







梯度消失和梯度爆炸
在计算W2的梯度时:
梯度为激活函数输出连乘的形式
当激活函数的输出-->0,造成梯度消失
当激活函数的输出-->无穷,造成梯度爆炸
初始化方式
采用标准差来衡量数量的差值范围
建立N层MLP,并打印经过每一层的方差
class MLP(nn.Module):
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return xnn.init.normal_(m.weight.data)
当初始化方式为正态分布,均值为0,方差为1,计算经过线性层的标准差
当均值为0时
则
当x、w都为正态分布,均值为0,方差为1时,经过线性层后的标准差为sqrt(n),n指输入长度
layer_nums = 100
neural_nums = 400
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
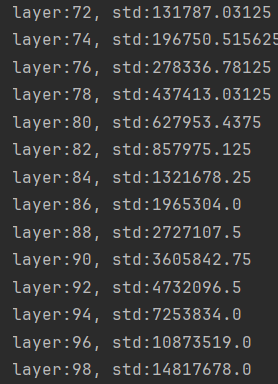
print(output)传入参数,每经过一次线性层,结果*sqrt(n),最终造成梯度爆炸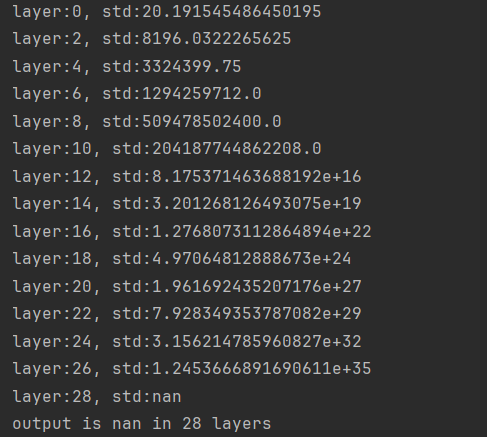
根据公式,将w的标准差改为sqrt(1/n)
nn.init.normal_(m.weight.data, std=np.sqrt(1/self.neural_num))
经过线性层的标准差相对稳定,不会过大或过小
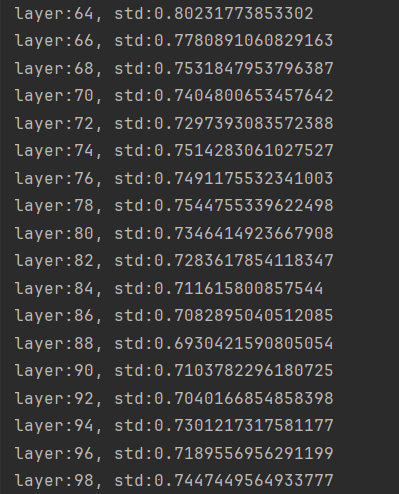
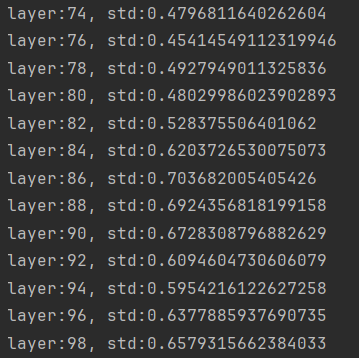
但是在前向加入sigmoid激活函数后
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.sigmoid(x)
if i%2==0:
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x标准差越来越小,有造成梯度消失的趋势
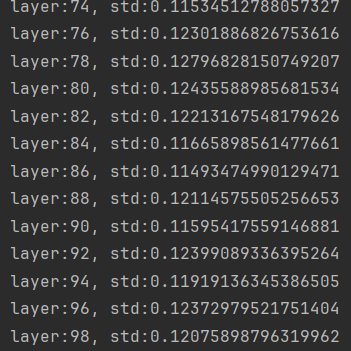
对于tanh,sigmoid等激活函数可以使用Xavier初始化方式
nn.init.xavier_uniform_(m.weight.data, gain=tanh_gain)
(PDF) Understanding the difficulty of training deep feedforward neural networks (researchgate.net)
tanh_gain = nn.init.calculate_gain('tanh')
nn.init.xavier_uniform_(m.weight.data, gain=tanh_gain)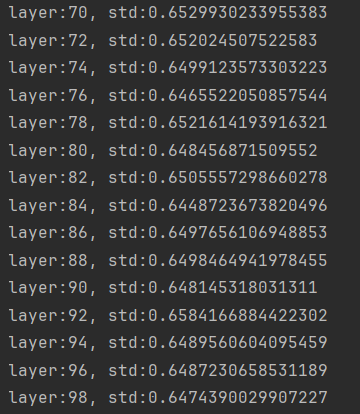
缓解梯度消失现象
但是若将激活函数换车Relu激活函数后,Xavier初始化方式失效
此时可以使用Kaiming初始化方法
nn.init.kaiming_normal_(m.weight.data)
可以根据网络的输入输出,计算标准差的增益
gain = x.std() / out.std()
print('gain:{}'.format(gain))
tanh_gain = nn.init.calculate_gain('tanh')
print('tanh_gain in PyTorch:', tanh_gain)














 3923
3923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









