fit_transform(xTest)
cubicModelRSquare = cubicModel.score(xTest_cubic, yTest)
print("三阶拟合R方:", cubicModelRSquare)
plt = initPlot()
plt.plot(xTrain, yTrain, 'r.') # 训练点数据(红色)
plt.plot(xTest, yTest, 'b.') # 测试点数据(蓝色)
plt.plot(plotData, cubicModelTrainResult, 'p-') # 三阶拟合线
plt.show()bias和variance
观察下列拟合(单变量):
1、左边图采用直线拟合,很显然有许多训练数据点不能很好的被拟合,将导致训练数据的残差很大。这种情况称为underfit(欠拟合),或者:High bias(高偏差)
2、 右边图采用4次曲线拟合,完美的通过了训练数据的每个点。但是,如果针对另一批测试数据做预测,这条高阶曲线将产生非常大的误差。这种情况称为overfit(过拟合),或者:High variance(高方差)
3、 中间图采用2次曲线拟合,虽然不能完美拟合每个数据点,但是对测试数据也能产生较好的预测效果。这时比较合适的情形
4、 因此,在计算模型参数时,既要防止High bias,也要防止High variance















 1489
1489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











