






目录
1. 对于一个神经元,并使用梯度下降优化参数w时如果输入x恒大于0,其收敛速度会比零均值化的输入更慢。
2. 如果限制一个神经网络的总神经元数量(不考虑输入层)为N +1,输入层大小为 ,输出层大小为 1,隐藏层的层数为L,每个隐藏层的神经元数量为 ,试分析参数数量和隐藏层层数L的关系。
3. 为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化?
4.为什么在用反向传播算法进行参数学习时要采用随机参数初始化的方式而不是直接令 w=0,b = 0?
1. 对于一个神经元
,并使用梯度下降优化参数w时如果输入x恒大于0,其收敛速度会比零均值化的输入更慢。
零均值化:零均值化是指将数据集中的每个样本减去其均值,使得数据的均值为零。这个操作可以通过以下公式表示:
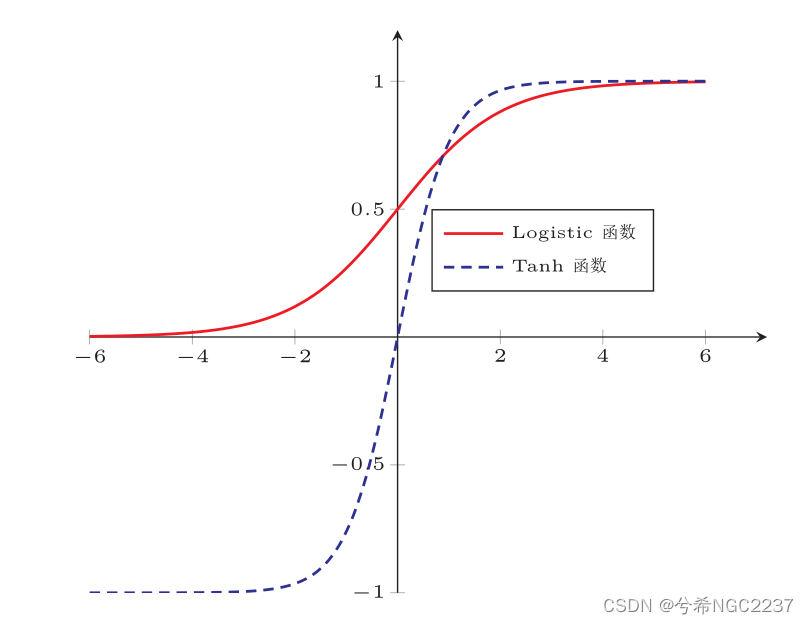
由零均值化的定义可知:将一个数据集零均值化,是使用原始数据减去原始数据的均值,使得零均值化后的数据分布在0附近,使得数据分布更加标准化,梯度下降优化参数收敛速度更快。在激活函数中,如下图:
|
|
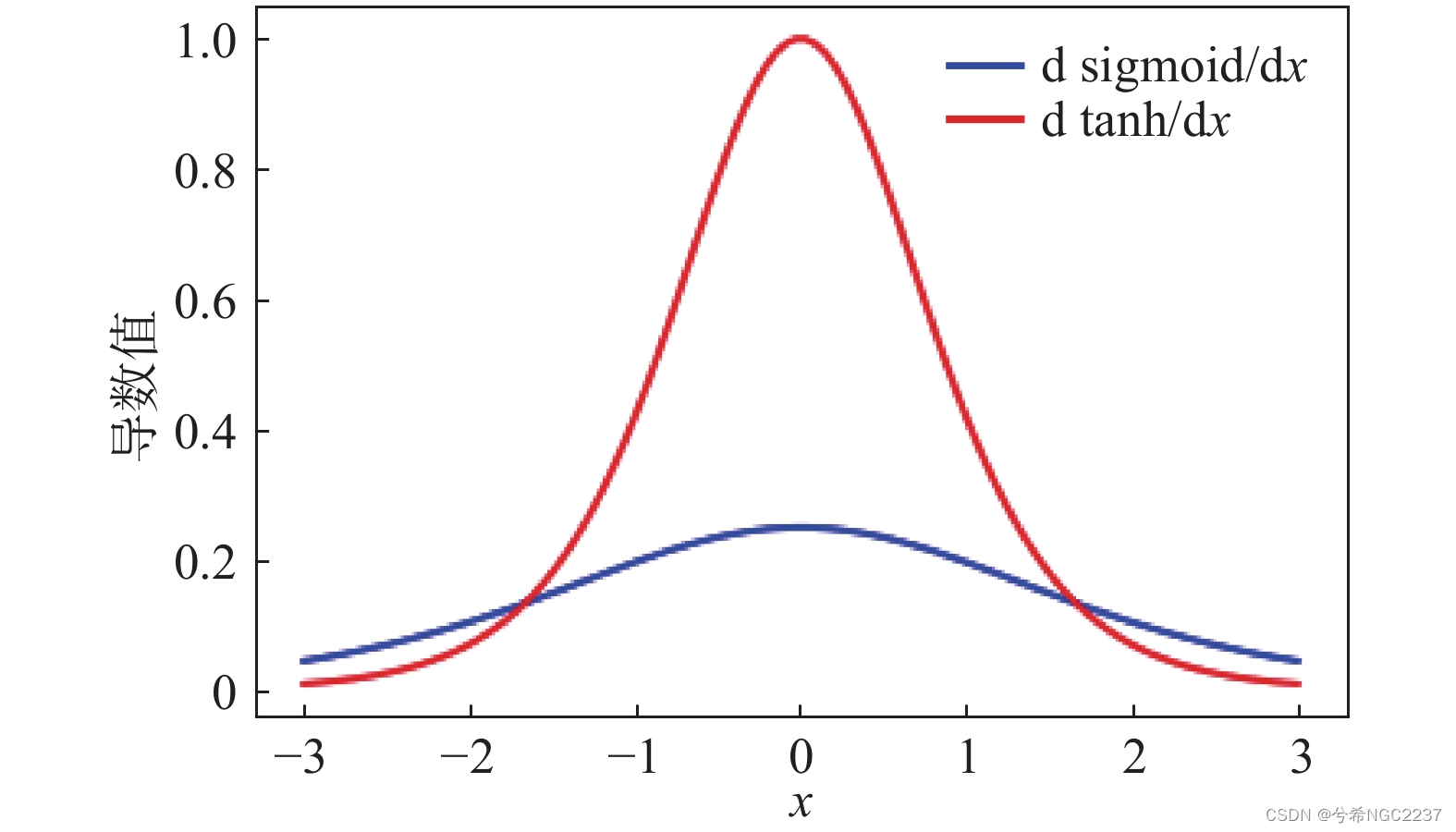
饱和状态:由饱和状态的定义,sigmoid函数和Tanh函数都属于两端饱和,ReLU函数也属于左饱和。

当输入x恒大于0时,神经元的激活函数很有可能处于饱和状态,梯度变得非常小,导致梯度下降算法收敛缓慢。而零均值化的输入可以使得数据分布主要集中0附近,在激活函数的非饱和状态,减少了饱和状态的出现,从而提高了梯度的大小,加速了梯度下降算法的收敛速度。
2. 如果限制一个神经网络的总神经元数量(不考虑输入层)为N +1,输入层大小为
,输出层大小为 1,隐藏层的层数为L,每个隐藏层的神经元数量为
,试分析参数数量和隐藏层层数L的关系。
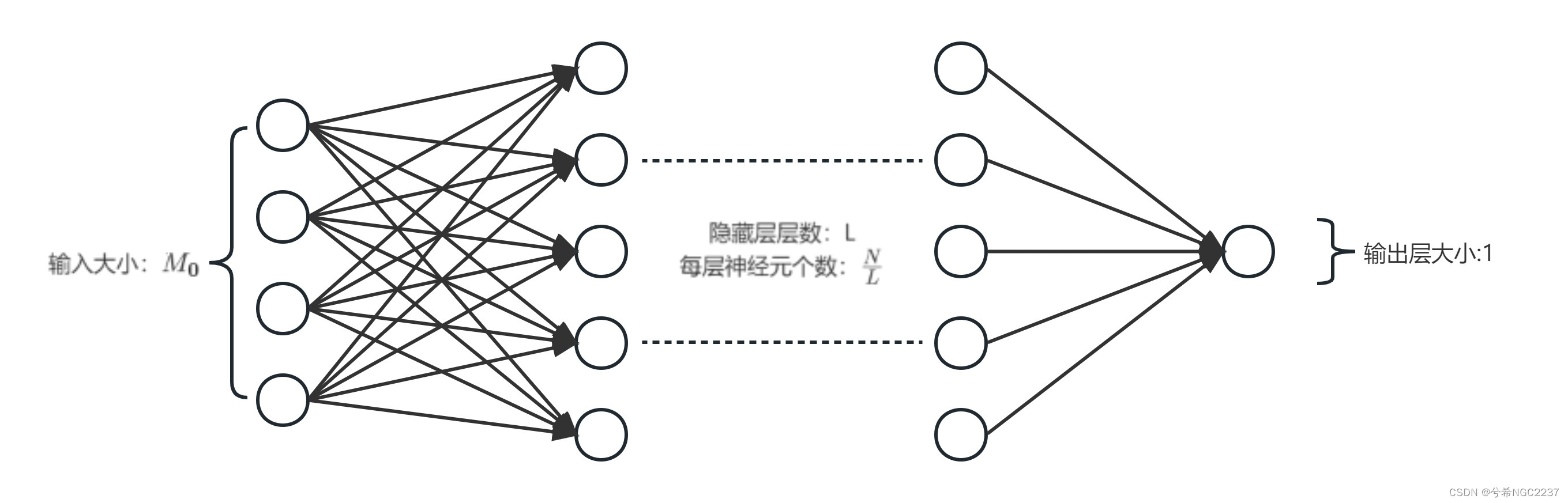
由题:首先计算参数数量(不算偏置)
- 输入层到第一个隐藏层的参数数量:
,
-
第一个隐藏层到第二个隐藏层之间的参数数量:
-
隐藏层之间参数数量:
-
最后一个隐藏层到输出层的参数数量:
-
总的参数数量:
-
参数数量和隐藏层层数L的关系:
3. 为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化?
正则化:是通过在模型的损失函数中添加一个正则化项来限制模型的复杂度,从而防止过拟合,提高模型的泛化能力。过拟合为对于微小的输入改变即会出现较大的输出偏差,导致过拟合的主要原因是权重系数w;
偏置参数b在神经网络中起到平移激活函数的作用,它可以调整神经元的输出,使得模型能够更好地拟合数据。与权重参数w不同,偏置参数b不会改变输入特征的权重,只是在激活函数中引入一个偏移量。因此,对偏置参数b进行正则化并不会对模型的复杂度产生明显的影响。
对偏置参数b进行正则化也可能会导致模型更趋向于简单(正则化会倾向于使参数值接近于零),从而出现欠拟合的问题,不利于模型的训练和泛化能力的提升。
4.为什么在用反向传播算法进行参数学习时要采用随机参数初始化的方式而不是直接令 w=0,b = 0?
神经网络模型通常是非凸的,存在多个局部最优解。如果将所有权重参数初始化为0,那么所有神经元将以相同的步长更新,容易陷入局部最优解。而随机参数初始化可以可以打破对称性,避免所有的神经元都输出相同的结果,从而提高模型的表达能力,增加模型探索的多样性,有助于避免陷入局部最优解,提高了模型的泛化能力。
5.梯度消失问题是否可以通过增加学习率来缓解?
梯度消失: 误差从输出层反向传播时,在每一层都要乘以该层的激活函数的导数,在使用sigmoid型函数时:其值域都小于等于1,并且它们的饱和区导数接近于0,误差经过每层都会不断衰减。当层数很深时,梯度就会不断衰减,直至消失,就是梯度消失问题。反向传播过程中的梯度是通过链式法则计算的,每一层的梯度是上一层梯度和当前层的权重矩阵的乘积。当使sigmoid型函数作为激活函数时,它的导数值域都小于等于1,并且在饱和区导数接近于0。这意味着:在每一层,梯度都会乘以一个小于等于1的值,导致梯度逐渐变小,逐渐接近于0,参数更新较慢甚至停止更新。
学习率是控制权重更新的步长,它决定了每次迭代中权重的调整幅度。增加学习率可能有助于缓解梯度消失问题,但并非一定有效。增加学习率可以使梯度更新幅度增加,有时可以跳出梯度较小的区域。然而,过大的学习率可能导致训练不稳定,甚至发散,产生梯度爆炸。(梯度爆炸:在神经网络的反向传播过程中,梯度值变得非常大,导致权重参数的更新过大,使得模型的训练变得不稳定甚至无法收敛。)















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









