






OmniParser V2的纯视觉驱动模式,以跨平台兼容性、高精度解析、实时动态响应为核心,结合结构化数据与开源生态,重新定义了GUI自动化交互范式。其技术突破不仅解决了传统方案的碎片化适配难题,更为大模型落地真实世界操作场景提供了关键桥梁。
一、无代码依赖的跨平台兼容性
- 摆脱底层API/HTML限制
传统自动化工具需依赖操作系统接口或HTML结构解析元素,而OmniParser V2仅通过屏幕截图即可识别按钮、输入框等交互组件,实现“所见即所得”的操作。
技术支撑:基于67k标注样本训练的YOLOv8微调模型,能精准检测最小8×8像素的UI元素。 - 全平台无缝适配
支持Windows、MacOS、iOS、Android及主流浏览器,无需针对不同系统开发独立逻辑,视觉解析能力统一覆盖多终端界面。
二、高精度小元素检测与语义理解
- 微小UI元素识别跃升
使用更大规模数据集(67k交互元素标注+7k图标描述数据)训练模型,对界面中的小尺寸图标、复选框等识别准确率显著提升,例如在高分辨率基准测试ScreenSpotPro中,V2+GPT-4o准确率达39.6%,远超单独使用GPT-4o的0.8%。 - 功能语义深度解析
结合BLIP-v2微调模型,为每个元素生成自然语言标签(如“保存按钮”),并将OCR提取文本与视觉元素融合,构建带语义的DOM++结构,降低大模型决策复杂度。
三、实时响应与动态环境适应
- 低延迟推理优化
通过缩小图标模型的输入尺寸(512×512→256×256)和模型轻量化技术,推理延迟较V1降低60%,达到实时交互级别。 - 动态界面状态追踪
采用差异比对算法实时感知屏幕变化(如弹窗出现、加载进度更新),自动更新DOM结构,确保动作与界面状态同步。
四、结构化数据驱动智能决策
- 增强DOM输出
将视觉解析结果封装为JSON格式,包含坐标、类型、语义标签等元数据,供大模型生成精准操作指令。例如,与GPT-4V协作时,图标标记正确率从70.5%提升至93.8%。 - 多模态协同增效
OCR提取文本与BLIP-v2语义描述结合,形成“视觉-文本”双通道输入,减少大模型Token消耗,上下文利用率提升4倍。
五、开源生态与开发者友好设计
- 工具链集成
开源OmniTool提供Docker化开发环境,集成屏幕解析、动作规划、硬件模拟等模块,支持快速构建定制化智能体。 - 低代码开发示例

OmniParser V2 的跨平台能力源于其纯视觉驱动与结构化语义解析的技术融合,通过以下核心机制实现多系统无缝适配:
OmniParser V2 通过视觉解析统一化、数据结构标准化、动态适配智能化三大技术支柱,实现了“一次训练,全平台适用”的突破。开发者无需针对不同系统编写适配代码,即可构建跨平台自动化工作流。
一、视觉驱动解析替代底层依赖
-
摒弃平台专属接口
传统自动化工具需调用 Windows UIA、Android Accessibility API 等平台专属接口,而 OmniParser V2 仅通过屏幕截图分析界面,彻底摆脱对操作系统底层接口的依赖。
技术实现:基于 67k 多平台标注数据训练的 YOLOv8 模型,可识别 Windows/MacOS/iOS/Android 等系统的 UI 元素(如按钮、输入框),最小支持 8×8 像素的图标检测。 -
统一视觉特征提取
不同平台的 UI 元素(如保存按钮)可能使用不同设计风格,但通过视觉语义模型(BLIP-v2 微调)提取通用功能标签(如“保存”),屏蔽平台视觉差异。
二、结构化数据标准化表示
-
跨模态 DOM++ 架构
将屏幕元素(图标、文本)解析为统一的 JSON 格式 DOM 结构,包含坐标、类型、语义标签等字段,为不同平台操作提供标准化输入。
示例字段: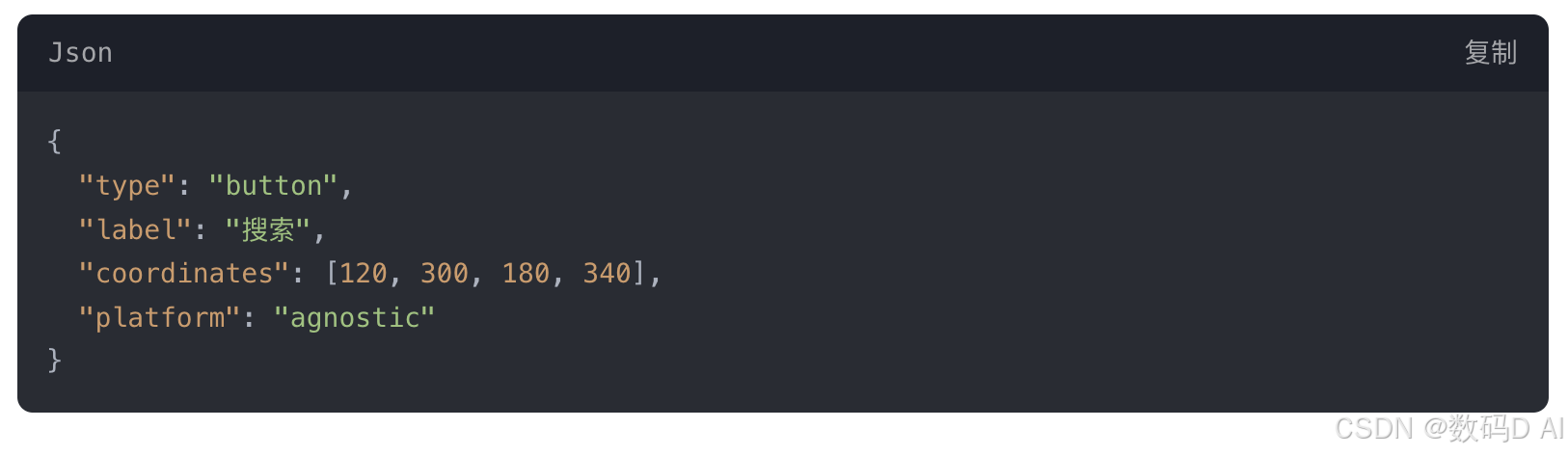
-
OCR 与视觉融合去歧义
集成 Tesseract OCR 提取文本,并与图标边界框去重融合,解决跨平台文字排版差异(如 iOS 圆角字体 vs Android 方正字体)导致的识别问题。
三、动态上下文适配机制
-
界面状态实时追踪
通过差异比对算法(如像素级变化检测)动态更新 DOM 结构,适应不同平台的界面刷新逻辑(如 Windows 窗口动画 vs Web 异步加载)。 -
操作指令归一化
将用户动作(点击、输入)转化为设备无关指令,底层通过虚拟化驱动层(如模拟鼠标移动至 DOM 坐标 [x,y])适配各平台硬件交互协议。
四、多平台泛化训练策略
-
跨系统数据集覆盖
使用涵盖 67k 样本的多平台界面数据集(包括 Windows 桌面应用、iOS 移动端、Web 浏览器等),提升模型对异质 UI 的泛化能力。 -
对抗性数据增强
在训练中引入平台特异性干扰(如模拟 MacOS 毛玻璃效果、Android 暗色主题),增强模型在未知平台上的鲁棒性。

















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









