







目录
参考资料:
仅是个人笔记
一、 理论知识
整体框架如下:
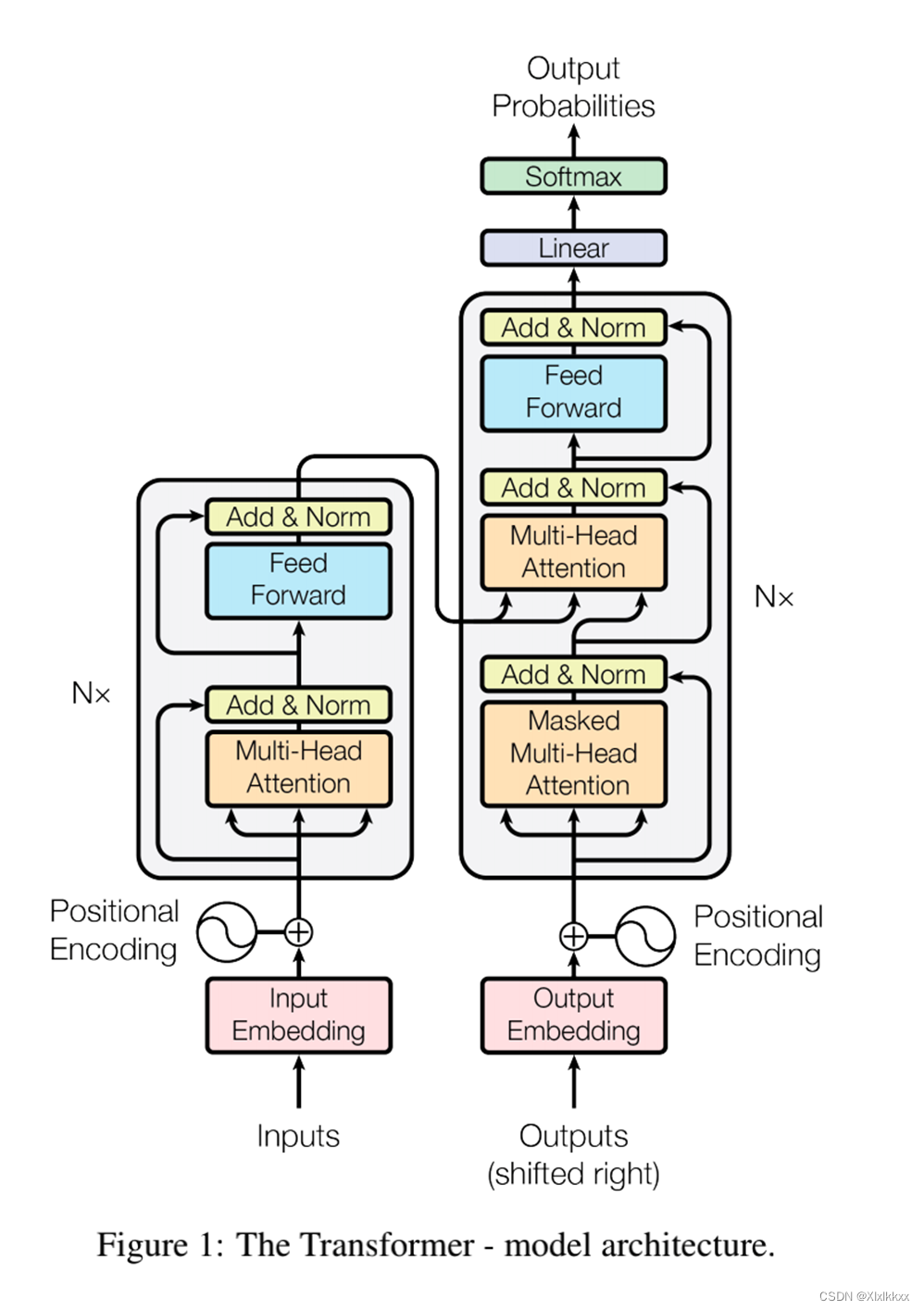
1. 编码器
由输入部分(1) + N个block(2 3)堆叠
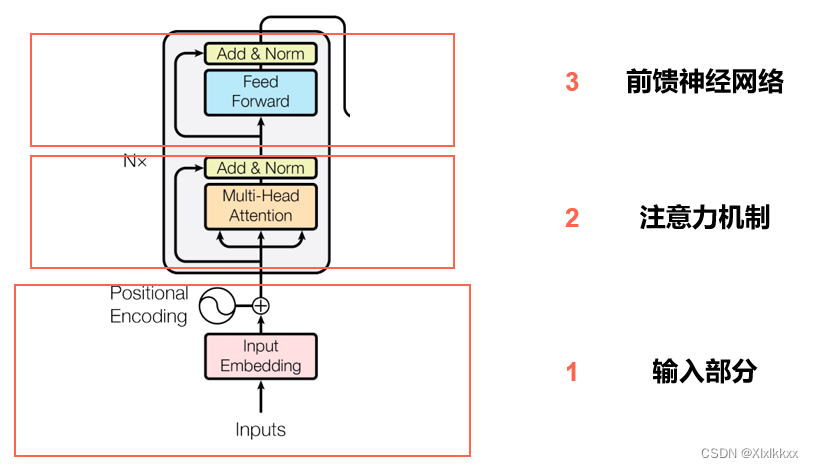
每个Block中包含了:
自注意力机制 + 残差链接 + LayerNorm + FC + 残差链接 + layer Norm
2. 解码器
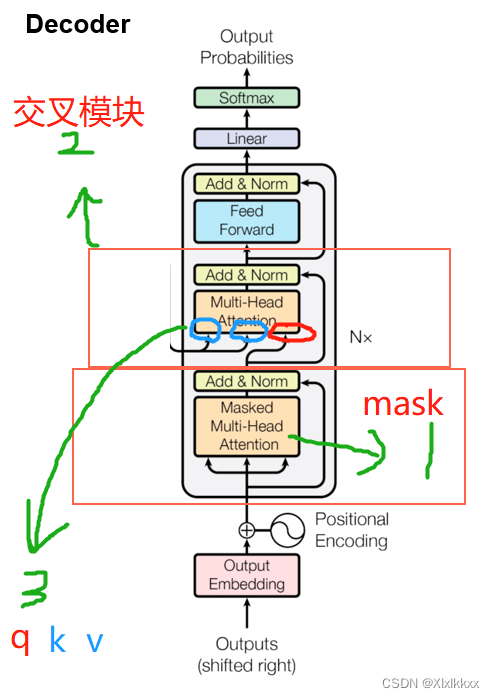
编码器与解码器的区别:
1. 将self attention 模块改成了 masked self-attention
2. 比编码器多了一个 Cross attention 交叉注意力模块
3. Cross attention 交叉注意力模块的Q K V来源不同
K V来自编码器最后一层的输出; Q 来自解码器的输出。如下图:
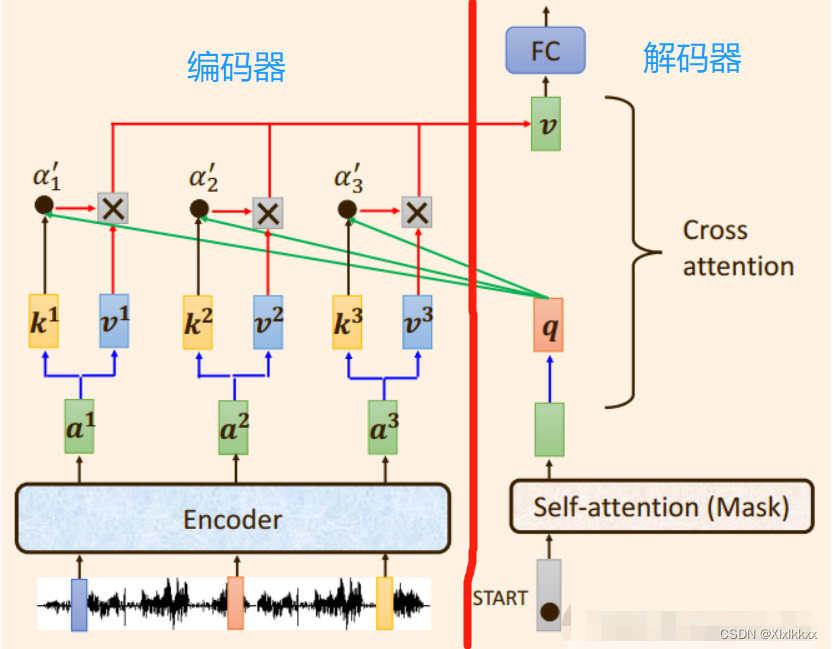
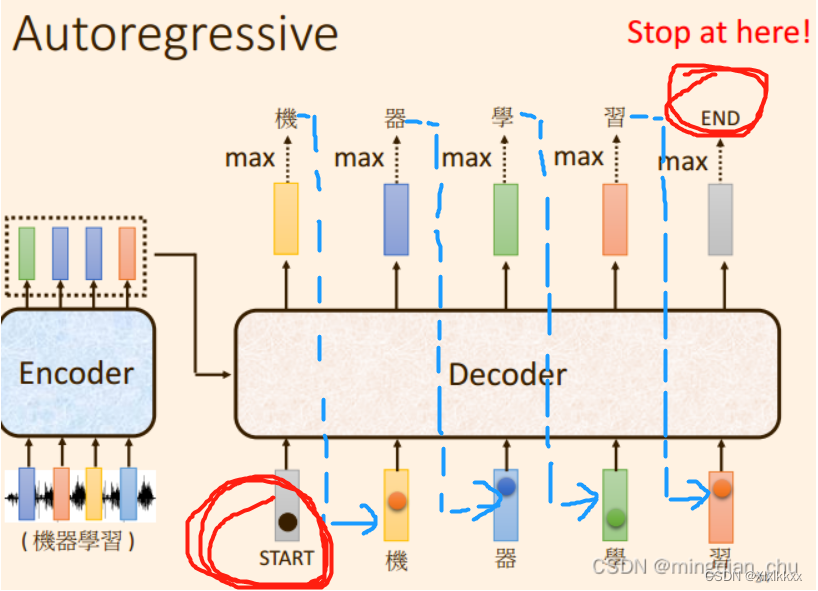
2.1 Decoder的流程
encoder完成编码(encoder是并行同时输入运算的)
decoder开始启动(递归单个输出):
会给decoder输入一个 “Start” 的标志,得到decoder的一个输出a;
下一步,把a输入到decoder,得到decoder的一个输出b;
下一步,把b输入到decoder,得到decoder的一个输出c;
.........
直到decoder的输出是一个结束标识符 “END” 。
整个Transformer流程结束。
如下图所示:
2.2 Mask含义
以上图为例:
第一步输入 “start”: decoder自注意计算只有 “start”, 得到输出 “机”
第二步输入 “机”: decoder自注意计算有 “start”和 “机”, 得到输出 “器”
第三步输入 “器”: decoder自注意计算有 “start”和 “机”和 “器”, 得到输出 “学”
。。。。。。
最后一步输入“习”: decoder自注意计算有 “start” “机” “器”“学”“习” 得到输出 “END”
过程结束。
Mask就是 和 当前输入 之前的输入做计算;而不是所有的输入做计算。
2.3 Decoder的输入 在训练和测试不一样
测试阶段(没有真实标签):
1.从input sequence中计算embeding,通过N个Encoder块得到各个单词之间关系。
2.使用一个开始的标志进行预测,例如上面的<SS>输入到decoder块中,并结合从Encoder中得到输入序列的关系,从而得到一个输出,即<SS>的下一个单词“Hola”。
3.将["<SS>", "Hola"]作为输入,重复上述过程,直到输出一个结束的提示,如<EOS>
在测试阶段是一个单词一个单词输出,而不是所有单词一起输出。
也就是标题 2.1 Decoder的流程
训练阶段(有真实标签):
- 模型训练时不宜采用上面的方式:
因为decoder 先前的输出 错误, 然后使用该 错误 作为decoder 当前的输入,有可能会导致后面的输出全部错误;而且递归单步输出,速度太慢。
- 充分利用label
训练阶段有label,但是label是存在偏移的;通过一个有偏移的label去预测一个没有偏移的label
eg:
decoder输入为 [‘<S>’, ’机’ , ‘器’, ‘学’, ‘习’]
输出为 [’机’ , ‘器’, ‘学’, ‘习’ , ’<E>’]
在训练阶段我们并行训练:
一次性给出decoder的全部输入,然后一次性预测decoder的全部输出
而不是像测试过程一样,只能用上一个单词的输出来预测下一个,
因此会产生一个问题:由于我们是直接将全部目标序列输入进行训练的,因此模型很容易看到未来信息,所以做Attention计算时使用MASK,只和当前输入 前面的输入做attention。
eg:
“s”:的自注意计算只有 “s”; “机”:的自注意计算有 “s”和 “机”
。。。。。。 “习”:的自注意计算有 “s” “机” “器”“学”“习”
二、 代码复现
目前看到的transformer时序预测,,,都只用了Encoder,之后使用全连接,decoder未使用attention???
有待继续查找资料,未解决
1. Transformer整体架构
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder() ## 编码层
self.decoder = Decoder() ## 解码层
self.projection = nn.Linear() #全连接---输出2. Encoder
包含三个部分:
词向量embedding;
位置编码部分;
注意力层及后续的前馈神经网络
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
## 这个其实就是去定义生成一个矩阵,大小是 src_vocab_size * d_model
self.pos_emb = PositionalEncoding(d_model) ## 位置编码
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
## 使用ModuleList对多个encoderlayer进行堆叠2.1 词向量embedding:
将某种格式的输入数据,例如文本,转变为模型可以处理的向量表示
借助torch提供的nn.Embedding

self.src_emb = nn.Embedding(src_vocab_size, d_model)
# 文字个数 每个文字的维度最终效果就是 输入(batch,len_seq)---------- 输出(batch,len_seq,dim)
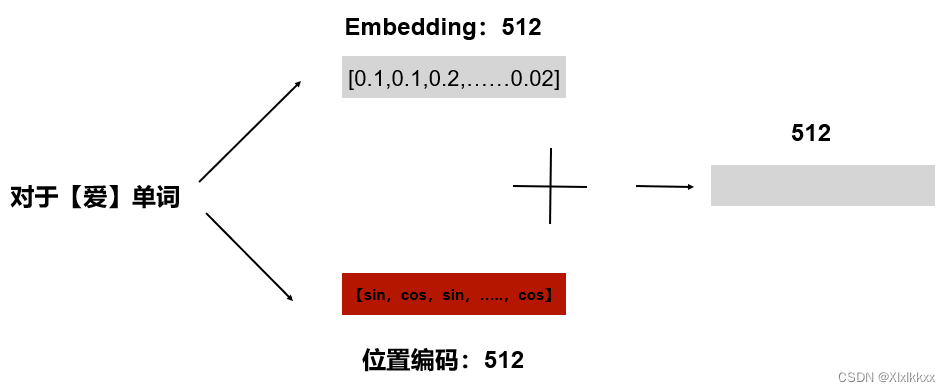
2.2 位置编码
所有的时间步是同时输入,并行推理的,因此要融合进位置编码的信息
## PositionalEncoding 代码实现
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
## pe[:, 0::2] 是从0开始到最后面,偶数位置
pe[:, 1::2] = torch.cos(position * div_term)
##pe[:, 1::2] 从1开始到最后面,奇数位置
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
## 定一个缓冲区,这个参数不更新
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)最终效果就是 输入(batch,len_seq,dim)---------- 输出(batch,len_seq,dim)
2.3 EncoderLayer
下图中的 2+3 部分
- 先实现 MultiHeadAttention
需要一个小功能函数:scaled_dot_product_attention 没太懂。。。。
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn整个scaled_dot_product_attention所做的工作就是就是Q*K的转置,然后除以一个标量,然后softmax一下,最后乘以V向量。
在其中加入了两个mask操作。这是为了将Q和K中一些填充的为零的向量清除掉。
实现 MultiHeadAttention: 没太懂。。。。
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, Q, K, V, attn_mask):
##Q K V: [batch_size x len x d_model]
residual, batch_size = Q, Q.size(0)
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2)
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2)
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2)
# q_s k_s v_s : [batch_size x n_heads x len x d_k]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
# [batch_size x n_heads x len x len],就是把pad信息重复了n个头上
## ScaledDotProductAttention函数
## 得到的结果有两个:context: [batch_size x n_heads x len x d_v]
## attn: [batch_size x n_heads x len x len_k]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v)
# context: [batch_size x len_q x n_heads * d_v]
output = self.linear(context) # output: [batch_size x len_q x d_model]
return self.layer_norm(output + residual), attn - 前馈神经网络
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, inputs):
residual = inputs # 要先进行维度交换(B,len,dim)---(B,dim,len)
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
output = self.conv2(output).transpose(1, 2) # (B,dim,len)---(B,len,dim)
return self.layer_norm(output + residual)
######################### 注意是nn.Conv1d
Conv1d 输入输出以及卷积核维度:
对应文本数据
input (批大小, 数据的通道数, 数据长度)-------------------(B,dim,len)
output (批大小, 产生的通道数, 卷积后长度)-----------------(B,dim,len)
卷积后的长度:(n - k + 2 * p ) / s + 1
k: 卷积核大小,p: 使用边界填充,s: 步长。最终效果就是 输入(batch,len_seq,dim)---------- 输出(batch,len_seq,dim)
- 实现EncoderLayer
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask)
enc_outputs = self.pos_ffn(enc_outputs)
return enc_outputs, attn3. Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) # 同encoder
self.pos_emb = PositionalEncoding(d_model) # 同encoder
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])3.1 DecoderLayer
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention() # 同Encoder
# Decoder输入只有其自己的MultiHeadAttention
self.dec_enc_attn = MultiHeadAttention()
# Decoder同Encoder的交互层
self.pos_ffn = PoswiseFeedForwardNet() # 同Encoder














 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









