







目录
1. Inception块
仅是个人笔记,代码学习资源来源B站博主霹雳吧啦Wz的个人空间_哔哩哔哩_bilibili
一、理论知识
1. Inception块
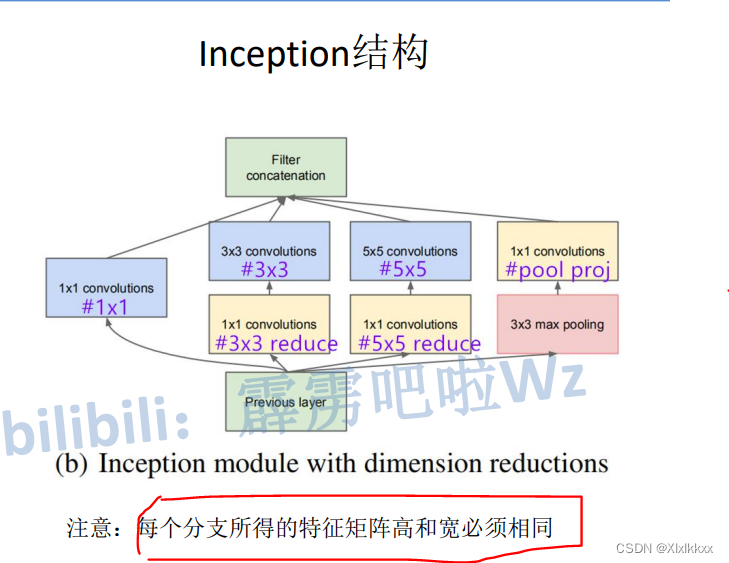
该结构融合不同尺度的特征信息,各并行分支得到的结果在channel方向进行拼接
Inception块中1*1的作用————降维(减小通道数)
进行降维后再卷积可大大减小参数量
假设输入:512*8*8,走第二条路径的输出是64*8*8
- 直接使用3*3卷积参数量:
512*64*3*3 = 294 912
- 先使用1*1降维到24,再使用3*3升维到64:
512*24*1*1 + 24*64*3*3 = 26 112
2. 辅助输出
除最后一层的输出结果,中间节点的分类效果也有可能是很好的,所以GoogLeNet将中间某一层的输出作为分类,并以一个较小的权重(0.3)加到最终的分类结果中。有2个辅助分类节点。

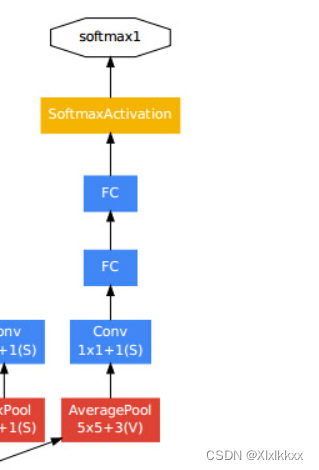
3. 丢弃全连接层
在网络的最终输出部分使用平均池化层+一个全连接
代替之前网络的两个全连接(大大减少模型参数)
为什么最后一个还是全连接??
个人理解。。。绝大多数网络最后一个都是全连接
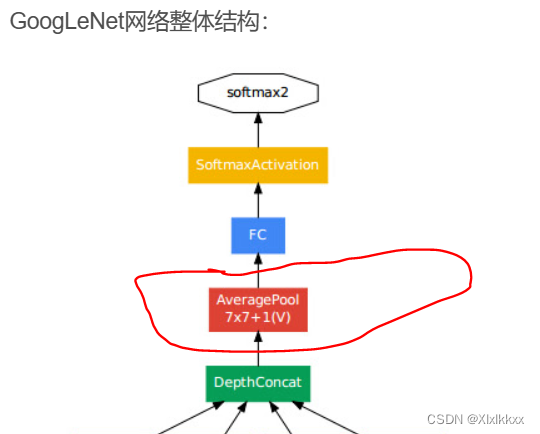
4. 网络结构和参数配置

图中每个Inception的结构都是一样的,只是参数不同
参数配置如下图:
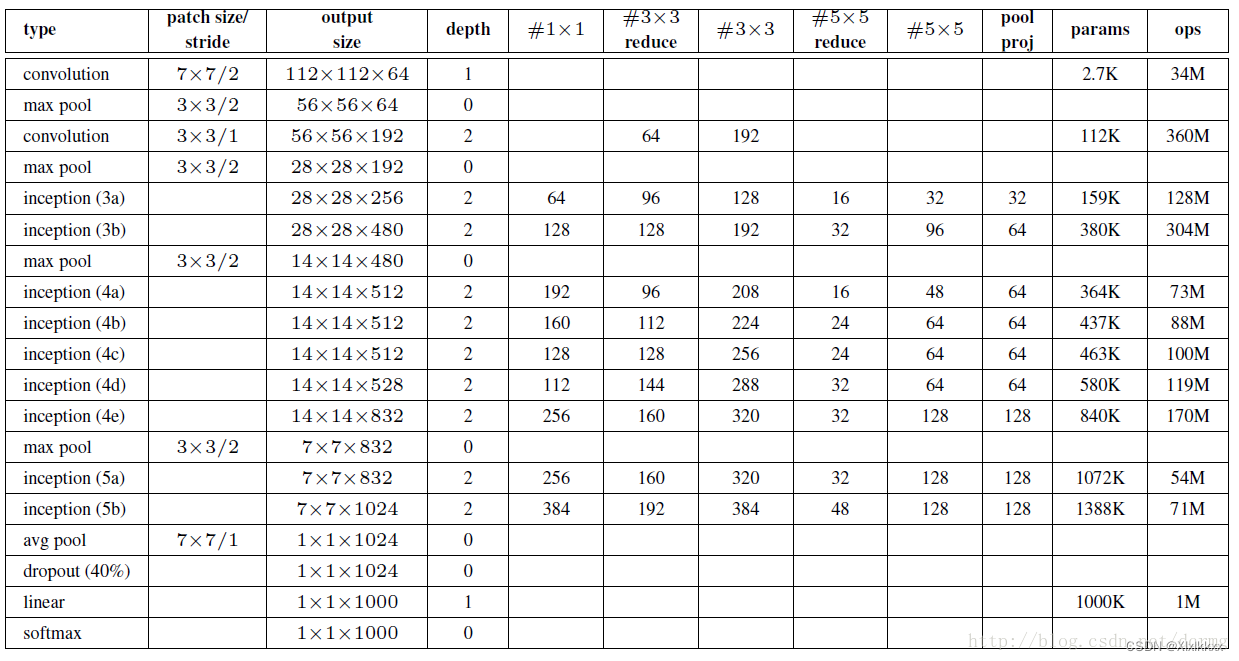
- 特征图大小只在输入图像第一个卷积操作和maxpool发生变化
- Inception不改变特征图大小,只改变通道数
特征图变化说明:
inception(3a)为例:输入28*28*192-------------输出28*28*256
depth==2:因为每个inception块是两层深度
inception(3a)并行分支1:28*28*192-----(1*1卷积降维操作)------28*28*64
inception(3a)并行分支2:28*28*192-----(1*1卷积降维操作,表中3*3reduce)------28*28*96
28*28*96-----(3*3卷积升维操作,表中3*3)------28*28*128
因为要保证特征图不变,所以3*3卷积要padding 1
inception(3a)并行分支3:28*28*192-----(1*1卷积降维操作,表中5*5reduce)------28*28*16
28*28*16-----(5*5卷积升维操作,表中5*5)------28*28*32
因为要保证特征图不变,所以5*5卷积要padding 2
inception(3a)并行分支4:28*28*192-----(池化+1*1卷积,表中poolproj)------28*28*32
最终输出-------通道方向拼接:
28*28*(64+128+32+32)=====28*28*256
二、代码复现
1. 网络搭建部分代码
inception实现
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
# 对应 参数 配置 表 中 的 参数
super(Inception, self).__init__()
self.branch1 = ...
self.branch2 = ...
self.branch3 = ...
self.branch4 = ...
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)inception第四个分支
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
# pad保证输出大小等于输入大小
BasicConv2d(in_channels, pool_proj, kernel_size=1)
# BasicConv2d是自定义的, 一个卷积 + 一个relu
)四个分支拼接
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)torch.cat():
torch.cat((A,B),dim)时,除拼接维数dim数值可以不同,其余维数数值需相同,结果维度数不变
outputs中每个元素B C H W 按照维度C(索引为1)方向拼接
eg: A (2,3,4) B(4,3,4)
dim只能为0------------------------拼接结果shape(6,3,4)
torch.stack():
torch.cat((A,B),dim)时,A和B完全一样的shape,dim是新增的维度;结果会增加维度
eg: A B都是(3,3)
dim = 0-------------拼接结果shape(2,3,3)
dim = 1-------------拼接结果shape(3,2,3)
dim = -1-------------拼接结果shape(3,3,2)
辅助分类器使用:只在训练部分且使用辅助分类器才会被激活
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False): # 是否要aux_logits两个辅助输出
super(GoogLeNet, self).__init__()
......
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
......
def forward(self, x):
......
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
......
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
......
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x2. train部分
流程同01 02 一样:
如果使用辅助分类器,如下:
#使用两个辅助分类器的话,损失计算如下
for epoch in range(epochs):
net.train() # train
......
for step, data in enumerate(train_bar):
......
logits, aux_logits2, aux_logits1 = net(images.to(device))
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0 + loss1 * 0.3 + loss2 * 0.3 #辅助输出时,3个损失按比例计算总损失
loss.backward()
net.eval()
with torch.no_grad():
......
for val_data in val_bar:
......
logits = net(images.to(device))
# 因为是val,此时没有辅助器输出














 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









