







目录
1. 明确项目背景和需求
项目目的:
项目是为了通过对某电商用户的行为进行分析,从而找到提升GMV方法。
分析思路:
项目GMV的拆解公式为:GMV=UV(独立访客数)* 用户下单转化率 * 客单价,由于数据集不涉及客单价相关的内容,故优化GMV主要考虑提高UV和提升转化率这两个方面。提高UV的方法就是拉新,这需要对我们的用户进行拆解,找出新客户的来源的主要渠道,拉来更多的新用户。提高转化率主要有两方面:一方面是提高转化率高的那群人的占比,这需要找出哪些因素(随机森林模型)影响了用户的转化率,另一方面是找出转化率的环节,看是否有异常,如果有就优化掉。
2 数据探索(EDA)
2.1 数据集信息
因列数太长,无法完全显示,故一一列出各列的含义:
user_id :用户id
new_user :是否新用户 是:1、否:0
age :用户年龄
sex :用户性别
market :用户所在市场级别
device :用户设备
operative_system :操作系统
source :来源
total_pages_visited :浏览页面总数
home_page : 浏览过主页的用户
listing_page : 浏览过列表页的用户
product_page : 浏览过产品详情页的用户
payment_page : 浏览过支付结算页的用户
payment_confirmation_page : 浏览过确认支付完成页的用户
NAN值代表用户未浏览该页面,为了方便后面的计算,此处替换为0.
# 数据清洗
# 将不同页面的nan值替换为0
for col in['home_page','listing_page','product_page','payment_page','confirmation_page']:
user_info[col].fillna(0,inplace = True)
user_info.head() 可以看到已经转换成功了。
可以看到已经转换成功了。
# 便于计算,利用正则表达式将page页面信息转化为数字
for col in ['home_page','listing_page','product_page','payment_page','confirmation_page']:
user_info[col].replace(re.compile('page'),1,inplace=True)
user_info.head()
接下来通过info()了解数据类型,查看是否有缺失值(NAN)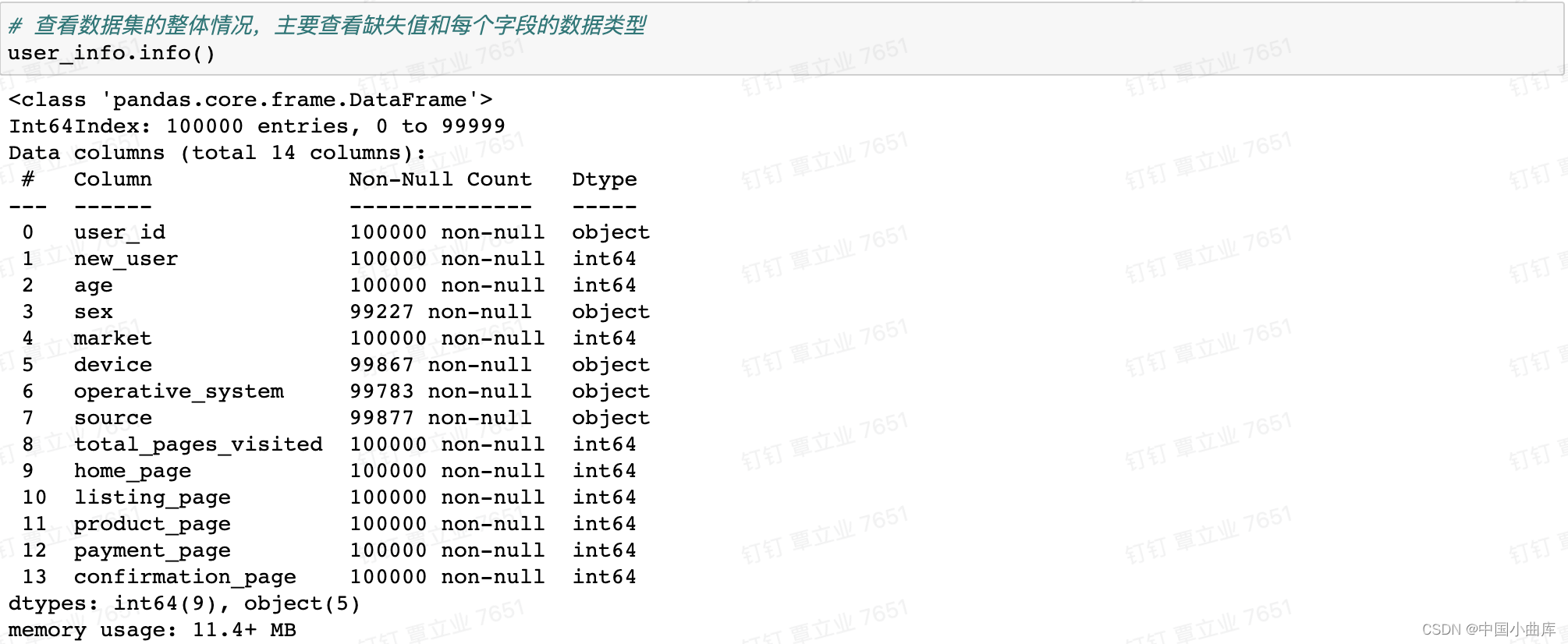
可以看到性别、设备、操作系统、来源存在空值,后面需要进行处理。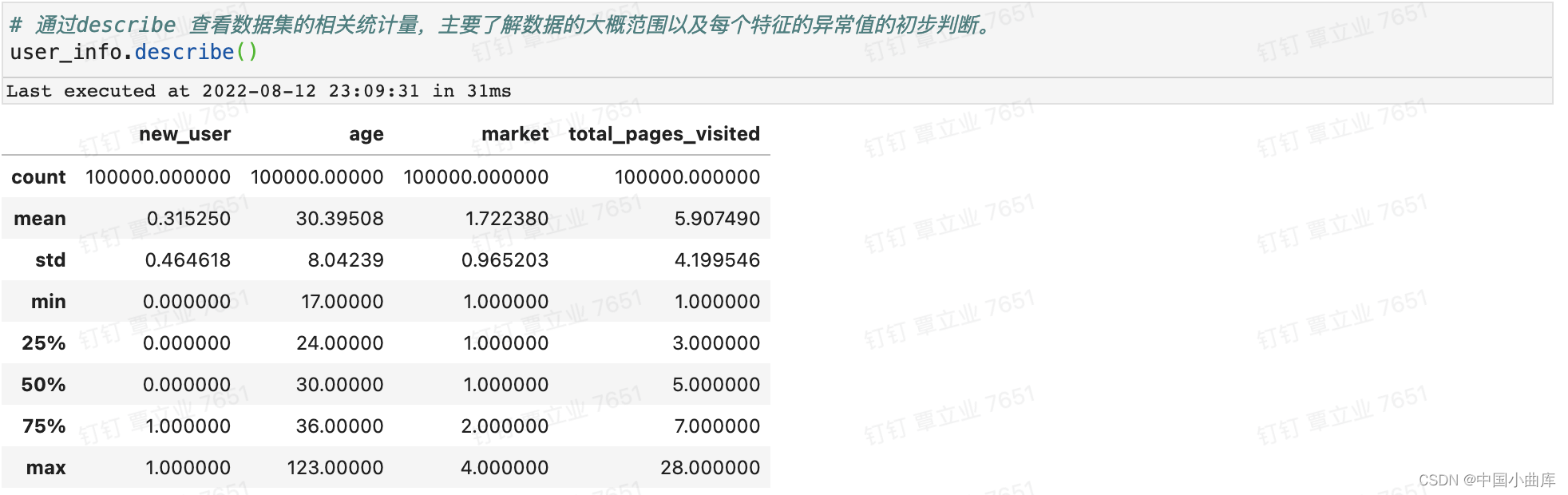
最大年龄有123岁,属于异常值,还需进一步查看大于100岁的用户个数。
查看数据维度
查看最终转化人数 查看最终转化率
查看最终转化率
这是我们项目数据集得到的最终转化率2.4%。
2.2数据预览
2.2.1 new_user
plt.figure(figsize=(10,6),dpi=400 )
new_user = pd.DataFrame(user_info['new_user'].value_counts().reset_index(name= 'counts'))
g = sns.barplot(x = 'index', y = 'counts',data = new_user)
for index,row in new_user.iterrows():
g.text(row.name,row.counts,row.counts,color = 'black',ha = 'center')
plt.xlabel('用户新老',fontsize=30)
plt.ylabel('数量',fontsize=30)
# width=0.1
plt.show()
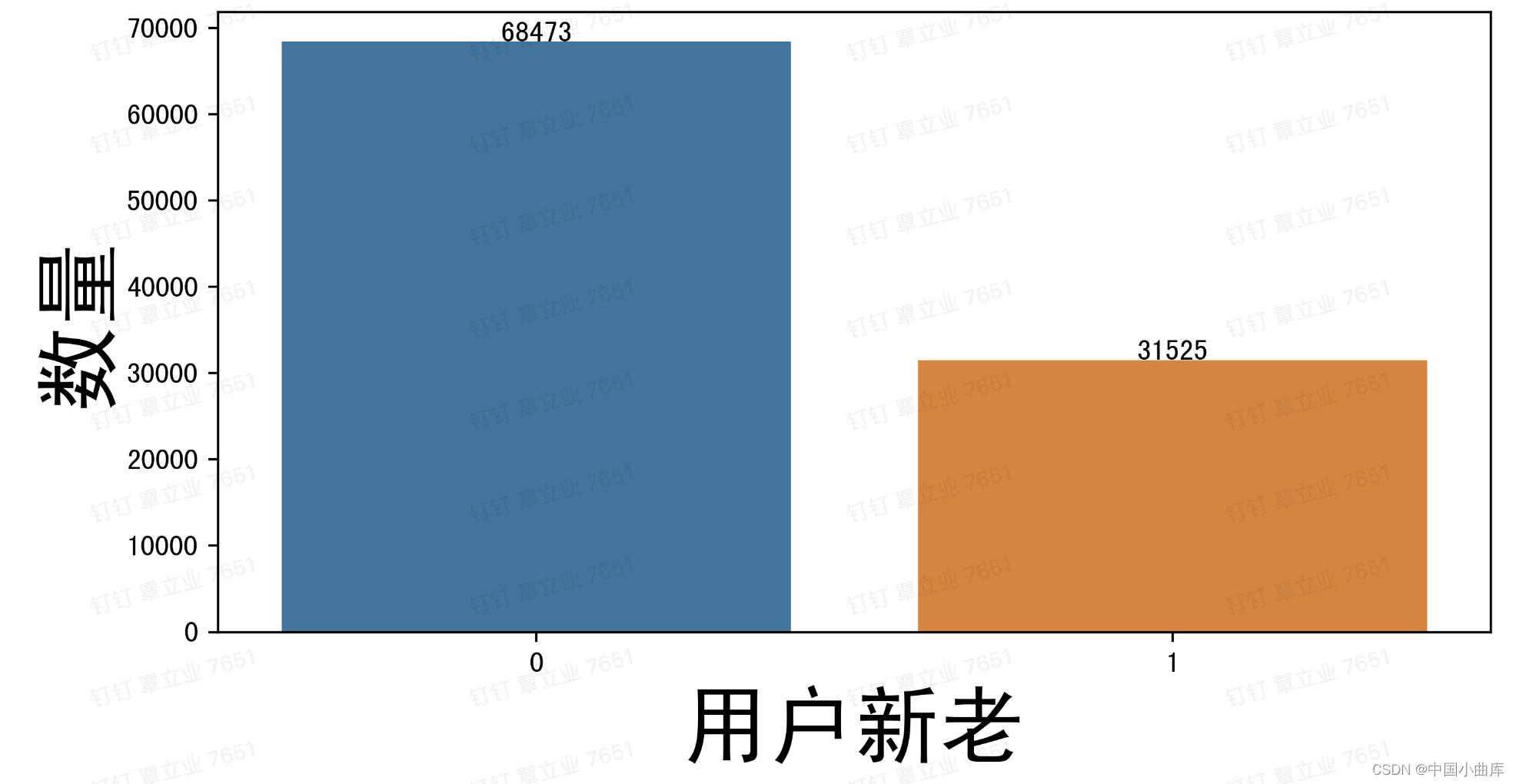
68475的新用户,31525万的老用户,为了直观的观察两者之间的比例,用饼图展示。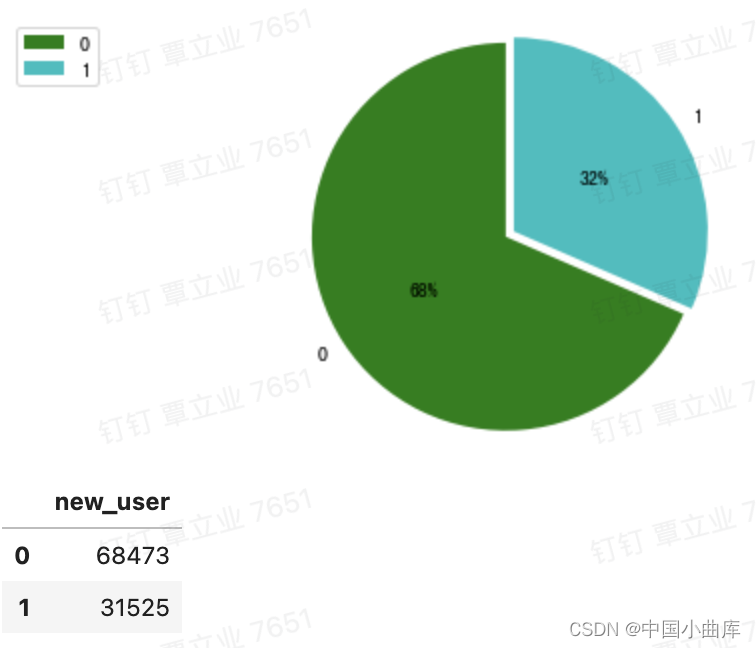
2.2.2 age
# age 年龄 选择用直方图观察,是连续型数值变量,所以可以用直方图展示
plt.figure(figsize=(8,6),dpi=400)
sns.displot(user_info['age'])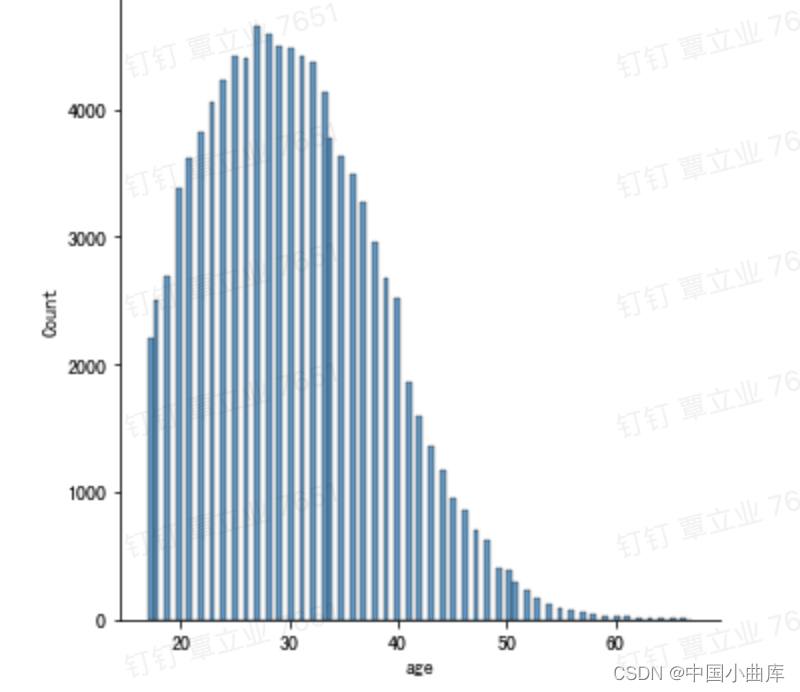
可以看到年龄基本集中在20~36岁,前面观察到的123基本可以确定为异常值了。
2.2.3 sex
# 性别
plt.figure(figsize=(10,6),dpi = 400)
sex = pd.DataFrame(user_info['sex'].value_counts().reset_index(name='counts'))
g = sns.barplot(x = 'index',y='counts',data = sex)
for index,row in sex.iterrows():
g.text(row.name,row.counts,row.counts,color = 'black',ha='center')
plt.xlabel('用户性别')
plt.ylabel('数量')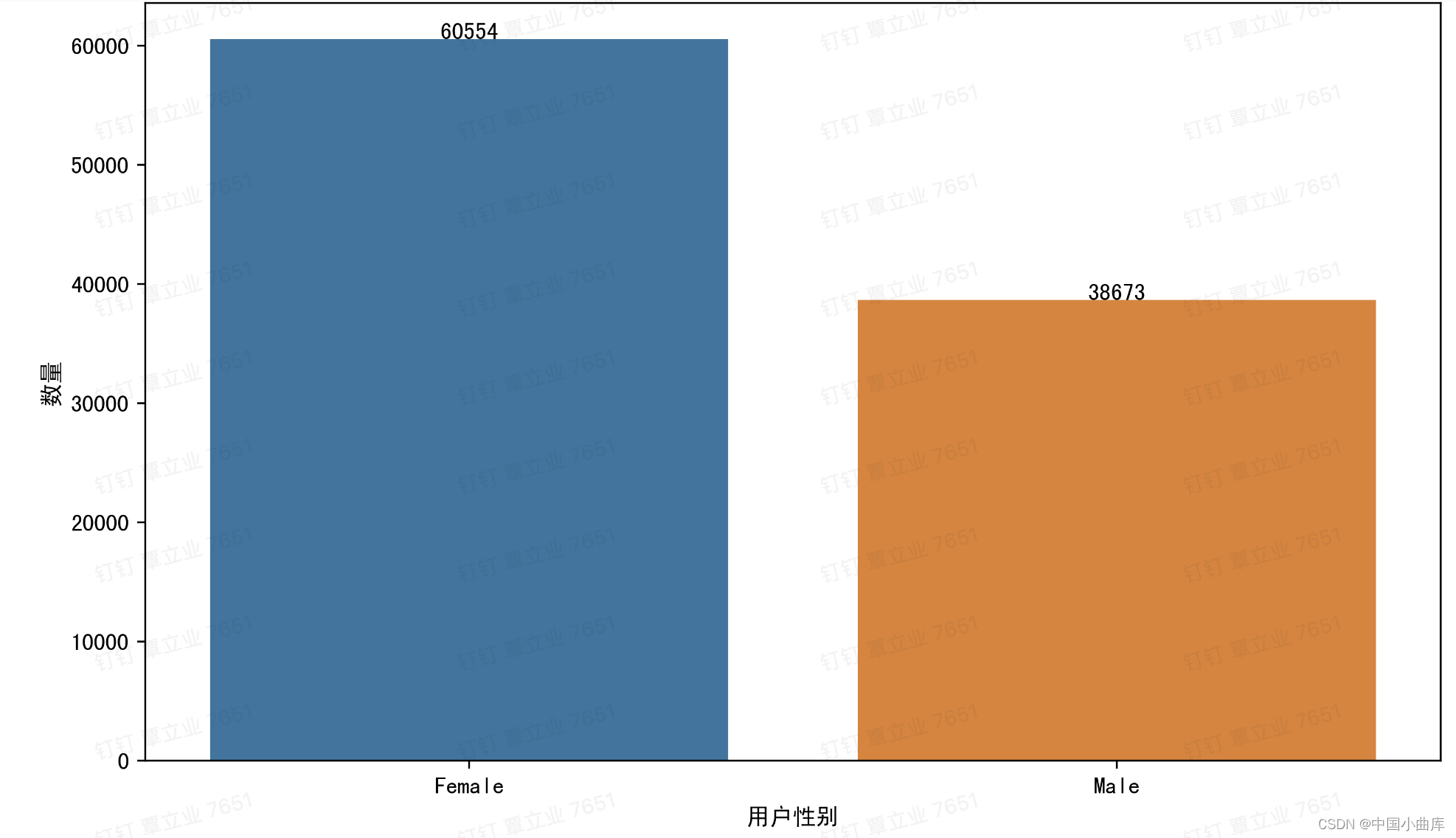
女性的用户数更多,同样的,看看男女之间的比例是多少
sex = pd.DataFrame(user_info['sex'].value_counts())
labels = sex.index
sizes = sex.values
colors = ['green','c','gray','beige','darkkhaki','fuchsia']
explode = (0.05,0)
patches,l_text,p_text = plt.pie(sizes,explode=explode,labels=labels,colors=colors,
labeldistance = 1.1,autopct='%2.0f%%',shadow=False,
startangle = 90,pctdistance = 0.5)
for t in l_text:
t.set_size = 30
for t in p_text:
t.set_size = 20
plt.axis('equal')
plt.legend(loc='upper Right',bbox_to_anchor = (-0.1,1))
plt.grid()
plt.show()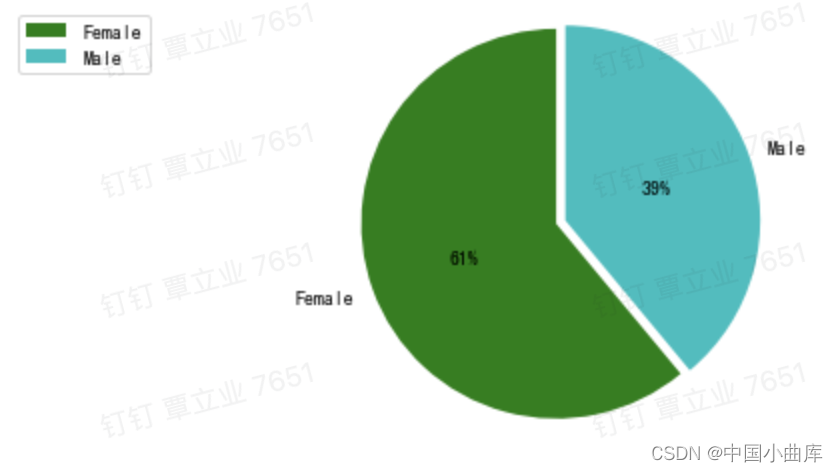
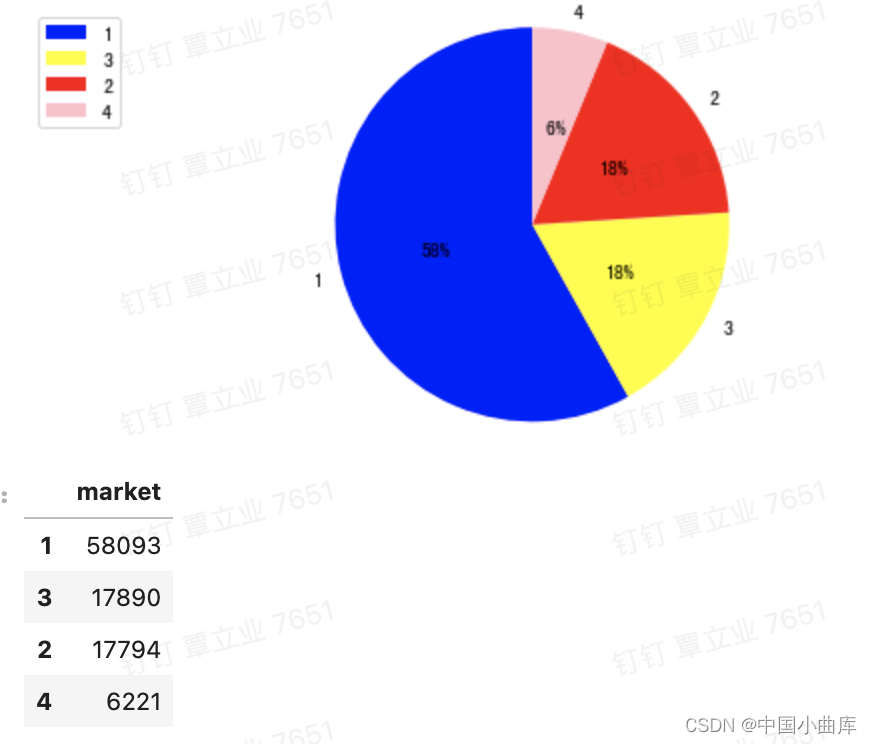
2.2.4 market
# market 看一下市场,我们看到一线城市的比例明显高于其他城市
plt.figure(figsize=(10,6),dpi = 400)
country = pd.DataFrame(user_info['market'].value_counts().reset_index(name='counts'))
g = sns.barplot(x = 'index',y='counts',data = country)
for index,row in country.iterrows():
g.text(row.name,row.counts,row.counts,color = 'black',ha='center')
plt.xlabel('市场级别')
plt.ylabel('数量')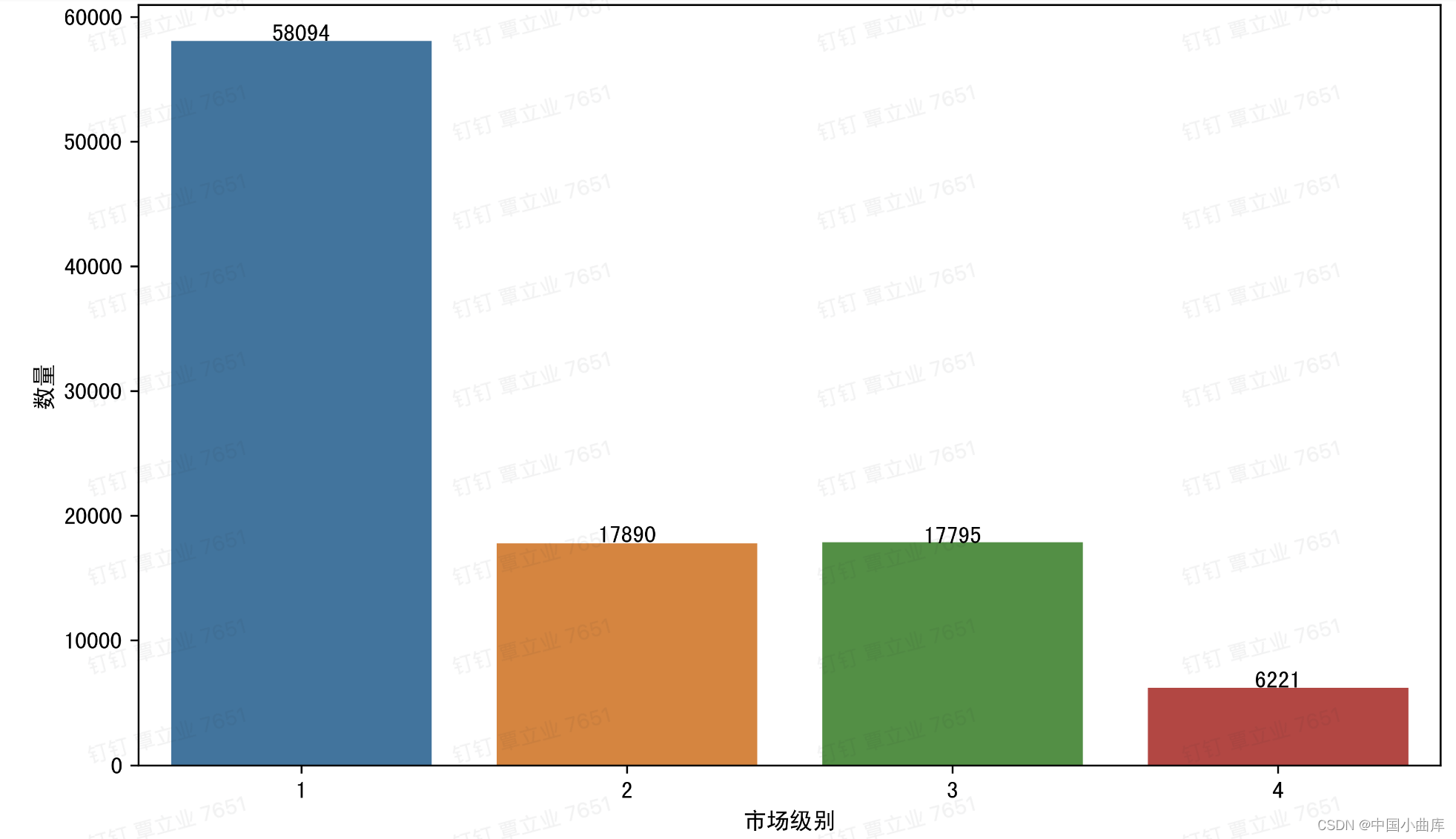
一线城市的用户数量明显多于2、3、4线城市。看看他们分别的占比
2.2.5 device
# device 设备 可以看到用手机登陆的,是比直接用桌面网页登陆的多
plt.figure(figsize=(20,8))
device = pd.DataFrame(user_info['device'].value_counts().reset_index(name ='counts'))
g = sns.barplot(x = 'index',y='counts',data = device)
for index,row in device.iterrows():
g.text(row.name,row.counts,row.counts,color = 'black',ha='center')
plt.xlabel('用户设备')
plt.ylabel('数量')
plt.show()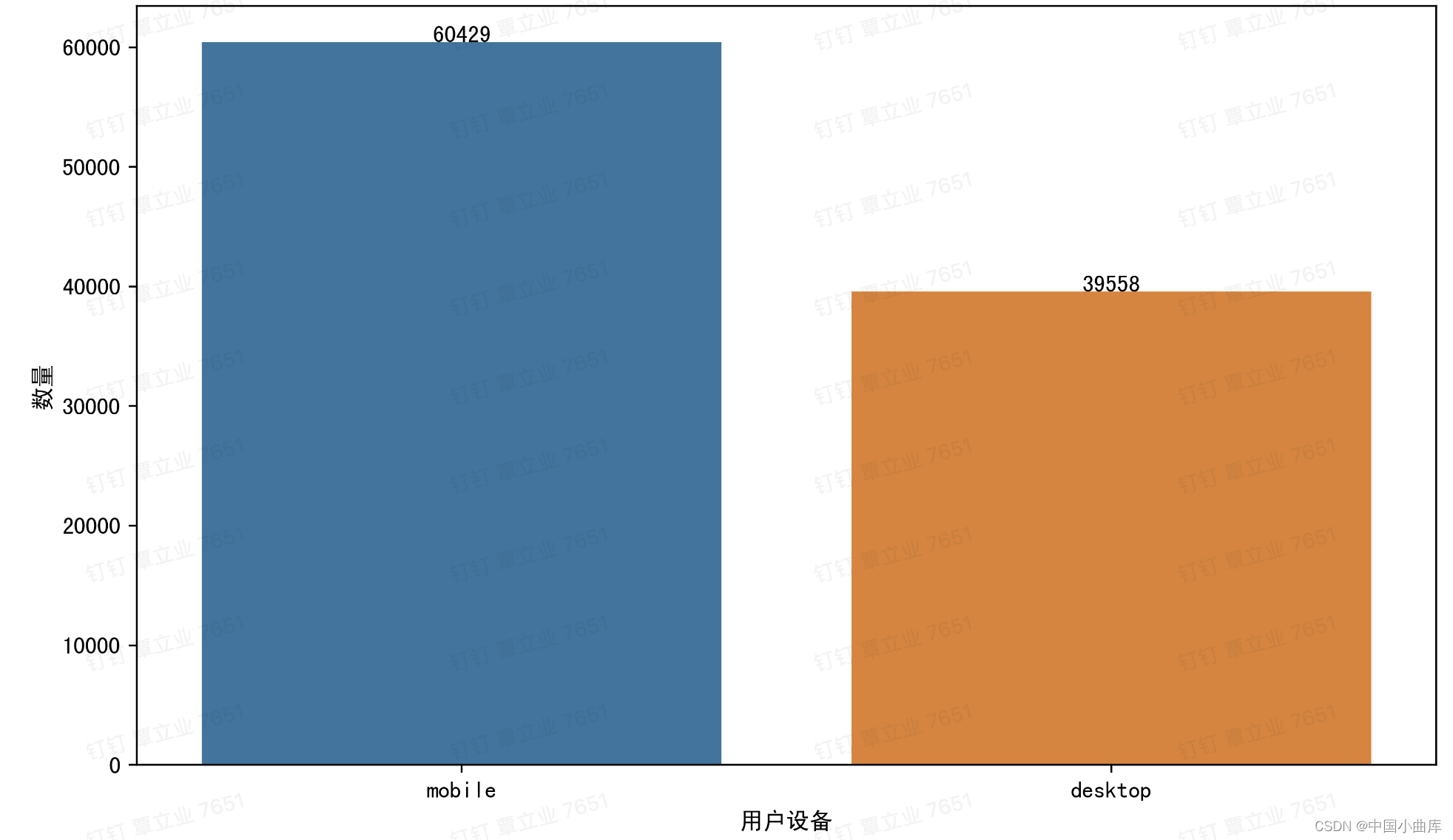
用手机登陆的该电商的数量,是比直接用桌面网页登陆的多,看看占比。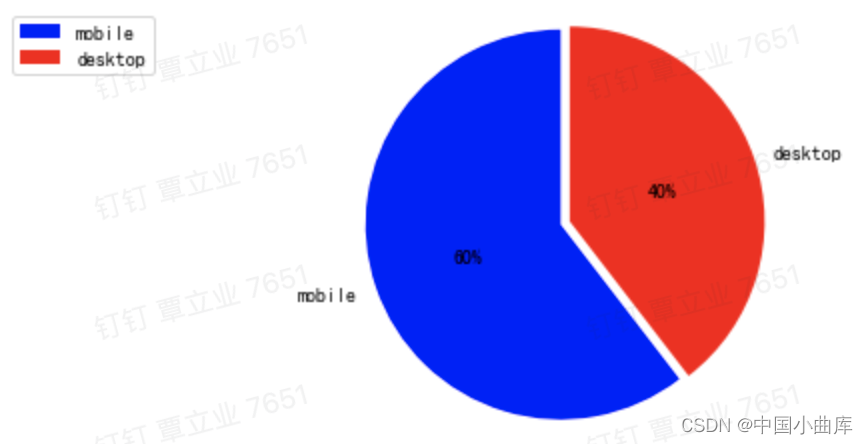
2.2.6 operative_system
# 操作系统,主流的三个操作系统
plt.figure(figsize=(20,8))
operative_system = pd.DataFrame(user_info['operative_system'].value_counts().reset_index(name ='counts'))
g = sns.barplot(x = 'index',y='counts',data = operative_system)
for index,row in operative_system.iterrows():
g.text(row.name,row.counts,row.counts,color = 'black',ha='center')
plt.xlabel('用户操作系统')
plt.ylabel('数量')
plt.show()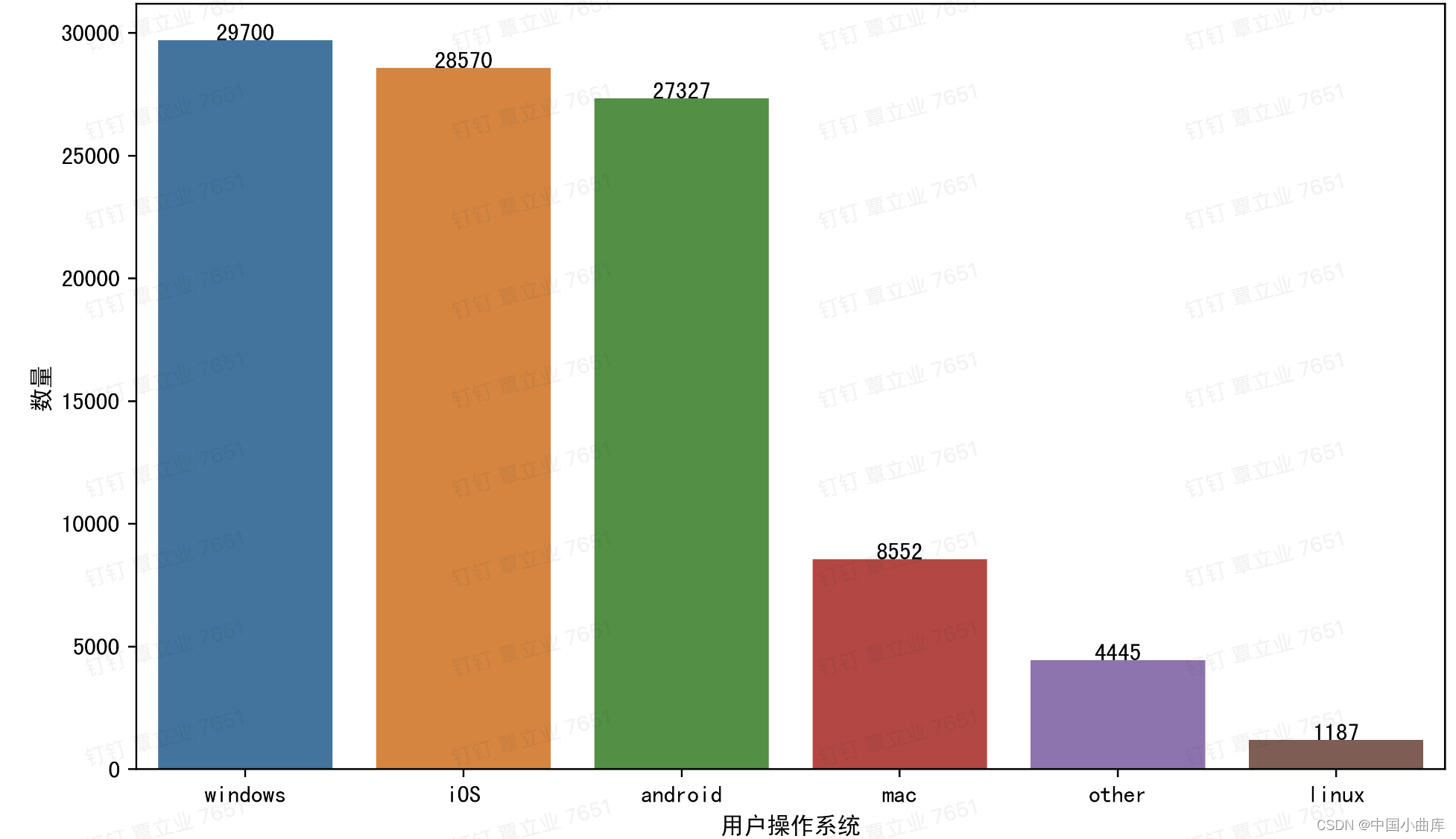
用户使用的最多的还是目前主流的操作系统:windos、iOS、android。看看各类的占比。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5262
5262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









