






参数
d_model = 512 # 输入到网路的词向量维度\是embedding的维度\是PE的最后一维度
d_k = 64 # w_q\w_k\w_v的维度
Max_len = 40 # 最大句长
head_en = 8 # 多头注意力head的个数
# 前馈网络的参数,其中输入输出维度跟d_model一样就不设置了,直接用d_model
Hidden_size = 2048 # 中间层的全连接神经元个数dff
en_N = 6
de_N = 6
vocab_input_len = 7926
vocab_target_len = 12556
##########################################################################
batch_size = 128
data_path = "./data/e2c.xlsx"
PAD = 0
SOS = 1
EOS = 2
学习率是1e-5
训练部分的代码
import random
import torch
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
from Transformer import Transformer
from config import *
from get_parm import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# trainning pram
optim_l_r = 1e-3
epochs = 80
def Show_sentence(sentence_list):
for word in sentence_list:
if word == "<EOS>":
print(word, end="")
break
print(word, end="")
print()
def get_loss(decoder_outputs, target):
decoder_outputs = torch.log(decoder_outputs)
# torch.nn.CrossEntropyLoss==torch.nn.NLLLoss+torch.nn.LogSoftmax,因此这里需要取对数
target = target.view(-1) # [batch_size*max_len]
decoder_outputs = decoder_outputs.view(batch_size * max_len_ch, -1)
return criterion(decoder_outputs, target)
transformer = Transformer()
if os.path.exists("./models/transformer_e2c.pkl"):
transformer.load_state_dict(torch.load("./models/transformer_e2c.pkl"))
optimizer = optim.Adam(transformer.parameters(), optim_l_r)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[30, 60], gamma=0.01)
criterion = nn.NLLLoss(ignore_index=vocab_en.word2idx("<PAD>"), reduction="mean")
transformer.train()
transformer.to(device)
Loss_list = []
loss_min = float('inf')
for epoch in range(epochs):
progress_bar = tqdm(total=len(trainDataLoader), desc='Train Epoch {}'.format(epoch), unit='batch')
loss_all = 0
n = 0
for idx, (en_text, ch_text) in enumerate(trainDataLoader):
n += 1
optimizer.zero_grad()
en_text = en_text.to(device)
ch_text = ch_text.to(device)
output = transformer(en_text, ch_text)
loss_t = get_loss(output, ch_text)
loss_all += loss_t.item()
loss_t.backward()
optimizer.step()
if idx == 0:
predict = torch.argmax(output.data, dim=-1)
print("预测:", end="")
number = random.randint(0, int(batch_size // 2))
Show_sentence(mapping(predict[number], vocab_ch, reverse=True))
print("真实:", end="")
Show_sentence(mapping(ch_text[number], vocab_ch, reverse=True))
progress_bar.set_postfix({'loss': loss_all / (idx + 1), "lr": optimizer.param_groups[0]['lr']})
progress_bar.update()
Loss_list.append(loss_all / n)
with open("loss/loss_data.txt", "w", encoding="utf8") as f:
f.write(str(Loss_list))
if (loss_all / n) < loss_min:
torch.save(transformer.state_dict(), "./models/transformer_e2c.pkl")
loss_min = loss_all / n
progress_bar.close()
scheduler.step()
注意的是:
损失函数使用NLLloss
推理过程
import ast
import torch
from Transformer import Transformer
from config import *
from vocab import tokenizer, Vocab, mapping
def load_vocab(path):
with open(path, "r", encoding="utf8") as f:
rel = ast.literal_eval(f.readline()) # 字符串列表转回列表
return rel
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if __name__ == "__main__":
# 加载词汇表同时构造词汇表类
vocab_en = Vocab(load_vocab("./vocab/vocab_en.txt"), init=False)
vocab_ch = Vocab(load_vocab("./vocab/vocab_ch.txt"), init=False)
# 载入模型
transformer = Transformer()
transformer.load_state_dict(torch.load("./models/transformer_e2c.pkl", map_location=torch.device(device)))
transformer.eval()
# 构造编码器的输入
en_input = ["Tom has no siblings."]
en_token_sentence_list = tokenizer(en_input)
print("编码器的输入:", en_token_sentence_list)
vector_en_list = []
for sentence in en_token_sentence_list:
vector_en_list.append(mapping(sentence, vocab_en))
print("编码器输入word2idx:", vector_en_list)
vector_en_list = torch.tensor(vector_en_list, dtype=torch.int64)
# 构造解码器的输入端GO
ch_sentence = ["Tom"]
ch_token_sentence_list = tokenizer(ch_sentence, inference=True)
print("解码器的输入:", ch_token_sentence_list)
vector_ch_list = []
for sentence in ch_token_sentence_list:
vector_ch_list.append(mapping(sentence, vocab_ch))
print("解码器输入word2idx:", vector_ch_list)
vector_ch_list = torch.tensor(vector_ch_list, dtype=torch.int64)
for _ in range(Max_len - vector_ch_list.shape[1] + 1):
output_de = transformer(vector_en_list, vector_ch_list)
if torch.argmax(output_de.data[:, -1, :], dim=-1).item() == EOS:
vector_ch_list = torch.cat((vector_ch_list, torch.argmax(output_de.data[:, -1, :], dim=-1).unsqueeze(0)),
dim=-1)
break
vector_ch_list = torch.cat((vector_ch_list, torch.argmax(output_de.data[:, -1, :], dim=-1).unsqueeze(0)),
dim=-1)
rel = mapping(vector_ch_list[0], vocab_ch, reverse=True)
print("经过transformer的输出:", rel)
print("#" * 100)
print("输入:", en_input[0])
print("输出:", end="")
for word in rel:
if word == "<SOS>": continue
print(word, end="")
print()
不知道是不是哪里有问题,推理的结果很差,但是训练的效果看着好像还可以:
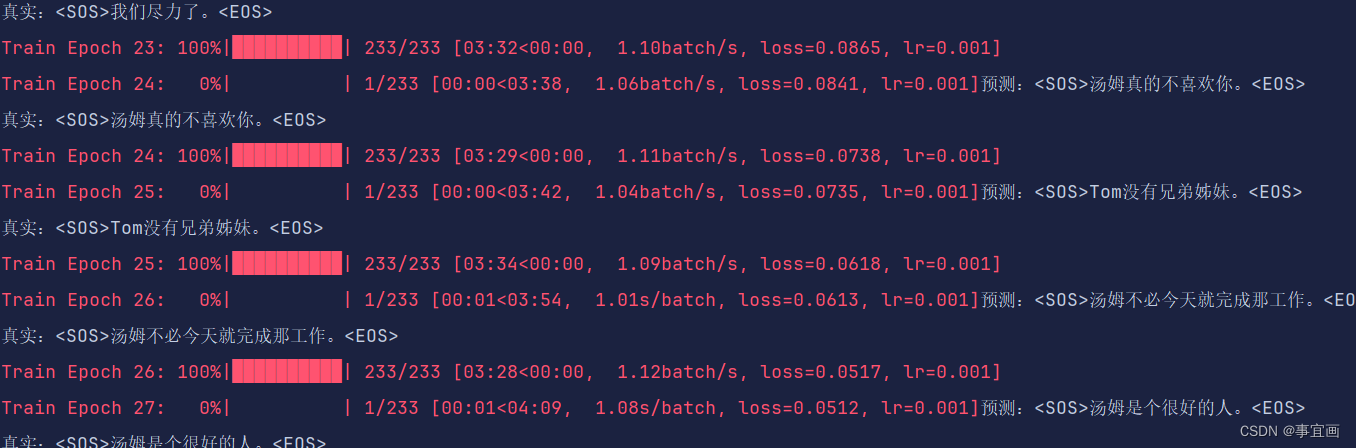
可能是我推理过程搭错了,或者是训练的还不够
推理过程我是初始化一个SOS作为开始符号,然后送进网络,得到的结果跟SOS拼接,然后在送进网络,重复一直到输出EOS或者达到最大长度
其中的推理结果如下:
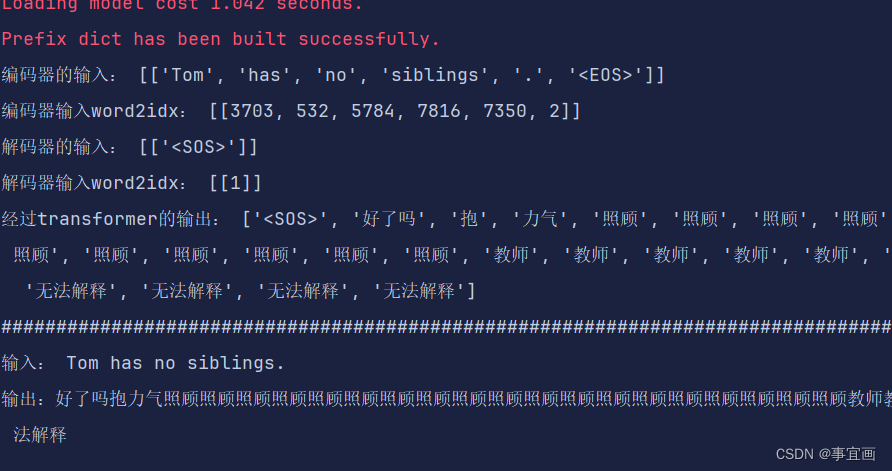
还在寻找哪里有问题
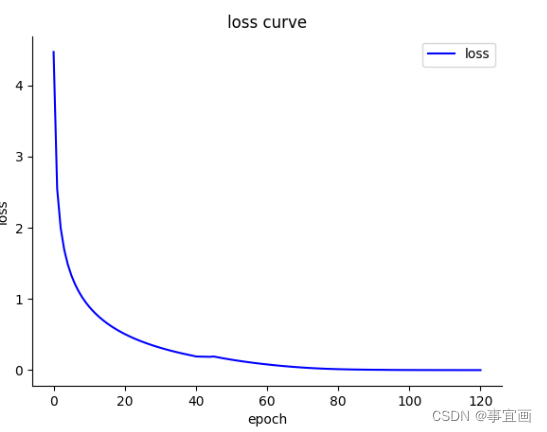
总结
transformer进行训练时,在小数据集上效果很难练出来,同时需要训练的epoch更多,参数方面也很难调整;而使用时序rnn模块来训练时,在数据集较小上的结果很不错,需要的代价也少很多。很大原因是因为transformer是有教师机制来引导训练的。















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









