






导论:
在机器学习中,我们需要对数据集的数据进行处理,进而使用sklearn库中的一些函数对数据进行数据特征提取,训练模型,其中fit,transform,fit_transform是进行数据的预处理。
函数解释:
fit(): Method calculates the parameters μ and σ and saves them as internal objects.
解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。(相当于训练模型)
transform(): Method using these calculated parameters apply the transformation to a particular dataset.
解释:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。

fit_transform(): joins the fit() and transform() method for transformation of dataset.
解释:fit_transform是fit和transform的组合,既包括了训练又包含了转换。
transform()和fit_transform()二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等
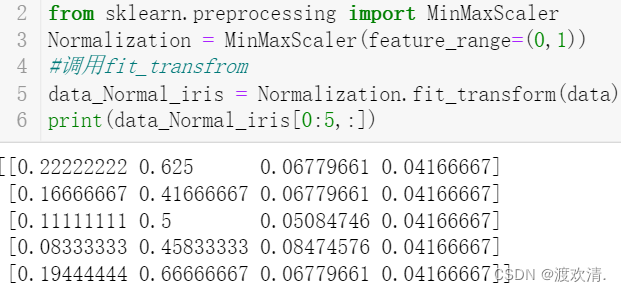
注意事项:
必须先用fit_transform(trainData),之后再transform(testData)。如果直接transform(testData),程序会报错。如果fit_transfrom(trainData)后,使用fit_transform(testData)而不使用transform(testData),虽然也能归一化,但是两个结果不是在同一个“标准”下的,具有明显差异。(一定要避免这种情况)
五. 为何训练集使用fit_transform(),而测试集使用tranform(),不再使用fit_transform();
因为在trainData的时候,已经使用fit()或者fit_transform得到了整体的指标(均值,方差等),所以在测试集上直接transform(),使用之前的指标,如果在测试集上再进行fit(),由于两次的数据不一样,导致得到不同的指标,会使预测发生偏差,因为模型是针对之前的数据fit()出来的标准来训练的,而现在的数据是新的标准,会导致预测的不准确。
fit_transform()干了两件事:fit找到数据转换规则,并将数据标准化。transform:是将数据进行转换,比如数据的归一化和标准化,将测试数据按照训练数据同样的模型进行转换,得到特征向量。
可以直接把转换规则拿来用,所以并不需要fit_transform(),否则,两次标准化后的数据格式(或者说数据参数)就不一样了















 3359
3359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









