






1 基本认识
不管将对数据进行什么样的操作,对数据本身的理解包括对生成数据的业务的理解总是首要的。假设我现在要使用Keras对IMDB数据集进行二分类,那么我首先要去了解这个数据集是什么样子的。
首先,需要找到数据集的来源,一般在来源网站会有对数据集的描述。
使用bing或者google搜索引擎,将会出现高质量的数据集的可能的来源。
一般进入官网阅读官方指示文档。

找到自己想要研究的数据集: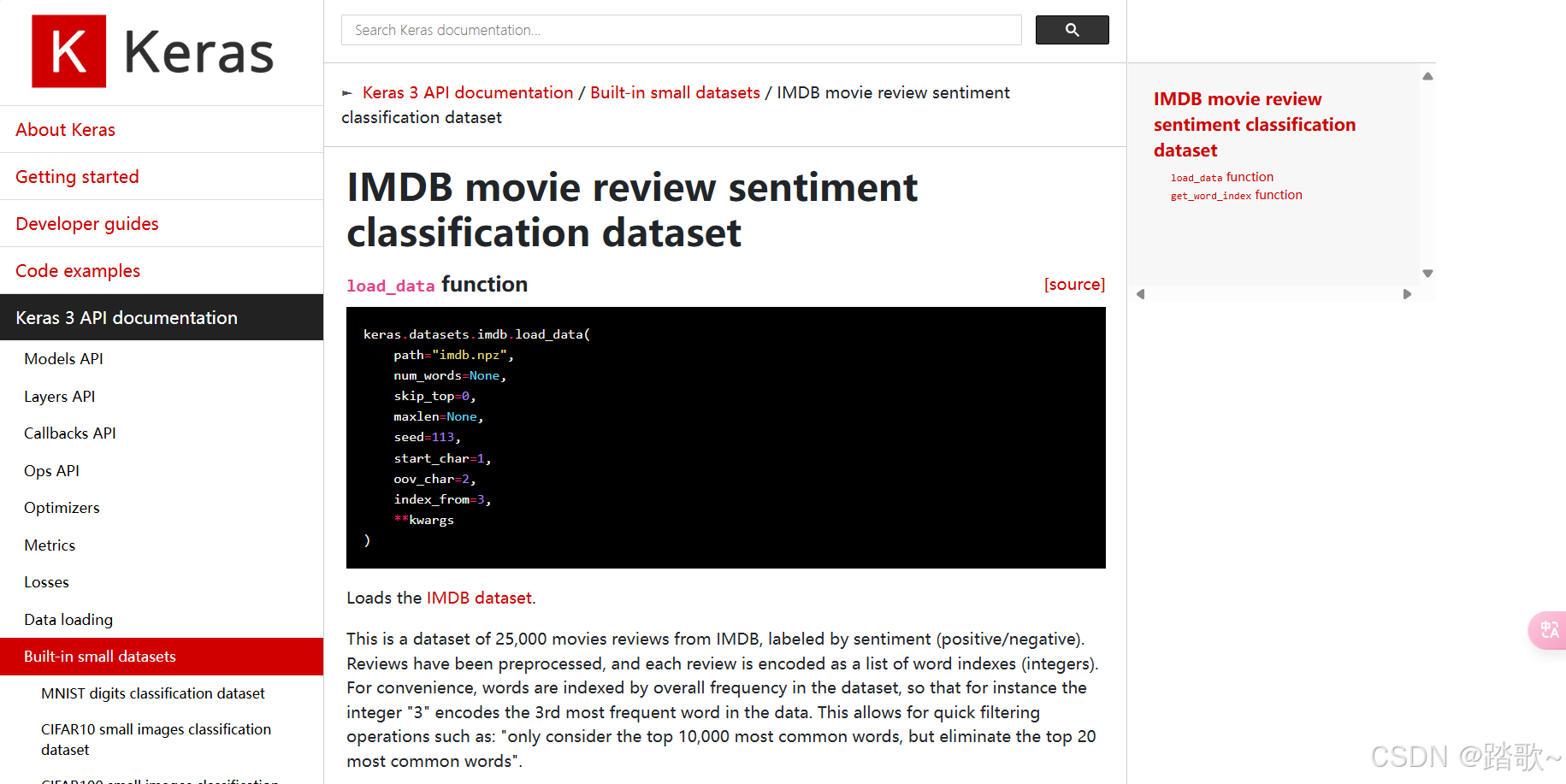
开始仔细阅读,起码要对开发者针对这个数据集开发的函数和参数有清晰的理解。
以下是对tf.keras.datasets里面的IMDB数据进行的理解和分析:
数据集的简单介绍:提供筛选后的极性影评数据,有输入和标签。输入形式可以为原始文本的格式也可以是由原始文本提取过后的词袋(输入是向量的形式)。
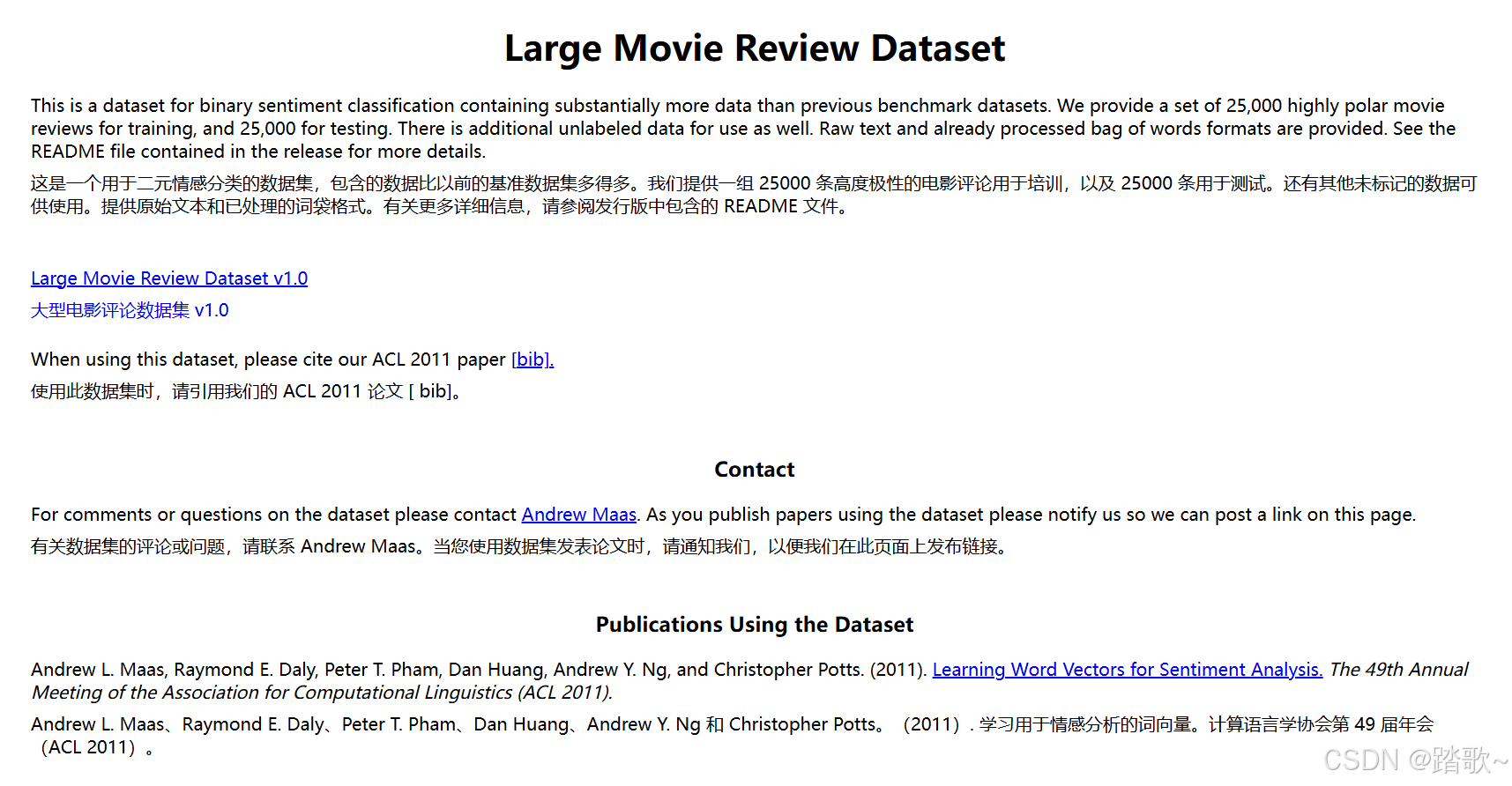
标签的意义是积极或者消极,数据集的数量是25000。
对于每条影评,其中的每一个单词都在一个列表中有索引。有这个索引的列表是这样构建的:
按照词频降序进行排序,例如某个单词被表示为3,那么去找对应的映射关系,它代表着第三个最频繁的单词;1000代表着第一千个最频繁的单词。
值得注意的是,这个词表是被处理过的。这样的操作是为了语义增强,使得每个单词替换成对应的索引数字后,这些数字能够尽量的区分每一句话。一般来讲是这样操作:
1、依据词频进行排序。
2、掐头去尾选择中间的词作为有效词,形成词列表。(词频很高的词假设每句话都有,每个句子里都有这个标记则无法利用这个标记进行句子的区分,故这样的词是无效的)(词频很低的词假设每句话都没有,极端情况是只有一个,那么一方面创建的这个标记几乎不会被用到,另一方面有这个词的句子还有很多有效词,这个低频词的作用会被大大减少,故这样的词也是无效的)
3、形成这个词表之后,这个词表的格式就不变了。当然,按照惯例会将列表的前三列当作功能列。例如,在这个数据集中,"0"被用作填充(pad)标记,而不是表示特定的单词。原因如下:
在IMDB数据集中,"0"被用作填充(pad)标记,而不是表示特定的单词。这种设计是为了处理不同长度的评论序列,以便在输入到模型时能够保持一致的形状。
解释填充的必要性
序列长度不一致:IMDB数据集中的电影评论长度各不相同。有些评论可能只有几个单词,而有些评论可能有几百个单词。为了在深度学习模型中进行批处理,所有输入序列需要具有相同的长度。
填充的作用:为了实现这一点,较短的评论会被填充到一个固定的长度(例如500个单词)。填充通常是在序列的开头或结尾添加特定的标记,以使所有序列达到相同的长度。在IMDB数据集中,"0"被用作填充标记。
当然还有其他可以人为设置的标记,例如这个数据集词表的第二列被用于标记序列开始start of sequence,第三列用于存储未知词unknow保留的索引。
4、对于一个具体的句子,不管其是否是用于构建词表的句子,还是根本没有见过的句子,都要使用构建的词表进行把单词进行数字化。其实就是把句子里的单词用词表里这个词对应的索引来表示。那么这就遇到一个问题,如果句子里出现的词是词表中没有的呢(这可能是由于遇到了词频很高或者很低的词)?一般的处理办法是把遇到词表中没有的词标记为一个特定的符号。例如这个数据集标记的就是"[OOV]"

下面解释对于这个数据集作者提供的操作的两个函数:load_data和get_word_index
2 load_data
2.1 输入
这个函数是这样使用的,你的输入如下:

其中每个参数的解释如下:
- path: where to cache the data (relative to
~/.keras/dataset).
path:缓存数据的位置(相对于~/.keras/dataset)。一般不需要改变。- num_words: integer or None. Words are ranked by how often they occur (in the training set) and only the
num_wordsmost frequent words are kept. Any less frequent word will appear asoov_charvalue in the sequence data. If None, all words are kept. Defaults toNone.
num_words:整数或无。单词按其出现频率(在训练集中)进行排序,并且仅保留最频繁num_words单词。任何频率较低的单词都将在序列数据中显示为oov_char值。如果为 None,则保留所有单词。默认为None。执行的是构建词表的去尾操作,即取所有降序词的前多少个词作为有效词。- skip_top: skip the top N most frequently occurring words (which may not be informative). These words will appear as
oov_charvalue in the dataset. When 0, no words are skipped. Defaults to0.
skip_top:跳过出现频率最高的前 N 个单词 (这可能没有信息)。这些字词将显示为oov_char数据集中的值。当 0 时,不跳过任何单词。默认为0。执行的是构建词表的掐头操作,即去除所有降序词表中的前多少个词。- maxlen: int or None. Maximum sequence length. Any longer sequence will be truncated. None, means no truncation. Defaults to
None.
maxlen:int 或 None。最大序列长度。任何更长的序列都将被截断。None,表示没有截断。默认为None。- seed: int. Seed for reproducible data shuffling.
种子:int。用于可重现数据随机排序的种子。- start_char: int. The start of a sequence will be marked with this character. 0 is usually the padding character. Defaults to
1.
start_char:int。序列的开头将使用此字符标记。0 通常是填充字符。默认值为1。- oov_char: int. The out-of-vocabulary character. Words that were cut out because of the
num_wordsorskip_toplimits will be replaced with this character.
oov_char:int。词汇外字符。由于num_words或skip_top限制将替换为此字符。- index_from: int. Index actual words with this index and higher.
index_from:int。使用此索引和更高索引为实际单词编制索引。
2.2 输出
你的输出如下:

3 get_word_index


但是一般操作的话,先使用上述函数返回一个字典,然后就是字典的操作。


















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











