






【本文以Transformer模型中采取的位置编码为例】
一、理解来源
原文:【Transformer系列】深入浅出理解Positional Encoding位置编码
二、位置编码的定义
针对于NLP等文字处理任务而言,为了更接近实际现实情况,在处理词向量的时候,我们要给词向量添加一些有关位置的信息。不同于循环神经网络RNN的天然富有序列位置前后信息的结构,Transformer将一个序列中的词向量拼接成一个矩阵,一次性输入到网络结构中进行处理,这也就决定了Transformer结构是天然缺乏位置信息的。因此,我们要人为地为Transformer的输入添加位置信息,即位置编码。

三、位置编码的分类
1、绝对位置编码
位置编码在序列对应的每一个位置都代表着一个绝对位置,不需要经过比较,各自就有前后。
2、相对位置编码
各位置的位置编码并没有绝对位置的信息,需要进行相乘才能得到两个位置编码之间的相对距离(位置)。【Transformer中采用的就是这种编码方式】
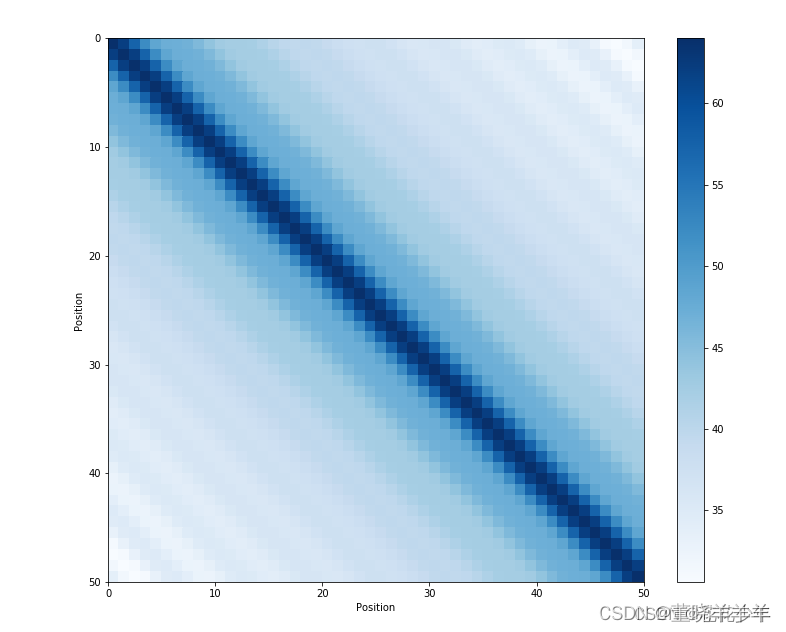
该图表示两个不同位置的位置编码相乘情况。
可以看到,主对角线上的颜色是相同的,而距离主对角线越远,则颜色越浅(越不一样)。
模型是如何理解各个编码之间的位置关系的?
举个简单的例子来理解一下相对编码。
import torch
# 向量维数为4
d_model = 4
# 序列最长长度为10
max_len = 10
# 序列0到9的位置
pos = torch.arange(0, max_len)
# 2 * i
_2i = torch.arange(0, d_model, step=2)
#给出位置编码
pos_encoding = torch.zeros(max_len, d_model)
pos_encoding[:, 0::2] = torch.sin(pos / ( 10000 ** (_2i / d_model)))
pos_encoding[:, 1::2] = torch.cos(pos / ( 10000 ** (_2i / d_model)))
#tensor([[ 0.0000, 1.0000, 0.0000, 1.0000],
# [ 0.8415, 0.5403, 0.0100, 0.9999],
# [ 0.9093, -0.4161, 0.0200, 0.9998],
# [ 0.1411, -0.9900, 0.0300, 0.9996],
# [-0.7568, -0.6536, 0.0400, 0.9992],
# [-0.9589, 0.2837, 0.0500, 0.9988],
# [-0.2794, 0.9602, 0.0600, 0.9982],
# [ 0.6570, 0.7539, 0.0699, 0.9976],
# [ 0.9894, -0.1455, 0.0799, 0.9968],
# [ 0.4121, -0.9111, 0.0899, 0.9960]])
# 则得到10个位置,维度为4的位置编码
# 分别取位置编码中第0,1,2个编码
t1 = pos_encoding[0] # [ 0.0000, 1.0000, 0.0000, 1.0000]
t2 = pos_encoding[1] # [ 0.8415, 0.5403, 0.0100, 0.9999]
t3 = pos_encoding[2] # [ 0.9093, -0.4161, 0.0200, 0.9998]
# 分别进行向量内积
t = t1 @ t1
# tensor(2.)
t = t2 @ t2
# tensor(2.)
# 也就是说,t1到t1的位置与t2到t2的位置是一样的
t = t1 @ t2
# tensor(1.5403)
t = t2 @ t3
# tensor(1.5403)
# 也就是说,t1到t2的位置与t2到t3的位置是一样的
其他部分在原文中讲的都很详细,可以仔细阅读原文
下面的文章对Transformer讲的也很详细透彻















 1077
1077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









