







1. 背景
随着DeepSeek开源带来的影响不断扩大,2025年将会是AI Agent商业化应用爆发的一年。为什么会这么说?有几个原因。
1.1 开源推动大模型成本降低,加速企业采用 AI Agent
DeepSeek开源了V3和R1,企业和开发者可以低成本获得足够的 AI 能力,降低训练和推理成本,使得 AI Agent 不再是大厂或者是主流的几家大模型公司的专属。之前企业普遍依赖主流的几家大模型API。现在,DeepSeek让企业可以本地部署、私有化使用,降低了数据隐私泄露风险,提高可控性。这使得 AI Agent 可以在更多行业、企业和应用场景中落地,加速商业化。
1.2 AI Agent 具身化能力增强,提升实用性
DeepSeek 的开源不仅是语言能力的开放,它的训练方法、推理优化、模型架构等都给 AI Agent 发展带来了启发。AI Agent 可以结合视觉、代码生成、自动化操作等能力,与 GUI 交互。
- 自动化办公 Agent:解析 Excel、邮件、文档并执行任务。
- 代码开发 Agent:帮助工程师完成编码、调试和部署。
- 智能客服 Agent:结合视觉和语言能力,实现更自然的用户交互。
- 机器人控制 Agent:结合视觉导航,让 AI 控制真实世界中的机器人。
3. AI Agent + 开源生态 = 更快商业落地
DeepSeek 作为开源大模型生态的一部分,可以与 Hugging Face、LangChain、AutoGen、LlamaIndex 等开源框架结合,让 AI Agent 模块化、低成本、可定制化,推动 AI Agent 迅速落地商业应用。我们之前介绍了针对Agent的标准协议MCP《MCP(Model Context Protocol) 大模型智能体第一个开源标准协议》,其实就是为了更方便利用第三方接口能力,进行商业落地。
- 企业可以定制自己的 AI Agent,而不必依赖封闭 API。
- 创业公司门槛降低,可以更快开发产品,抢占市场。
- 开发者生态繁荣,更多应用可以基于 DeepSeek 开源模型构建,而不受限于 GPT-4。
2. 技术路线
针对AI Agent的构建,目前的主流技术路线有两种:
(1)基于端到端的模式,比如智谱清言推出的CogAgent系列【1】。其采用的是端到端的模式,CogAgent是一个 180亿参数的视觉语言模型(VLM),专门用于 GUI 理解与导航。采用低分辨率与高分辨率图像编码器。CogAgent 仅依赖屏幕截图作为输入,完成 PC 和 Android GUI 上的导航任务。
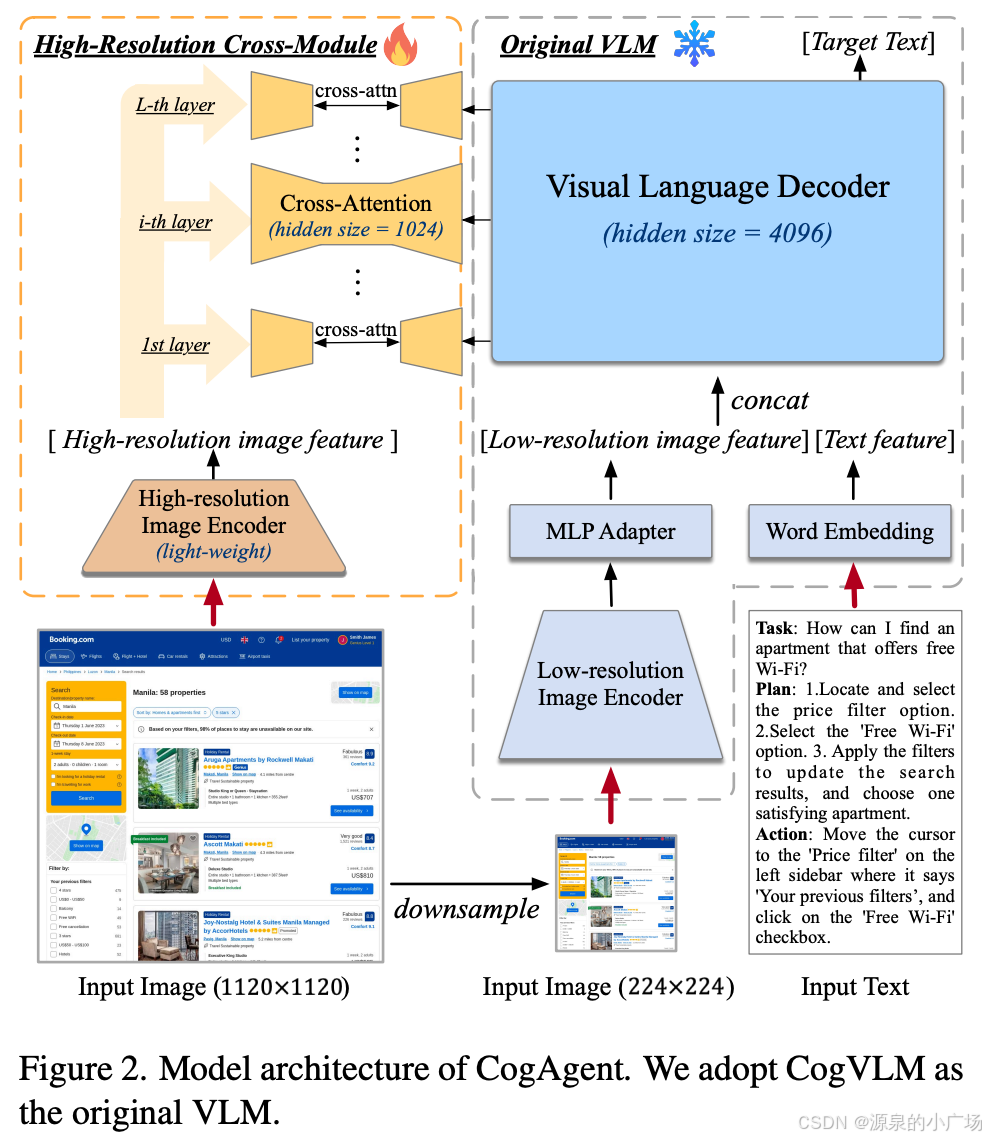
CogAgent构建了一个 GUI 和 OCR 标注数据集,以用于持续预训练。另外设计了跨注意力(cross-attention)分支。结合了 CogVLM 中的 ViT(4.4B 参数) 和一个 小型高分辨率跨模块(0.30B 参数的图像编码器),共同建模视觉特征。
这种方案有其优点,也有其弊端。如果训练数据不够充分的情况下,可能不太好训出一个稳定可靠的模型。另外端到端,如果出现错误,也很难做调整。还有网站一旦更新,势必需要重新训练模型,对于频繁更新的网站,不是很友好。
(2)思维链模式,也可以理解为多步推理。通过思维链提示来引导智能体导航,使其能够推理计算机的当前状态、回顾自身的过往操作,并决定最合适的下一步行动。
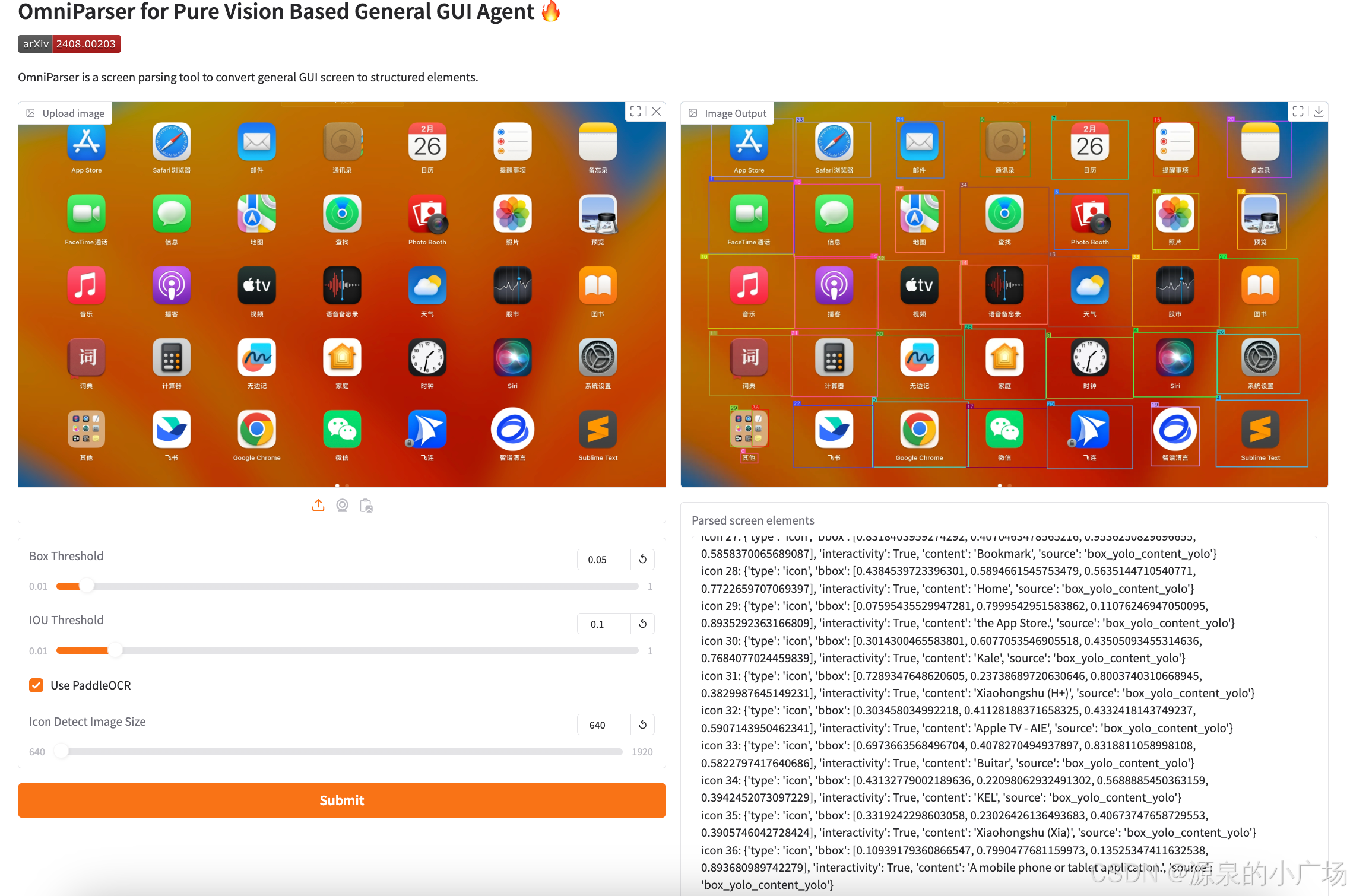
智能体接收以下输入信息:当前前台窗口的标题、所有其他窗口或当前打开的浏览器标签页的标题,以及当前屏幕的表示。比如采用OmniParser【2】模型,检测文本、图标和图像,并提供图标的文字描述,给到智能体进行识别确定下一步的动作,然后调用相应的工具执行。这种具备很强的可解释性和工程干预能力。

3. 基于OmniParser-V2+DeepSeek 实现路径规划
关于omniparser的部署,可以参考【3】。环境部署反正在国内是比较蛋疼的,问题慢慢解决。
这里就展示一个case:让智能体执行“查询浙江大学官网的最近一篇新闻并进行总结”的任务。
(1)给智能体发送当前界面截图进行识别
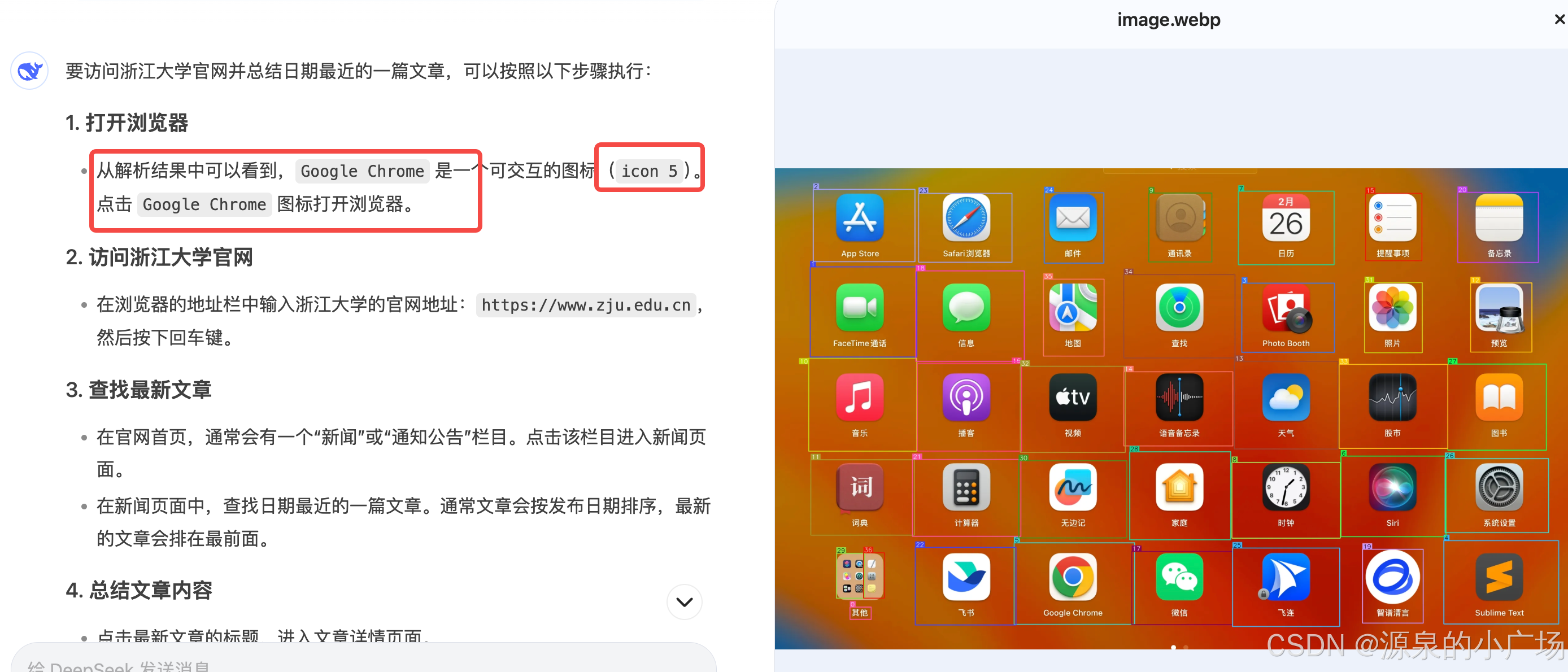
(2)将识别后的图片以及解析内容交给deepseek进行规划
prompt:给你一张omniparser识别的图,以及解析结果,帮我指定一个执行路径,访问浙江大学官网,总结日期最近的一篇文章。 以下是对应的解析:icon 0: {'type': 'text', 'bbox': [0.09253617376089096, 0.9117646813392639, 0.11881188303232193, 0.9373401403427124], 'interactivity': False, 'content': '#t', 'source': 'box_ocr_content_ocr'} icon 1: {'type': 'icon', 'bbox': [0.04344545677304268, 0.20500528812408447, 0.17521511018276215, 0.39236176013946533], 'interactivity': True, 'content': 'FaceTime ii ', 'source': 'box_yolo_content_ocr'} icon 2: {'type': 'icon', 'bbox': [0.047564536333084106...
(3)借助python的gui动作包点击icon5,并将打开后的界面给到omniparser识别
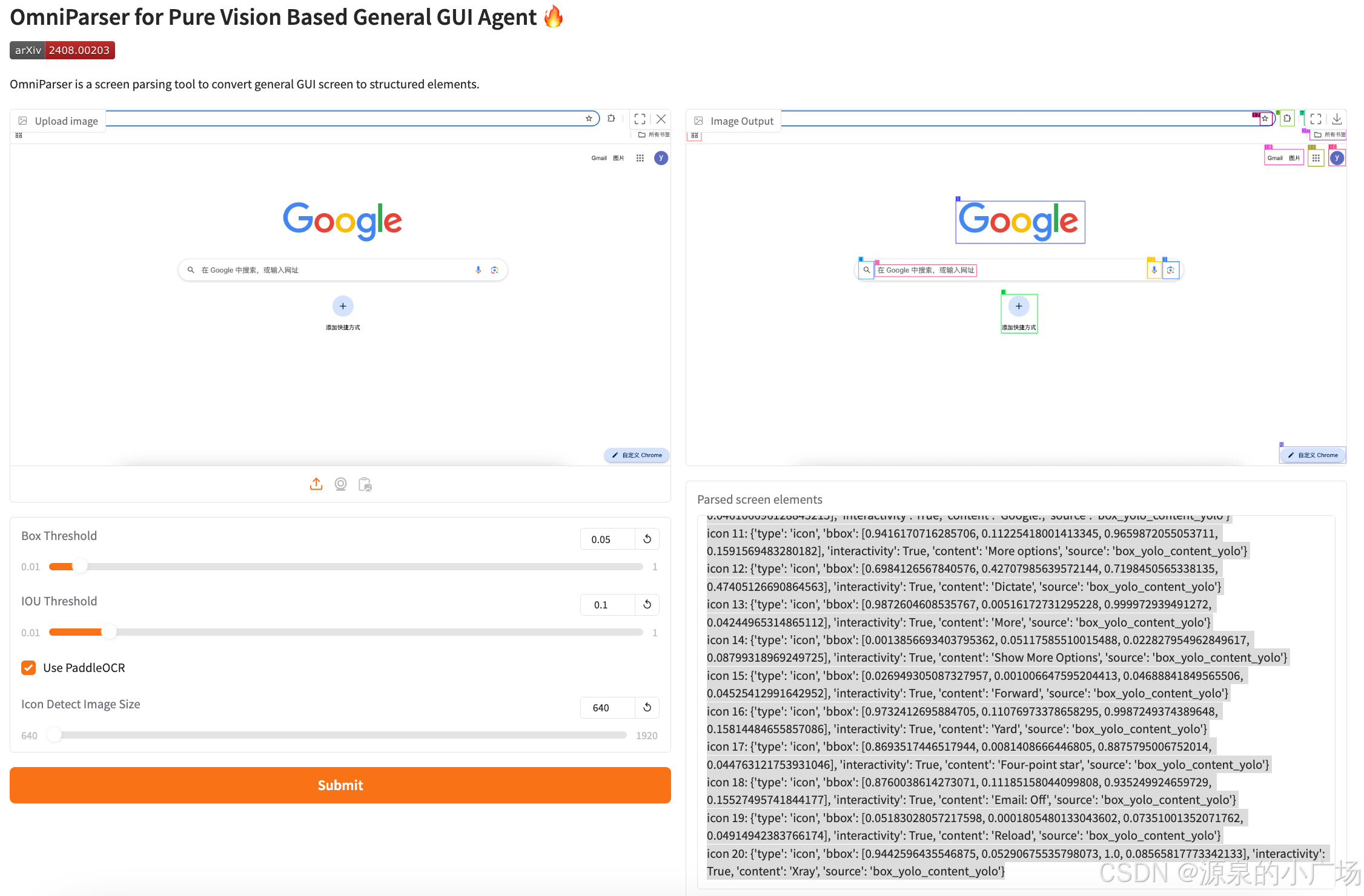
(4)继续使用deepseek规划下一步路径
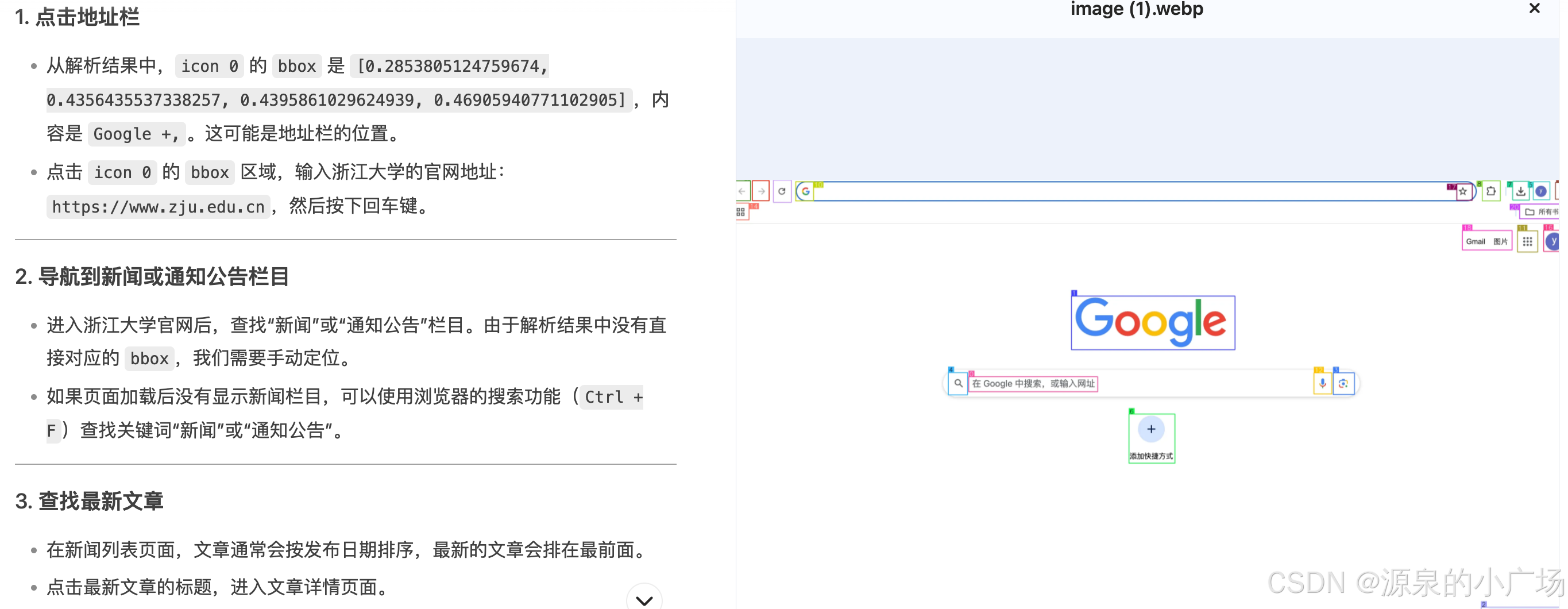
同理将每一个步骤的截图发送给omniparser v2进行解析,以及将解析结果发送给deepseek进行规划动作,再调用python的gui工具进行动作执行,最后获得最终的结果。
不过执行下来,感觉对于中文的解析还是有点问题,对于中文还是需要重新微调模型。
4. 参考材料
【1】CogAgent: A Visual Language Model for GUI Agents



















 3406
3406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











