







目录
习题4-2
试设计一个前馈神经网络来解决XOR问题,要求该前馈神经网络具有两个隐藏神经元和一个输出神经元,并使用ReLU作为激活函数
- XOR问题介绍
- 代码实现
XOR问题介绍:
对于“XOR"大家并不陌生,在很多课程中都有遇到,它是一个数学逻辑运算符号,在计算机中表示为XOR,在数学中表示为 ,学名为“异或”。
异或问题(exclusive OR, XOR、 EOR、 EX-OR)。 1969 年, Marvin Minsky 出版《感知器》一书,指出了神经网络的两个关键缺陷: 一是感知器无法处理 “异或” 回路问题; 二是当时的计算机无法支持处理大型神经网络所需要的计算能力。这些论断使得人们对以感知器为代表的神经网络产生质疑, 并导致神经网络的研究进入了十多年的 “冰河期”。可以认为感知器是一层前馈神经网络(不含输入层)。
感知机(一层前馈神经网络)无法实现异或问题,这主要是因为一层前馈神经网络只能表示线性空间,而异或问题属于非线性空间内的问题。
异或是对两个运算元的一种逻辑分析类型,当两两数值相同时为否,而数值不同时为真。异或的真值表如下:
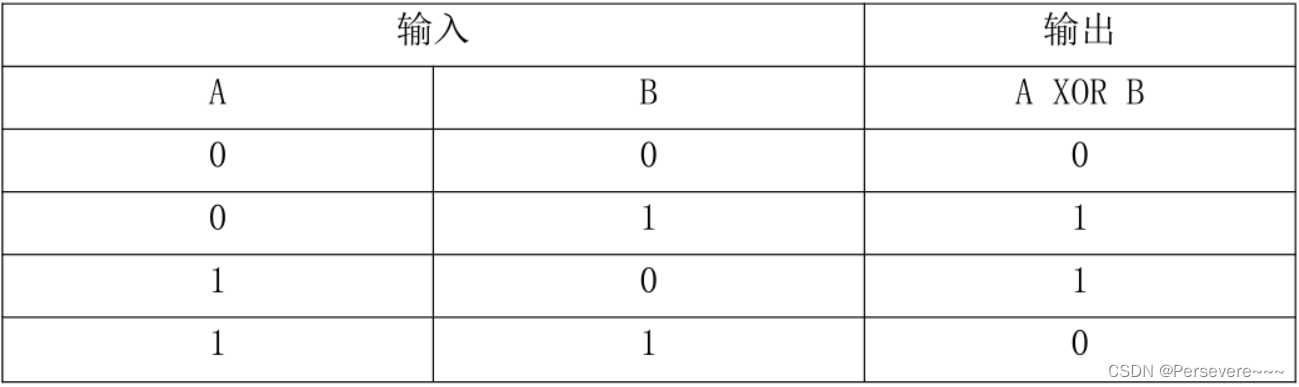
异或(XOR)问题可以看做是单位正方形的四个角,响应的输入模式为(0,0),(0,1),(1,1),(1,0)。如图所示:
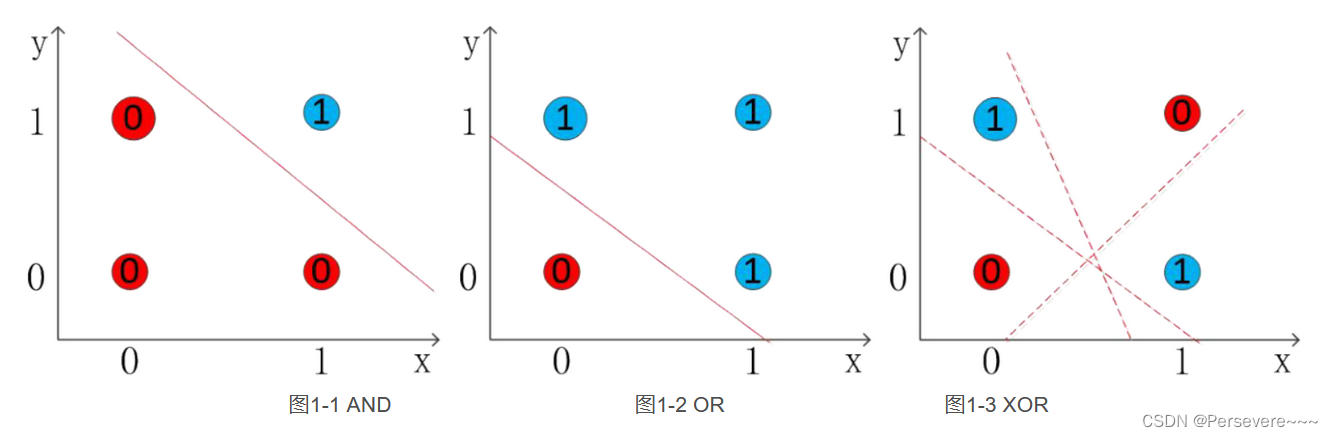
为了采用前馈神经网络解决XOR问题,首先我们通过引入其他逻辑运算与XOR问题进行对比分析,从而设计适合解决XOR运算的网络结构模型。如图1-1和图1-2所示,图中的直线是决策边界。在逻辑运算与、或运算中我们总可以找到一条直线对它们进行准确的分类,它们属于线性可分。然而在图1-3所示的XOR问题中,我们无法找到一条直线将其进行准确的分类,XOR属于一种线性不可分。由于单层神经网络只能解决线性问题,无法解决非线性问题,异或问题属于非线性问题,所以要解决XOR运算问题,需要生成非线性的决策边界。
XOR运算网络结构图示为:
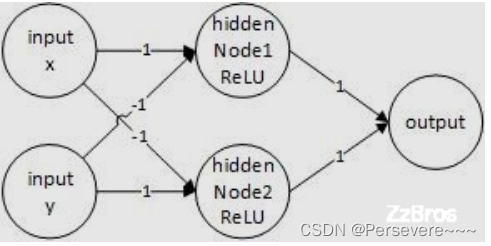
具体过程:
整个网络的计算为:
可以给出XOR问题的一个解。令
以及
我们现在可以了解这个模型如何处理一批输入。令X表示设计矩阵,它包含二进制输入空间中全部的四个点,每个样本占一行,那么矩阵表示为
神经网络的第一步是将输入矩阵乘以第一层的权重矩阵:
然后,我们加上偏置向量c,得到
在这个空间中,所有的样本都处在一条斜率为1的直线上。当我们沿着这条线移动时,输出需要从0升到1,然后再将回0。线性模型不能实现这样的一种函数。为了对每个样本求值,我们使用整流线性变换(即ReLU函数):
这个变换改变了样本间的关系,它们不再处于同一条直线上。
我们最后乘以一个权重向量w得:
神经网络对这一批次中的每个样本都给出了正确的结果。
代码实现:
# 使用Pytorch解决XOR问题
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
# 输入和输出数据
data = np.array([[0, 0, 1], [0, 1, 1],
[1, 0, 0], [1, 1, 0]], dtype='float32')
x = data[:, :2]
y = data[:, 2]
# 初始化权重变量
def weight_init_normal(m):
classname = m.__class__.__name__
if classname.find('Linear') != -1:
m.weight.data.normal_(0.0, 1.)
m.bias.data.fill_(0.)
class XOR(nn.Module):
def __init__(self):
super(XOR, self).__init__()
self.fc1 = nn.Linear(2, 2) # 一个隐藏层 2个神经元
self.fc2 = nn.Linear(2, 1) # 输出层 1个神经元
'''
# 使用'torch.nn.ReLU'定义 relu 激活函数
self.act = torch.nn.ReLU()
'''
def forward(self, x):
'''
h1 = self.act(self.fc1(x))
h2 = self.act(self.fc2(h1))
'''
h1 = F.sigmoid(self.fc1(x)) # 尝试过用ReLU作为激活函数, 太容易死亡ReLU了.
h2 = F.sigmoid(self.fc2(h1))
return h2
net = XOR()
net.apply(weight_init_normal)
x = torch.Tensor(x.reshape(-1, 2))
y = torch.Tensor(y.reshape(-1, 1))
# 定义loss function
loss_function = nn.BCELoss() # MSE
# 定义优化器
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9) # SGD
# 训练
for epoch in range(1000):
optimizer.zero_grad() # 清零梯度缓存区
out = net(x)
loss = loss_function(out, y)
print(loss)
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 测试
test = net(x)
print("input is {}".format(x.detach().numpy()))
print('out is {}'.format(test.detach().numpy()))

尝试过使用ReLU函数作为激活函数, 太容易死亡ReLU了,试了很多次,没能得到结果,最后换成了使用sigmoid函数。
习题4-3
试举例说明死亡ReLU问题,并给出解决方法。
上一题中,在使用ReLU函数作为激活函数时, 就出现了死亡ReLU问题:

在反向传播过程中,如果学习率比较大,一个很大的梯度经过ReLU神经元,可能会导致ReLU神经元更新后的偏置和权重是负数,进而导致下一轮正向传播过程中ReLU神经元的输入是负数,输出是0。由于ReLU神经元的输出为0,在后续迭代的反向过程中,该处的梯度一直为0,相关参数不再变化,从而导致ReLU神经元的输入始终是负数,输出始终为0。即为“死亡ReLU问题”
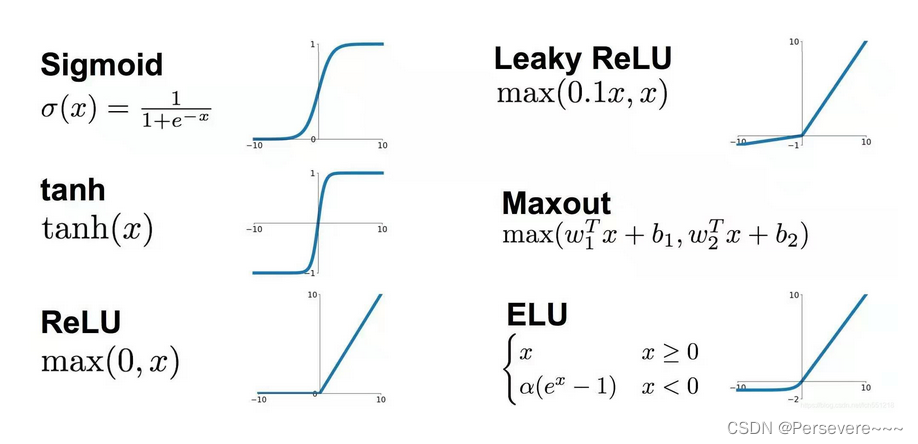
下图分别是ReLU函数图像和导函数图像,可以发现:当输入大于0时,局部梯度永远不会为0,比较有利于梯度流的传递。

ReLU函数作为激活函数的特点:
优点:
1、解决了梯度消失问题 (在正区间)
2、计算速度非常快,只需要判断输入是否大于0
3、收敛速度远快于Logistic和Tanh
缺点:1、ReLU的输出不是零中心化
2、Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) 学习率太大导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将学习率设置太大或使用adagrad等自动调节学习率的算法。
3、ReLU在 x > 0时,导数为常数1的好处就是在链式法则中不会出现梯度消失,但梯度下降的强度就完全取决于权值的乘积,这样就可能会出现梯度爆炸问题。解决这类问题:一是控制权值,让它们在(0,1)范围内;二是做梯度裁剪,控制梯度下降强度
在实际使用中,为了避免上述情况,有几种
ReLU的变种也会被广泛使用。
解决方法有[书中86-88页]:
- 使用带泄露的ReLU
- 使用带参数的ReLU
- 使用ELU函数
- 使用Softplus函数
ELU、PReLU、LeakyRelu都是让Relu在自变量小于0时函数值也是一个小于0的值,从而让w小于令0在后期有机会更新为正值。
习题4-7
为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化?
正则化的作用是为了限制模型的复杂度避免模型过拟合,提高模型的泛化能力。
对于某个神经元的输入来说,
对于样本特征向量X,其对input的贡献只与权重向量W有关。
而过拟合一般表现为模型对于输入的微小改变产生了输出的较大差异,这主要是由于有些参数W过大的关系,通过对进行惩罚,可以缓解这种问题。
而偏置b,因为在对输出结果的贡献中,参数b对于输入的改变是不敏感的,不管输入改变是大还是小,参数b的贡献就只是加个偏置而已,所以不需要考虑对b进行正则化。
或者说,模型对于输入的微小改变产生了输出的较大差异,这是因为模型的“曲率”太大,而模型的曲率是由W决定的,b不贡献曲率(对输入进行求导,b是直接约掉的)。
习题4-8
为什么在用反向传播算法进行参数学习时要采用随机参数初始化的方式而不是直接令W=0,b=0?
反向传播就是要将神经网络的输出误差,一级一级地传播到输入。在计算过程中,计算每一个w对总的损失函数的影响,即损失函数对每个w的偏导。根据w的误差的影响,再乘以步长,就可以更新整个神经网络的权重。当一次反向传播完成之后,网络的参数模型就可以得到更新。更新一轮之后,接着输入下一个样本,算出误差后又可以更新一轮,再输入一个样本,又来更新一轮,通过不断地输入新的样本迭代地更新模型参数,就可以缩小计算值与真实值之间的误差,最终完成神经网络的训练。
若将𝑾和𝒃都初始化为0,则在输入层之后的所有隐藏层神经元接收到的输入都是一样的,那么在使用反向传播算法进行梯度的传递时,每一隐藏层的权重梯度值都是相同的,这就导致了权重只能向同一方向下降,这样会导致隐藏层神经元没有区分性。这种现象称为对称权重现象。
习题4-9
梯度消失问题是否可以通过增加学习率来缓解?
梯度消失问题:
网络层之间的梯度(值小于 1.0)重复相乘导致的指数级减小会产生梯度消失;
原因: 主要是因为网络层数太多,太深,导致梯度无法传播。本质应该是激活函数的饱和性。
表现:神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层产生的偏差就因为乘了很多的小于1的数而越来越小,最终就会变为0,从而导致层数比较浅的权重没有更新,这就是梯度消失。
是否可以通过增加学习率来缓解:
分情况,在深层神经网络的浅层如果使用较大的学习率可能会导致模型跨过全局最优点而进入局部最优点。
但在网络的深层使用较大的学习率则可以保证网络的参数仍然在被更新,以达到更好的学习效果。
在一定程度上可以缓解。适当增大学习率可以使学习率与导数相乘结果变大,缓解梯度消失;过大学习率可能梯度巨大,导致梯度爆炸。
总结:
这次的作业与上次的实验作业可以结合起来看,在动手做完实验以后,理解运行了代码,对模型的效果有了亲身体验,再完成这些相关的理论部分的习题,也是对实验的理论知识的补充和文字总结,两者结合以后就会更完整,更好理解。
这次作业给自己留下的印象比较深,这种在实验时遇到了问题之后,留下了悬念,埋下了伏笔,然后在完成作业时解决这些问题,就有种呼应上了的感觉,这种感觉,真的真的很不错,就很好。
参考链接:
https://blog.csdn.net/weixin_36670529/article/details/100689846
https://blog.csdn.net/sinat_28178805/article/details/118764250
https://blog.csdn.net/lch551218/article/details/118860970
https://blog.csdn.net/weixin_43650749/article/details/106109163















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









