






目录
一、最大间隔与分类
1、基本概念
支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,用于二分类和多分类任务。它的基本思想是找到一个最大间隔超平面,将不同类别的样本点分开。
最大间隔是指在特征空间中,使得两个不同类别样本点之间的距离最大化的超平面。这个超平面可以最大程度地降低训练样本分类错误的风险。
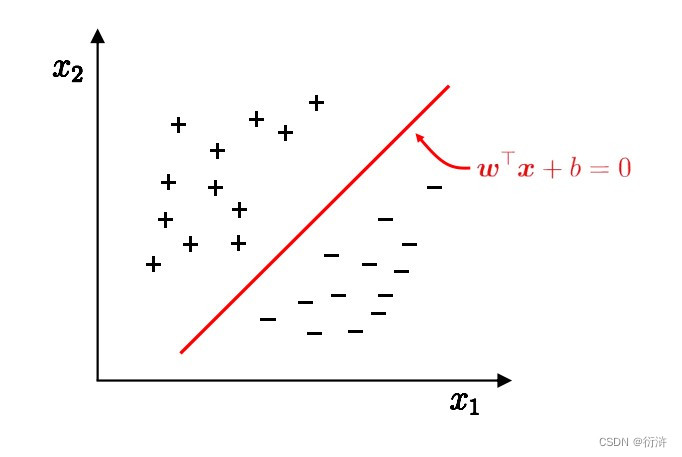
那么如何选择”正中间” , 容忍性好, 鲁棒性高, 泛化能力最强的超平面呢?
2、最大化决策边界的边缘
在支持向量机中,最大化决策边界的边缘是指找到一个超平面,使得它与离它最近的两个不同类别的样本点之间的距离最大化。这个距离被称为“边缘”(margin)。
具体来说,假设有两个不同类别的样本点,分别用x1和x2表示,它们位于超平面的两侧。超平面可以表示为w*x+b=0,其中w为法向量,b为偏置项。则x1和x2到超平面的距离分别为:
d1 = |wx1 + b| / ||w|| d2 = |wx2 + b| / ||w||
其中,||w||表示w的模长。由于要使得超平面与两个样本点之间的距离最大化,因此我们需要找到一个w和b,使得下面的式子最大化:
min(d1, d2)
经过一些变换之后,上式可以转化为下面的形式:
y1(wx1+b) ≥ 1 y2(wx2+b) ≤ -1
其中,y1和y2分别表示x1和x2的类别标签,假设它们的取值为+1和-1。这个式子可以写成以下的形式:
y_i(w*x_i+b) ≥ 1
对于所有满足上述条件的w和b,我们需要找到一个最大的边缘,即max(d1, d2) = 2/||w||。因此,我们需要最大化:
minimize 1/2 * ||w||^2
subject to y_i(w*x_i+b) ≥ 1
这个问题可以通过拉格朗日乘子法转化为求解一个对偶问题,进而得到支持向量机的分类器。
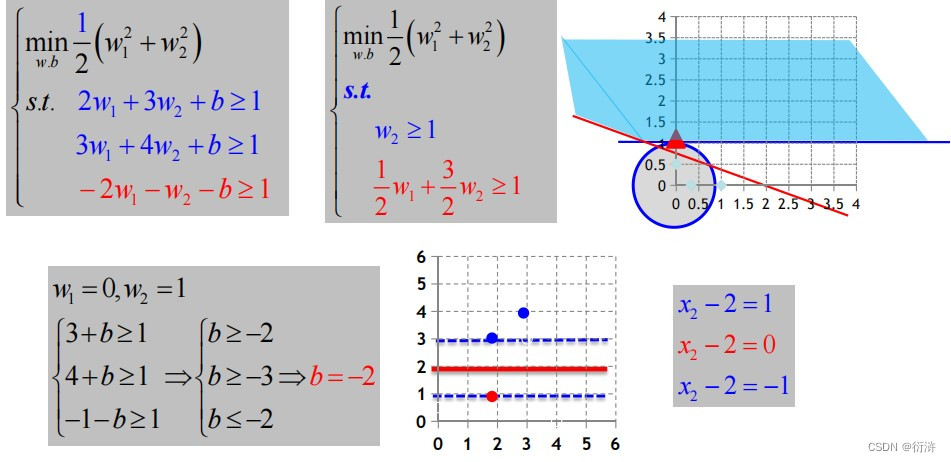
二、对偶问题
在支持向量机(Support Vector Machine,SVM)中,对偶问题是通过拉格朗日乘子法将原始问题转化为一个等价的优化问题。对偶问题的求解可以更高效地找到最优解。
首先,我们来看一下支持向量机的原始问题:
原始问题: minimize 1/2 * ||w||^2 subject to y_i(w*x_i+b) ≥ 1
其中,w是超平面的法向量,b是偏置项,(x_i, y_i)是训练数据的特征和标签。
接下来,我们使用拉格朗日乘子法对原始问题进行变换。我们给每个约束条件引入一个拉格朗日乘子α_i,得到拉格朗日函数:
L(w, b, α) = 1/2 * ||w||^2 - ∑(α_i * [y_i * (w*x_i + b) - 1])
其中,∑表示对所有训练样本的求和。
然后,我们针对参数w和b分别求导数,并令导数为零,可以得到以下两个式子:
∂L/∂w = w - ∑(α_i * y_i * x_i) = 0 (1) ∂L/∂b = ∑(α_i * y_i) = 0 (2)
将(1)式带入拉格朗日函数,可以得到对偶问题的形式:
maximize ∑(α_i) - 1/2 * ∑∑(α_i * α_j * y_i * y_j * (x_i * x_j))
其中,α_i是拉格朗日乘子,满足α_i ≥ 0,∑表示对所有训练样本的求和。
通过求解对偶问题,我们可以得到一组拉格朗日乘子的解α。然后,使用这些α计算超平面的法向量w和偏置项b:
w = ∑(α_i * y_i * x_i) b = y_j - ∑(α_i * y_i * (x_i * x_j))
其中,j是在支持向量上取的任意一个索引。
最后,利用得到的w和b构建最终的支持向量机分类器。对于新的样本点x,根据决策函数 f(x) = w*x + b 的结果来进行分类。
通过求解对偶问题,我们可以更高效地找到支持向量机的最优解,同时还可以通过拉格朗日乘子α获取支持向量的信息,从而进行模型解释和可视化等进一步分析。
三、核函数
若找不到能正确划分两类样本的超平面,我们可以将样本从原始空间映射到一个更高维的特征空间, 使得样本在这个特征空间内线性可分,即线性不可分—高维可分。
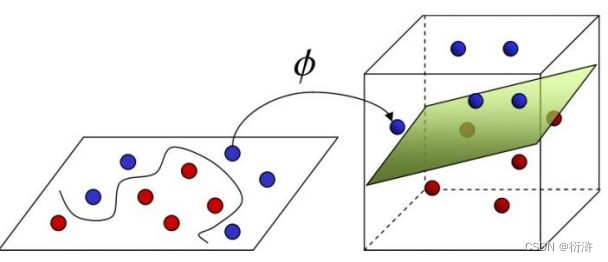
在支持向量机(Support Vector Machine,SVM)中,核函数(Kernel Function)是一种用于将输入数据映射到高维特征空间的技术。它可以有效地处理非线性可分的数据,并在计算上具有高效性。
核函数的作用是通过一个非线性变换将原始输入数据从低维空间映射到高维空间,使得在高维空间中的数据更容易被线性分类器(如支持向量机)进行分离。
核函数的定义如下:
K(x, y) = φ(x) · φ(y)
其中,K(x, y)表示核函数,x和y是输入样本的特征向量,φ(·)表示将输入数据从低维空间映射到高维空间的映射函数。
常见的核函数包括线性核函数、多项式核函数、高斯核函数(也称为径向基函数,RBF)等。不同的核函数适用于不同类型的数据分布。
以高斯核函数为例,其定义如下:
K(x, y) = exp(-γ ||x - y||^2)
其中,γ是控制高斯核函数衰减速度的参数,||·||表示向量的欧氏距离。
通过使用核函数,我们可以在不直接计算高维特征空间中的内积的情况下,隐式地利用核技巧计算内积,从而避免了高维空间的计算开销。这样,在低维空间中就能够进行高维特征空间中的分类任务,提高了算法的效率和性能。
一些常见核函数:

四、软间隔与正则化
当出现下列情况时,我们就引入“软间隔”的概念。
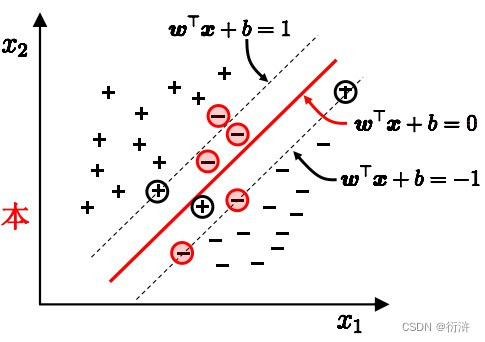
软间隔和正则化是支持向量机(Support Vector Machine,SVM)中用于处理数据不完全线性可分情况的两种技术。
软间隔(Soft Margin)允许在超平面分类时存在一些错误分类的样本。它的目标是在保持较好的分类能力的同时,尽量减少错误分类样本的数量。
在软间隔的支持向量机中,原始问题的约束条件变为:
y_i(w*x_i + b) ≥ 1 - ξ_i
其中,ξ_i表示松弛变量,它允许样本落在超平面的错误一侧。通过引入松弛变量,目标函数变为:
minimize 1/2 * ||w||^2 + C * ∑(ξ_i)
其中,C是一个调节参数,用于平衡分类间隔和错误分类样本数量的权重。较大的C会对错误分类样本施加较大的惩罚,使得分类间隔更严格;而较小的C允许有更多的错误分类样本。
通过调节C的值,我们可以控制模型对于错误分类的容忍程度。当C趋近于无穷大时,模型更加关注准确分类,即硬间隔支持向量机;当C取较小的值时,模型允许一定数量的错误分类,即软间隔支持向量机。
正则化是为了防止模型过拟合而引入的一种技术。在支持向量机中,引入正则化项可以在目标函数中加入对模型复杂度的惩罚。常用的正则化项是L1范数或L2范数。
通过在目标函数中加入正则化项,可以使得模型在优化过程中更倾向于选择较简单的权重向量w,避免过度依赖训练数据和噪声,从而提高模型的泛化能力。
正则化参数(通常表示为λ)控制正则化项的权重。较大的λ会增强正则化的作用,使得模型更加趋向于选择简单的解;而较小的λ则对正则化的影响较小,允许模型更灵活地拟合训练数据。
综上所述,软间隔和正则化都是在支持向量机中用于处理非线性可分问题和过拟合问题的技术。软间隔通过引入松弛变量允许一定数量的错误分类样本,而正则化通过加入正则化项来约束模型的复杂度。这些技术可以提高支持向量机的鲁棒性和泛化能力。
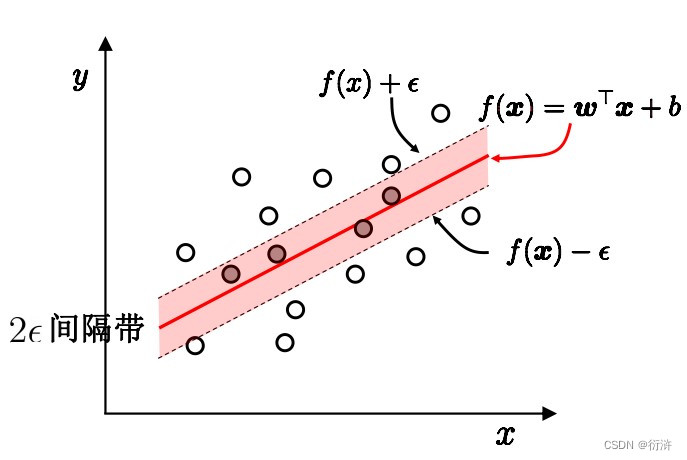
五、支持向量回归
支持向量回归(Support Vector Regression,SVR)是一种基于支持向量机(SVM)的回归方法。与传统的回归方法不同,SVR利用支持向量机的思想来建立回归模型。
在支持向量回归中,我们的目标是通过构建一个超平面,使得尽可能多的训练样本点落在超平面的边界内,并且超平面与这些点之间的距离最小。与分类问题中的硬间隔和软间隔不同,支持向量回归引入了一个称为ε-insensitive loss的概念。
ε-insensitive loss允许在一定程度上容忍样本的预测误差。具体来说,对于目标值y_i和预测值f(x_i),若它们的绝对差小于等于ε,则认为预测是准确的;若绝对差大于ε,则需要对预测误差进行惩罚。
支持向量回归的目标是求解最小化以下目标函数:
minimize 1/2 * ||w||^2 + C * ∑(ξ_i + ξ_i*)
其中,||w||是权重向量w的L2范数,C是一个调节参数,用于平衡模型复杂度和错误预测的权重,ξ_i和ξ_i*是松弛变量,用于容忍预测误差。
通过求解上述优化问题,可以得到支持向量回归模型的超平面和对应的权重向量w。
支持向量回归在处理回归问题时具有以下特点:
- 能够处理非线性关系:通过使用核函数,支持向量回归可以将数据映射到高维空间,从而处理非线性关系。
- 对异常值敏感度低:由于引入了ε-insensitive loss,支持向量回归对于部分异常值的存在具有一定的容忍性。
- 考虑到样本的相对重要性:只有位于边界上的支持向量样本点会对模型产生影响,从而减少了对于大量训练样本的依赖,降低了计算复杂度。
总而言之,支持向量回归是一种能够处理回归问题的机器学习方法,通过构建最优超平面来进行回归预测。它在非线性关系、异常值处理和样本选择等方面具有独特的优势。
六、实例
步骤1: 导入必要的库和模块
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler步骤2: 生成数据集并进行预处理
# 生成样本数据
X, y = make_blobs(n_samples=100, centers=2, random_state=0, cluster_std=0.5)
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 转换为张量
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32)步骤3: 定义支持向量机模型
class SVM(nn.Module):
def __init__(self):
super(SVM, self).__init__()
self.linear = nn.Linear(2, 1) # 输入特征维度为2,输出维度为1
def forward(self, x):
return self.linear(x)步骤4: 定义损失函数和优化器
model = SVM()
criterion = nn.HingeEmbeddingLoss() # 使用合页损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01)步骤5: 训练模型
num_epochs = 100
for epoch in range(num_epochs):
outputs = model(X_train)
loss = criterion(outputs.squeeze(), y_train) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数步骤6: 测试模型
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32)
outputs = model(X_test)
predicted = (outputs.squeeze() > 0).float()
accuracy = (predicted == y_test).sum().item() / y_test.size(0)
print("Test Accuracy: ", accuracy)七、总结
支持向量机(Support Vector Machine,SVM)是一种强大而灵活的监督学习算法,用于二分类和回归问题。下面是对支持向量机的学习总结:
-
支持向量机的原理:支持向量机通过在特征空间中找到一个最优超平面来进行分类或回归。最优超平面是使得训练样本离超平面的距离最大化的平面,同时保证分类或回归误差最小化。
-
支持向量:支持向量是离最优超平面最近的训练样本点。这些样本点对于确定最优超平面起着关键作用,因为它们决定了超平面的位置和方向。
-
硬间隔和软间隔:硬间隔指的是训练样本完全正确分类的情况,软间隔则允许一定程度上的分类误差。软间隔可以提高模型的鲁棒性,避免过拟合。
-
核函数:核函数是支持向量机处理非线性问题的重要工具。通过将数据映射到高维特征空间,支持向量机可以在低维空间中使用线性方法进行分类或回归。
-
C参数和正则化:C参数控制了模型的复杂度和错误预测的权重。较小的C值会使模型更加简单,容忍更多的分类或回归误差;较大的C值则会使模型更加复杂,力求减少分类或回归误差。
-
SVM的优点:支持向量机具有以下优点:
- 在高维空间中有效:通过使用核函数,支持向量机可以处理高维特征空间中的数据,并构建一个有效的分类或回归模型。
- 对于小样本数据有效:由于支持向量机主要依赖于支持向量,只有少数关键样本点对模型产生影响,因此它对于小样本数据的处理效果较好。
- 鲁棒性强:支持向量机通过最大化超平面与支持向量之间的距离,降低了对异常值的敏感性。
-
SVM的缺点:支持向量机也有一些缺点:
- 对大规模数据集不太友好:支持向量机在处理大规模数据集时可能会面临计算和内存方面的挑战。
- 参数选择较为困难:选择合适的核函数和调整参数(如C值)是支持向量机的一个挑战,需要通过交叉验证等方法来进行调优。
总而言之,支持向量机是一种强大的机器学习算法,适用于二分类和回归问题。它通过寻找最优超平面来进行分类或回归,并具有高维处理能力、鲁棒性强的优点。但在实际应用中,需要仔细选择合适的核函数和调整参数,以充分发挥支持向量机的性能。















 3419
3419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









