







在本文中,我们将探讨一些解释技术,以理解为什么做出了一个给定的预测。我们将看到不同的技术家族,并专注于两个最流行的:GNNExplainer和集成梯度。我们将使用Cora数据集将前者应用于图分类任务。然后,我们将介绍Captum,这是一个Python库,提供了许多解释技术。最后,使用Twitch社交网络,我们将实现集成梯度来解释节点分类任务上模型的输出。
文章目录
前言
图神经网络(GNN)在处理图结构数据(如社交网络、分子图和知识图)方面越来越受欢迎。然而,基于图的数据的复杂性和图中节点之间的非线性关系使得很难理解为什么GNN会做出特定的预测。随着图神经网络的普及,人们对解释其预测的兴趣也越来越大。
解释在实际机器学习应用中的重要性怎么强调都不为过。它们有助于在模型中建立信任和透明度,因为用户可以更好地了解预测是如何做出的,以及影响预测的因素。它们改善了决策,让决策者有了更多的理解,从而根据模型预测做出更明智的决策。解释还使从业者更容易调试和改进他们开发的模型的性能。在某些领域(如金融和医疗保健),由于遵从性和法规,甚至可能需要解释。
一、图解释技术
在本文中,我们区分“可解释的”和“可追溯的”模型。如果一个模型在设计上是人类可以理解的,那么它就被称为“可解释的”,比如决策树。另一方面,当它作为一个黑盒子,其预测只能通过解释技术追溯理解时,它是“可追溯的”。这是神经网络的典型情况:它们的权重和偏差不像决策树那样提供明确的规则,但它们的结果可以间接解释。
以下是四种主要的局部解释技术:
- 基于梯度的方法分析输出的梯度来估计归因分数(例如,集成梯度)。
- 基于扰动的方法屏蔽或修改输入特征以测量输出中的变化(例如,GNNExplainer)。
- 分解方法将模型的预测分解成几个术语来衡量它们的重要性(例如,图神经网络分层相关传播(GNN-LRP))。
- 代理方法使用简单且可解释的模型来近似原始模型对某个区域的预测(例如,GraphLIME)。
这些技术是互补的:它们有时在边缘和特征的贡献上存在分歧,这可以用来进一步完善预测的解释。传统上,解释技术是使用以下指标来评估的:
- 保真度:比较原图
G
i
G_i
Gi 和解释图
G
^
i
\hat{G}_i
G^i 对于真实值
y
i
y_i
yi 的预测概率。解释图只保留
G
i
G_i
Gi 中最重要的特征(节点、边、节点向量)。换句话说,保真度衡量的是重要特征,这些特征组合起来足以获得正确的预测,其公式定义如下:
F i d e l i t y = 1 N ∑ i = 1 N ( f ( G i ) y i − f ( G ^ i ) y i ) Fidelity=\frac{1}{N}\sum_{i=1}^N{\left( f\left( G_i \right) _{y_i}-f\left( \hat{G}_i \right) _{y_i} \right)} Fidelity=N1i=1∑N(f(Gi)yi−f(G^i)yi) - 稀缺度:测量重要特征在总特征中的比例(包括节点、边、节点特征)。特征越多解释起来越困难,这就是稀缺度提出的原因。其公式表达如下:
S p a r s i t y = 1 N ∑ i = 1 N ( 1 − ∣ m i ∣ ∣ M i ∣ ) Sparsity=\frac{1}{N}\sum_{i=1}^N{\left( 1-\frac{\left| m_i \right|}{\left| M_i \right|} \right)} Sparsity=N1i=1∑N(1−∣Mi∣∣mi∣)
式中, ∣ m i ∣ \left| m_i \right| ∣mi∣ 代表重要特征的数目, ∣ M i ∣ \left| M_i \right| ∣Mi∣ 代表总特征的数目。
在这篇博文中,我们将一步一步地介绍解释性模块,阐明框架的每个组件是如何工作的,以及它服务的目的。之后,我们将讨论各种解释评估方法和综合基准,它们携手合作,以确保您为手头的任务提供最佳解释。我们将继续看看现有的可视化方法。最后,我们将讨论在PyG中实现您自己的解释方法所需的步骤,并重点介绍在高级用例(如异构图和链接预测解释)上的工作。
二、GNNExplainer算法
2.1 算法原理
GNNExplainer是一种在GNN架构下解释另一个GNN模型的算法。在表格数据下,我们希望知道哪些特征和边对预测有重要的影响,然而仅仅观察表格数据是不够的。GNNExplainer通过生成子图
G
S
G_S
GS 和节点特征
X
S
X_S
XS 来产生预测,下图展示了GNNExplainer对选定节点的解释。

为了生成 G S G_S GS 和 X S X_S XS ,GNNExplainer应用了边掩码(edge mask:隐藏边连接)和特征掩码(feature mask:隐藏节点特征)。如果被隐藏的边或者节点特征是重要的,那么预测值会被改变。否则,预测值不会发生变化,这意味着被隐藏的信息是冗余的或者不想管的。该原理是基于扰动的方法(GNNExplainer)的核心。
在实践中,我们必须草拟合适的损失函数去寻找最优的掩码。GNNExplainer衡量标签 Y Y Y 分布和( G S G_S GS , X S X_S XS)之间的相互依赖性,也被称为交互信息(MI)。我们的目标是最大化MI,这等效于最小化交叉熵。GNNExplainer将寻找最优的变量 G S G_S GS 和 X S X_S XS 使得预测 y ^ \hat{y} y^ 的概率最高。
为了优化架构,GNNExplainer还学习二进制特征掩码以及应用正则化的技术。同时,最小化稀缺度。它被计算为掩码参数的所有元素的总和,并添加到损失函数中。它创建了更加用户友好和简洁的解释,更容易理解和解释。
GNNExplainer可以应用于大多数GNN架构和不同的任务,如节点分类、链接预测或图分类。它还可以生成类标签或整个图的解释。
2.2 应用Cora数据集
2.2.1 数据库导入
import os.path as osp
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
import torch_geometric.transforms as T
from torch_geometric.datasets import Planetoid
from torch_geometric.explain import Explainer, GNNExplainer
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import ExplainerDataset
torch.manual_seed(42)
torch.cuda.manual_seed(42)
torch.cuda.manual_seed_all(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
2.2.2 数据训练
在本实例中,采用Cora数据集,关于数据集的介绍具体见:GNN。
dataset = 'Cora'
path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', 'Planetoid')
dataset = Planetoid(path, dataset)
data = dataset[0]
数据的训练采用 GCN 架构,通过卷积层嵌入信息。
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, x, edge_index):
x = F.relu(self.conv1(x, edge_index))
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN().to(device)
data = data.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
for epoch in range(1, 201):
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
2.2.3 解释模型
首先,我们需要构建解释器。
explainer = Explainer(
model=model,
algorithm=GNNExplainer(epochs=100),
explanation_type='model',
node_mask_type='attributes',
edge_mask_type='object',
model_config=dict(
mode='multiclass_classification',
task_level='node',
return_type='log_probs',
),
)
在解释器中,我们使用GNNExplainer算法去解释模型。
针对explanation_type参数,有两种选择:
- phenomenom:其目的是连接输入和输出,解释两者之间的联系。选定该参数需要增加标签
target。 - model:其目的是为了解释训练后的模型,在该情况下,旨在打开黑盒子并解释其背后的逻辑。同时模型的预测将被用作标签。
针对node_mask_type和edge_mask_type参数,有多种选择:
- None:不会产生任何节点或边的掩码。
- object:会产生所有节点或边的掩码。
- common_attributes:会掩码每一个节点特征向量或边权重。
- attributes:在所有的节点或边分离的基础上掩码每一个节点特征向量或边权重。
针对mode参数,有三种选择:
- binary_classification:二分类模型。
- multiclass_classification:多分类模型。
- regression:回归模型。
针对task_level参数,有三种选择:
- node:预测节点的网络。
- edge:预测边的网络。
- graph:预测图的网络。
针对return_type参数,有三种选择:
- raw:返回原始值。
- probs:返回概率值。
- log_probs:返回对数概率。
2.2.4 结果可视化
在解释模型构建好后,我们将数据集代入。
# explain the node with index 10 with graph and feature importance
node_index = 10
explanation = explainer(data.x, data.edge_index, index=node_index)
print(f'Generated explanations in {explanation.available_explanations}')
explanation.visualize_feature_importance(top_k=10)
explanation.visualize_graph()
通过输入index=10,我们想要知道针对索引为10的节点,GCN架构是如何给出它的预测的。
可视化的结果如下。

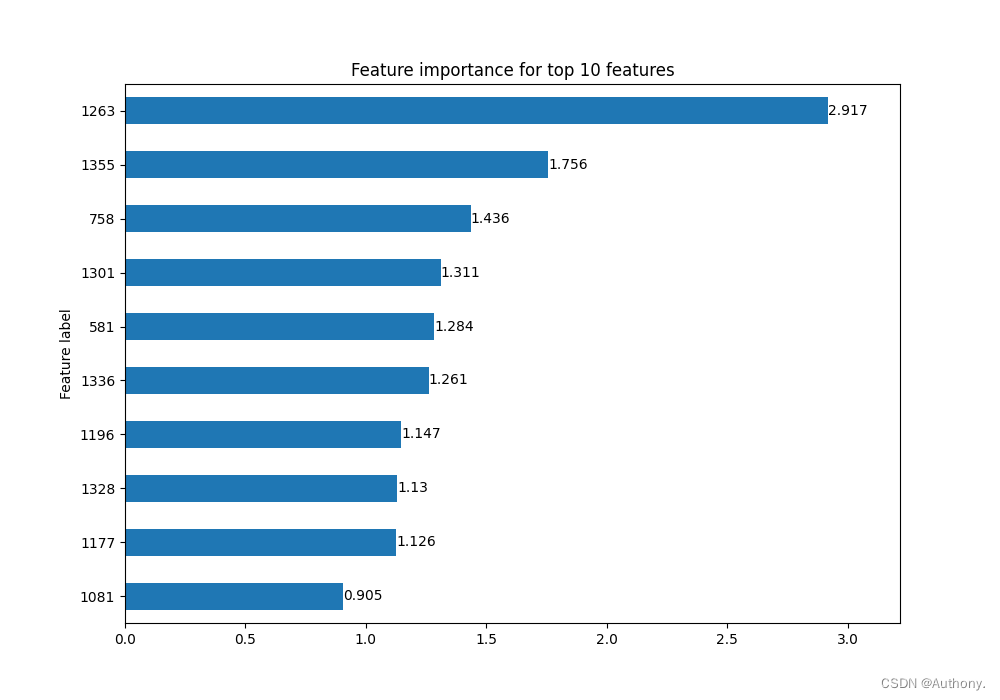
在图2中,显示了针对索引为10的节点,特征重要性前10的特征索引值。

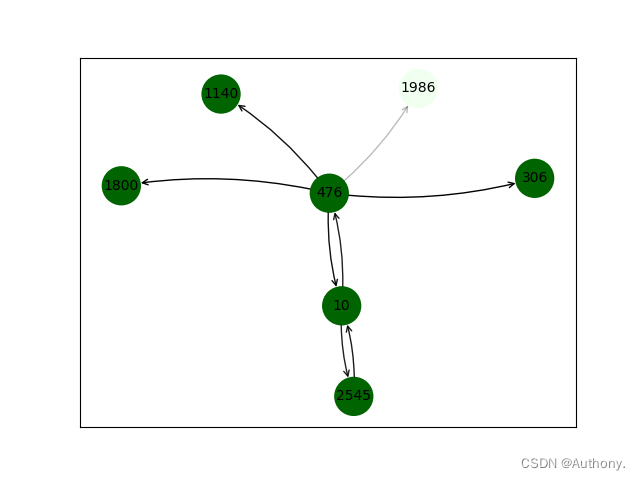
在图3中,连接线的不透明度代表了连接的重要性。可以看出对于节点10来说,节点476和节点2545对节点10的预测值有着重要的影响。
通过观察节点10、节点476和节点2545的输入特征 x x x 可以发现,三个节点的输入在1263、1355位置处都为1除了[2545, 1355]。因此,节点特征的重要性同节点关联可视化图是相互关联的,两者对于理解模型预测具有积极意义。
2.3 应用TUDataset数据集
2.3.1 数据库导入
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch.nn import Linear, Sequential, BatchNorm1d, ReLU, Dropout
from torch_geometric.datasets import TUDataset
from torch_geometric.nn import GCNConv, GINConv
from torch_geometric.nn import global_mean_pool, global_add_pool
from torch_geometric.loader import DataLoader
from torch_geometric.explain import Explainer, GNNExplainer
torch.manual_seed(42)
torch.cuda.manual_seed(42)
torch.cuda.manual_seed_all(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
2.3.2 数据训练
该数据集的训练,我们采用小批次的方式,具体可查看GIN。
dataset = TUDataset(root='data/TUDataset', name='MUTAG').shuffle()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Create training, validation, and test sets
train_dataset = dataset[:int(len(dataset)*0.8)]
val_dataset = dataset[int(len(dataset)*0.8):int(len(dataset)*0.9)]
test_dataset = dataset[int(len(dataset)*0.9):]
# Create mini-batches
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)
'''
GIN
'''
class GIN(torch.nn.Module):
"""GIN"""
def __init__(self, dim_h):
super(GIN, self).__init__()
self.conv1 = GINConv(
Sequential(Linear(dataset.num_node_features, dim_h),
BatchNorm1d(dim_h), ReLU(),
Linear(dim_h, dim_h), ReLU()))
self.conv2 = GINConv(
Sequential(Linear(dim_h, dim_h), BatchNorm1d(dim_h), ReLU(),
Linear(dim_h, dim_h), ReLU()))
self.conv3 = GINConv(
Sequential(Linear(dim_h, dim_h), BatchNorm1d(dim_h), ReLU(),
Linear(dim_h, dim_h), ReLU()))
self.lin1 = Linear(dim_h * 3, dim_h * 3)
self.lin2 = Linear(dim_h * 3, dataset.num_classes)
def forward(self, x, edge_index, batch):
h1 = self.conv1(x, edge_index)
h2 = self.conv2(h1, edge_index)
h3 = self.conv3(h2, edge_index)
h1 = global_add_pool(h1, batch)
h2 = global_add_pool(h2, batch)
h3 = global_add_pool(h3, batch)
h = torch.cat((h1, h2, h3), dim=1)
h = self.lin1(h)
h = h.relu()
h = F.dropout(h, p=0.5, training=self.training)
h = self.lin2(h)
return F.log_softmax(h, dim=1)
model = GIN(dim_h=32)
@torch.no_grad()
def test(model, loader):
criterion = torch.nn.CrossEntropyLoss()
model.eval()
loss = 0
acc = 0
for data in loader:
out = model(data.x, data.edge_index, data.batch)
loss += criterion(out, data.y) / len(loader)
acc += accuracy(out.argmax(dim=1), data.y) / len(loader)
return loss, acc
def accuracy(pred_y, y):
return ((pred_y == y).sum() / len(y)).item()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
epochs = 200
model.train()
for epoch in range(epochs+1):
total_loss = 0
acc = 0
val_loss = 0
val_acc = 0
# Train on batches
for data in train_loader:
optimizer.zero_grad()
out = model(data.x, data.edge_index, data.batch)
loss = criterion(out, data.y)
total_loss += loss / len(train_loader)
acc += accuracy(out.argmax(dim=1), data.y) / len(train_loader)
loss.backward()
optimizer.step()
# Validation
val_loss, val_acc = test(model, val_loader)
# Print metrics every 20 epochs
if(epoch % 20 == 0):
print(f'Epoch {epoch:>3} | Train Loss: {total_loss:.2f} | Train Acc: {acc*100:>5.2f}% | Val Loss: {val_loss:.2f} | Val Acc: {val_acc*100:.2f}%')
test_loss, test_acc = test(model, test_loader)
print(f'Test Loss: {test_loss:.2f} | Test Acc: {test_acc*100:.2f}%')
2.3.3 解释模型
同前文基本相同,在此不在赘述。
explainer = Explainer(
model=model,
algorithm=GNNExplainer(epochs=100),
explanation_type='model',
node_mask_type='attributes',
edge_mask_type='object',
model_config=dict(
mode='multiclass_classification',
task_level='graph',
return_type='log_probs',
),
)
2.3.4 结果可视化
在此处,模型的可视化的输入需要同模型训练时的输入相同,需要增加batch参数。不同的是,在此处的index代表可视化子图的索引。
# explain the graph with index 10 with graph and feature importance
for data in test_loader:
print(data)
break
node_index = 17
explanation = explainer(data.x,
data.edge_index,
batch=data.batch,
index=node_index)
# print(f'Generated explanations in {explanation.available_explanations}')
# explanation.visualize_feature_importance(top_k=10)
explanation.visualize_graph()
可视化结果如下。

在图4中可以发现,节点特征4-6的重要性为0,我们通过输出输入向量 x x x 得到:
0 1 2 3 4 5 6
count 333.000000 333.000000 333.000000 333.000000 333.0 333.0 333.0
mean 0.705706 0.114114 0.168168 0.012012 0.0 0.0 0.0
std 0.456411 0.318428 0.374578 0.109103 0.0 0.0 0.0
min 0.000000 0.000000 0.000000 0.000000 0.0 0.0 0.0
25% 0.000000 0.000000 0.000000 0.000000 0.0 0.0 0.0
50% 1.000000 0.000000 0.000000 0.000000 0.0 0.0 0.0
75% 1.000000 0.000000 0.000000 0.000000 0.0 0.0 0.0
max 1.000000 1.000000 1.000000 1.000000 0.0 0.0 0.0
从表格中可以发现节点特征4-6的数值都为0对预测结果基本不产生影响。而特征0的均值最大相对应的影响也就越高,节点2其次。
选择测试集的第17张子图,可视化结果如下:

通过观察输入向量 x x x 可知,节点287、节点292、节点293等关联性高的节点,其节点特征0或者节点特征2为1。
综上,GNNExplainer虽然并没有提供关于决策过程的精确规则,但提供了对GNN模型在做出预测时所关注的内容的见解。但仍然需要人类的专业知识来确保这些想法是连贯的,并与传统的领域知识相对应。
三、Integrated Gradients算法
当归因结果与人类经验相异的时候我们很难判断到底是模型的问题还是技术的问题,因此需要设定可解释算法必须满足的公理,用满足公理的技术进行归因得到的结果必然是模型所应有的。
3.1 算法原理
基线值:当我们把一件事情的发生归结于某个原因的时候,我们就可以把没有该原因的情况当做基线值,如状态不佳的原因是失眠(有状态),那没有失眠就是基线值,因为没有失眠对应的输出是啥事没有(无状态)。对于一个图像识别系统来说,基线值可以是一张全黑的图片;而对于一个NLP系统而言,基线值可以是全部值为0的词向量。
Integrated Gradients技术旨在为每个输入特征分配归因得分。为此,它使用相对于模型输入的梯度。具体来说,它使用一个输入 x x x 和一个基线输入 x ′ x' x′ (在我们的例子中,所有边的权重都为零)。它计算 x x x 和 x ′ x' x′ 之间路径上所有点的梯度,并将它们累加起来。
输入
x
x
x 沿着
i
t
h
i^{th}
ith 维的积分梯度定义如下:
IntegratedGrads
i
(
x
)
=
(
x
i
−
x
i
′
)
×
∫
α
=
0
1
∂
F
(
x
′
+
α
×
(
x
−
x
′
)
)
∂
x
i
d
α
\text { IntegratedGrads }_{i}(x)=\left(x_{i}-x_{i}^{\prime}\right) \times \int_{\alpha=0}^{1} \frac{\partial F\left(x^{\prime}+\alpha \times\left(x-x^{\prime}\right)\right)}{\partial x_{i}} d \alpha
IntegratedGrads i(x)=(xi−xi′)×∫α=01∂xi∂F(x′+α×(x−x′))dα
在实践中,我们不直接计算这个积分,而是用一个离散和来近似它。
集成梯度是模型不可知的,基于两个公理:
- 敏感度(Sensitivity):每一个对于预测有贡献的特征必然是非零属性。
- 实现不变性(Implementation Invariance):尽管内部实现不一致,但对于所有的输入,输出结果都是一致的两个模型被称为功能等效。面对两个功能等效的模型进行归因分析而获得相同的成因的归因算法满足实现不变性,这样子便是将得到输出的责任仅仅是归结于输入,与算法内部实现路径脱敏。
积分梯度算法满足敏感性和实现不变性的公理。从公式的表达可以看出积分梯度算法仅仅考虑了模型的输入输出且函数处处可微,不需要模型内部细节的参与,因此积分梯度算法是满足实现不变性的。而对于敏感型的公理,文章直接提出了一个新的公理为完整度(Completeness),并且直白地说完整度是敏感型的更高实现,其本身蕴含着敏感性,并没有进行具体的讲述和论证,下面尝试着按照我的理解解释一下。
完整度:归因技术以积分的方式加和了从基线值到输入间的输出值称为满足完整度。直接梯度是选取当前输入一个点进行输入输出的归因,当输入的特征值刚刚好处于梯度饱和阶段时,获得的归因结果在该特征上的归因比重往往微乎其微,但该输入特征并非不重要,这其实才是敏感性真正要解决的问题。而积分梯度通过在基线值和输入值之间选取了无限多个积分点进行积分加和即满足完整度,这时并不拘泥于梯度饱和阶段而更像是对 x i x_i xi - x i ′ x_i' xi′ 整体进行均衡加权归因,这样便巧妙地解决了梯度饱和问题,因此说完整度是蕴含了敏感性,是其更高的实现。
3.2 应用Cora数据集
Integrated Gradients考虑节点和边而不是特征。因此,您可以看到输出与GNNExplainer不同,后者考虑节点特征和边。这就是为什么这两种方法可以互补。现在让我们实现这个技术并可视化结果。
3.2.1 数据库导入
import os.path as osp
import pandas as pd
import numpy as np
import torch
import torch.nn.functional as F
from torch_geometric.datasets import Planetoid
from torch_geometric.explain import CaptumExplainer, Explainer
from torch_geometric.nn import GCNConv
np.random.seed(42)
torch.manual_seed(42)
torch.cuda.manual_seed(42)
torch.cuda.manual_seed_all(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
3.2.2 数据训练
dataset = 'Cora'
path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', 'Planetoid')
dataset = Planetoid(path, dataset)
data = dataset[0]
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, x, edge_index):
x = F.relu(self.conv1(x, edge_index))
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN().to(device)
data = data.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
for _ in range(1, 201):
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
3.2.3 解释模型
利用Integrated Gradients对训练模型进行解释。
explainer = Explainer(
model=model,
algorithm=CaptumExplainer('IntegratedGradients'),
explanation_type='model',
model_config=dict(
mode='multiclass_classification',
task_level='node',
return_type='log_probs',
),
node_mask_type='attributes',
edge_mask_type='object',
threshold_config=dict(
threshold_type='topk',
value=200,
),
)
3.2.4 结果可视化
node_index = 10
explanation = explainer(data.x, data.edge_index, index=node_index)
print(f'Generated explanations in {explanation.available_explanations}')
explanation.visualize_feature_importance(top_k=10)
explanation.visualize_graph()
与GNNExplainer算法的比较结果如下。
在图6和图7中左侧的两张图中GNNExplainer算法的结果,右侧的两张图是Integrated Gradients算法的结果。
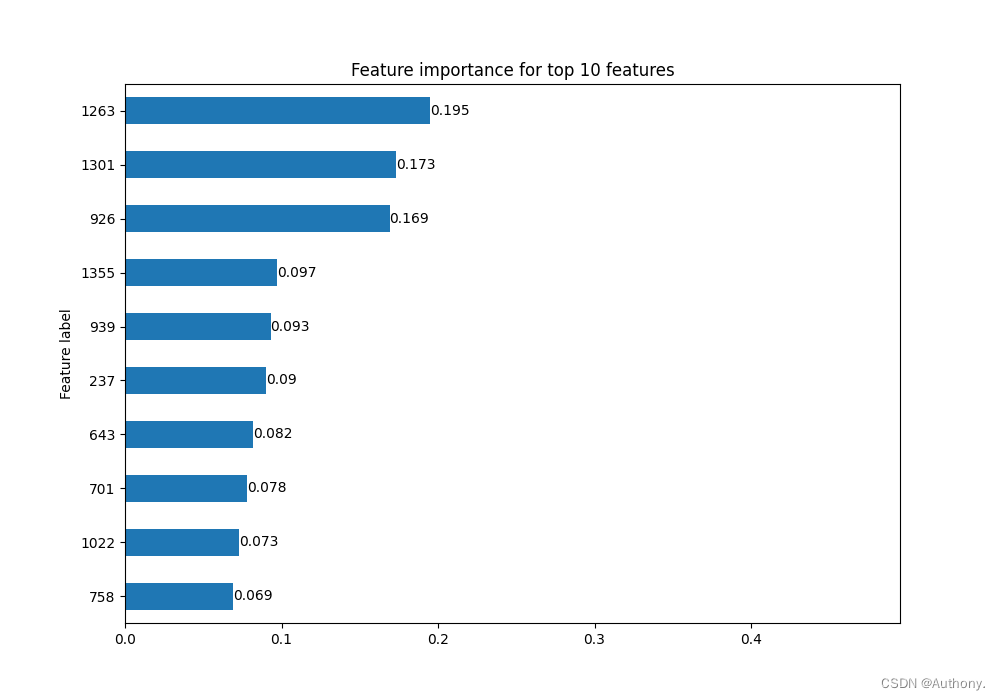
从图6中可以看出,两种不同算法分析得到的节点特征重要性排序是不同的,但在整体上又保持一定的一致性,我们可以结合实际分析不同的特征重要性结果。
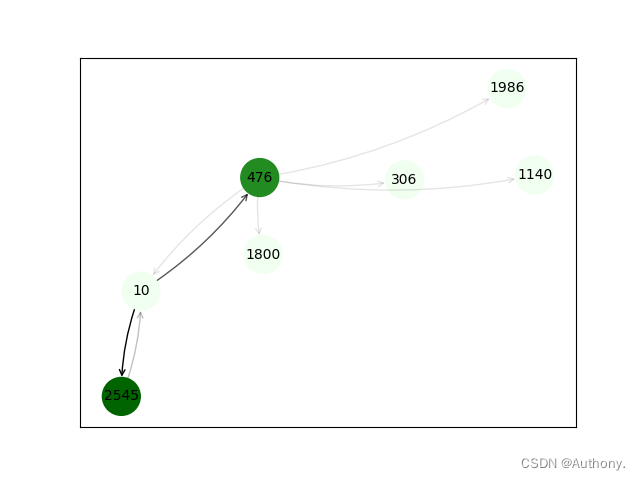
从图7中可以看出,针对节点10,两张算法分析得到的重要邻接节点是相同的。箭头的透明度代表了重要度,其中一跳邻接节点476和2545对于节点10的重要性较高,其他二跳节点重要性较低。
总结
综上,虽然图解释技术可以帮助我们很好的理解模型预测的过程,但是这些解释不应被视为灵丹妙药。人工智能的可解释性是一个丰富的话题,通常涉及不同背景的人。因此,沟通结果并获得定期反馈尤为重要。了解边、节点和特征的重要性是必要的,但这应该只是讨论的开始。来自其他领域的专家可以利用或改进这些解释,甚至可以发现可能导致架构更改的问题。
在本博文中,我们探讨了XAI应用于GNN的领域。可解释性在许多领域都是一个关键因素,可以帮助我们建立更好的模型。我们看到了提供局部解释的不同技术,并专注于GNNExplainer(基于微扰的方法)和Integrated Gradients(基于梯度的方法)。我们使用PyTorch Geometric在两个不同的数据集上实现了它们,以获得图和节点分类的解释。最后,我们对这些技术的结果进行了可视化和讨论。















 4967
4967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









