






目录
一、前言
Hadoop是一个开源的分布式系统基础架构,用于处理和分析大规模数据集。它由Apache基金会开发,并广泛用于各种场景,包括批处理、实时分析、数据挖掘和机器学习等。Hadoop的设计目标是提供一个能够在廉价硬件上运行,并处理大规模数据的可靠、高效、可扩展的存储和计算平台。由于Hadoop是一个分布式系统的基础架构,有着HDFS、MapReduce、YARN三大设计,市面上大多数其他的大数据框架都是以Hadoop为基础去使用的,比如Hive、Hbase、Pig、Sprark等。
那我们先要明白什么是分布式,为什么需要分布式。
分布式
分布式在于分,我一个人解决不了的问题,一群人一起解决,效率不就高很多啦,比如分布式存储:
一个100TB的文件 放到服务器里边去,太大啦,服务器也装不下这么大的文件
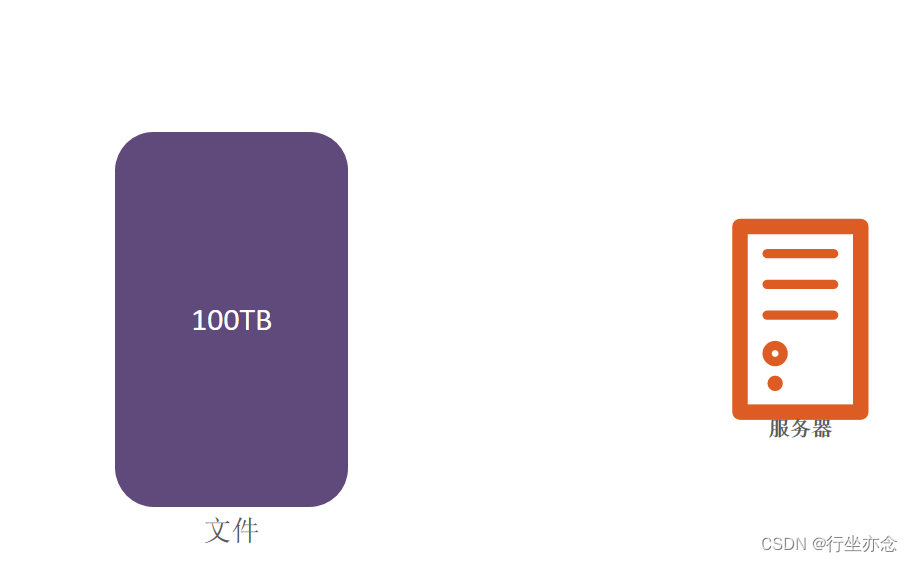
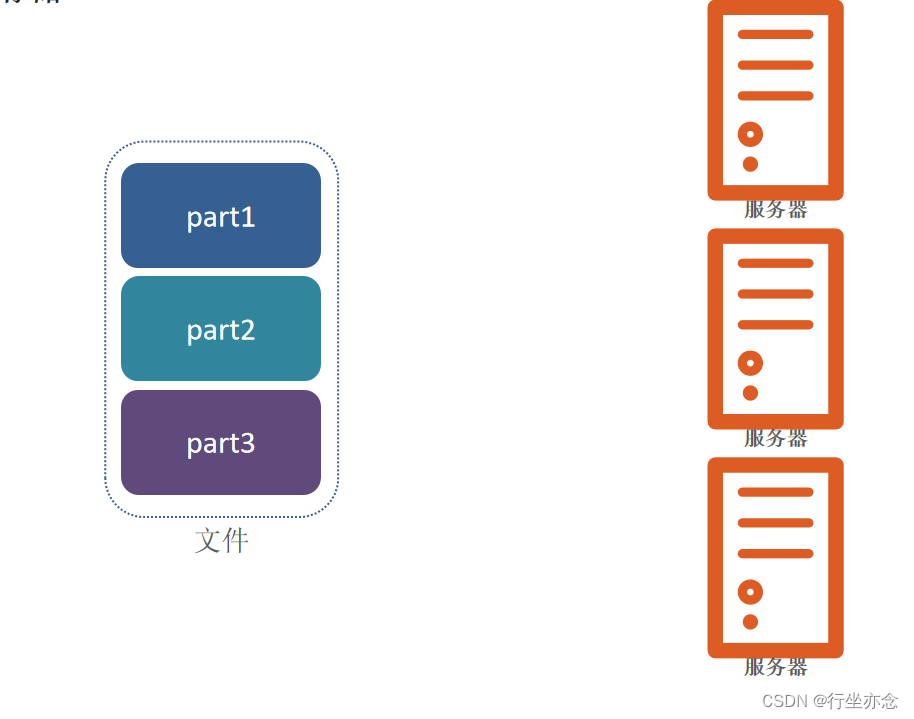
所以买了三台服务器,把文件分为三部分去存储,这样的话我不仅仅解决了存储的问题,我还有三倍的网络传输效率 和 三倍的磁盘写入效率,那样我不就能提升工作效率啦。
调度
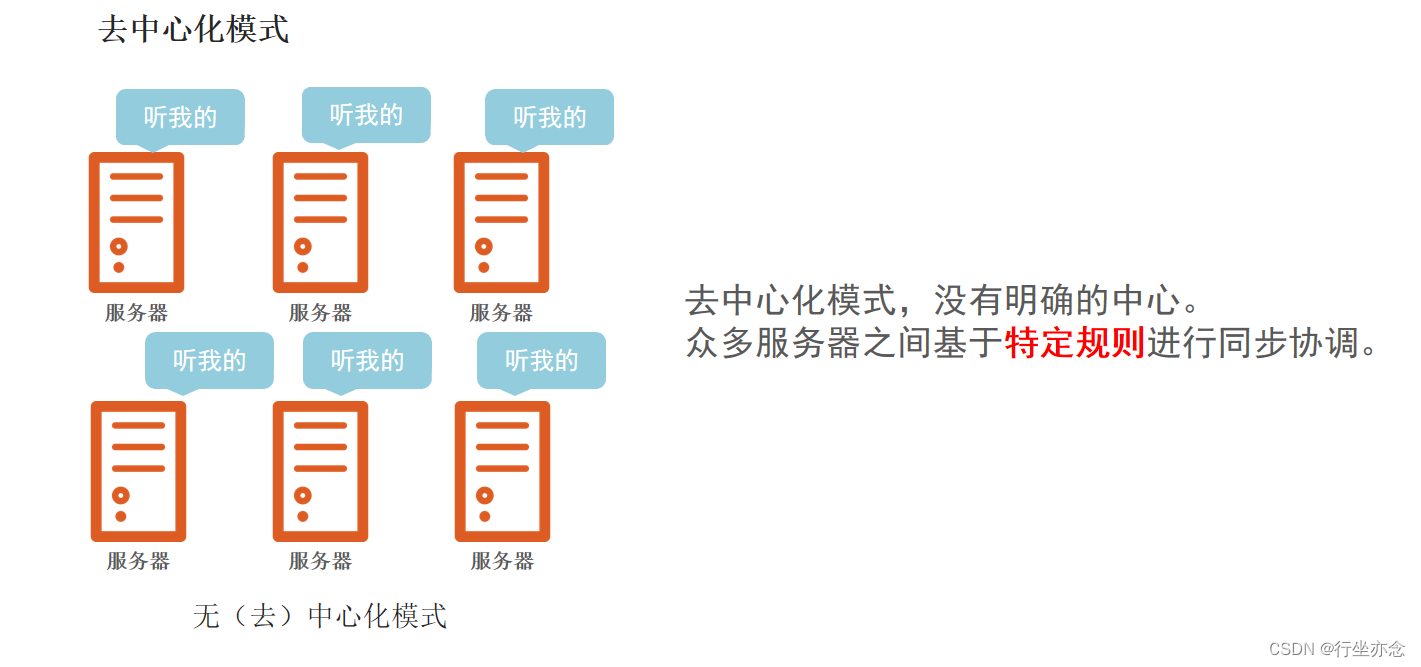
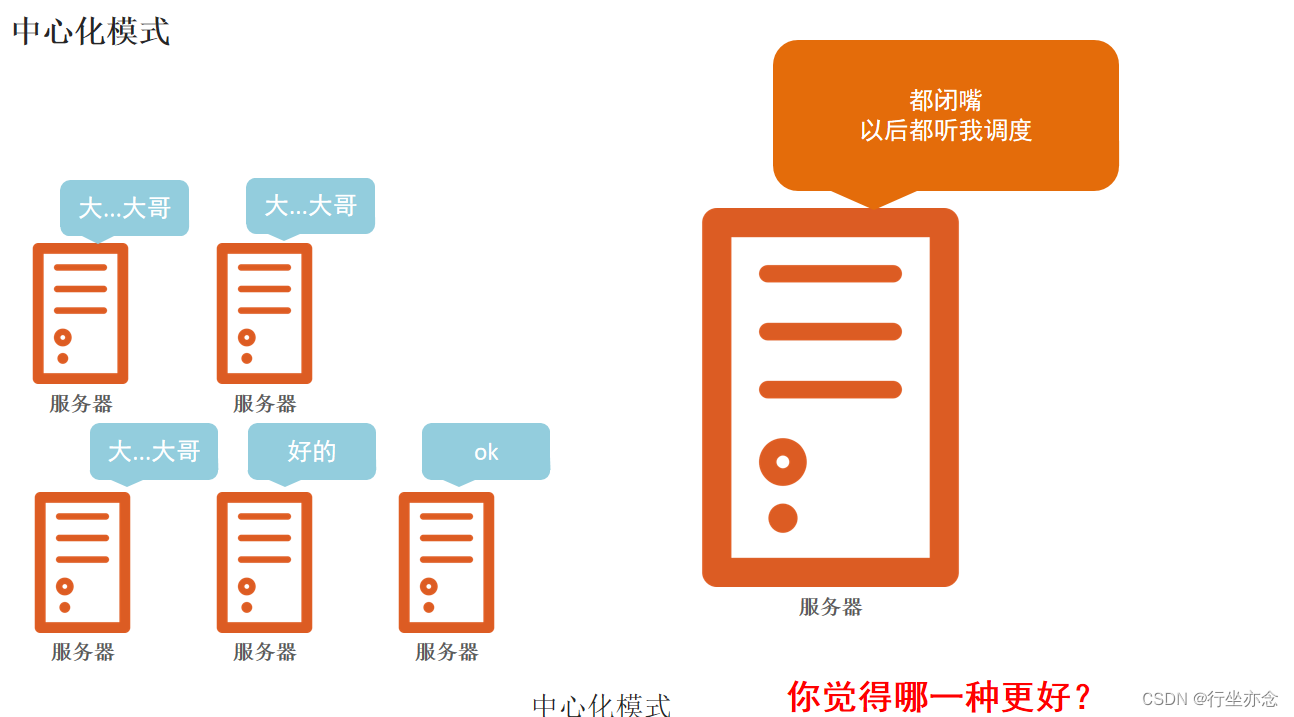
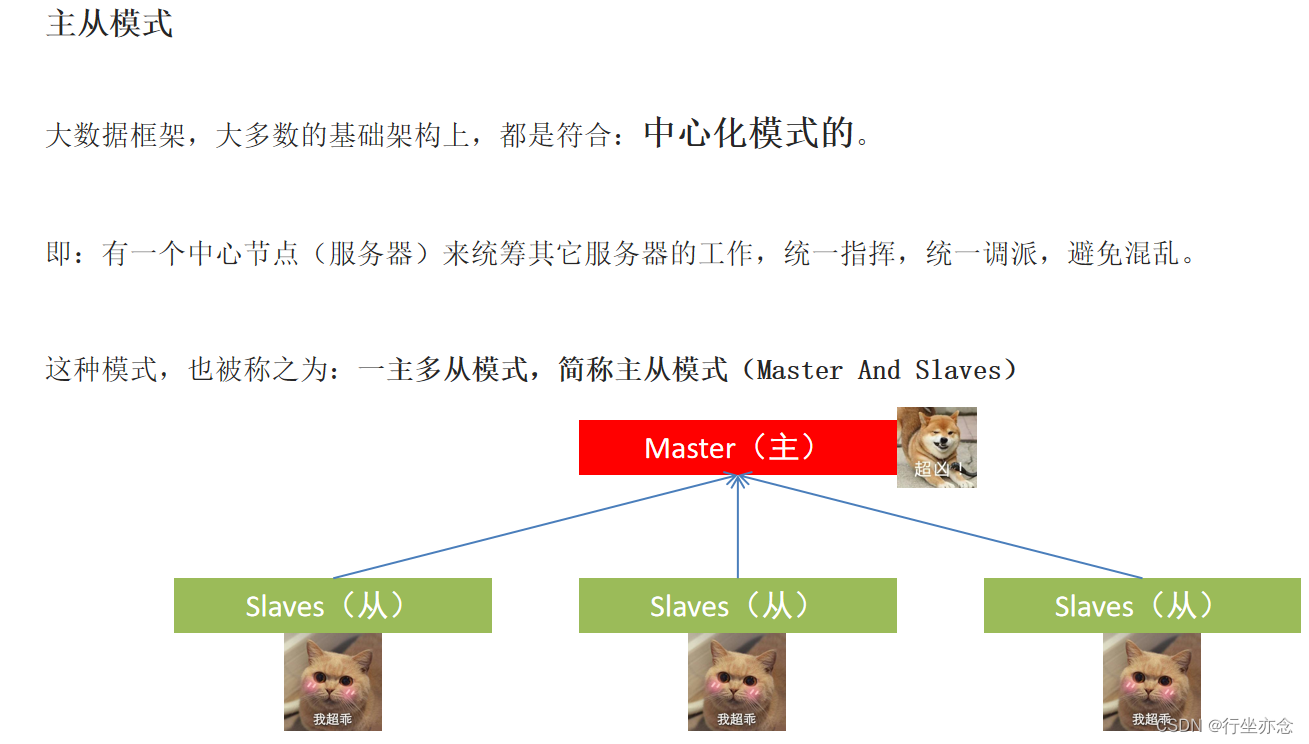
人多了就不好管理,服务器也是一样的道理,大数据体系中,分布式的调度主要有2类架构模式: 去中心化模式 和 中心化模式
去中心化就是没有指挥,按照某个任务去执行,规则就是把这个任务细分,然后有序地各司其职,这样做就做完啦。
中心化就是在服务器里面找个老大哥,当然这个老大哥要有能力,也就是要比其他服务器性能存储方面要好,然后其余的服务器听从老大哥的指挥,干完活给老大哥进行汇总。
在这个中心化基础上有了一些其他的相似的模式
主从模式(接下来要学的HDFS就是主从模式的架构):
二、Hadoop基础架构
1.HDFS
HDFS(Hadoop Distributed File System)是Hadoop项目中的一个核心子项目,它是Hadoop分布式文件系统的简称。HDFS是一个高度容错性的分布式文件系统,旨在部署在廉价硬件上,并提供对数据的高吞吐量访问。HDFS设计用于存储非常大的数据集,并且这些数据集能够在集群中的多个节点上存储和管理。

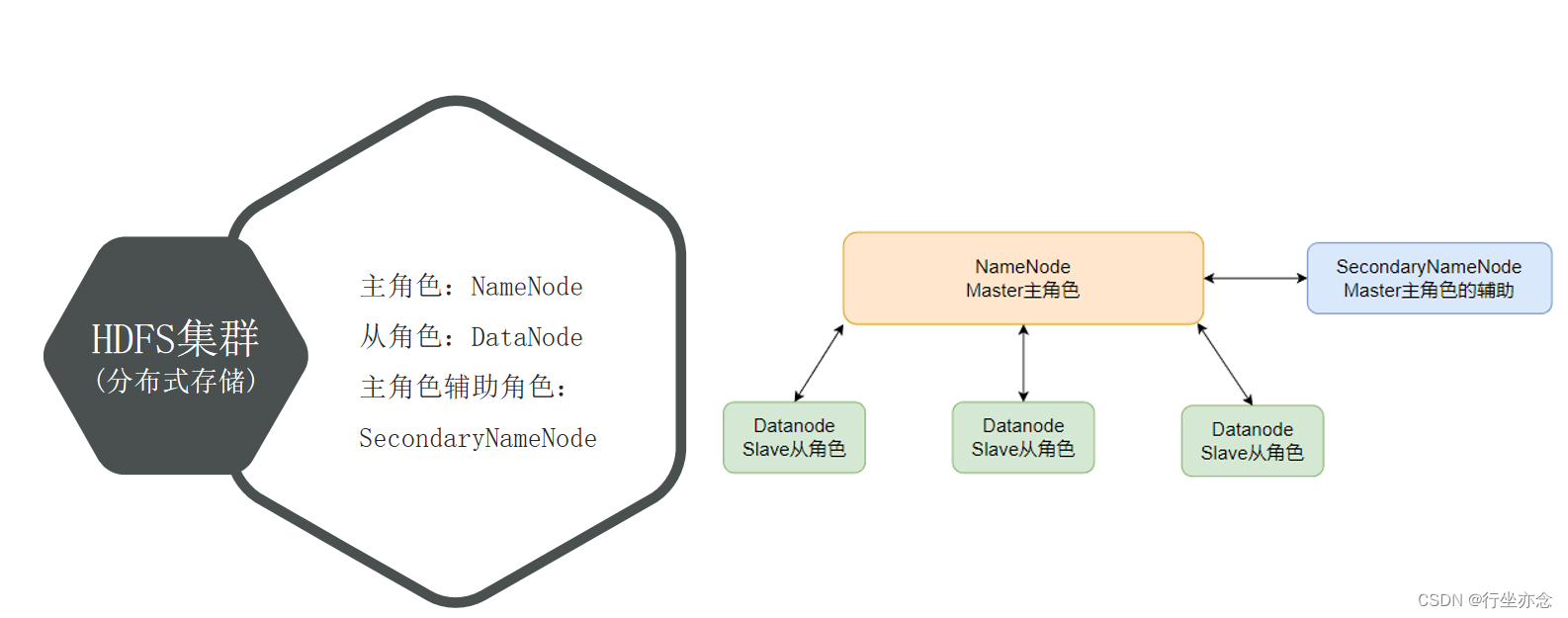
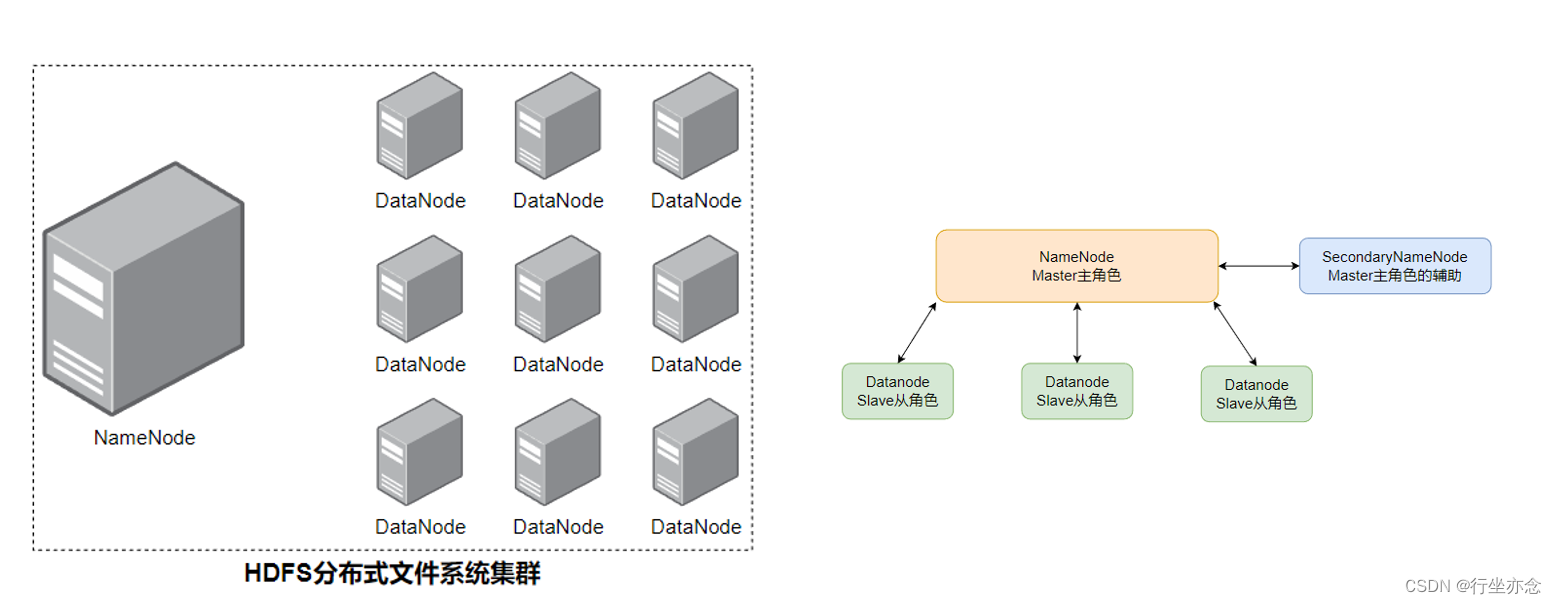
NameNode:
HDFS系统的主角色,是一个独立的进程
负责管理HDFS整个文件系统
负责管理DataNode
SecondaryNameNode: NameNode的辅助,是一个独立进程
主要帮助NameNode完成元数据整理工作(打杂)
DataNode: HDFS系统的从角色,是一个独立进程
主要负责数据的存储,即存入数据和取出数据
2.MapReduce
MapReduce是“分散->汇总”模式的分布式计算框架,可供开发人员开发相关程序进行分布式数据计算。
MapReduce提供了2个编程接口:
Map:Map功能接口提供了“分散”的功能, 由服务器分布式对数据进行处理
Reduce:Reduce功能接口提供了“汇总(聚合)”的功能,将分布式的处理结果汇总统计
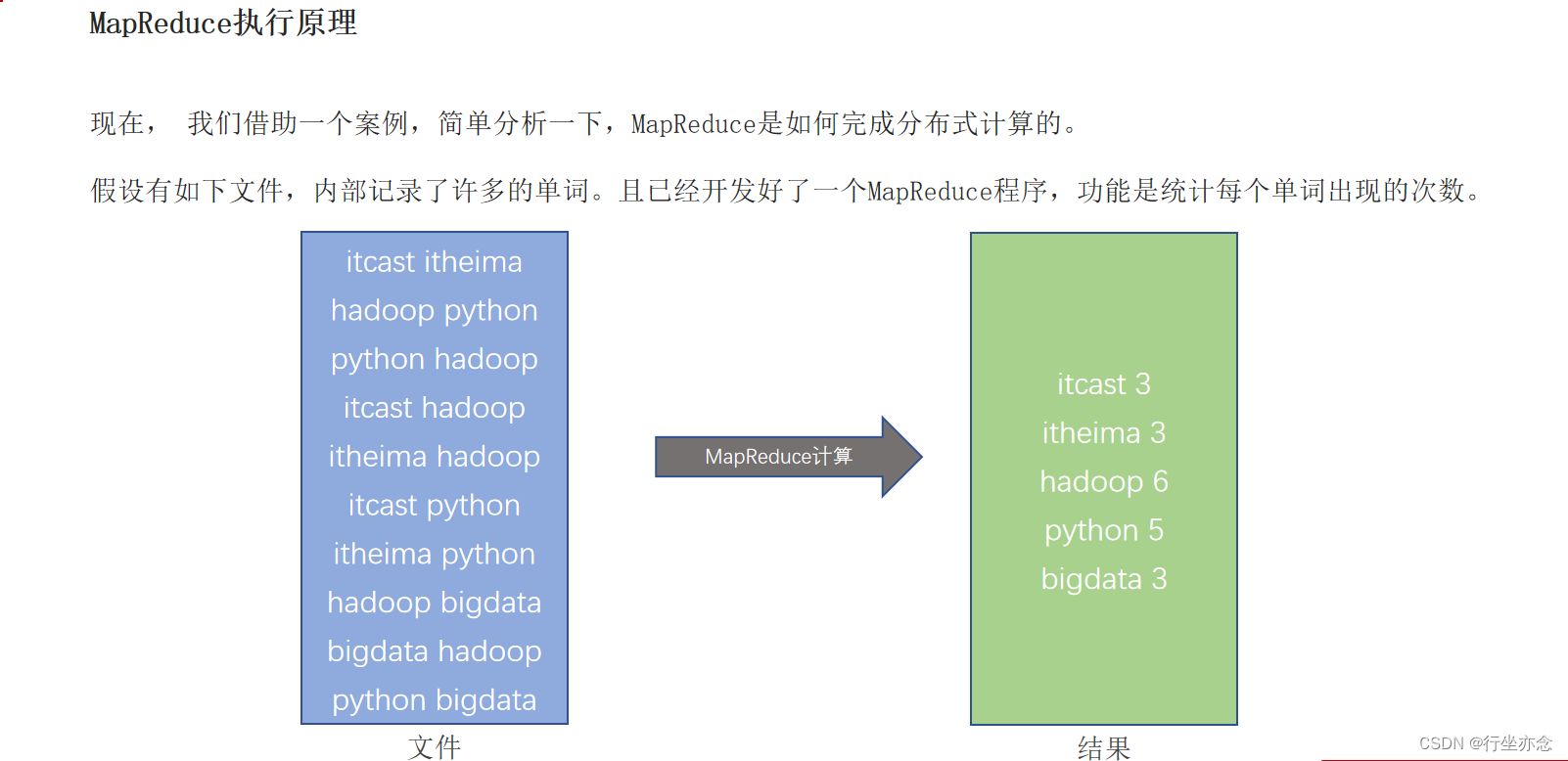
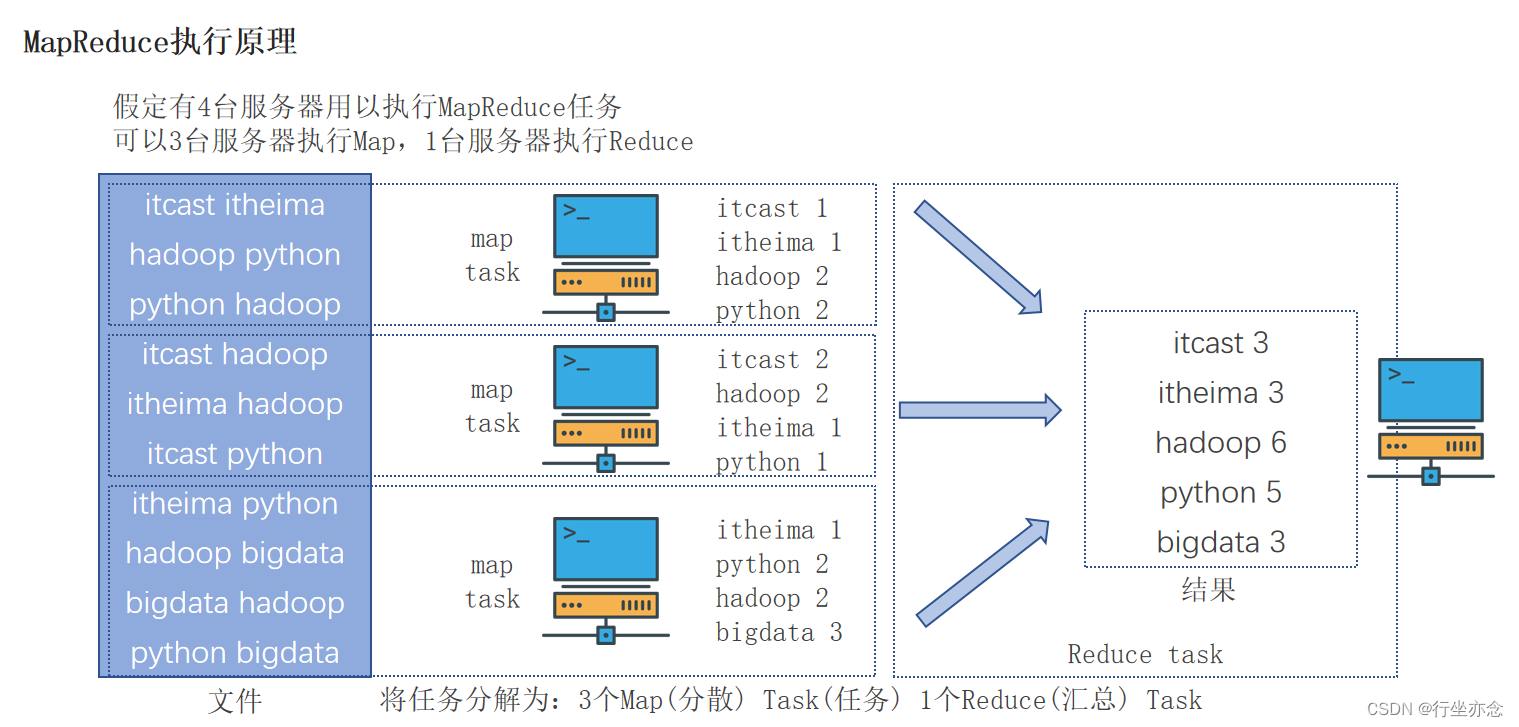
总结一下就是:Map接口分给小弟去帮我算数,Reduce小弟计算好了大哥来汇总再算一次得到结果。
3.YARN
3.1什么是YARN?
YARN(Yet Another Resource Negotiator)的设计目标是实现集群资源的统一管理和调度,以便更高效地运行各种类型的应用程序,而不仅仅局限于MapReduce任务。YARN将资源管理和作业调度两个功能分离,使得Hadoop集群更加灵活和可扩展。
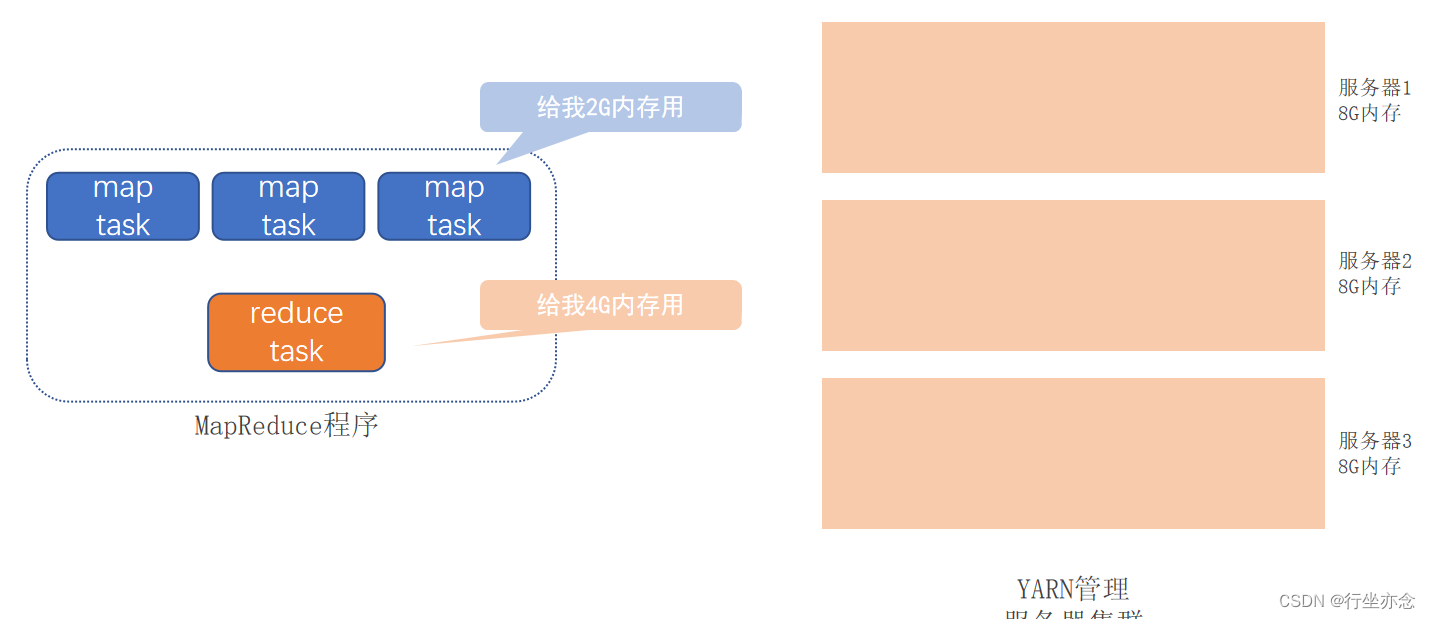
MapReduce是基于YARN运行的,即没有YARN”无法”运行MapReduce程序。
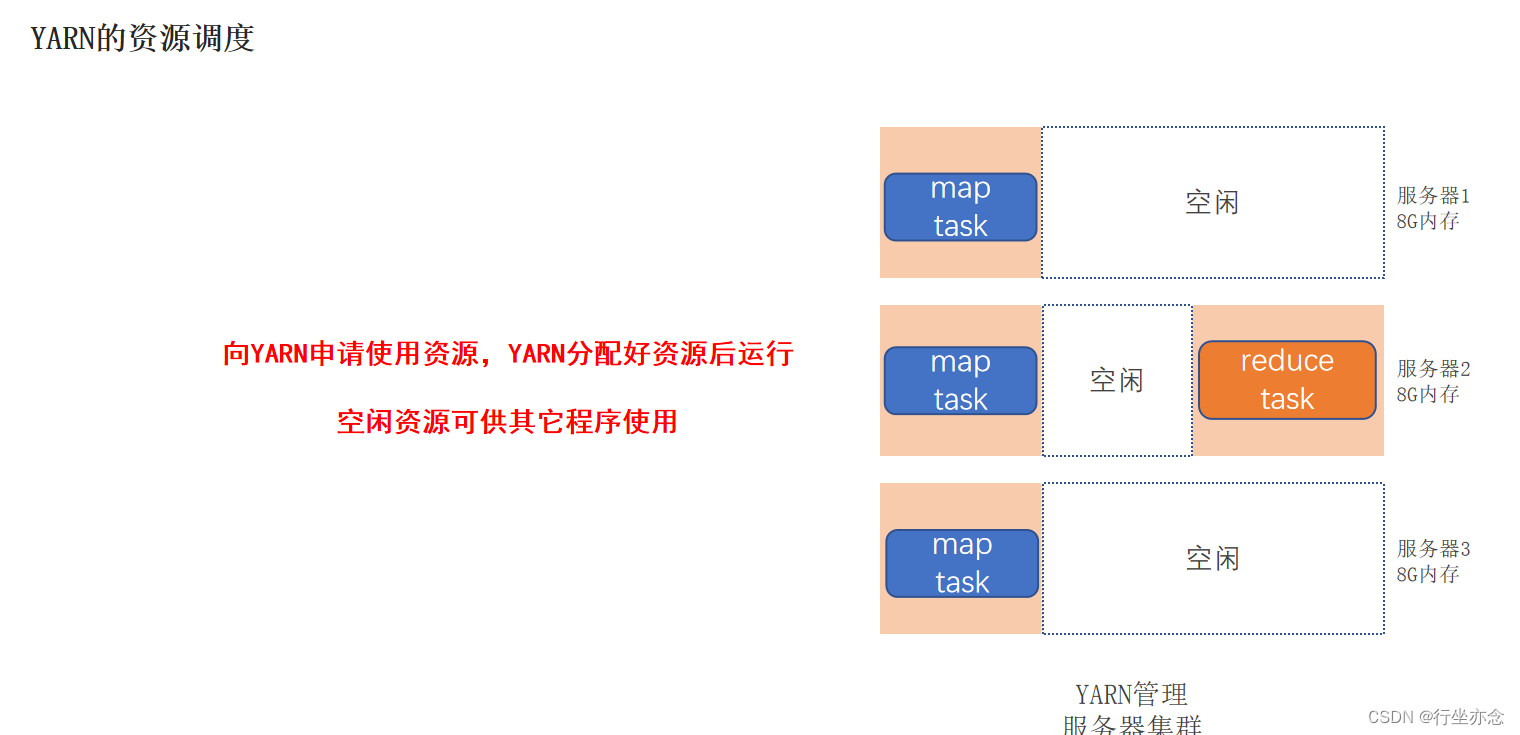
mapReduce向YARN申请内存,然后YARN收到指令之后给MapReduce程序分配对应的内存
剩下的资源供其他程序使用,避免了杂乱无章的现象。
3.2YARN的架构
YARN跟HDFS一样有两个角色(不算辅助角色奥)
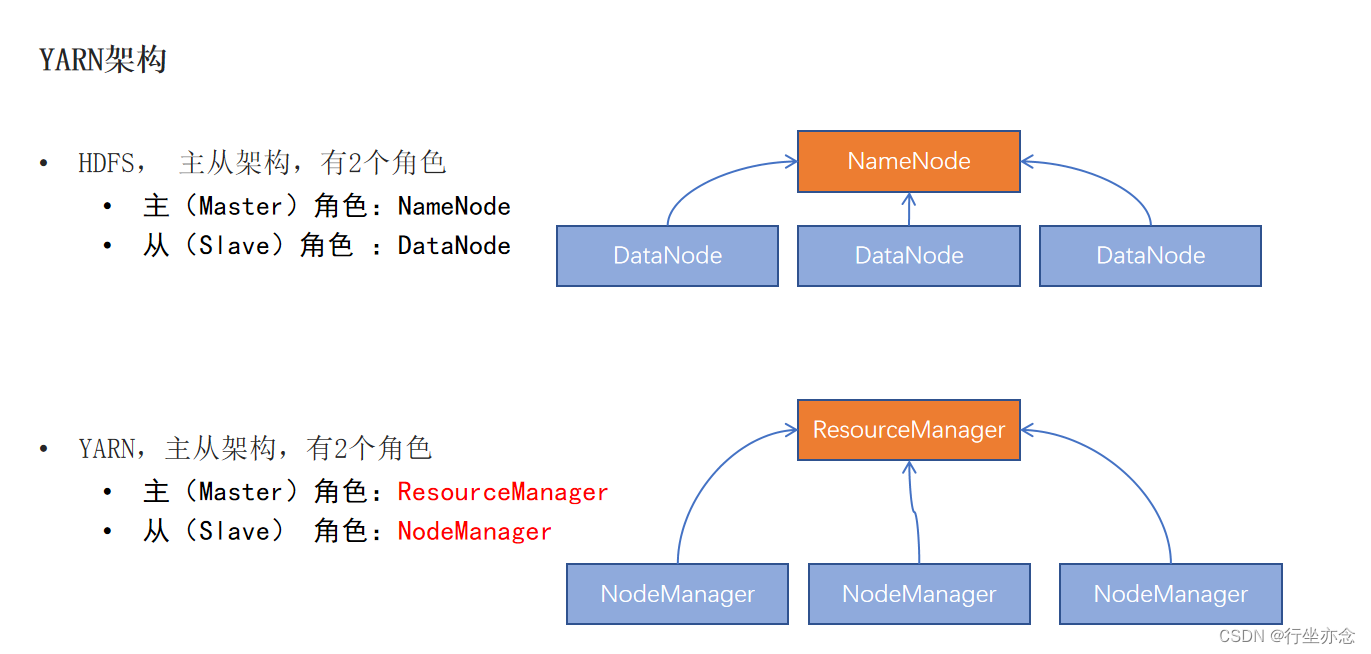
ResourceManager在接收到指令之后会计算一下自己有多少个小弟,从而给他们分配任务
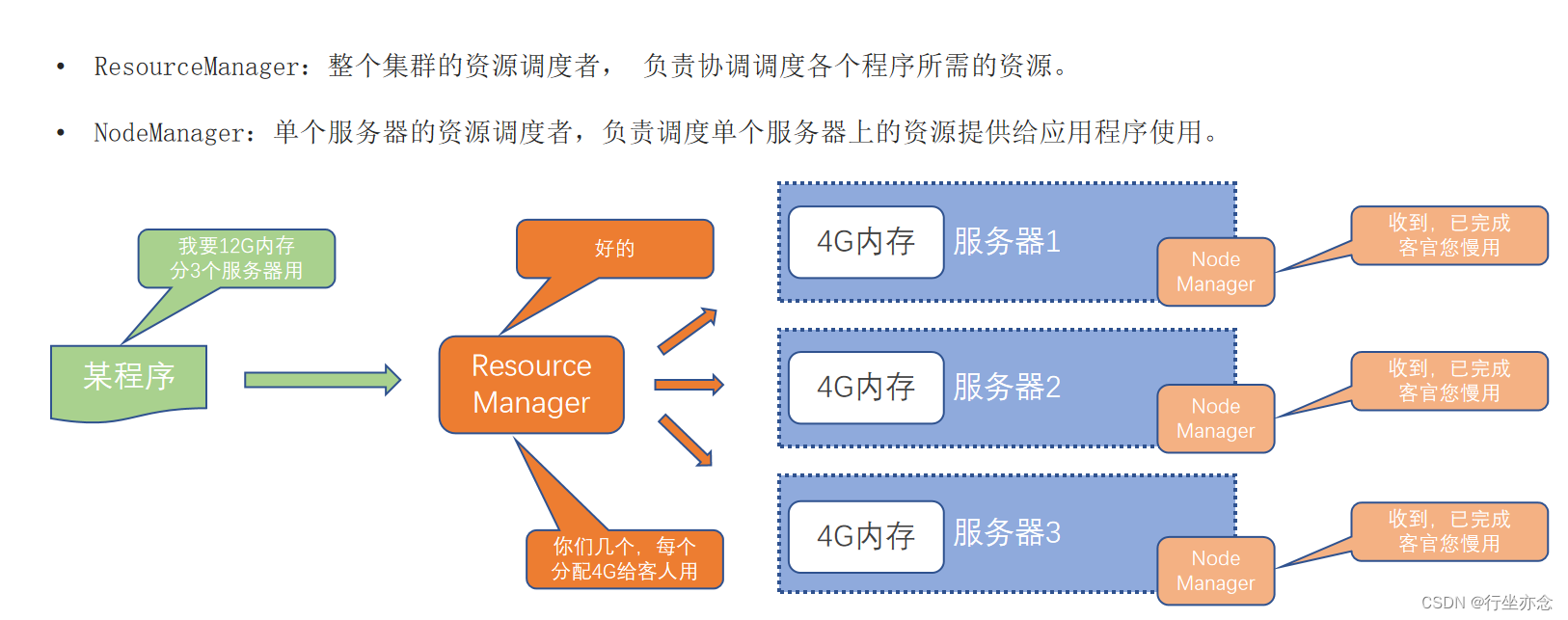
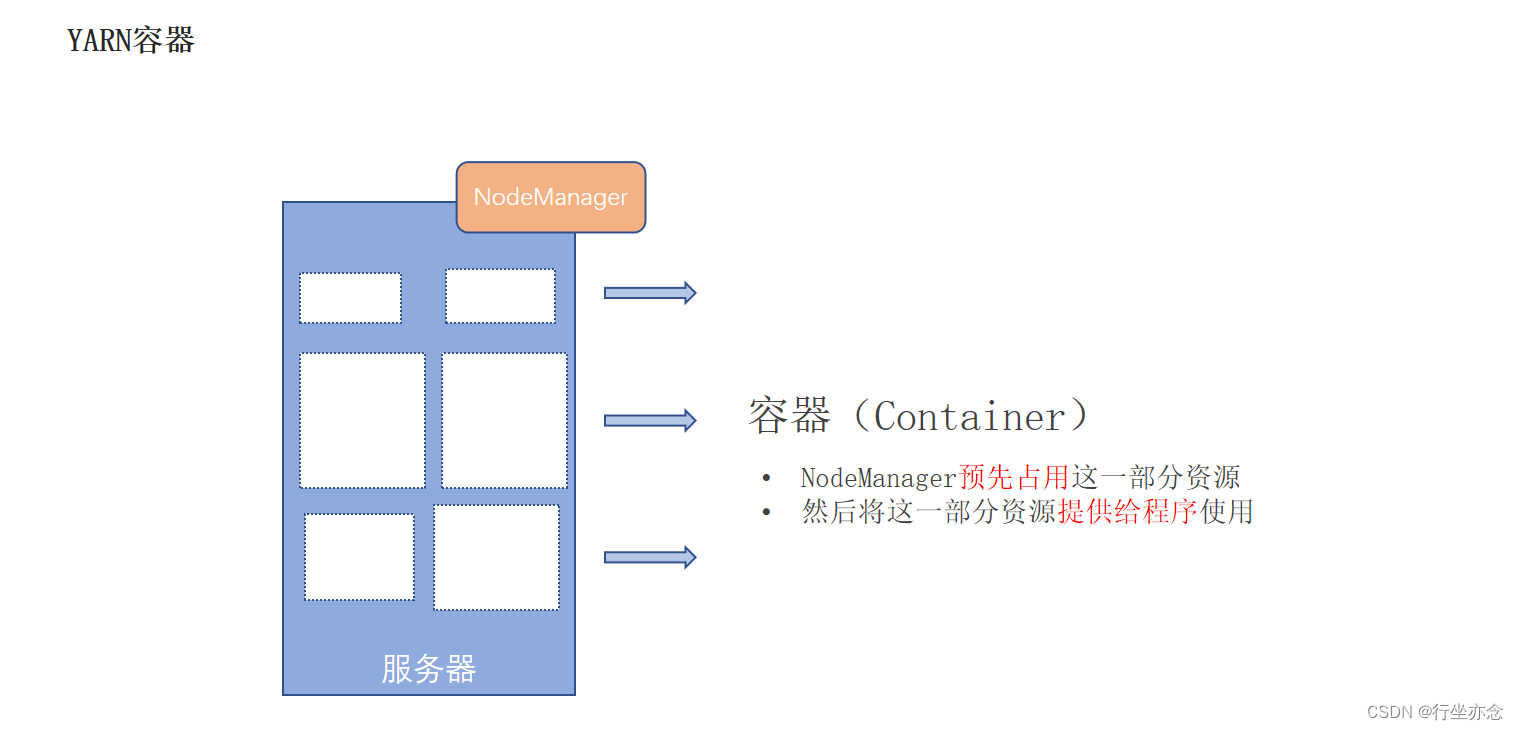
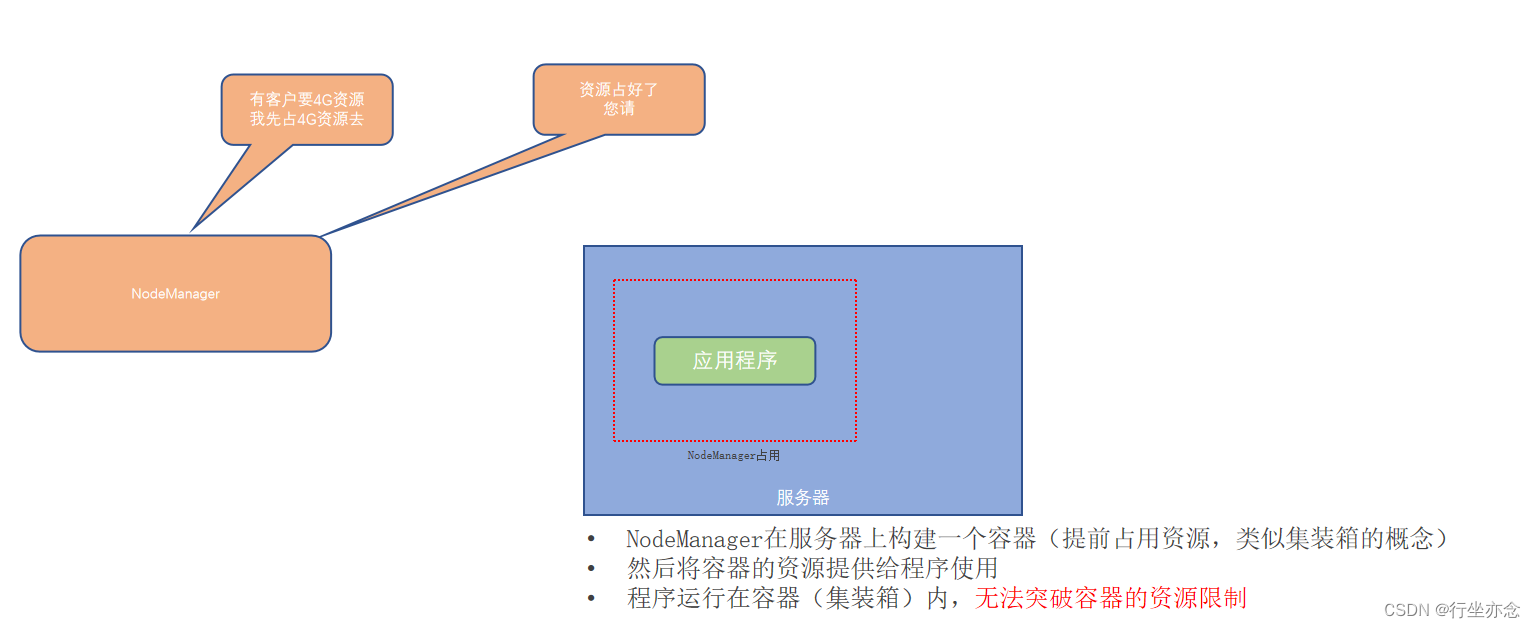
小弟接收指令之后会腾出个位置给程序使用,这个位置叫做容器
4.Hadoop优缺点
Hadoop作为一个分布式系统基础架构,具有其独特的优点和缺点。以下是Hadoop的优缺点概述:
优点:
- 可扩展性:Hadoop可以处理大规模数据集,并且能够横向扩展,通过增加更多的节点来提高集群的处理能力。
- 高可靠性:Hadoop能够自动保存数据的多个副本,并且具有容错性,能够在集群中自动重新分配失败的任务。
- 高效性:Hadoop以并行的方式处理数据,通过MapReduce编程模型将数据划分为多个小块并在集群中的多个节点上并行处理,从而大大提高了处理速度。
- 低成本:Hadoop可以运行在普通硬件上,降低了硬件成本。同时,Hadoop是开源的,可以免费使用,降低了软件成本。
- 灵活性:Hadoop生态系统提供了丰富的工具和框架,如Hive、HBase、Pig、Spark等,可以方便地与其他系统集成,满足不同的数据处理需求。
- 社区支持:Hadoop是一个开源项目,拥有庞大的社区支持,可以获取到丰富的文档、教程和解决方案。
缺点:
- 延迟高:Hadoop主要针对批处理任务设计,对于实时或低延迟的数据处理需求可能不够理想。
- 不适合所有类型的数据:Hadoop主要适用于处理结构化数据,对于非结构化或半结构化数据的处理可能不够高效。
- 学习曲线陡峭:Hadoop是一个复杂的系统,需要一定的学习和实践经验才能掌握其使用和调优。
- 配置和管理复杂:Hadoop集群的配置和管理需要一定的专业知识和经验,对于初学者来说可能比较困难。
- 资源消耗大:Hadoop集群需要占用大量的计算资源和存储资源,可能会对组织的IT基础设施造成一定的压力。
- 安全性:Hadoop在安全性方面存在一些挑战,如数据访问控制、加密和审计等。需要额外的安全措施来保护数据和集群的安全。
基于目前Hadoop存在的问题和挑战可以有以下几个改进方向:
1. 性能优化
- 任务调度:优化Hadoop的任务调度算法,减少单个task任务调度的延迟。例如,可以通过重叠I/O和CPU阶段、任务预取和数据预取等技术来提升任务调度的效率。
- 资源管理:更智能地管理集群资源,包括内存、CPU和磁盘等,以确保资源得到最有效的利用。例如,可以动态调整Map和Reduce任务的数量,以适应不同大小的数据集和集群规模。
2. 数据处理效率
- 小文件处理:优化对小文件的处理,例如通过合并小文件、使用自定义InputFormat或将小文件存储为SequenceFile文件等方式,以减少NameNode的内存压力和提升处理效率。
- 数据压缩:采用更有效的数据压缩技术,如Snappy或LZOP压缩编码器,以减少网络I/O时间和存储空间占用,从而提升数据传输和处理效率。
3. 安全性和可靠性
- 身份验证和授权:增强Hadoop集群的身份验证和授权机制,确保只有授权用户可以访问集群,并执行他们被授权的操作。
- 数据加密:对于敏感数据,实施加密措施以保护数据在传输和存储过程中的安全性。
三、总结
Hadoop以其独特的分布式架构和高效的数据处理能力,在大数据领域发挥了重要的作用。通过HDFS和MapReduce等核心组件,Hadoop能够轻松应对海量数据的存储和计算挑战,为各行各业提供了强大的数据处理能力。同时,Hadoop的开源特性使得用户可以自由地使用和定制它,满足不同的业务需求。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









