






目录
一、概念
模型评估是机器学习中非常重要的一个概念,它指的是对训练出来的模型进行评估和比较,以便了解模型的性能和一般化能力,从而更好地选择、优化和部署模型。
通常情况下,模型评估涉及到以下几个方面:
1、数据集划分:为了保证评估结果的客观性和可靠性,我们需要将数据划分成训练集、验证集和测试集。其中训练集用于模型的训练,验证集用于模型的参数调整和选择,测试集则是最终用于评估模型性能的数据集。
2、度量标准:为了度量模型的性能,我们需要选择适当的度量标准。例如,在分类问题中,我们通常使用准确率、精确率、召回率和 F1 分数等指标来评估模型的性能;在回归问题中,我们通常使用均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)等指标来评估模型的性能。
3、交叉验证:为了避免数据划分不恰当带来的影响,我们可以使用交叉验证的方法来进行模型评估。常见的交叉验证方法包括 k-fold 交叉验证和留一法交叉验证等。
4、模型比较:在选择模型时,我们通常需要将不同模型的性能进行比较。通过对比不同模型的评估指标,可以了解它们在不同数据集上的性能表现和优缺点,从而更好地选择最适合自己需求的模型。
总之,模型评估是机器学习中至关重要的一个环节。仅有良好的数据和算法并不能保证一个好的模型,我们还需要通过模型评估来确定模型的性能和可靠性,并根据评估结果对模型进行进一步的调整和改进。
二、常见的模型分类评估指标
机器学习中常见的模型分类评估指标主要包括以下几个:
1、准确率(Accuracy):准确率是最简单直观的模型评估指标,它表示模型在所有样本中正确分类的比例。然而,当数据集存在类别不平衡问题时,准确率可能会产生误导。
描述:所有分类正确的样本数占总样本数的比例。
公式:
2、混淆矩阵:一个用来显示模型对每个类别的预测数量和实际数量。
主要组件:真正例(True Positive,TP),假正例(False Positive,FP),真反例(True Negative,TN),假反例(False Negative,FN)。
| True Positive | True Negative | |
| Predicted Positive | TP | FP |
| Predicted Negative | FN | TN |
3、精确率(Precision)和召回率(Recall):精确率和召回率常用于二分类问题的评估。精确率表示被模型正确预测为正类的样本占所有预测为正类样本的比例,召回率表示被模型正确预测为正类的样本占真实正类样本的比例。这两个指标可以帮助我们评估模型对正类和负类的分类能力。
精确率公式:
召回率公式:
4、F1 分数(F1-Score):F1 分数综合考虑了精确率和召回率,是精确率和召回率的调和均值。它可以帮助我们综合评估模型的分类性能,并在精确率和召回率之间找到一个平衡点。
5、ROC 曲线和 AUC:ROC 曲线(Receiver Operating Characteristic Curve)和 AUC(Area Under the Curve)常用于评估二分类模型在不同阈值下的性能。ROC 曲线以真正率(True Positive Rate)为纵轴,假正率(False Positive Rate)为横轴绘制,AUC 表示 ROC 曲线下的面积,可以作为评估模型分类性能的指标。AUC 的取值范围在 0.5 到 1 之间,值越大表示模型性能越好。
除了上述常见的评估指标,还有一些其他的指标也可以用于模型分类评估,如特异度(Specificity)、受试者工作特征曲线(Receiver Operating Characteristic Curve, ROC)等,具体选择哪些指标要根据具体问题和需求来决定。
需要注意的是,不同的模型和任务可能适用不同的评估指标。在选择评估指标时,需要根据具体情况考虑模型的应用场景、数据的特点以及对不同类型错误的重视程度。
三、两种相关曲线
1、ROC曲线
ROC(Receiver Operating Characteristic)曲线是用于二分类问题中评价模型性能的一种方法。它将真正率(True Positive Rate, TPR)作为纵轴,假正率(False Positive Rate, FPR)作为横轴。
首先,我们需要导入需要的库:
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC然后,我们可以创建一个模拟的二分类问题并分解为训练和测试集:
X, y = make_classification(n_samples=1000)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.4, random_state=42)接下来,我们可以训练SVM分类器:
clf = SVC(probability=True)
clf.fit(X_train, y_train)然后,我们可以使用训练好的SVM预测测试集的概率,然后用这个概率来计算ROC曲线:
y_pred = clf.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
roc_auc = auc(fpr, tpr)最后,我们可以绘制ROC曲线:
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic Example')
plt.legend(loc="lower right")
plt.show()运行结果如下:
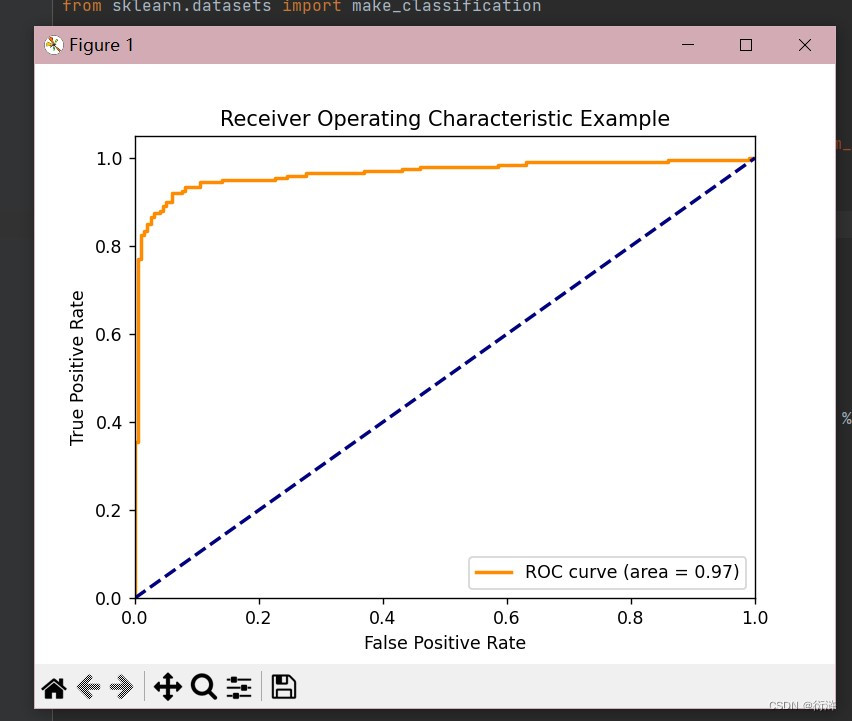
2、PR曲线
PR曲线,即Precision-Recall曲线,是一种用于评估分类器在不同阈值下的性能的工具。它基于查全率(Recall)和查准率(Precision)这两个评价指标。
1、查准率(Precision): 在被预测为正样本的样本中,实际上是正样本的比例。Precision = TP / (TP + FP),其中TP是真正样本数,FP是假正样本数。
2、查全率(Recall): 在所有实际上是正样本的样本中,被预测为正样本的比例。Recall = TP / (TP + FN),其中FN是假负样本数。
PR曲线的x轴是Recall,y轴是Precision。每个点对应一个决策阈值下的Precision和Recall,将所有阈值的点连线即可得到PR曲线。
PR曲线的主要应用场景是数据不均衡的情况。当正样本和负样本的数量差距很大时,相比ROC曲线,PR曲线更能反映模型的性能。
PR曲线的AUC(Area Under Curve,即曲线下面积)越接近1,模型的性能就越好。如果模型预测的结果完全正确,则PR曲线将成为一个直角,并且AUC为1。
样例:
from sklearn.metrics import precision_recall_curve, auc
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
X, y = make_classification(n_samples=1000)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.4, random_state=42)
clf = SVC(probability=True)
clf.fit(X_train, y_train)
y_score = clf.decision_function(X_test)
precision, recall, _ = precision_recall_curve(y_test, y_score)
pr_auc = auc(recall, precision)
plt.figure()
plt.plot(recall, precision, color='darkorange', label='PR curve (area = %0.2f)' % pr_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall curve')
plt.legend(loc="lower right")
plt.show()
运行结果如下:
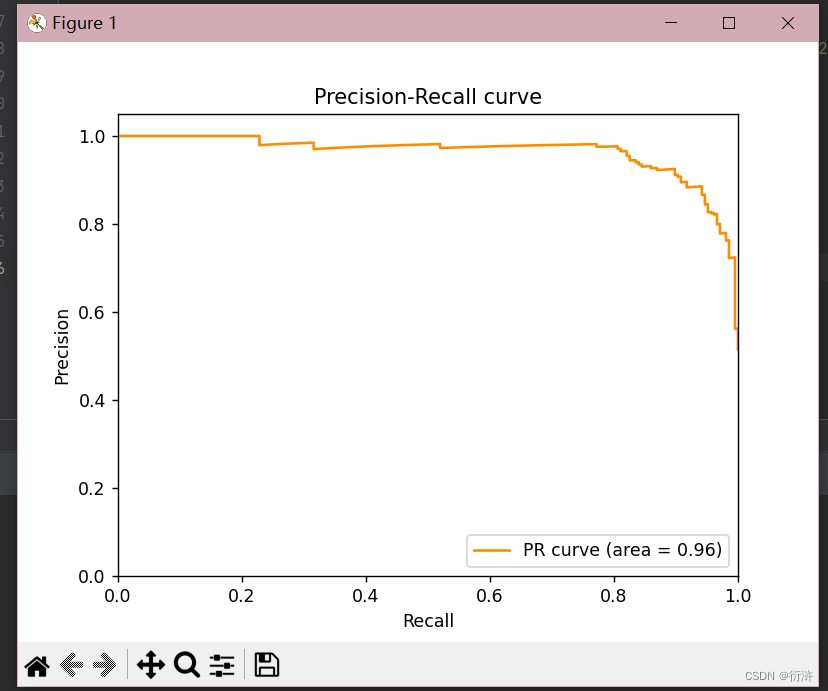
3、差异
1.坐标轴
ROC曲线的x轴是FPR,y轴是TPR。
PR曲线的x轴是Recall(或TPR),y轴是Precision。
2.应用场景
在正负样本均衡的情况下,ROC曲线是一个很好的性能度量
在正负样本不均衡的情况下,PR曲线往往更有信息量。
3.整体性能指标
ROC曲线使用AUC(曲线下的面积)。
PR曲线使用AP(Average Precision,曲线下的面积)。
总之,AUC是ROC曲线下的面积,它考虑了分类器在所有可能的决策边界下的性能。AP是PR曲线下的面积,它特别适用于正负样本不平衡的情况,提供了对分类器整体精确率的评估。选择AUC还是AP取决于具体问题和数据集的性质。在正负样本严重不平衡的情况下,AP可能会提供更真实、更有信息量的评估。
四、小结
在机器学习中,模型评估是非常重要的一环,关系到我们是否能准确地了解模型的性能。模型评估通常涉及如下步骤:
1、数据的划分:将数据划分为训练集和测试集。训练集用于拟合模型,测试集用于评估模型。标准的划分比例一般是70%的训练数据和30%的测试数据。在数据有限的情况下,我们可以使用交叉验证划分数据,比如k-折交叉验证,留一交叉验证等。
2、模型的训练:选择合适的机器学习模型,并用训练集进行训练。
3、模型的预测:使用训练好的模型对测试集进行预测。
4、评估指标的选择:选择合适的评估指标来衡量模型的性能。对于分类问题,我们可以选择准确率,精确率,召回率,F1-Score,ROC曲线,AUC等指标。对于回归问题,我们可以选择均方误差,均方根误差,平均绝对误差,R2分数等指标。
5、模型性能的评估:根据预测的结果和实际的结果,使用选择的评估指标计算模型的性能。
在这一系列的实验过程中,我们需要注意:
1、测试集不应参与模型训练,否则容易引发过拟合(模型在训练集上表现优秀,在测试集上表现糟糕)。
2、评估指标的选择应符合实际情况。比如在类别不平衡的情况下,使用准确率可能会给出误导,此时精确率,召回率和F1-Score就更为合适。
3、应用交叉验证可以有效防止过拟合及欠拟合,提高模型的稳定性和泛化性能。
4、对模型复杂度和训练数据量的控制也是提高模型性能的重要手段,通常通过调整超参数或应用正则化技术实现。
最后,我们需要记住,更复杂的模型并不一定能得到更好的性能,模型的选择应根据问题的实际需要,遵循奥卡姆剃刀原则,即在能解决问题的所有模型中选取最简单的一个。















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









