






记录自己的踩的坑和在超算上的运行代码的整个流程
第一步:注册账号
在官网申请免费试测名额,下载并登录客户端后用SSH或者Putty连接(putty选择最低的网络延迟,弹出的窗口点击yes )
第二步:利用秒传或者WinScp将本地文件拖拽到云桌面中
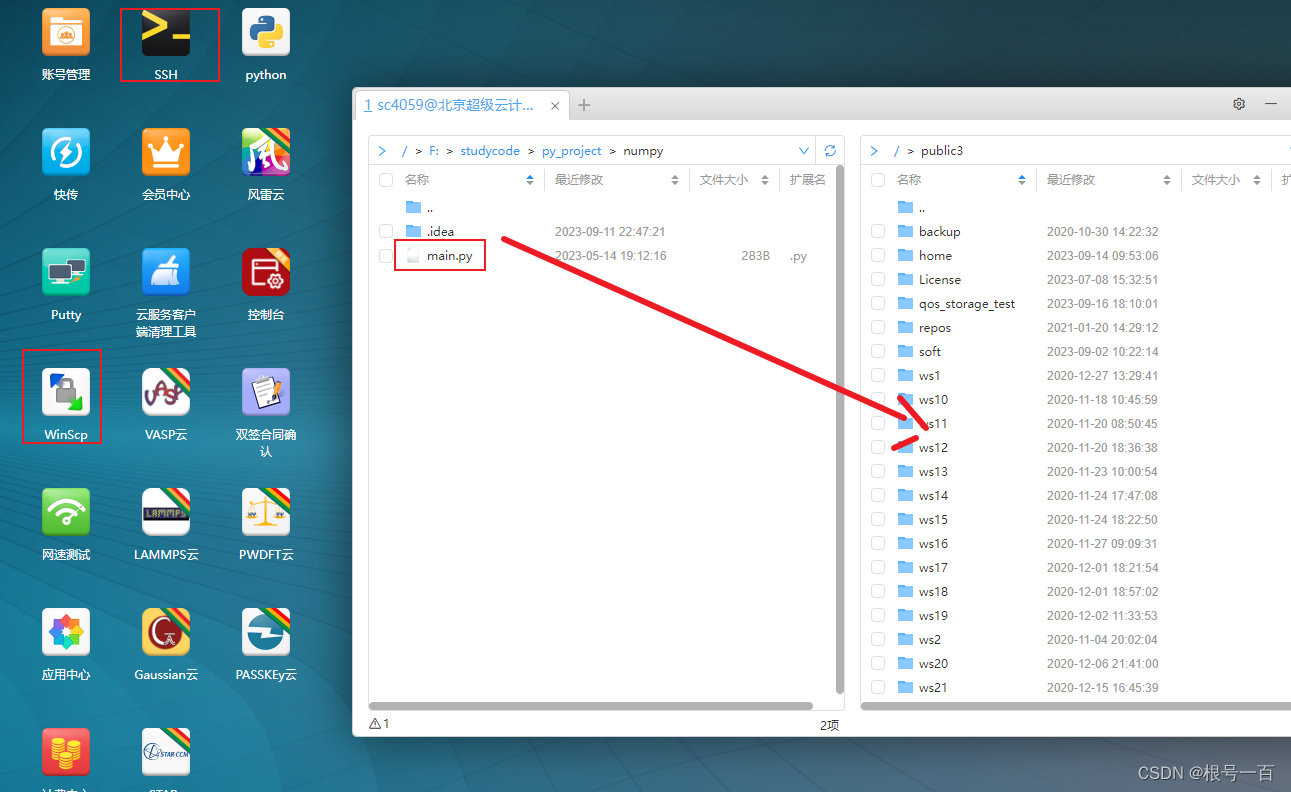
右键点击可新建文件夹存放自己的代码和数据集
第三步:用桌面上的SSH或Putty连接超算
选择自己的账号连接即可
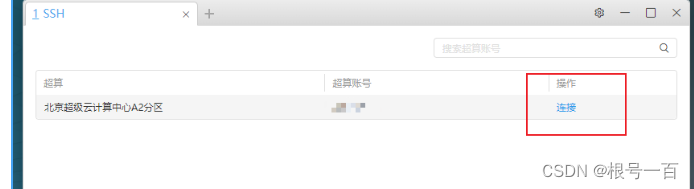
第一个坑:SSH无法连接
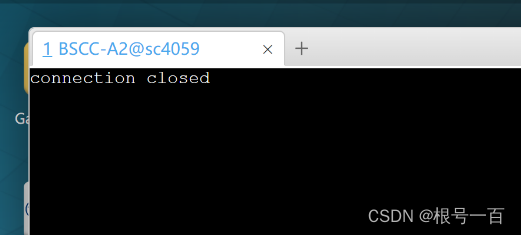
解决办法:找客服提供自己的云桌面的账号,或者用官方清理缓存软件修复客户端。工具链接: https://cloud.blsc.cn/fix.html
putty连接(putty选择最低的网络延迟,弹出的窗口点击yes )
连接超算后输入pwd查看自己的module的储存位置(如图,我的module在public3中)
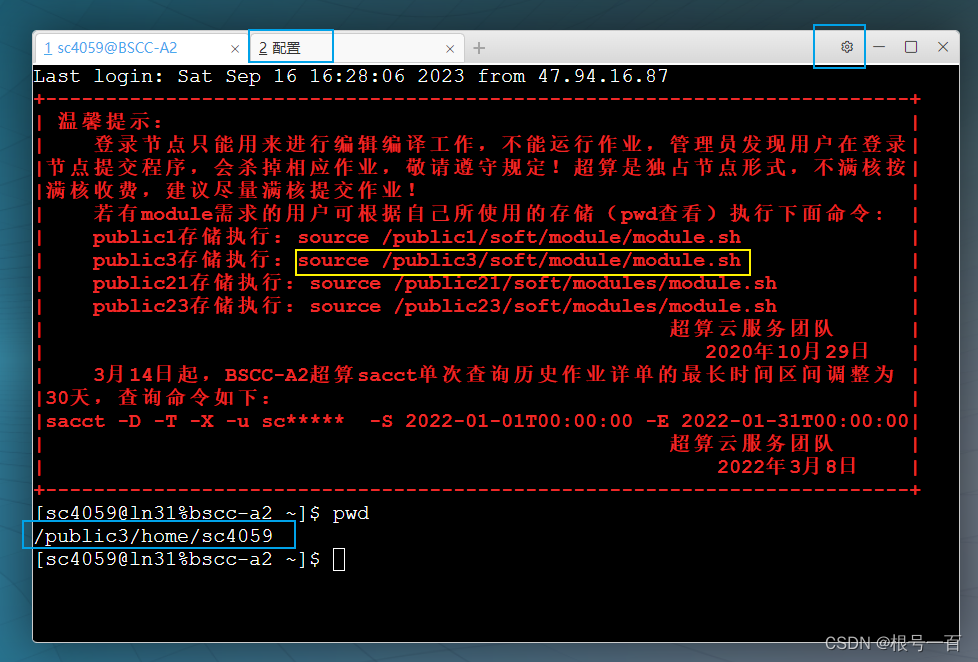
输入黄框中的命令source一下module,输入
module avail查看所有module(红框中即为module,下面还有很多module没加载出来)
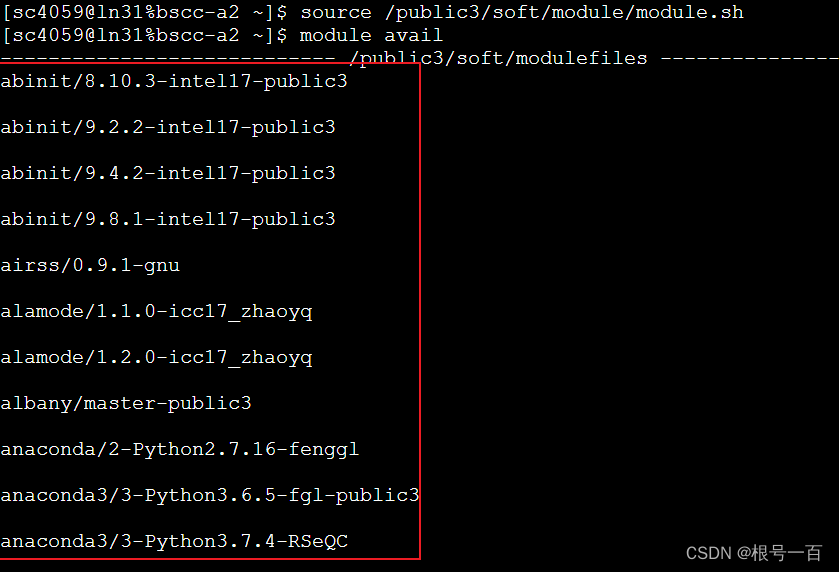
输入命令加载想要的module(我选择了anaconda3/3-python3.8.3-zyq)
module load anaconda3/3-python3.8.3-zyq加载好module后(可以用module list查看是否加载好)执行cd ~/.conda/envs里面ls看看有没有虚拟环境(执行conda env list也可以)

若没有环境则创建虚拟环境方便安装运行代码需要的特殊库文件
创建虚拟环境过程:
参考该文章:在并行超算使用conda创建虚拟环境 - 无言上善 - 博客园 (cnblogs.com)
使用命令:conda create -n 环境名 python=版本
例如:
conda create -n test python=3.7第二个坑:在我的代码中需要读取.pkl文件,安装3.7的python版本在后续运行代码时提示读取文件报错
解决办法:参考该文章重新创建了一个虚拟环境安装了3.10的python版本,成功解决报错。文章链接:unsupported pickle protocol: 5_This is JULY的博客-CSDN博客
第三个坑:创建虚拟环境时报错
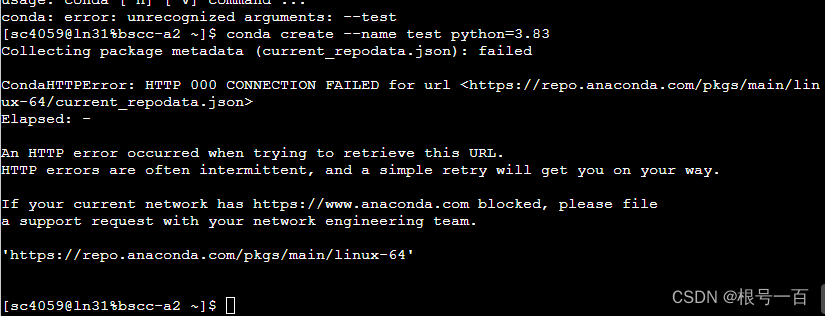
解决办法:输入以下代码执行联网代理
export http_proxy=http://172.16.54.201:8888
export https_proxy=http://172.16.54.201:8888
export ftp_proxy=http://172.16.54.201:8888输入后重新创建虚拟环境执行
conda env list查看虚拟环境
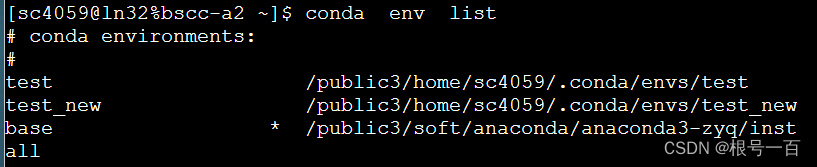
如果有,则说明创建虚拟环境成功,接下来激活虚拟环境
source activate envs_name
出现[env_name]说明激活成功

之后就可以按照conda里面一下输入命令安装库文件。比如

安装好所需的库文件后就可以编写作业脚本运行代码了。
第四步:编写作业脚本
第一步:在要运行的.py文件夹创建.sh脚本
vim your_shell.sh输入:
#!/bin/bash
#SBATCH -p amd_256
#SBATCH -N 1
#SBATCH -n 1
#SBATCH -c 64解释:#SBATCH -p amd_256 :选择amd_256架构
#SBATCH -N 1 :一个节点
#SBATCH -n 1 :1个进程
#SBATCH -c 64 :64线程(最少是64)
再输入
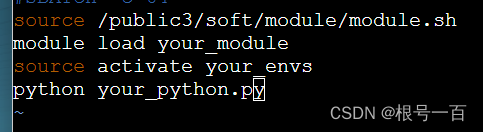
最后按 esc 输入:wq 即可保存退出
可以cat看一下sh脚本
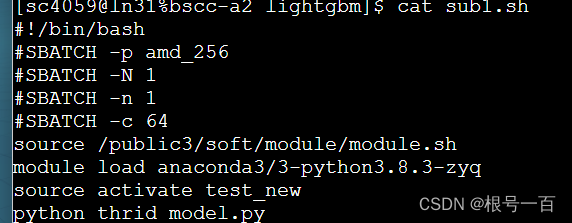
实际上就是第三步中加载module 和激活环境的操作,最后再加上运行代码
第二步:提交作业
输入
sbatch your_sh.sh输入sequeue可以查看作业队列
第三步:查看实时输出信息
提交作业后可用
ll -ltrash
查看是否有输出文件,找到.out文件
输入
tail -f your_file.out实时查看代码的输出信息。
可以用squeue看作业还在不在队列来确定作业是否结束
作业结束后用vim编辑器打开.out文件即可查看输出信息
vim your_file.out
参考视频:北京超级云客户端和超算资源使用介绍_哔哩哔哩_bilibili
视频里还说明了怎么用桌面的集成软件来提交作业,更加详细

















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









