







目录
习题4-1 对于一个神经元,并使用梯度下降优化参数w时,如果输入x恒大于0,其收敛速度会比零均值化的输入更慢。
习题4-5 如果限制一个神经网络的总神经元数量(不考虑输入层)为N+1,输入层大小为,输出层大小为1,隐藏层的层数为L,每个隐藏层的神经元数量为,试分析参数数量和隐藏层层数L的关系。
习题4-7 为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化?
习题4-8 为什么在用反向传播算法进行参数学习时要采用随即参数初始化的方式而不是直接令W=0,b=0?
习题4-1 对于一个神经元 ,并使用梯度下降优化参数w时,如果输入x恒大于0,其收敛速度会比零均值化的输入更慢。
,并使用梯度下降优化参数w时,如果输入x恒大于0,其收敛速度会比零均值化的输入更慢。
证明:
首先,理解什么是零均值化?有什么作用?
在全连接网络模型中,将输入的x值进行零均值化是一种预处理方法,旨在将训练集中的每个输入值x减去其均值,以0为中心,满足均值为0。这样做的优点是在反向传播时加快网络中每层权重参数的收敛,避免Z型更新的情况,从而加快神经网络的收敛速度。此外,零均值化还可以增加基向量的正交性,提高模型的训练效果。
下图是sigmoid函数的导数图:

零均值化的输入使得神经元值在0附近,sigmoid函数在零点处的导数最大,值为0.25,在反向传播过程中收敛速度最快。所以将输入值x零均值化,可以使x的值接近零,从而达到收敛速度最快(因为sigmoid函数的导数在0附近最大)。
习题4-5 如果限制一个神经网络的总神经元数量(不考虑输入层)为N+1,输入层大小为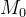 ,输出层大小为1,隐藏层的层数为L,每个隐藏层的神经元数量为
,输出层大小为1,隐藏层的层数为L,每个隐藏层的神经元数量为 ,试分析参数数量和隐藏层层数L的关系。
,试分析参数数量和隐藏层层数L的关系。
答:
在这里只考虑参数w的数量,暂不考虑权重b的数量。
神经网络为全连接神经网络,即层之间的神经元两两相连。易知,若第i层的神经元数量为x,第i+1层的神经元数量为y,则这两层的参数w数量为x*y。
现在假设:
输入层与第一个隐藏层之间的权重数量为T1
所有隐藏层之间的权重数量为T2
最后一个隐藏层和输出层之间的权重数量为T3
可以得到:
习题4-7 为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化?
答:
对于神经网络正则化,一般只对每一层仿射变换的w进行正则化惩罚,而不对偏置b进行正则化。
正则化是为了防止模型过拟合,降低过拟合风险,提升模型泛化能力的方法。过拟合一般表现为模型对于输入的微小改变产生了输出的较大差异,这主要是由于一些权重w过大,通过对||w||进行惩罚,可以缓解这种问题。在对输出结果的贡献中,参数b对于输入的改变是不敏感的,参数b的贡献只是加个偏置。如果对||b||进行惩罚,没有什么作用。
模型对于输入的微小改变产生了输出的较大差异,这是因为模型的“曲率”太大,而模型的曲率是由w决定的,b不贡献曲率。权重w会对不同的数据产生不同的加权值(w在每个神经元的贡献度分配不同),而偏置b对所有数据一视同仁,都加上固定值b。
反向传播过程中链式求导,一般调整的都是权重值w,偏置项b直接被约去了。(对输入进行求导,b直接约掉)
简单总结一下,神经网络中不对偏置项b进行正则化的原因主要有:
- 偏置项b对输入的改变是不敏感的。无论输入改变的大小,参数b的贡献只是加个偏置而已。
- 对bias进行正则化可能会引起欠拟合。
习题4-8 为什么在用反向传播算法进行参数学习时要采用随即参数初始化的方式而不是直接令W=0,b=0?
答:
因为如果参数都设为0,在第一遍前向计算的过程中所有的隐藏层神经元的激活值都相同。这样会导致隐藏层神经元没有区分性,模型在训练时无法区分不同的特征,从而陷入局部最小值。在反向传播时,所有权重更新也都相同,这种现象称为对称权重现象。直接令w=0,b=0,会让下一层神经网络中所有神经元进行着相同的计算,具有同样的梯度,同样权重更新。
而随机初始化参数可以避免梯度消失问题。在深度神经网络中,如果使用sigmoid或tanh等饱和激活函数,当神经元的激活值接近于0时,梯度接近于0,这会导致在反向传播过程中梯度消失。而随机初始化参数可以使得每个神经元的激活值都有所不同,从而避免在训练过程中出现梯度消失问题。
鱼书中提到此问题:

习题4-9 梯度消失问题是否可以通过增加学习率来缓解?
答:
1.首先了解什么是梯度消失问题?原因是什么?
梯度消失问题是指在神经网络中,随着隐藏层数目的增加,分类准确率反而下降的现象。这个问题在早期的BP网络中比较常见,具体表现为训练难以进行,且训练不再收敛,损失不再下降,精确度也不再提高。
梯度消失问题的原因在于对参数求偏导时,根据链式法则得到的连乘式中多个几乎为0的导数值连乘导致。导数小会导致每次更新时的值过小,从而使训练变得困难。比如激活函数为类似于sigmoid与tanh,其值太大或太小时导数都趋于0(左右趋近于饱和)。
以下是一些导致梯度消失的常见原因:
- 使用了深层网络:随着网络层数的增加,梯度传播过程中可能会经过多个非线性激活函数,这可能导致梯度消失问题。
- 不合适的损失函数:例如,如果使用sigmoid作为损失函数,其梯度可能在链式法则的连乘过程中逐渐消失。
- 激活函数的选择:一些激活函数(如sigmoid和tanh)在输入非常大或非常小的时候,它们的导数趋近于0,这可能导致在反向传播过程中梯度消失。
- 初始化权重:如果初始化的权重矩阵尺寸过小,也可能导致梯度消失问题。
在知乎文章上看到了一篇图,演示了BP算法基于梯度下降的策略:

可以看到,上式主要由两部分构成:多个激活函数偏导数的连乘,和多个权重参数的连乘。
如果激活函数求导后与权重相乘的积大于1,那么随着层数增多,求出的梯度更新信息将以指数形式增加,即发生梯度爆炸;如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生梯度消失。
2. 再来了解什么是学习率?它的作用是什么?
在反向传播过程中,学习率是一个非常重要的超参数,它决定了每次更新网络参数时所采用的步长。具体来说,学习率是用于调整网络参数的更新量,以使其能够更好地拟合训练数据。在每次迭代过程中,根据反向传播算法,会计算出当前网络参数下损失函数的梯度,然后根据学习率来决定将多少梯度信息用于更新网络参数。
在梯度下降法中,都是给定统一的学习率,整个优化过程中都以确定的步长进行更新,在迭代优化的前期中,学习率较大,则前进的步长就会较长,这时便能以较快的速度进行梯度下降,而在迭代优化后期,逐步减小学习率的值,减小步长,这样有助于算法的收敛,更容易接近最优解。
合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。如果学习率过大,可能会导致目标函数无法稳定收敛,导致模型在训练过程中波动较大;如果学习率过小,可能会导致目标函数收敛速度过慢,模型训练速度缓慢,甚至无法达到局部最小值。在实际应用中,可以通过调整学习率来控制模型的训练速度和精度。需要根据具体情况选择合适的学习率,以获得更好的训练效果。
结合了以上的知识点后,再考虑是否可以通过增加学习率来缓解梯度消失问题?
增加学习率不能解决梯度消失问题。实际上,增加学习率可能会使梯度消失问题更加严重。增加学习率只能改变权重的更新速度,而不能解决梯度消失问题。相反,如果增加学习率过大,可能会导致梯度爆炸,使得训练过程更加不稳定。
解决梯度消失问题的方法包括改变激活函数、使用ReLU等具有非线性特性的激活函数、调整隐藏层节点数等。
感谢各位博主提供的思路和解答参考,附上原文链接:
《神经网络与深度学习-邱锡鹏》习题解答-第4章 前馈神经网络 - 知乎 (zhihu.com)
NNDL 作业4:第四章课后题_梯度消失问题是否可以通过提高学习率缓解-CSDN博客
















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











