







目录
一、 原理
之前的FC、Conv每一层的节点之间没有相互关联,无法体现输入前后关系
1. RNN
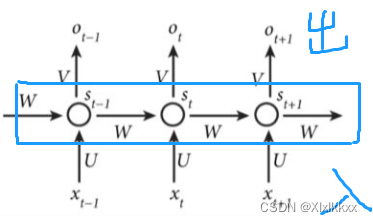
RNN结构如下:
可看作将上面的网络旋转90,然后同一层的节点之间有了交互。
输入输出数量可自由设置:
one-to-one、one-to-n、n-to-one、n-to-m、n-to-n(下图就是)
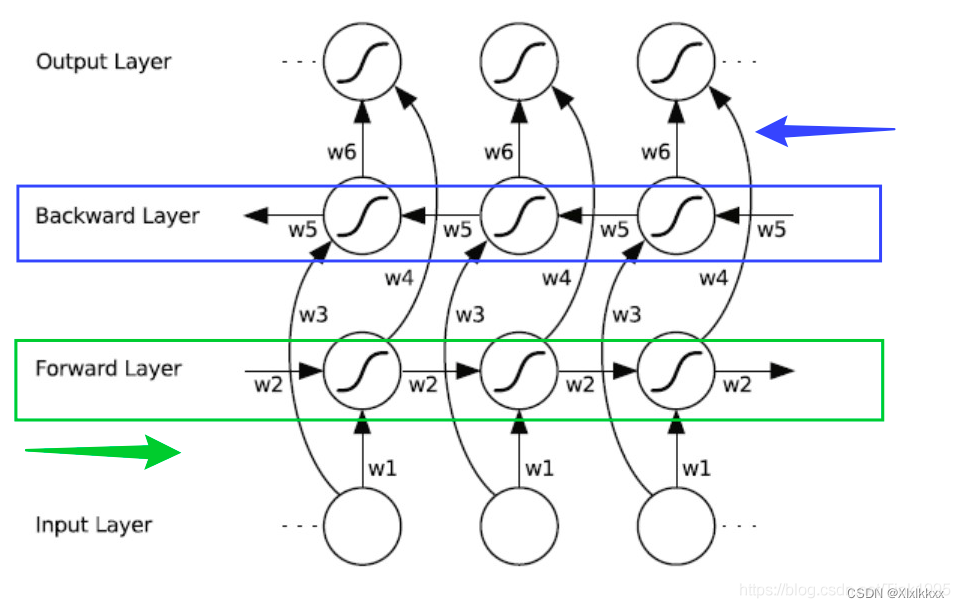
双向:
其实可以看作两个RNN的结果融合;RNN方向不同(从前往后+从后往前)
两个RNN相互独立,只有最后的结果融合
深层RNN:
堆叠多层,都是从前往后传播

问题:
梯度消失/爆炸
导致RNN忘记它在较长序列中以前看到的内容,因此RNN只具有短时记忆
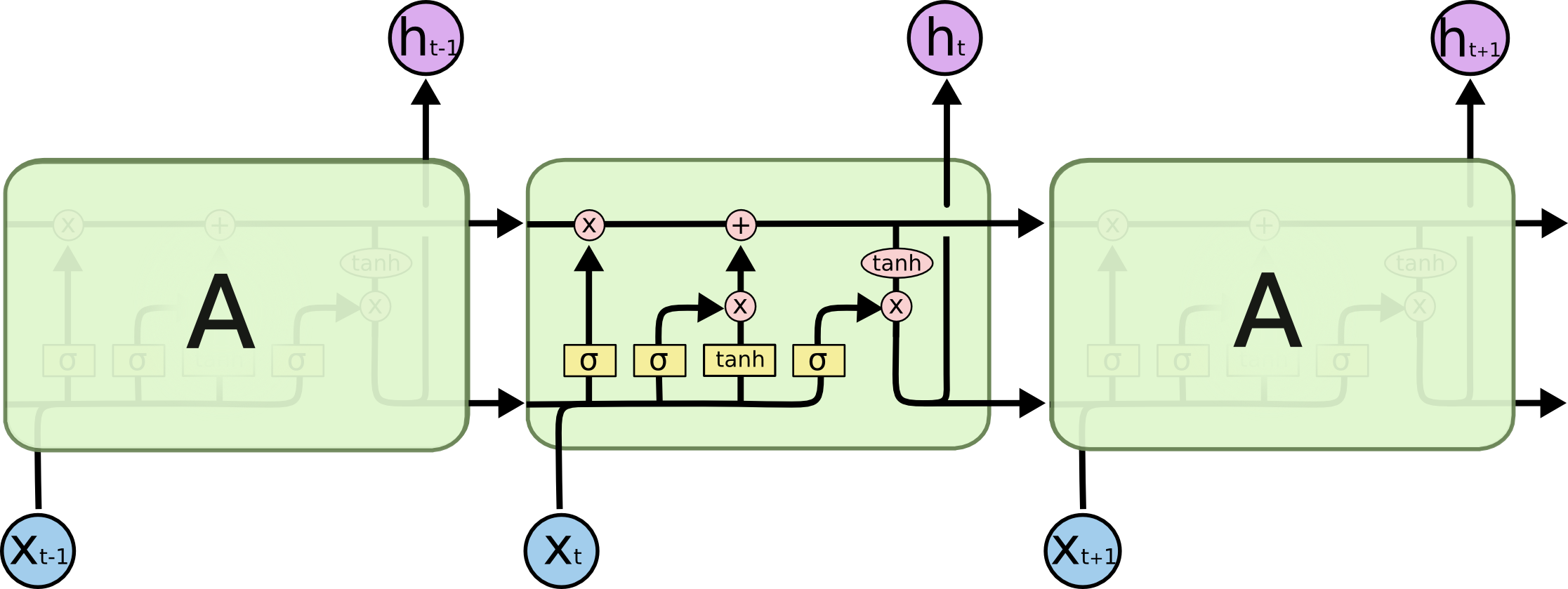
2. LSTM
缓解RNN的梯度消失/爆炸问题
结构:
将上图RNN中的白色方框单元换为LSTM单元
变体简化:
GRU等
其他一系列变体:ConvLSTM、Predrnn等 ... ...
gru结构图:
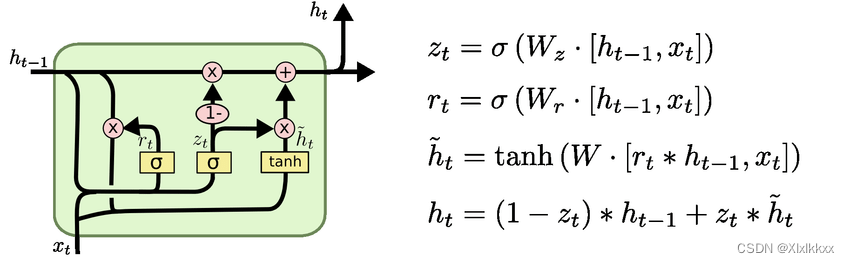
二、 代码实现
1. RNN
使用时,对下方代码稍作修改即可。现在基本不用RNN,看一看就好,用不太到
import torch
import torch.nn as nn
class RNN(nn.Module): # 输入长度 输入特征数 输出长度 输出特征数 隐藏层特征数 堆叠几层
def __init__(self, input_len, input_size, out_len, out_size, hidden_dim, n_layers):
super(RNN, self).__init__()
self.input_len = input_len
self.input_size = input_size
self.out_len = out_len
self.out_size = out_size
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.rnn = nn.RNN(input_size, hidden_dim, n_layers, batch_first=True)
# torch 官方文档中定义的nn.RNN中的参数
'''
nn.RNN网络参数:
input_size – 输入x中预期特征的数量
hidden_size – 隐藏状态h的特征数量
num_layers - 循环层数。默认值:1
nonlinearity — 隐藏层函数,可以是“tanh”或“relu”。默认值:'tanh'
bias - 如果为 False,则该层不使用偏差权重。默认值:真
batch_first - 将batch放在第一个维度。 默认值False。 一般需要我们设为True
dropout - 是否要引入Dropout层,dropout概率等于dropout。默认值:0
bidirectional —如果为真,则成为双向 RNN。默认值:假
使用时都是batch_first=True, bidirectional=False
输入:x: (batch_size, input_len, input_size)(批量,输入长度,输入特征数)+初始隐状态 :(n_layers, batch_size, hidden_dim)(堆叠层数,批量,隐藏特征数)
输出:y: (batch_size, input_len, hidden_dim)(批量,输入长度,隐藏特征数)+最后时间步的隐状态 :(n_layers, batch_size, hidden_dim)(堆叠层数,批量,隐藏特征数)
'''
# 最后接上一个全连接,得到输出;将隐藏特征数映射到输出特征数
self.fc = nn.Linear(hidden_dim, out_size)
def forward(self, x, hidden):
batch_size = x.size(0) # 取出批量数
r_out, hidden = self.rnn(x, hidden) # 得到input_len时长的输出,以及最后时间步的隐状态
output = self.fc(r_out) # 特征维度变换
output = output[:,-self.out_len:,:] # 取出最后的out_len天
return output
# 搭建网络
net = RNN(10,7,3,1,28,1) # 过去10天7变量,预测未来3天1变量, 隐藏层特征数是28,堆叠1层
# 网络输入: 输入x + 初始隐藏状态hidden
# 网络输出: 输出output维度: (batch_size, out_len, out_size)-----(批量,输出长度,输出特征数)
x = torch.randn(5, 10, 7) # x的维度: (batch_size, input_len, input_size)---- (批量,输入长度,输入特征数)
h0 = torch.randn(1,5,28) # 初始隐藏状态hidden维度: (n_layers, batch_size, hidden_dim)----(堆叠层数,批量,隐藏层特征数)
y = net(x,h0)
print(y.shape) # (5,3,1)- 说明1:官方nn.RNN输出有两个(forward函数第二行),输出如下图:
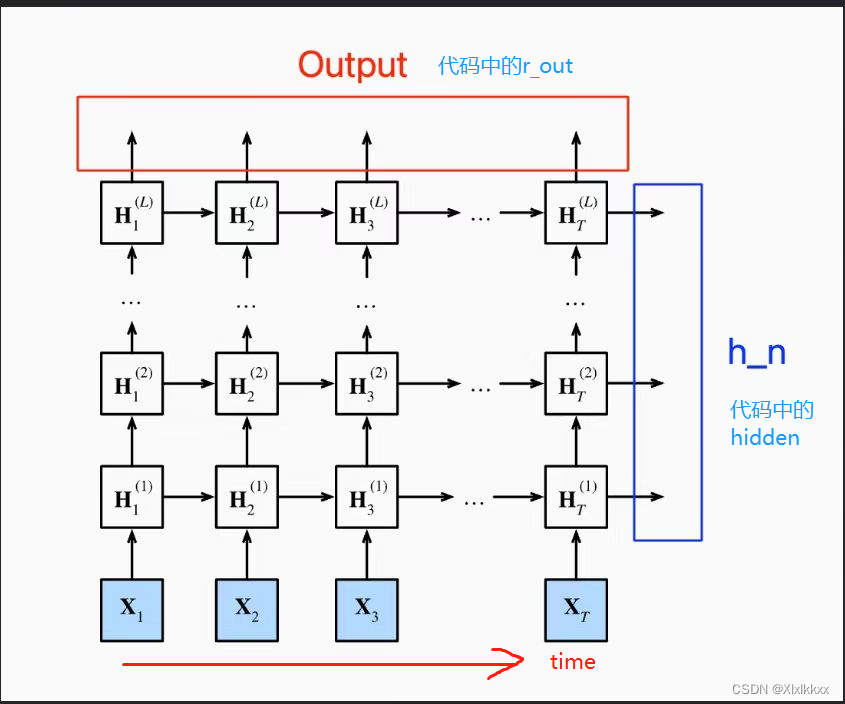
- 注意2:可以不初始化隐状态,不用输入隐状态。部分代码修改如下
class RNN:
...
同上---不变
...
def forward(self, x):
batch_size = x.size(0)
r_out, hidden = self.rnn(x) # 输出是两个,所以等号左边不能少
output = self.fc(r_out)
output = output[:,-self.out_len:,:]
return output
net = RNN(10,7,3,1,28,1)
x = torch.randn(5, 10, 7) # x的维度: (batch_size, input_len, input_size)---- (批量,输入长度,输入特征数)
y = net(x)
print(y.shape) # (5,3,1)- 注意3: 做维度变换、取时间步
这两个步骤顺序可交换;
一般是先取时间步,再做变换
# 也可
def forward(self, x):
batch_size = x.size(0)
r_out, hidden = self.rnn(x)
output = self.fc(r_out) # 先变
output = output[:,-self.out_len:,:] # 后取
return output
# 推荐!------------计算量会小
def forward(self, x):
batch_size = x.size(0)
r_out, hidden = self.rnn(x)
output = r_out[:,-self.out_len:,:] # 先取
output = self.fc(output) # 后变
return output2. LSTM
同RNN代码类似,只是隐状态有两个:h、c;
代码如下:
输入没有隐状态,自动生成; 先取时间步再维度变换
import torch
import torch.nn as nn
class LSTM(nn.Module): # 输入长度 输入特征数 输出长度 输出特征数 隐藏层特征数 堆叠几层
def __init__(self, input_len, input_size, out_len, out_size, hidden_dim, n_layers):
super(LSTM, self).__init__()
self.input_len = input_len
self.input_size = input_size
self.out_len = out_len
self.out_size = out_size
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.lstm = nn.LSTM(input_size, hidden_dim, n_layers, batch_first=True)
# torch 官方文档中定义的nn.LSTM中的参数
'''
参数基本上同RNN;
参数:proj_size – 如果>0, 则会使用相应投影大小的LSTM。默认值:0
##
使用时都是batch_first=True,其他用不到的参数默认就好
##
输入:
x: (batch_size, input_len, input_size)(批量,输入长度,输入特征数)
两个初始隐状态h0和c0 shape都是:(n_layers, batch_size, hidden_dim)(堆叠层数,批量,隐藏特征数)
两个作为整体一起输入(h0,c0)
##
输出:
y: (batch_size, input_len, hidden_dim)(批量,输入长度,隐藏特征数)
最后时间步的两个隐状态hn和cn shape都是:(n_layers, batch_size, hidden_dim)(堆叠层数,批量,隐藏特征数)
两个作为整体一起输出(hn,cn)
'''
# 最后接上一个全连接,得到输出;将隐藏特征数映射到输出特征数
self.fc = nn.Linear(hidden_dim, out_size)
def forward(self, x):
batch_size = x.size(0)
r_out, _ = self.lstm(x) # 输出 _ 是一个元组, _[0]=hn ; _[1]=cn
output = r_out[:,-self.out_len:,:]
output = self.fc(output)
return output
net = LSTM(10,7,3,1,28,1)
x = torch.randn(5, 10, 7) # x的维度: (batch_size, input_len, input_size)---- (批量,输入长度,输入特征数)
y = net(x)
print(y.shape) # (5,3,1)GRU
使用类似RNN,隐状态只有一个
3. 其它
encoder—decoder等结构就是先后经过两个网络。自由组合即可(如两个LSTM)。
encoder输出,输入到decoder中。保证输入输出以及中间的维度变化正确即可
带有attention就是encoder输出后,经过attention,再输入到decoder中
attention代码参见之前的。
4. convlstm
- 模型搭建----github查找如下:
import torch.nn as nn
import torch
class ConvLSTMCell(nn.Module):
def __init__(self, input_dim, hidden_dim, kernel_size, bias):
"""
Initialize ConvLSTM cell.
Parameters
----------
input_dim: int
Number of channels of input tensor.
hidden_dim: int
Number of channels of hidden state.
kernel_size: (int, int)
Size of the convolutional kernel.
bias: bool
Whether or not to add the bias.
"""
super(ConvLSTMCell, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.kernel_size = kernel_size
self.padding = kernel_size[0] // 2, kernel_size[1] // 2
self.bias = bias
self.conv = nn.Conv2d(in_channels=self.input_dim + self.hidden_dim,
out_channels=4 * self.hidden_dim,
kernel_size=self.kernel_size,
padding=self.padding,
bias=self.bias)
def forward(self, input_tensor, cur_state):
h_cur, c_cur = cur_state
combined = torch.cat([input_tensor, h_cur], dim=1) # concatenate along channel axis
combined_conv = self.conv(combined)
cc_i, cc_f, cc_o, cc_g = torch.split(combined_conv, self.hidden_dim, dim=1)
i = torch.sigmoid(cc_i)
f = torch.sigmoid(cc_f)
o = torch.sigmoid(cc_o)
g = torch.tanh(cc_g)
c_next = f * c_cur + i * g
h_next = o * torch.tanh(c_next)
return h_next, c_next
def init_hidden(self, batch_size, image_size):
height, width = image_size
return (torch.zeros(batch_size, self.hidden_dim, height, width, device=self.conv.weight.device),
torch.zeros(batch_size, self.hidden_dim, height, width, device=self.conv.weight.device))
class ConvLSTM(nn.Module):
"""
Parameters:
input_dim: Number of channels in input
hidden_dim: Number of hidden channels
kernel_size: Size of kernel in convolutions
num_layers: Number of LSTM layers stacked on each other
batch_first: Whether or not dimension 0 is the batch or not
bias: Bias or no bias in Convolution
return_all_layers: Return the list of computations for all layers
Note: Will do same padding.
"""
def __init__(self, input_dim, hidden_dim, kernel_size, num_layers,
batch_first=False, bias=True, return_all_layers=False):
super(ConvLSTM, self).__init__()
self._check_kernel_size_consistency(kernel_size)
kernel_size = self._extend_for_multilayer(kernel_size, num_layers)
hidden_dim = self._extend_for_multilayer(hidden_dim, num_layers)
if not len(kernel_size) == len(hidden_dim) == num_layers:
raise ValueError('Inconsistent list length.')
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.kernel_size = kernel_size
self.num_layers = num_layers
self.batch_first = batch_first
self.bias = bias
self.return_all_layers = return_all_layers
cell_list = []
for i in range(0, self.num_layers):
cur_input_dim = self.input_dim if i == 0 else self.hidden_dim[i - 1]
cell_list.append(ConvLSTMCell(input_dim=cur_input_dim,
hidden_dim=self.hidden_dim[i],
kernel_size=self.kernel_size[i],
bias=self.bias))
self.cell_list = nn.ModuleList(cell_list)
def forward(self, input_tensor, hidden_state=None):
if not self.batch_first:
# (t, b, c, h, w) -> (b, t, c, h, w)
input_tensor = input_tensor.permute(1, 0, 2, 3, 4)
b, _, _, h, w = input_tensor.size()
if hidden_state is not None:
raise NotImplementedError()
else:
hidden_state = self._init_hidden(batch_size=b,
image_size=(h, w))
layer_output_list = []
last_state_list = []
seq_len = input_tensor.size(1)
cur_layer_input = input_tensor
for layer_idx in range(self.num_layers):
h, c = hidden_state[layer_idx]
output_inner = []
for t in range(seq_len):
h, c = self.cell_list[layer_idx](input_tensor=cur_layer_input[:, t, :, :, :],
cur_state=[h, c])
output_inner.append(h)
layer_output = torch.stack(output_inner, dim=1)
cur_layer_input = layer_output
layer_output_list.append(layer_output)
last_state_list.append([h, c])
if not self.return_all_layers:
layer_output_list = layer_output_list[-1:]
last_state_list = last_state_list[-1:]
return layer_output_list, last_state_list
def _init_hidden(self, batch_size, image_size):
init_states = []
for i in range(self.num_layers):
init_states.append(self.cell_list[i].init_hidden(batch_size, image_size))
return init_states
@staticmethod
def _check_kernel_size_consistency(kernel_size):
if not (isinstance(kernel_size, tuple) or
(isinstance(kernel_size, list) and all([isinstance(elem, tuple) for elem in kernel_size]))):
raise ValueError('`kernel_size` must be tuple or list of tuples')
@staticmethod
def _extend_for_multilayer(param, num_layers):
if not isinstance(param, list):
param = [param] * num_layers
return param- 代码使用
# **************************************** 示例1 ****************************************
# 网络输入:
# shape:(B, T, C, H, W )
# 要求:搭建网络时batch_first要设为True!!!
# Output:
# A tuple of two lists of length num_layers (or length 1 if return_all_layers is False).
# 0 - layer_output_list is the list of lists of length T of each output
# 1 - last_state_list is the list of last states
# each element of the list is a tuple (h, c) for hidden state and memory
# *************************************** 示例说明2 ***************************************
# -------------------------搭建网络参数:
# 输入特征维数(理解为图片的通道数)---隐藏层状态的维数---卷积核尺寸---网络层数---batch_first---是否使用偏置---是否返回全部层
net1 = ConvLSTM(2, 14, (3,3), 2, True, True, False) # 2层网络,只返回最后层结果
net2 = ConvLSTM(2, 14, (3,3), 2, True, True, True) # 2层网络,返回所有层结果
# -------------------------输入网络数据的shape以及含义
# 是一个五维数据-----(batch_ize,t时间步,c通道数(特征数),h高,w宽)----搭建网络时batch_first要设为True!!!
x = torch.randn(4, 5, 2, 12, 12) # 4个样本,5天数据,2层数据,12*12的网格
# -------------------------输出数据说明,
# 其实和LSTM那些都一样,如果需要生成你自己想要的shape,对原始网络进行时间长截取+全连接维度变化
y1, state1 = net1(x)
y2, state2 = net2(x)
print(y1.shape,y2.shape)
# y1.shape---list元素只有一个----元素的shape(B, T, Hiddendim, w, h) ==== (4,5,14,12,12)
# state1-----一个list,元素有两个,代表h和c 元素的shape(B, Hiddendim, w, h) ==== (4,14,12,12)
# y2.shape---list元素有两个,因为是两层网络----每个元素的shape(B, T, Hiddendim, w, h) ==== (4,5,14,12,12)
# state2-----两个list因为是两层网络,每个list元素有两个代表h和c 元素的shape(B, Hiddendim, w, h) ==== (4,14,12,12)














 1170
1170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









